
- 1Git | Git入门,成为项目管理大师(一)_git 的作者
- 2Flink消费pubsub问题_flink pubsubsource
- 3【原创】JavaWeb仓库管理系统(Web仓库管理系统毕业设计)_java仓库管理系统
- 4java.io.FileNotFoundException: java.io.FileNotFoundException: HADOOP_HOME and hadoop.home.dir are un_windows java.io.filenotfoundexception: java.io.fil
- 5程序员的浪漫——给她专属的圣诞树_程序员给树命名
- 6使用Llamafile在本地运行LLM模型_tinyllama本地运行
- 7C语言数据结构——快速排序和归并排序_c语言数据结构快速排序
- 8HTML5 音频 Audio 标签详解_h5 audio标签
- 9Flink实现kafka到kafka、kafka到doris的精准一次消费_flink kafka doris
- 10存在 ZooKeeper 未授权访问【原理扫描】--通过防火墙策略进行修复
AI绘画入门教程(非常详细)从零基础入门到精通,看完这一篇就够了_ai绘画教程
赞
踩
AI绘画的出现,让越来越多的人可以轻松画出美丽的插画作品。在本篇文章中,我们将会使用AI绘画软件:触站,轻松创建属于自己的作品。从零开始学AI绘画!
从零开始学AI绘画关键步骤:
第一步:下载软件
首先,我们需要下载一个非常好用的AI绘画软件。AI绘画功能也十分强大,能够帮助零基础小白快速生成精美的作品。
