
机器学习笔记之线性分类——朴素贝叶斯分类器(Naive Bayes Classifier)
赞
踩
引言
本节将介绍一个经典的基于线性分类的概率生成模型——朴素贝叶斯分类器(Naive Bayes Classifier)。
回顾:概率生成模型
在机器学习笔记之线性分类——高斯判别分析(一)模型思路构建中介绍过,概率生成模型用于分类任务的朴素思想是软分类思想——给定样本
X
\mathcal X
X条件下,判断后验概率
P
(
Y
∣
X
)
P(\mathcal Y \mid \mathcal X)
P(Y∣X)之间的大小关系。以二分类为例:
P
(
Y
=
0
∣
X
)
=
?
P
(
Y
=
1
∣
X
)
P(\mathcal Y = 0 \mid \mathcal X) \overset{\text{?}}{=}P(\mathcal Y= 1 \mid \mathcal X)
P(Y=0∣X)=?P(Y=1∣X)
而概率生成模型是利用贝叶斯定理,将 后验概率大小关系 转化为 似然和先验概率的乘积形式,即通过乘积大小来反映后验概率的大小关系:
P
(
Y
=
0
∣
X
)
=
?
P
(
Y
=
1
∣
X
)
→
P
(
X
∣
Y
=
0
)
P
(
Y
=
0
)
=
?
P
(
X
∣
Y
=
1
)
P
(
Y
=
1
)
P(\mathcal Y = 0 \mid \mathcal X) \overset{\text{?}}{=} P(\mathcal Y = 1 \mid \mathcal X) \\ \to P(\mathcal X \mid \mathcal Y = 0)P(\mathcal Y =0) \overset{\text{?}}{=} P(\mathcal X \mid \mathcal Y=1)P(\mathcal Y=1)
P(Y=0∣X)=?P(Y=1∣X)→P(X∣Y=0)P(Y=0)=?P(X∣Y=1)P(Y=1)
从参数角度观察,概率生成模型是将 求解
P
(
Y
∣
X
)
P(\mathcal Y \mid \mathcal X)
P(Y∣X)的模型参数 转化为 求解
P
(
X
∣
Y
)
P(\mathcal X \mid \mathcal Y)
P(X∣Y)和
P
(
Y
)
P(\mathcal Y)
P(Y)的概率分布参数。
注意上面的表达,先验概率分布
P
(
Y
)
P(\mathcal Y)
P(Y)的参数同样是未知的,先验概率分布同样需要求解。因此,在求解概率分布参数的过程中,使用的是 极大似然估计(MLE),而不是最大后验概率估计(MAP):
最大后验概率估计(MAP)是对‘概率模型’
P
(
X
∣
Y
)
P(\mathcal X \mid \mathcal Y)
P(X∣Y)求解最优参数的过程中,使用一个‘人为设定的经验分布’
P
(
Y
)
P(\mathcal Y)
P(Y)作为先验概率,而该分布中不存在任何参数,设定出来即可直接使用。并且该先验分布的作用只是对‘极大似然估计’方法求解的模型参数起到一个约束作用。
θ
^
=
arg
max
θ
L
(
θ
)
L
(
θ
)
=
log
∏
i
=
1
N
P
(
x
(
i
)
∣
y
(
i
)
)
P
(
y
(
i
)
)
\hat \theta = \mathop{\arg\max}\limits_{\theta} \mathcal L(\theta) \\ \mathcal L(\theta) = \log \prod_{i=1}^N P(x^{(i)} \mid y^{(i)}) P(y^{(i)})
