
- 1VUE项目中优雅使用EasyPlayer实时播放摄像头多种格式视频
- 2蓝桥杯刷题第七天_任何一个大于 1 的正整数都能被分解为若干个质数相乘, 比如 28 = 2 × 2 × 7 28=
- 3代码随想录算法训练营第52天(py)| 动态规划 | 647. 回文子串、516.最长回文子序列
- 4微信小程序对radio等标签调节大小_微信小程序修改radio大小
- 5【问题记录】Linux下克隆git项目到本地_linux git clone 公钥
- 6GBDT-梯度提升决策树_梯度提升决策树模型
- 7毕设/私活/必备,一个挣钱的标准开源前后端分离【springboot+vue+redis+Spring Security】脚手架--若依框架_毕设有必要前后端分离吗
- 8美团基于AI的搜索引擎架构建设与实践
- 92024年Web前端最全Angular、React、Vue,谁能成为2024年JavaScript框架冠军?,直面秋招_前端新框架
- 10推荐一款好用的编辑工具——onlyoffice桌面编辑器8.1
小白学习Java第十五天_java 十五天学习计划
赞
踩
复习
1.泛型:
jdk5.0版本的新特性,属于是一个安全机制,可以将运行时出现的问题提前至编译时期,也不需要做强转操作。
弊端:只能操作泛型上执行的类型。
格式: <引用类型名>
自定义泛型:
泛型类 class 类名<T,U,…>
泛型方法 修饰符 <T,U,W,…> 返回值类型 方法名(T t, U u, W w){}
泛型接口 interface 类名<T,U,…>
泛型限定:
应用在方法的参数列表上。
<?> <? extends E> <? super E>
2.Set接口 :无序不可重复
实现类:
HashSet:
保证元素唯一:哈希表算法
哈希表算法依赖于 hashCode(),equals()这两个方法,因此存储自定义对象时需要重写这两个方法。
子类:LinkedHashSet ,有序不可重复。
TreeSet:(了解)
保证元素唯一:二叉树算法,元素要排序。
new TreeSet(): 自然顺序排序,元素要转为Comparable类型,通过compareTo方法的返回值进行排序和去重
new TreeSet(比较器):比较器方式排序,定义类实现Comparator接口,重写compare方法,通过这个方法的返回值进行排序和去重
3.Map接口
存储的是具有映射关系的键值对。
键:必须唯一;值:可以重复。可以存储null作为key-value。
方法:
put(key,value), get(key) , remove(key), containsKey/value() , values() , size()…
实现类:
HashMap : key,哈希表。
LinkedHashMap :key,哈希表+链表
TreeMap:key,二叉树
课程
一. 双列集合
(一) Map集合的遍历方式
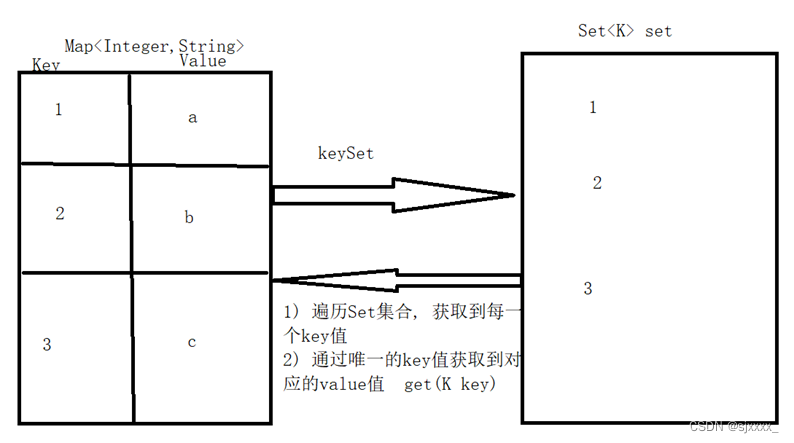
1.1 键遍历
1、获取Map集合中的所有键,放到一个Set集合中,遍历该Set集合,获取到每一个键,根据键再来获取对应的值。
2、获取Map集合中的所有键
Set keySet()
3、遍历Set集合的两种方法:
迭代器
增强for循环
4、拿到每个键之后,获取对应的值
V get(K key)
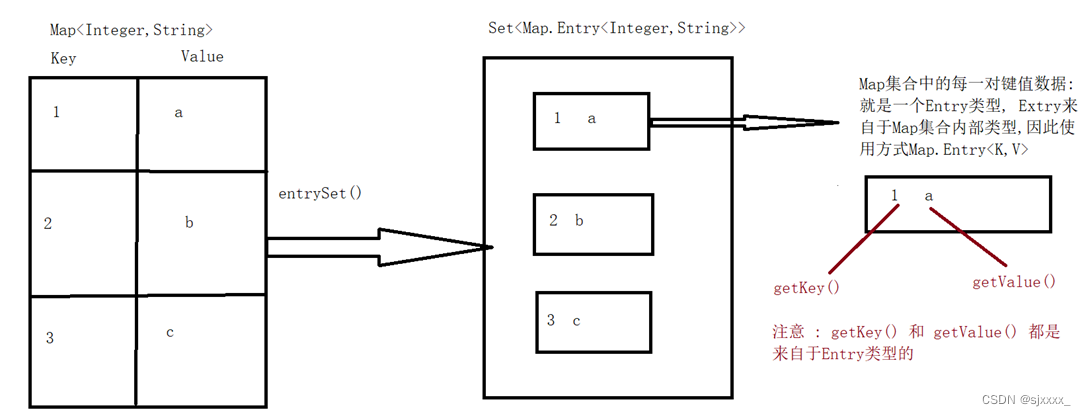
1.2 键值对遍历
- 获取Map<K,V>集合中,所有的键值对(Entry)对象,以Set集合形式返回。方法:entrySet()。
- 遍历包含键值对(Entry)对象的Set集合,得到每一个键值对(Entry)对象。
- 通过键值对(Entry)对象,获取Entry对象中的键与值。方法:getkey() getValue()
import java.util.HashMap; import java.util.Map; import java.util.Set; import java.util.Map.Entry; public class Demo1 { public static void main(String[] args) { HashMap<String ,String > map = new HashMap<>(); map.put("01","zhangsan"); map.put("02","lisi"); map.put("03","zhaoliu"); map.put("04","wangwu"); map.put("05","songqi"); /* * keySet: * 1.将map中所有的key取出,存储到Set集合中。 * 2.遍历Set集合,根据Map中提供的 get(key)方法,取出对应的value * */ Set<String> keys = map.keySet(); for(String key : keys){ String value = map.get(key); System.out.println(key+"-----"+value ); } System.out.println("-------------------------------------"); /* * entrySet: * 将map中存储的 键值对的关系取出,存储到set集合中 * 关系也是数据,就有对应的数据类型来表示,数据类型是:Map.Entry * Map.Entry是一个接口,接口中提供了getKey和getValue方法,可以取出关系中的key和value。 * */ Set<Map.Entry<String, String>> entries = map.entrySet(); for(Map.Entry<String, String> entry:entries){ String key = entry.getKey(); String value = entry.getValue(); System.out.println(key+"...."+value); } } }

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
练习1:
定义出任意一个字符串, 例如: ”abcdsscchdyti12” , 计算字符串中每个字符出现的次数,最终获取到的结果 : a有1个 b有1个 c有3个…