第二步:准备素材
在使用AI绘画软件之前,我们需要准备一些素材。如果您想要创作人物插画,可提前准备好所需要的角色形象、服饰、背景等元素。如果您想要创作风景插画,可准备好所需的城市或自然景色等元素。这些素材将成为我们创作作品的重要基础。
第三步:选择AI绘画功能
打开软件后,在页面上能够看到AI绘画选项。点击AI绘画之后,会弹出AI绘画的选择界面。在此菜单中,我们可以根据自己的需求,选择不同的AI绘画分类,例如人物、风景、卡通等。然后选择AI绘画素材。
第四步:调整参数
在选择了所需的素材后,我们需要根据实际需求调整一些参数。比如说,我们可以调整线条或色彩的明暗度,来达到更逼真、炫酷或柔和的效果。设置好参数后,点击“生成”按钮,等待片刻,AI就能帮助我们生成一张美丽的插画作品。
第五步:保存作品
在成功生成插画作品之后,我们需要保存缩小版到本地。在这个过程中,我们可以选择画质、尺寸、格式等信息。推荐选择高清晰度和较大的尺寸,让我们的作品更加生动,满足所需输出比例。
人工智能技术为画师们提供了更简单、更快捷的画画方法,使得任何人都可以轻松地创造出自己想要的插画作品。在使用AI绘画软件时,我们需要提前准备好素材,根据实际需求调整AI的参数,然后保存作品。另外,不断地学习和尝试,能够帮助我们不断优化自己的作品,成为更加优秀的艺术家。
Stable Diffusion无疑是最近最火的AI绘画工具之一,所以本期给大家带来了全新Stable Diffusion 升级版资料包(文末可获取)