θ^=θargmaxL(θ)L(θ)=logi=1∏NP(x(i)∣y(i))P(y(i))
概率生成模型:高斯判别分析对应样本分布的假设表示如下:
以二分类为例,基于样本的二分类属性,假设先验概率
P
(
Y
)
P(\mathcal Y)
P(Y)为伯努利分布;在分类确定的条件下,假设各分类下的样本分布服从高斯分布:
Y
∼
B
e
r
n
o
u
l
l
i
(
ϕ
)
X
∣
Y
=
0
∼
N
(
μ
1
,
Σ
)
X
∣
Y
=
1
∼
N
(
μ
2
,
Σ
)
\mathcal Y \sim Bernoulli(\phi) \\ \mathcal X \mid \mathcal Y = 0 \sim \mathcal N(\mu_1,\Sigma) \\ \mathcal X \mid \mathcal Y = 1 \sim \mathcal N(\mu_2,\Sigma)
Y∼Bernoulli(ϕ)X∣Y=0∼N(μ1,Σ)X∣Y=1∼N(μ2,Σ)
观察上述假设,先验概率
P
(
Y
)
P(\mathcal Y)
P(Y)的伯努利分布是基于样本的二分类属性,没的说;但是对似然
P
(
X
∣
Y
)
P(\mathcal X \mid \mathcal Y)
P(X∣Y)的假设显得有些简单:
样本集合
X
=
{
x
(
1
)
,
x
(
2
)
,
⋯
,
x
(
N
)
}
N
×
p
\mathcal X = \{x^{(1)},x^{(2)},\cdots,x^{(N)}\}_{N \times p}
X={x(1),x(2),⋯,x(N)}N×p,集合中的任意样本均是
p
p
p维向量:
x
(
i
)
=
(
x
1
(
i
)
,
x
2
(
i
)
,
⋯
,
x
p
(
i
)
)
T
x^{(i)} = (x_1^{(i)},x_2^{(i)},\cdots,x_p^{(i)})^{T}
x(i)=(x1(i),x2(i),⋯,xp(i))T
因此,该样本服从的自然也是
p
p
p维高斯分布。但实际情况是,由于样本特征的复杂性,使得样本各维度特征
(
x
1
,
x
2
,
⋯
,
x
p
)
(x_1,x_2,\cdots,x_p)
(x1,x2,⋯,xp)可能服从于不同分布。因此,抱着对似然
P
(
X
∣
Y
)
P(\mathcal X \mid \mathcal Y)
P(X∣Y)的假设更加细致的朴素思想,介绍一种经典思想:朴素贝叶斯分类器。
朴素贝叶斯分类器
朴素贝叶斯假设
朴素贝叶斯分类器的核心思想是朴素贝叶斯假设,又称条件独立性假设:
在分类确定的条件下(假设包含
k
k
k个分类),各分类下样本
X
l
(
l
=
1
,
2
,
⋯
,
k
)
\mathcal X_{l}(l=1,2,\cdots,k)
Xl(l=1,2,⋯,k)的任意两个不同特征之间相互独立。数学符号表示如下:
x
i
⊥
x
j
∣
Y
=
l
(
i
,
j
∈
{
1
,
2
,
⋯
,
p
}
,
i
≠
j
,
l
∈
{
1
,
2
,
⋯
,
k
}
)
x_i \perp x_j \mid \mathcal Y=l \quad (i,j \in \{1,2,\cdots,p\},i \neq j,l \in \{1,2,\cdots,k\})
