
- 1android自定义view之---组合view_android 自定义组合view
- 2新手入门:大语言模型训练指南_大语言模型 专业词汇训练
- 3Dockerfile——ENTRYPOINT详解
- 4【机器学习】我们该如何评价GPT-4o?GPT-4o的技术能力分析以及前言探索_gpt4o的评估指标
- 5Github贡献PR六部曲_github 如何 pr
- 6前端下载包命令_下载前端环境指令
- 7SpringBoot与shardingsphere分库分表实战_springboot集成shardingsphere 实战
- 8Spring的JdbcTemplate自动关闭连接_jdbctemplate 关闭连接
- 9git clone 用户名密码_解决git每次推送仓库都要输入用户名密码的解决方案
- 10智能电饭煲设计(文档+仿真源文件)_基于51单片机多功能电饭锅控制系统的设计与实现的方框图
机器学习笔记 人脸识别技术全面回顾和小结(1)_采集每一位家庭成员的人脸照片让人脸识别门锁学习识别属于机器学习中的什么学
赞
踩
一、简述
人脸识别是视觉模式识别的一个细分问题。人类一直在识别视觉模式,我们通过眼睛获得视觉信息。这些信息被大脑识别为有意义的概念。对于计算机来说,无论是图片还是视频,它都是许多像素的矩阵。机器应该找出数据的某一部分在数据中代表了什么概念。这是视觉模型识别中的一个粗略分类问题。对于人脸识别,需要在所有机器认为人脸的数据部分区分人脸属于谁。这是一个细分问题。
广义的人脸识别包括用于构建人脸识别系统的相关技术。它包括人脸检测、人脸定位、身份识别、图像预处理等。人脸检测算法是找出一张图像中所有人脸的坐标系。这是扫描整个图像以确定候选区域是否是面部的过程。人脸坐标系的输出可以是正方形、矩形等。人脸位置是人脸特征在人脸检测坐标系中的坐标位置。深度学习框架基本上实现了当前一些不错的定位技术。与人脸检测相比,人脸定位算法的计算时间要短得多。
从人脸识别技术的应用布局来看,它在考勤门禁、安全和金融领域应用最为广泛,而物流、零售、智能手机、交通、教育、房地产、政府管理、娱乐广告、网络信息安全等领域也开始涉足。在安全领域,无论是对可疑情况的预警,还是对嫌疑人的追踪,都可以在人脸识别的辅助下完成。它代表着人工智能技术的巨大进步,这意味着我们需要更准确、更灵活、更快的识别技术。
人脸识别技术经历了很长的的发展阶段,包括早期算法、人工特征和分类器、深度学习等阶段。而且形成了人脸识别的一般评价标准和一般数据库。
二、人脸识别及其相关技术
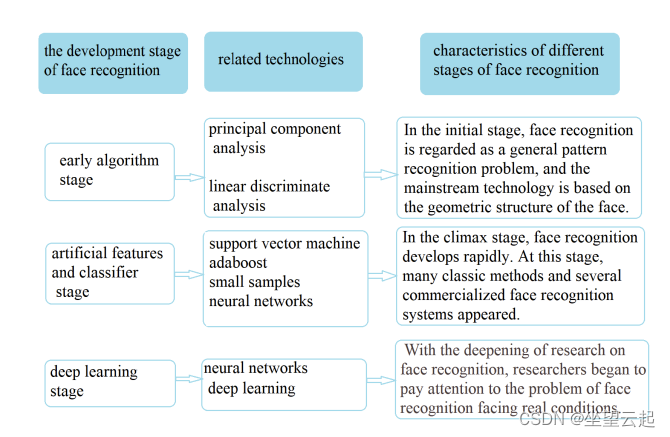
1、早期阶段