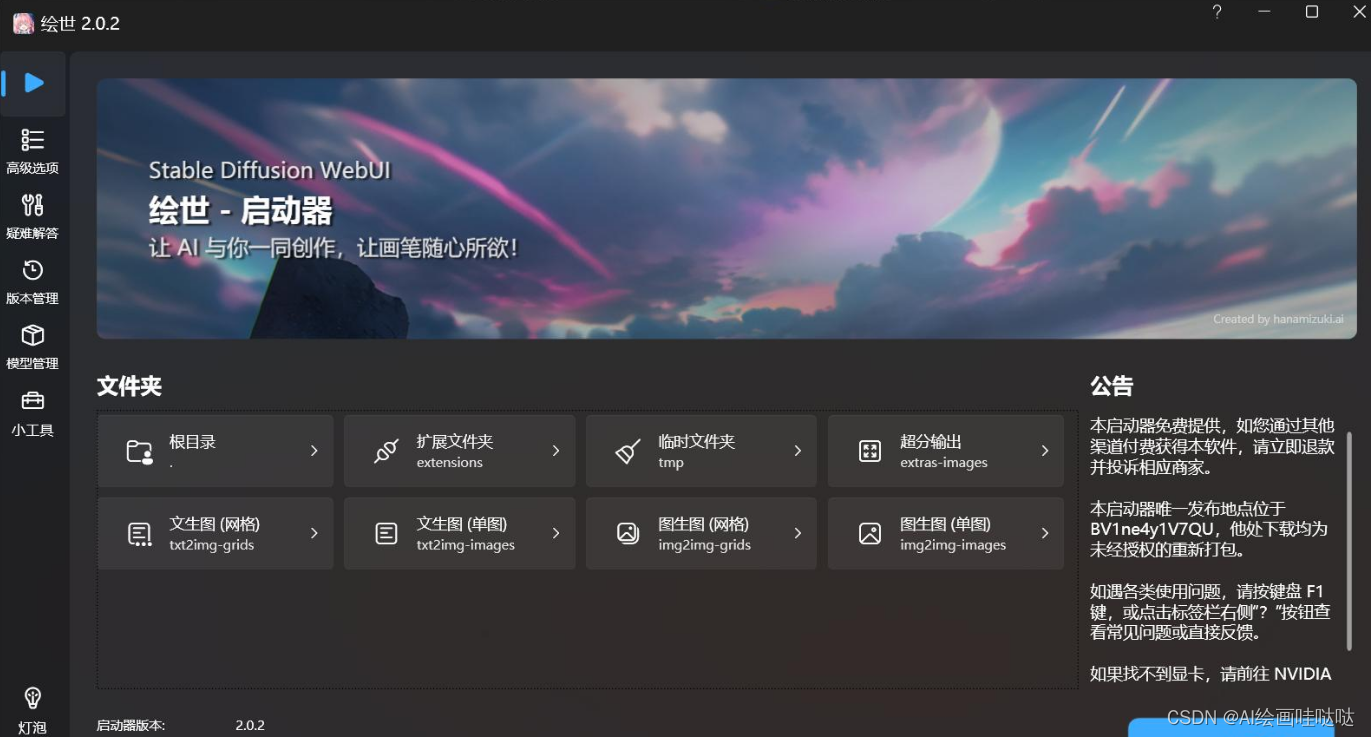
01 新版本一键安装启动软件
02 AI绘画基础+速成+进阶使用教程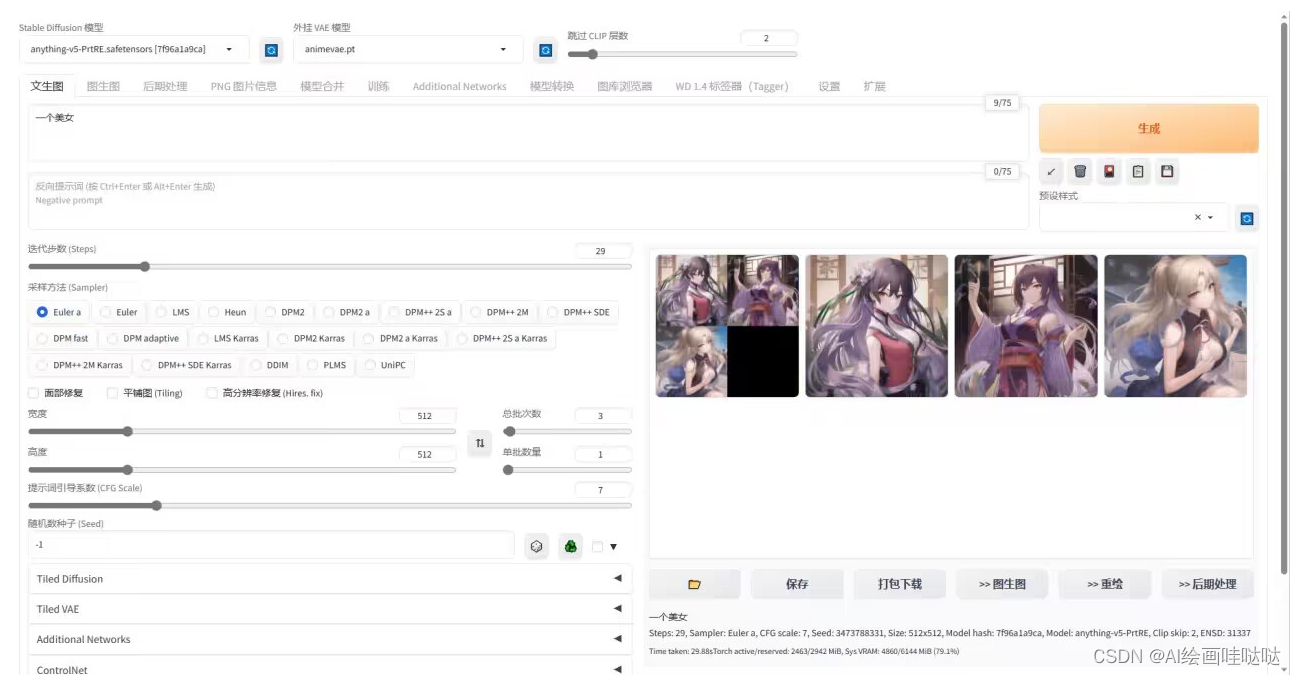
AI 绘画工具的部署安装
以下主要介绍三种部署安装方式:云端部署、本地部署、本机安装,各有优缺点。当本机硬件条件支持的情况下,推荐本地部署,其它情况推荐云端方式。
1.云端部署 Stable Diffusion
通过 Google Colab 进行云端部署,推荐将成熟的 Stable Diffusion Colab 项目复制到自己的 Google 云端硬盘运行,省去配置环境麻烦。这种部署方式的优点是: 不吃本机硬件,在有限时间段内,可以免费使用 Google Colab 强大的硬件资源,通常能给到 15G 的 GPU 算力,出图速度非常快。缺点是: 免费 GPU 使用时长不固定,通常情况下一天有几个小时的使用时长,如果需要更长时间使用,可以订阅 Colab 服务

Stable Diffusion WebUl 运行界面如下,在后面的操作方法里我会介绍下 Stable Diffusion
的基础操作。
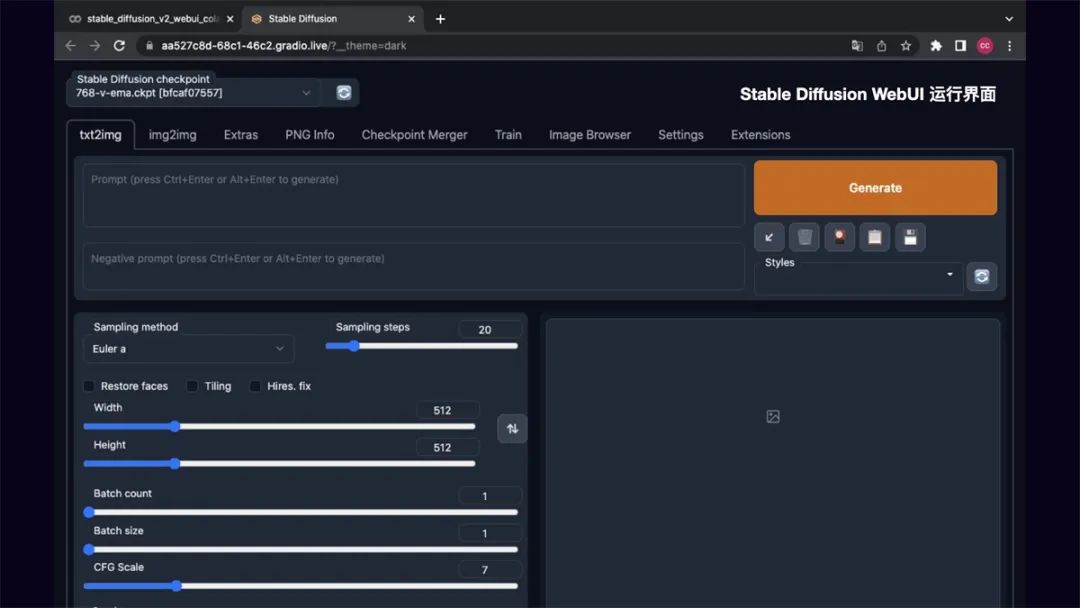
2.本地部署 Stable Diffusion
相较于 Google Colab 云端部署,本地部署 Stable Diffusion 的可扩展性更强,可自定义安装需要的模型和插件,隐私性和安全性更高,自由度也更高,而且完全免费。当然缺点是对本机硬件要求高,Windows 需要 NVIDIA 显卡,8G 以上显存,16G 以上内存。Mac 需要M1/M2 芯片才可运行。