import com.sun.javafx.collections.MappingChange; import java.util.HashMap; import java.util.Map; import java.util.Set; public class Demo2 { public static void main(String[] args) { //定义出任意一个字符串, 例如: ”abcdsscchdyti12” , 计算字符串中每个字符出现的次数, // 最终获取到的结果 : a有1个 b有1个 c有3个... String s = "abcdsscchdyti12"; //1.遍历字符串 //2.判断字符在map中出现过吗? // 出现过:重新存储(字符,value+1) 没出现过:直接存储(字符,1) //3.遍历map //定义map集合,存储key即是字符,value次数 HashMap<Character,Integer> map = new HashMap<>(); //遍历字符串 for (int i = 0; i <s.length(); i++){ char key = s.charAt(i); //判断map中是否存储过该字符 if(map.containsKey(key)){ //包含 Integer value = map.get(key); value = value+1; map.put(key,value); }else{ //不包含 map.put(key,1); } } //遍历map Set<Character> keys = map.keySet(); for (Character key : keys){ Integer value = map.get(key); System.out.println(key+"...."+value); } /*Set<Map.Entry<Character, Integer>> entries = map.entrySet(); for (Map.Entry<Character, Integer> entry:entries){ Character key= entry.getKey(); Integer value = entry.getValue(); System.out.println(key+"有"+value+"个"); }*/ } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
(二) HashMap中key值唯一分析
1、HashMap就是Map集合使用哈希表的存储方式的一种实现类
2、HashMap存储的是jdk中提供的类型的键,就可以直接保证键的唯一性
3、HashMap中存储的键,是自定义类型,无法保证键的唯一性;原因:虽然都是张三、23,但是这些对象并不是相同的对象,这些对象的哈希值计算结果各不相同,就说明一定不是相同的对象,所以无法保证键的唯一。
需要重写hashCode和equals方法
说明:HashMap的键的唯一性和HashSet的元素的唯一性,保证方式都一样
4、HashMap和HashSet的关系:
1、HashSet是由HashMap实现出来的,HashSet就是HashMap的键的那一列
2、将HashMap中的值的那一列隐藏掉,就变成了HashSet
HashSet保证元素唯一原理, 就是使用了HashMap中Key值唯一的原理
import java.util.Enumeration; import java.util.Hashtable; import java.util.LinkedHashMap; import java.util.Set; public class Demo3 { public static void main(String[] args) { LinkedHashMap<Integer,String> map = new LinkedHashMap<>(); map.put(1,"aa"); map.put(5,"cc"); map.put(2,"dd"); map.put(9,"ee"); map.put(9,"hh"); Set<Integer> keys = map.keySet(); for(Integer key : keys){ System.out.println(key+"..."+map.get(key)); } System.out.println("-----------------------------------------"); Hashtable<Integer,String> table = new Hashtable<>(); table.put(1,"aa"); table.put(3,"cc"); table.put(6,"ee"); table.put(9,"vv"); table.put(11,"ss"); //遍历 //获取所有的value Enumeration<String> values = table.elements(); while (values.hasMoreElements()) System.out.println(values.nextElement()); //获取所有的key Enumeration<Integer> en = table.keys(); while(en.hasMoreElements()){ System.out.println(en.nextElement()); } } } /* * LinkedHashMap: * key:采用链接列表+哈希表两个算法 * 特点: 保证迭代的顺序,同时key唯一。 * * Hashtable: * jdk1.0版本对象,集合框架后,被HashMap替代了,也是Map的一个实现类。 * 与HashMap的区别:Hashtable是一个线程安全对象,不允许存储null作为键值,初始容量是11。 * HashMap:是一个线程不安全对象,欲奴存储null作为键值,初始容量是16. * */
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
(三) Collections 工具类
3.1可变参数的使用和注意事项