20世纪50年代,人们开始研究如何让机器识别人脸。1964年,人脸识别工程的应用研究正式开始,主要利用人脸几何进行识别。但它尚未在实践中得到应用。
1) Principal Component Analysis (PCA)
主成分分析(PCA)是应用最广泛的数据降维算法。在人脸识别算法中,主成分分析实现了特征人脸的提取。1991年,麻省理工学院媒体实验室的Turk和Pentland将主成分分析引入人脸识别。
主成分分析通常用于在其他分析之前对数据进行预处理。在具有更多维度的人脸数据中,它可以去除冗余信息和噪声,保留数据的本质特征,大大降低维度,提高数据的处理速度,并节省大量时间和成本。因此,该算法通常用于降维和多维数据可视化。
在基于主成分分析的特征提取算法中,特征脸是经典算法之一。图2是一个简单的特征提取过程,其中PCA通过使用K-Nearest-Neighbor(KNN)算法与人脸识别相结合。我们从采样数据中得到协方差矩阵的特征值和特征向量,并选择主分量,即具有最大特征值的特征向量。
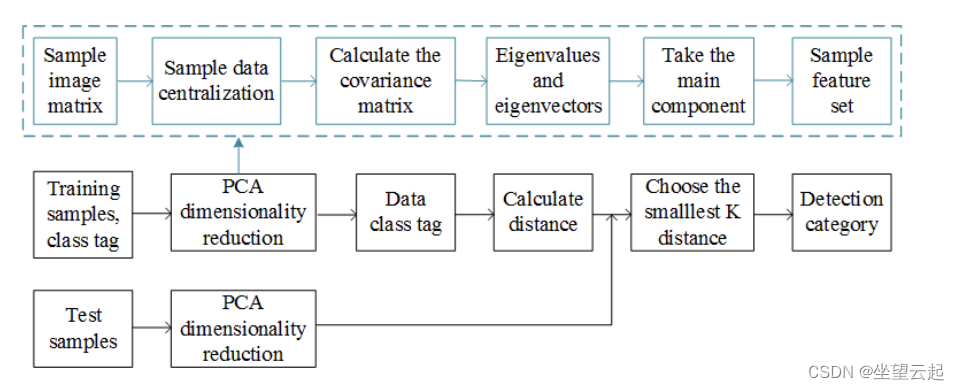
同时,通过相同的降维过程获得测试数据的特征矩阵。最后,利用KNN分类器对测试集的人脸图像类别进行检测。
尽管主成分分析在处理大型数据集时是有效的。其最大的缺点是其训练数据集必须足够大。例如,人脸识别系统中的原始照片数量必须至少为数千张,因此主成分分析的结果是有意义的。然而,当人们的面部表情不同时,会有障碍物遮挡面部,或者光线太强或太弱,很难获得良好的低维数据。
2) Linear Discriminate Analysis (LDA)
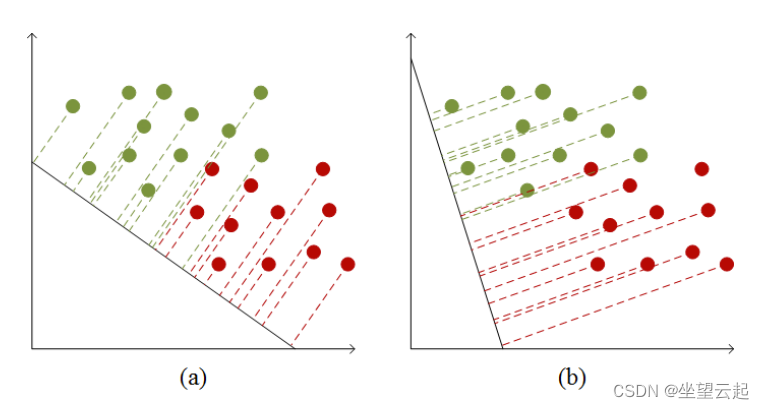
对于带有标签的人脸识别数据集,我们可以使用线性判别分析(LDA)。用于人脸分类。PCA要求降维后的数据方差尽可能大,以便数据可以尽可能广泛地划分,而LDA要求投影后同一类数据组内的方差尽可能小,组间的方差尽尽可能大,如图所示,这意味着LDA已经监督了降维,它应该使用标签信息尽可能地分离不同类别的数据。
2、人工特征与分类器阶段
1) Support Vector Machine (SVM)
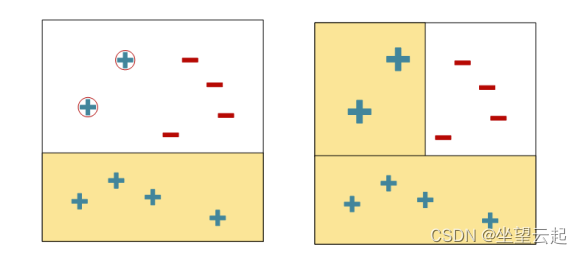
1995年,Vapnik和Cortes提出了支持向量机(SVM)。支持向量机是一种专门针对小样本、高维人脸识别问题的算法。它是在广义肖像算法的基础上发展起来的分类器。由于其在文本分类方面的优异性能,它很快成为机器学习的主流技术。在人脸识别中,我们使用提取的人脸特征和SVM来找到用于区分不同人脸的超平面。