3.本机安装 DiffusionBee
如果觉得云端部署和本地部署比较繁琐,或对使用要求没有那么高,那就试下最简单的一键安装方式。
下载 Diffusionbee 应用: diffusionbee.com/download。
优点是方便快捷,缺点是扩展能力差(可以安装大模型,无法进行插件扩展,如 ControlNet) 。

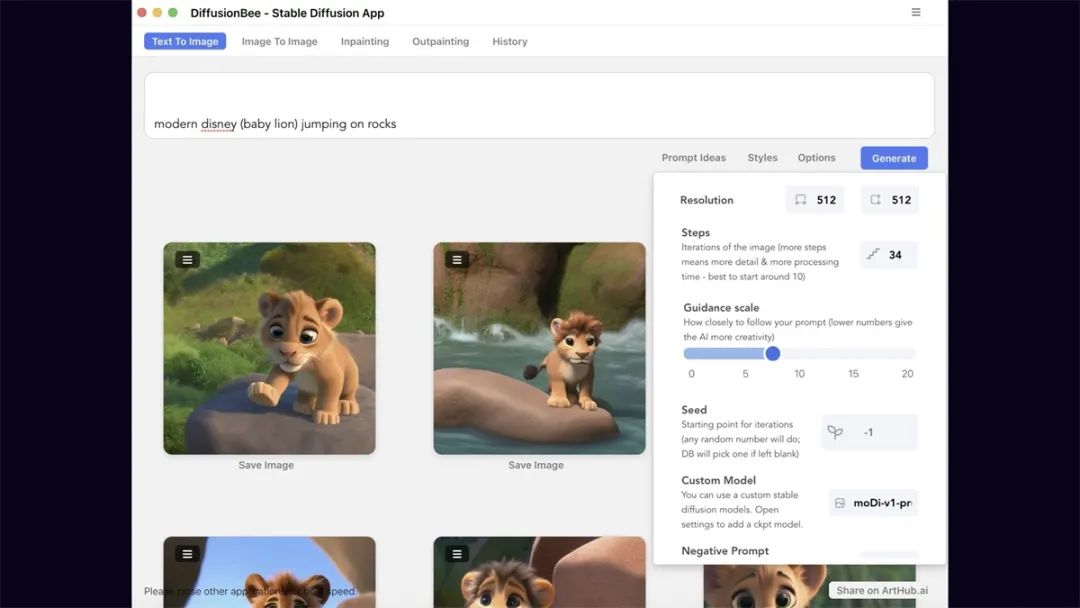
3、AI 绘画工具的操作技巧
1.Stable Diffusion 基础操作
文生图
如图所示 Stable Diffusion WebUl 的操作界面主要分为: 模型区域、功能区域、参数区域出图区域
txt2img 为文生图功能,重点参数介绍:
正向提示词: 描述图片中希望出现的内容
反向提示词: 描述图片中不希望出现的内容
Sampling method: 采样方法,推荐选择 Euler a 或 DPM++ 系列,采样速度快
Sampling steps: 迭代步数,数值越大图像质量越好,生成时间也越长,一般控制在 30-50就能出效果
Restore faces: 可以优化脸部生成
Width/Height: 生成图片的宽高,越大越消耗显存,生成时间也越长,一般方图 512x512竖图 512x768,需要更大尺寸,可以到 Extras 功能里进行等比高清放大
CFG: 提示词相关性,数值越大越相关,数值越小越不相关,一般建议 7-12 区间
