
热门标签
热门文章
- 1268-C++ 红黑树RBTree_c++ rbtree
- 2解决Docker镜像拉取失败问题_docker拉取镜像失败
- 3程序员需要的各种PDF格式电子书_程序员书籍pdf
- 4python文件读写_python open(flog,encoding='utf-8').readlines()[165
- 5将AI的潜能转化为人类的福祉
- 6Pytorch Lightning实现BertNER:Bert模型如何集成进NER中_bert4torch用来做ner的数据集怎么处理
- 7基于Java+Spring+Vue超市库存管理系统设计和实现_超市仓库管理系统vue
- 8使用 Kafka 保证消息不丢失的策略及原理解析_kafk 消息监听处理后未消失
- 9计算机行业新技术 —— 区块链
- 10Java面试指导_java面试辅导
当前位置: article > 正文
Python学习——八、文件读取、写入_python 读取文件写入文件
作者:小桥流水78 | 2024-07-13 16:39:37
赞
踩
python 读取文件写入文件

- # 一、读取文件
- # open(file, mode, encoding)
- # mode: r w a
- f = open("E:/jupyter/hwdata2a.csv", "r", encoding="UTF-8")
- print(type(f))
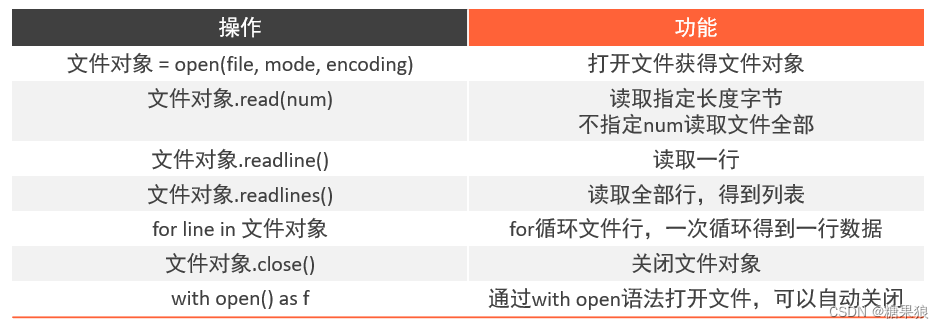
- print(f"读取10字节的结果:{f.read(10)}")
- # 多次read,下一个read会在上一个之后接着读取
- print(f"read方法读取全部内容的结果:{f.read()}")
-
- # 读取全部行,封装到列表中
- lines = f.readlines()
- print(f"lines对象的类型是:{type(lines)}")
- print(f"lines对象的类容是:{lines}")
-
- # 每次读取一行
- line1 = f.readline()
- line2 = f.readline()
- print(f"第一行内容是:{line1}")
- print(f"第二行内容是:{line2}")
-
- # for循环读取每一行
- for line in f:
- print(f"每一行数据是:{line}")
-
- # 二、关闭文件
- f.close()
- # 读取完自动关闭文件
- with open("E:/jupyter/hwdata2a.csv", "r", encoding="UTF-8") as f:
- for line in f:
- print(f"文件的每一行是:{line}")
-
- # 案例:字符数量统计
- # 方法一
- f = open("C:/Users/LUO/Desktop/word.txt", "r", encoding="UTF-8")
- content = f.read()
- count = content.count("itheima")
- print(f"itheima在文件中出现了:{count}次")
- f.close()
- # 方法二
- f = open("C:/Users/LUO/Desktop/word.txt", "r", encoding="UTF-8")
- count = 0
- for line in f:
- line = line.strip() # 去除开头结尾的空格以及换行符
- words = line.split(" ")
- print(words)
- # 统计次数
- for word in words:
- if word == "itheima":
- count += 1
- print(f"itheima出现的次数是:{count}次")
- f.close()


- # 三、文件的写入
- # 1.w方法
- f = open("C:/Users/LUO/Desktop/accpt.txt", "w", encoding="UTF-8")
- # 文件不存在会创建文件,文件存在会把原来的内容清空然后写入
- f.write("你好,吉吉国王") # 将内容写入内存中,而不是在文件中
- f.flush()
- f.close() # close方法内置了flush功能
-
- # 2.文件的追加:a方法
- f = open("C:/Users/LUO/Desktop/test.txt", "a", encoding="UTF-8")
- # 文件不存在会创建文件,文件存在会把原来的内容清空然后写入
- f.write("\n你好,吉吉国王") # 将内容写入内存中,而不是在文件中
- f.close() # close方法内置了flush功能

- # 文件操作综合案例
- # 1.读取
- fr = open("C:/Users/LUO/Desktop/test.txt", "r", encoding="UTF-8")
- # 2.写入
- fw = open("C:/Users/LUO/Desktop/bill.txt.bak", "w", encoding="UTF-8")
- for line in fr:
- line = line.strip()
- if line.split(",")[-1] == "测试":
- continue #进入下一次循环,这一次后面的就跳过啦
- fw.write(line)
- # 由于换行符不见了,所以要加上换行符
- fw.write("\n") # 还在内存中不会清空原来的内容
-
- fr.close()
- fw.close()
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/小桥流水78/article/detail/820505
推荐阅读

相关标签