假设存在一个具有许多训练数据的二维空间。SVM应该找到一组直线来正确地对训练数据进行分类。由于训练数据数量的限制,训练之外的样本集合可能比训练集中的数据更接近分割线。因此,我们选择离最近的数据点最远的线,即支持向量。这样的分割方法具有最强的泛化能力,如下图所示。上述方法区分了二维平面上的数据,但这一理论也可以应用于三维甚至更高维的空间,只有要找到的边界成为平面或超平面。

2) Adaboost
最初的boosting算法是由Schapire提出的。它用于人脸检测。Boosting算法可以提高任何给定学习算法的准确性。其主要思想是通过一些简单的规则将不同的分类器集成到一个更强的最终分类器中,从而使整体性能更高。
boosting算法中的人脸识别存在两个问题。一个是如何调整训练集,另一个是将弱分类器组合成强分类器。Adaboost对这些问题进行了改进,并被证明是一种有效实用的人脸识别增强算法。Adaboost使用加权的训练数据而不是随机选择的训练样本来关注相对困难的训练数据样本。Adaboost使用加权投票机制代替平均投票机制,使分类效果好的弱分类器具有更大的权重。
Adaboost分类器可以理解为一个函数(见下图)。它输入特征值x并返回值G(x)。在adaboost分类器中,多个弱分类器Gi被组合成一个强分类器,每个弱分类器都有权重wi,如下所示
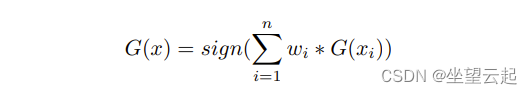
在人脸识别中,使用adaboost算法应该为每个图像提取Haar特征。此功能反映图像的灰度级变化。
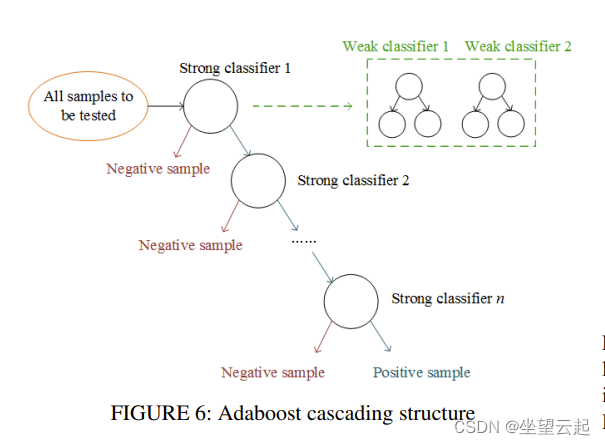
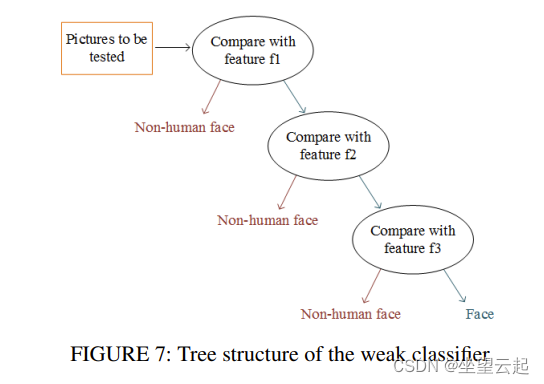
Haar分类器是adaboost算法的级联应用。级联分类器的结构如图6所示。每个级联分类器包含多个弱分类器,每个弱分类器的结构也是一个决策树。图7显示了一个决策树形式的弱分类器,用于确定图片是否是人脸。
3) Small samples
小样本问题是指人脸识别的训练样本数量太少,导致大多数人脸识别算法无法达到理想的识别性能。
为了有效地保留图像信息,保持样本之间的关系,减少噪声的影响,进一步增强人脸识别效果,人们进行了许多研究。Howland等人提出了将线性判别分析与广义奇异值分解(GSVD)相结合的方法来解决小样本量问题。He等人提出了一种在不同空间中使用Householder QR分解过程来提高线性判别分析方法对小样本的性能的方法。王等针对局部保持投影(LPP)技术所面临的小样本问题,提出了一种指数局部保持投影方法。Wan等人提出了一种基于DLMPP的广义判别局部中值保持投影(GDLMPP)算法,可以有效地解决小样本量问题。这些研究极大地提高了人脸识别的性能。
4) Neural networks