- 概述: 可变参数又称参数个数可变,用作方法的形参出现,那么方法参数个数就是可变的了,方法的参数类型已经确定,个数不确定,我们可以使用可变参数.
- 格式:
修饰符 返回值类型 方法名(数据类型…变量名) {
} - 注意事项:
(1) 可变参数在方法中其实是一个数组
在方法中写数组和写可变参数不算重载,底层逻辑就是数组,是一样的
(2) 如果一个方法有多个参数,包含可变参数,可变参数必须要放在最后
(3) 方法中只能有一个可变参数
案例 : 定义出一个方法功能, 求任意个数整的累加和
public class Demo4 { public static void main(String[] args) { test(1,2,3); test1(1); sum(1,2,3,4,5); } public static void test1(int arr){ System.out.println(arr); } public static void test1(int... arg){ System.out.println(arg); } public static void test(int x,int... num){ System.out.println(num); System.out.println(num.length); for (int i =0; i < num.length; i++) System.out.println(num[i]); } //案例 : 定义出一个方法功能, 求任意个数整的累加和 public static void sum(int... arg){ int sum = 0; for (int num : arg){ sum = sum + num; } System.out.println(sum); } } /* * 集合工具类: * Collections: * 类中成员都是静态的,直接通过类名访问即可。 * 可变参数: * jdk5.0特性。 * 格式: 数据类型... 参数名 * int... num * 给可变参数赋值,值的个数大于等于0个都可以。 * 可变参数底层原理就是数组,当调用带有可变参数的方法时,创建一个数组,这个数组的大小取决于实际参数的个数。 * 可变参数按照数组方式进行操作即可。 * 注意: * 1.参数列表中,可变参数个数最多1个 * 2.参数列表中,可变参数一定在最后 * */
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
3.2 Collections单列集合工具类
-
Collections类是一个单列集合的工具类,在类中封装类很多常用的操作集合的方法.因为Collections工具类中, 没有对外提供构造方法, 因此不能创建对象, 导致类中所有成员和方法全部静态修饰, 类名.直接调用
-
Collections类中的常用方法:
- sort(List list): 将指定的列表按升序排序,从小到大
- max、min(Collection c):获取集合的最大值或者最小值
- replaceAll(List list, E oldVal, E newVal):将集合list中的所有指定老元素oldVal都替换成新元素newVal
- reverse(List list):将参数集合list进行反转
- shuffle(List list):将list集合中的元素进行随机置换
import java.util.*; /* * 1.addAll(Collection<T> ,T...) :将多个T类型数据添加到集合中 * 2.sort(List) : list元素按照自然顺序排序 * 3.sort(List,Comparator) : list元素按照比较器顺序排序 * 4.shuffle(List) :随机打乱List集合 * 5.reverse(List):反转list集合 * */ public class Demo5 { public static void main(String[] args) { ArrayList<String> list = new ArrayList<>(); Collections.addAll(list,"11","00","aa","cc","dd"); //list的自然顺序排序 Collections.sort(list); //比较器方式排序 Collections.sort(list, new Comparator<String>() { @Override public int compare(String s1, String s2) { return s2.compareTo(s1); } }); //随机打乱List集合 //Collections.shuffle(list); //反转 //Collections.reverse(list); System.out.println(list); //返回一个比较器,这个比较器逆转了自然顺序。 TreeSet<Integer> set = new TreeSet<>(Collections.reverseOrder()); Collections.addAll(set,4,6,1,3,9,7); System.out.println(set); //返回一个比较器,这个比较器逆转了参数比较器的顺序 TreeSet<Integer> treeSet = new TreeSet<>(Collections.reverseOrder(new Comparator<Integer>() { @Override public int compare(Integer o1, Integer o2) { return o2-o1; } })); Collections.addAll(treeSet,4,6,1,3,9,7); System.out.println(treeSet); ArrayList<String> list1 = new ArrayList<>(); Collections.addAll(list1,"123","11111","55","999999"); System.out.println(Collections.max(list1)) ; //999999 System.out.println(Collections.max(list1, new Comparator<String>() { @Override public int compare(String o1, String o2) { return o1.length()-o2.length(); } })); System.out.println("----------------------------------------------"); //集合数组间转换 Object[] objects = list.toArray(); //集合--->数组 Integer[] arr = {1,2,3,4}; List<Integer> list2 = Arrays.asList(arr); //数组--->集合 //注意:转的这个集合,大小是固定的,不能改变其长度,因此不能使用集合中的增删方法。 