xi⊥xj∣Y=l(i,j∈{1,2,⋯,p},i=j,l∈{1,2,⋯,k})
如果将该思想写成似然形式,表达如下:
由于假设的相互独立性,因此‘联合概率分布’
P
(
x
1
,
x
2
,
⋯
,
x
p
∣
Y
=
l
)
P(x_1,x_2,\cdots,x_p \mid \mathcal Y=l)
P(x1,x2,⋯,xp∣Y=l)可直接写成各项乘积的形式。
P
(
X
∣
Y
=
l
)
=
P
(
x
1
,
x
2
,
⋯
,
x
p
∣
Y
=
l
)
=
∏
i
=
1
p
P
(
x
i
∣
Y
=
l
)
P(\mathcal X \mid \mathcal Y = l) = P(x_1,x_2,\cdots,x_p \mid \mathcal Y=l) = \prod_{i=1}^p P(x_i \mid \mathcal Y = l)
P(X∣Y=l)=P(x1,x2,⋯,xp∣Y=l)=i=1∏pP(xi∣Y=l)
基于朴素贝叶斯假设的分类过程
继续观察朴素贝叶斯假设,相比于高斯判别分析对于
P
(
X
∣
Y
)
P(\mathcal X \mid \mathcal Y)
P(X∣Y)的假设,不否认朴素贝叶斯分类器对
P
(
X
∣
Y
)
P(\mathcal X \mid \mathcal Y)
P(X∣Y)的假设更加细致,精确到了样本
X
\mathcal X
X的各个维度;
但从 假设本身(假设方式) 来考虑朴素贝叶斯假设,它的假设是非常简单,甚至是非常苛刻的:各维度之间相互独立,意味着样本集合
X
\mathcal X
X的各特征之间
x
i
(
i
=
1
,
2
,
⋯
,
p
)
x_i(i=1,2,\cdots,p)
xi(i=1,2,⋯,p)必须存在严格界限。相反,如果各维度间存在关联关系,使用朴素贝叶斯分类器来执行分类任务可能没有良好的分类效果。
朴素贝叶斯假设如此严苛,那么构建该假设的动机是什么? 自然是 简化运算。由于条件独立性假设,在使用极大似然估计求解各维度对应分布的参数时,其他维度分布均可视为常数,求导过程中直接消掉即可。
场景描述
数据集合
D
a
t
a
=
{
(
x
(
i
)
,
y
(
i
)
)
}
i
=
1
N
Data = \{(x^{(i)},y^{(i)})\}_{i=1}^N
Data={(x(i),y(i))}i=1N,任意
x
(
i
)
x^{(i)}
x(i)均属于
p
p
p维向量:
x
(
i
)
=
(
x
1
(
i
)
,
x
2
(
i
)
,
⋯
,
x
p
(
i
)
)
p
×
1
T
(
i
=
1
,
2
,
⋯
,
N
)
x^{(i)} = (x_1^{(i)},x_2^{(i)}, \cdots,x_p^{(i)})_{p \times 1}^{T} \quad (i=1,2,\cdots,N)
x(i)=(x1(i),x2(i),⋯,xp(i))p×1T(i=1,2,⋯,N)
任意
y
(
i
)
y^{(i)}
y(i)均属于标量,且只包含两种标签信息:
y
(
i
)
∈
{
0
,
1
}
(
i
=
1
,
2
,
⋯
,
N
)
y^{(i)} \in \{0,1\} \quad (i=1,2,\cdots,N)
y(i)∈{0,1}(i=1,2,⋯,N)
分类过程
我们的分类思想依然没有变化,仍然是软分类思想:
P
(
Y
=
0
∣
X
)
=
?