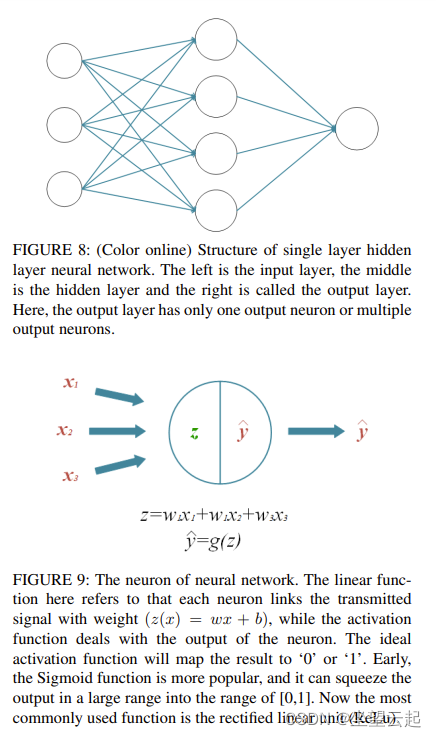
神经网络是一种模拟人脑进行人脸识别的算法。人脸识别作为生物识别技术中最受关注的识别方法之一,已成为神经网络领域的研究热点之一。一个典型的神经网络结构如图8所示。每个神经元由一个线性函数和一个非线性激活函数组成,如图9所示。
3、深度学习
深度学习是机器学习的一个分支。深度学习可以在训练过程中自动找出分类所需的特征,而无需进行特征提取步骤。这是为了迫使网络学习获得更有效的特征来区分不同的人脸。深度学习已经彻底改变了人脸识别领域。深度学习广泛应用于人脸识别,分为以下几个方面。
首先是基于卷积神经网络(CNN)的人脸识别方法。CNN利用数据的局部性和其他特征,通过结合局部感知区域、共享权重和人脸图像的下采样来优化模型结构。CNN与普通的神经网络非常相似。它们由具有可学习权重和偏差值的神经元组成。在接收到输入数据之后,对每个神经元执行点积计算。然后输出每个分类的分数。它是应用最广泛的深度学习框架。图11清楚地描绘了CNN的结构。
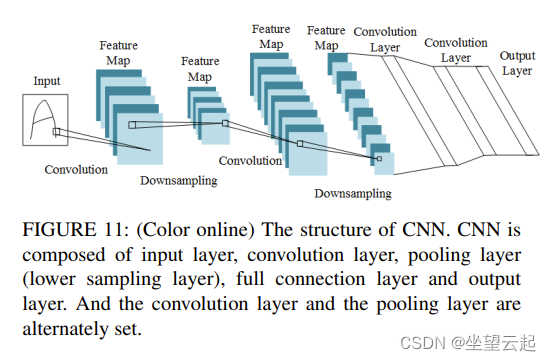
第二个方面是深度非线性人脸形状提取方法。人脸形状提取或人脸对齐在人脸识别、表情识别和人脸动画合成等任务中起着非常重要的作用。人脸识别的难点在于人脸形状和纹理的高度复杂。为了进一步提高算法的非线性回归能力,获得对形状等变化的鲁棒性,提出了一种从粗到细的深度非线性人脸形状提取方法(粗到细自动编码器网络,CFAN)。
基于深度学习视频监控的人脸识别是第三个方面。在智能监控环境中,识别可疑字符是人脸识别的一个重要用途。准确、快速地识别视频中的人的身份对于视频搜索和视频监控非常重要。Schofield等人提出了一种深度卷积神经网络方法,该方法可以自动检测、跟踪和记录视频中的人脸,并可用于研究动物的行为。
第四个方面是基于深度学习的低分辨率人脸识别。在实际应用中,采集到的人脸图像姿态变化多样,图像分辨率低,导致人脸图像识别性能迅速下降。年,对低分辨率人脸数据集进行了研究,采用了最先进的监督判别学习方法,引入了生成对抗网络预训练方法和全卷积结构,提高了低分辨率人脸识别效果。许多深度学习模型侧重于训练方法和过程的优化。然而,低分辨率人脸识别的准确性不断提高,运行时间也相应减少,从而能够更好地投入实际应用。
随着更全面的深度学习模型的发展,不仅有能够适应大规模数据的深度模型,还有能够适应一些特定情况下的小数据集的处理方法。一种方法是使用合成数据,另一种是使用当前流行的生成对抗性网络来生成数据。然而,深度学习也有一些不足之处。例如,训练模型需要很长时间,需要不断迭代来优化模型,并且不能保证全局最优解。这些也需要在未来进行探索。