list2.contains(2); //对象间的转 目的就是为了使用对方的功能。 } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
三. File类
(一)概述
- File类介绍:来自于java.io包
(1) 它是文件和目录路径名的抽象表示。
(2) 文件和目录是可以通过File封装成对象的。
(3) 对于File而言,其封装的并不是一个真正存在的文件,仅仅是一个路径名而已。这个路径名它可以是存在的,也可以是不存在的.将来是可以通过具体的操作把这个路径的内容转换为存在的路径操作。 - 路径:用于描述文件或者文件夹的所在位置的字符串。举例 : D:\笔记
- 路径分类:
(1) 绝对路径:是一个完整的路径,从盘符开始。举例 : D:\Idea资料
(2) 相对路径:是一个简化的路径,相对当前项目下的路径。举例: a\b\ok.txt
idea中, 默认的路径: 当前项目工程根目录
(二)File类型的构造方法
1、File(String path):把字符串的路径,封装成一个File对象
2、File(String parent, String child):将父级路径和子级路径封装成一个File对象,其实描述的是父级路径和子级路径拼接后的路径
3、File(File parent, String child):将父级File对象路径和字节路径封装成一个File对象,其实描述的也是父级路径和子级路径拼接后的路径
import java.io.File; public class Demo6 { public static void main(String[] args) { String path = "d:\\abc\\a.txt"; path = "d:/abc/a.txt"; path = "d:"+ File.separator+"abc"+File.separator+"a.txt"; //目录分隔符 System.out.println(path); //构造方法: File f1 = new File("e:\\abc\\a.txt"); System.out.println(f1); File f2 = new File("e:\\abc","a.txt"); System.out.println(f2); File f3 = new File(new File("e:\\abc"),"a.txt"); System.out.println(f3); } } /* 包:java.io * File类 该对象是用于封装文件信息和目录信息的。 注意:file仅仅是封装信息,封装的信息不能保证真实存在,即文件或目录是真实有效 file不能操作文件中的数据。 file封装的文件或目录可以通过一些手段,让其真实存在。 * */
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
(三)File类型的创建方法
1、boolean createNewFile():创建当前File对象所描述的路径的文件
2、boolean mkdir():创建当前File对象所描述的路径的文件夹(如果父级路径不存在,那么不会自动创建父级路径)
3、boolean mkdirs():创建当前File对象所描述的路径的文件夹(如果父级路径不存在,那么自动创建父级路径)
(四)File类型的删除方法
1、delete():删除调用者描述的文件或者文件夹, 文件存在或者文件夹为空才能删除成功
2、注意事项:
- delete在删除文件夹的时候,只能删除空文件夹, 是为了尽量保证安全性
- delete方法不走回收站
(五)File类型常用的判断功能
1、exists():判断当前调用者File对象所表示文件或者文件夹,是否真实存在, 存在返回true,不存在返回false
2、isFile():判断当前调用者File对象,是否是文件
3、isDirectory():判断当前调用者File对象,是否是文件夹
(六)File类型的获取功能
1、String getAbsolutePath():获取当前File对象的绝对路径
2、String getPath():获取的就是在构造方法中封装的路径
3、String getName():获取最底层的简单的文件或者文件夹名称(不包含所造目录的路径)
4、String[] list():获取当前文件夹下的所有文件和文件夹的名称,到一个字符串数组中
5、File[] listFiles():获取当前文件夹下的所有文件和文件夹的File对象,到一个File对象数组中