P
(
Y
=
1
∣
X
)
P(\mathcal Y = 0 \mid \mathcal X) \overset{\text{?}}{=}P(\mathcal Y= 1 \mid \mathcal X)
P(Y=0∣X)=?P(Y=1∣X)
软分类思想的概率表达形式如下:
Y
p
r
e
d
^
=
arg
max
Y
∈
{
0
,
1
}
P
(
Y
∣
X
)
\hat {\mathcal Y_{pred}} = \mathop{\arg\max}\limits_{\mathcal Y \in \{0,1\}} P(\mathcal Y \mid \mathcal X)
Ypred^=Y∈{0,1}argmaxP(Y∣X)
根据贝叶斯定理,将上式进行转化:
Y
p
r
e
d
^
=
arg
max
Y
∈
{
0
,
1
}
P
(
X
∣
Y
)
P
(
Y
)
\hat {\mathcal Y_{pred}} = \mathop{\arg\max}\limits_{\mathcal Y \in \{0,1\}}P(\mathcal X \mid \mathcal Y)P(\mathcal Y)
Ypred^=Y∈{0,1}argmaxP(X∣Y)P(Y)
和线性判别分析相似,同样对
P
(
Y
)
,
P
(
X
∣
Y
)
P(\mathcal Y),P(\mathcal X \mid \mathcal Y)
P(Y),P(X∣Y)的概率分布进行假设:
-
P
(
Y
)
P(\mathcal Y)
P(Y)基于二分类性质,依然假设
Y
\mathcal Y
Y服从伯努利分布(Bernoulli Distribution);
Y ∼ B e r n o u l l i ( ϕ Y ) \mathcal Y \sim Bernoulli(\phi_{\mathcal Y}) Y∼Bernoulli(ϕY)
如果是多分类任务,假设 Y \mathcal Y Y服从分类分布(Categorial Distribution);
Y ∼ C a t e g o r i c a l ( ϕ Y ) \mathcal Y \sim Categorical(\phi_{\mathcal Y}) Y∼Categorical(ϕY) - 关于
P
(
X
∣
Y
)
P(\mathcal X \mid \mathcal Y)
P(X∣Y),基于条件独立性假设,我们需要对
X
\mathcal X
X每个维度
x
i
(
i
=
1
,
2
,
⋯
,
p
)
x_i(i=1,2,\cdots,p)
xi(i=1,2,⋯,p)的概率分布进行假设:
- 如果
x
i
x_i
xi属于离散型随机变量,通常假设
x
i
x_i
xi服从分类分布;
x i ∼ C a t e g o r i c a l ( ϕ x i ) x_i \sim Categorical(\phi_{x_i}) xi∼Categorical(ϕxi) - 如果
x
i
x_i
xi属于连续型随机变量,通常假设
x
i
x_i
xi服从高斯分布;
由于x i x_i xi是样本x x x在i维度上的分量,通常是一个实数值,因此这里定义x i x_i xi服从的分布是‘一维高斯分布’。
x i ∼ N ( μ j , σ j 2 ) x_i \sim \mathcal N(\mu_j,\sigma_j^{2}) xi∼N(μj,σj2)
- 如果
x
i
x_i
xi属于离散型随机变量,通常假设
x
i
x_i
xi服从分类分布;
至此,已经将 P ( Y ) , P ( X ∣ Y ) P(\mathcal Y),P(\mathcal X \mid \mathcal Y) P(Y),P(X∣Y)的概率分布假设完毕,后面对概率分布参数求解过程和高斯判别分析完全相同,即使用 极大似然估计 方法。
令
θ
\theta
θ为 待求解的概率分布参数,似然函数
L
(
θ
)
\mathcal L(\theta)
L(θ)定义如下:
L
(
θ
)
=
log
∏
i
=
1
N
[
P
(
x
(
i
)
∣
y
(
i
)
)
P
(
y
(
i
)
)
]
=
∑
i
=
1
N
log
[
P
(
x
(
i
)
∣
y
(
i
)
)
P
(
y
(
i
)
)
]
基于条件独立性假设,
x
(
i
)
x^{(i)}
x(i)的任意一个维度均服从一个概率分布,则有:
P
(
x
(
i
)
∣
y
(
i
)
)
=
∏
j
=
1
p
P
(
x
j
(
i
)
∣
y
(
i
)
)
P(x^{(i)} \mid y^{(i)}) = \prod_{j=1}^p P(x_j^{(i)} \mid y^{(i)})
P(x(i)∣y(i))=j=1∏pP(xj(i)∣y(i))
将基于条件独立性假设的
P
(
x
(
i
)
∣
y
(
i
)
)
P(x^{(i)} \mid y^{(i)})
P(x(i)∣y(i))带入上式,则有:
L
(
θ
)
=
∑
i
=
1
N
{
log
[
P
(
x
(
i
)
∣
y
(
i
)
)
]
+
log
[
P
(
y
(
i
)
)
]
}
=
∑
i
=
1
N
{
log
[
∏
j
=
1
p
P
(
x
j
(
i
)
∣
y
(
i
)
)
]
+
log
[
P
(
y
(
i
)
)
]
}
=
∑
i
=
1
N
{
∑
j
=
1
p
log
[
P
(
x
j
(
i
)
∣
y
(
i
)
)
]
+
log
[
P
(
y
(
i
)
)
]
}
最后将对应假设的
P
(
x
j
(
i
)
∣
y
(
i
)
)
,
P
(
y
(
i
)
)
P(x_j^{(i)} \mid y^{(i)}),P(y^{(i)})
P(xj(i)∣y(i)),P(y(i))的分布带入,对
L
(
θ
)
\mathcal L(\theta)
L(θ)进行极大似然估计即可。
θ
^
=
arg
max
θ
L
(
θ
)
\hat {\theta} = \mathop{\arg\max}\limits_{\theta} \mathcal L(\theta)
θ^=θargmaxL(θ)
实例解析
对于朴素贝叶斯分类器中的条件独立性假设十分抽象,这里我们反过来思考:什么样的样本能够完整符合朴素贝叶斯分类器的全部要求?