import org.junit.Test; import java.io.File; import java.io.FileFilter; import java.io.FilenameFilter; import java.io.IOException; import java.text.SimpleDateFormat; import java.util.Date; public class Demo7 { @Test public void test() throws IOException { //创建方法 File f = new File("a.txt"); //创建文件 (文件不存在则创建,文件存在则不创建) //注意:创建文件前,要保证父目录存在 // System.out.println(f.createNewFile()); File f1 = new File("abc"); //创建目录 (目录不存在则创建,目录存在则不创建) //只创建一级目录,前提是父母录存在。 // System.out.println(f1.mkdir()); File f2 = new File("a\\b"); //创建多级目录,即父目录+子目录 // System.out.println(f2.mkdirs()); //删除文件或目录 (注意:删除的内容不经过回收站,因此要慎重) //删除目录,前提该目录为空,即目录中不能有内容 System.out.println(f.delete()); System.out.println(f1.delete()); System.out.println(f2.delete()); } @Test public void test1(){ File f = new File("a.txt"); //判断文件或目录是否存在,真实查找 //通常情况下,调用创建文件或目录方法前,都先调用该方法。 System.out.println(f.exists()); //判断是否是文件,真实查找 System.out.println(f.isFile()); //判断是否是目录,真实查找 System.out.println(f.isDirectory()); //是否是绝对路径,只看file对象的封装内容的格式 System.out.println(f.isAbsolute()); //是否是隐藏文件 System.out.println(f.isHidden()); } @Test public void test2(){ File file = new File("a.txt"); //将字符串转为File对象 //获取绝对路径 System.out.println(file.getAbsoluteFile()); //获取路径 System.out.println(file.getPath()); //返回值是String,即将file对象转为字符串 //获取文件或目录名 System.out.println(file.getName()); } @Test public void test3(){ File file = new File("E:\\0802java系统班\\day15"); //列出指定目录下的所有内容 String[] names = file.list(); for (String name:names) System.out.println(name); System.out.println("-------------------------------"); File[] files = file.listFiles(); for (File f : files) System.out.println(f.getName()); } //需求:列出指定目录下及其子目录下的所有文件名称 @Test public void test4(){ File file = new File("E:\\0802java系统班\\day16\\test"); listNames(file); } //方法自己调用自己----方法递归 //注意: 递归一定要能停止,而且次数也不能过多,都有可能造成内存溢出。 public void listNames(File file){ File[] files = file.listFiles(); for (File f : files) { if(f.isDirectory()){ listNames(f); }else { System.out.println(f.getName()); } } } @Test public void test5(){ File file = new File("a.txt"); //获取文件的字节数(注意,该方法只操作文件,不要操作目录) System.out.println(file.length()); //文件的最后一次修改时间,返回的是毫秒值 System.out.println(file.lastModified()); String date = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss").format(new Date(file.lastModified())); System.out.println(date); } @Test public void test6(){ File file = new File("E:\\0802java系统班\\day15"); //过滤出该目录下的txt格式的文件 File[] files = file.listFiles(new FileFilter() { @Override public boolean accept(File pathname) { //pathname : 指定目录下的每个内容 return pathname.isFile() && pathname.getPath().endsWith("txt"); } }); for (File f: files) System.out.println(f.getName()); /* String[] names = file.list(new FilenameFilter() { @Override public boolean accept(File dir, String name) { //dir:指定的目录, name:指定目录下的每个内容的名字 return new File(dir,name).isFile() && name.endsWith("txt"); } }); for (String name:names) System.out.println(name);*/ } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111
- 112
- 113
- 114
- 115
- 116
- 117
- 118
- 119
- 120
- 121
- 122
- 123
- 124
- 125
- 126
- 127
- 128
- 129
- 130
- 131
- 132
- 133
- 134
- 135
- 136
- 137