这里以机器学习(周志华著)的西瓜数据集3.0为例,从样本的角度观察条件独立性假设以及各维度的概率分布情况。
西瓜数据集3.0共包含17个样本。具体数据表示如下:
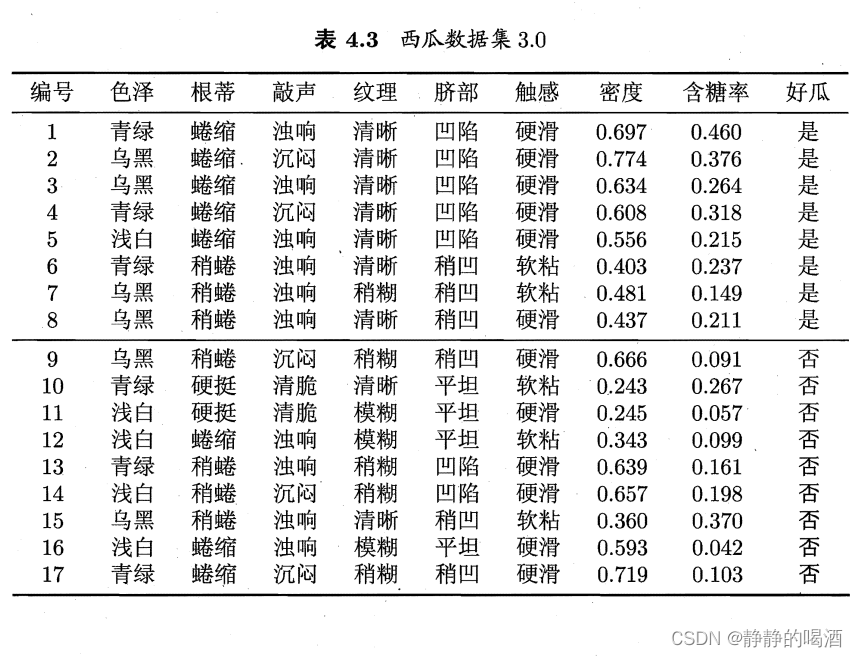
- 该样本中包含2个类别的标签:好瓜 = 是,好瓜 = 否;
- 数据集合中一共包含8个维度的样本特征。在这里我们暂时认为样本特征之间相互独立(各维度特征之间可能存在因果关系(关联关系),我不是领域专家,我不懂~);
- 观察各维度样本特征,有的是服从伯努利分布,如触感特征;有的是服从分类分布,如色泽特征,不仅包含离散型随机变量,密度、含糖率均为连续型随机变量;
至此,线性分类模型系列暂时结束,下面将介绍新的系列,一种特殊的硬分类模型——支持向量机(Support Vector Machine,SVM)
相关参考:
机器学习(周志华著)
机器学习-线性分类9-朴素贝爷斯分类器(Naive Bayes Classifier)