Batch count/Batch size: 生成批次和每批数量,如果需要多图,可以调整下每批数量
Seed: 种子数,-1 表示随机,相同的种子数可以保持图像的一致性,如果觉得一张图的结构不错,但对风格不满意,可以将种子数固定,再调整 prompt 生成

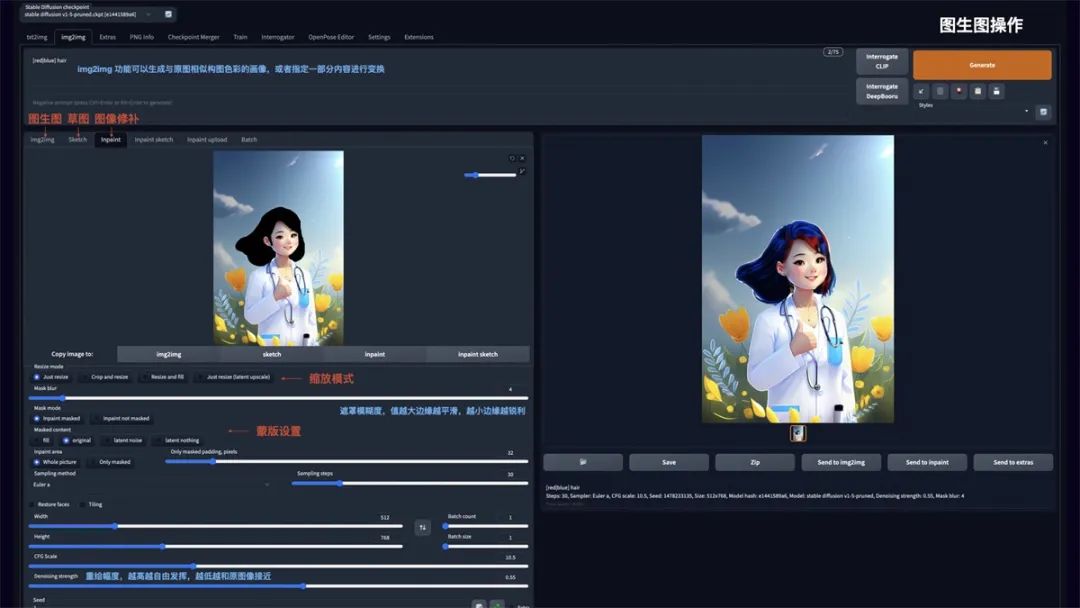
图生图
img2img 功能可以生成与原图相似构图色彩的画像,或者指定一部分内容进行变换。可以重点使用 Inpaint 图像修补这个功能:
Resize mode: 缩放模式,Just resize 只调整图片大小,如果输入与输出长宽比例不同,图片会被拉伸。Crop and resize 裁剪与调整大小,如果输入与输出长宽比例不同,会以图片中心向四周,将比例外的部分进行裁剪。Resize and fill 调整大小与填充,如果输入与输出分辨率不同,会以图片中心向四周,将比例内多余的部分进行填充
Mask blur: 蒙版模糊度,值越大与原图边缘的过度越平滑,越小则边缘越锐利
Mask mode: 蒙版模式,Inpaint masked 只重绘涂色部分,Inpaint not masked 重绘除了涂色的部分
Masked Content: 蒙版内容,fill 用其他内容填充,original 在原来的基础上重绘
Inpaint area: 重绘区域,Whole picture 整个图像区域,Only masked 只在蒙版区域
Denoising strength: 重绘幅度,值越大越自由发挥,越小越和原图接近
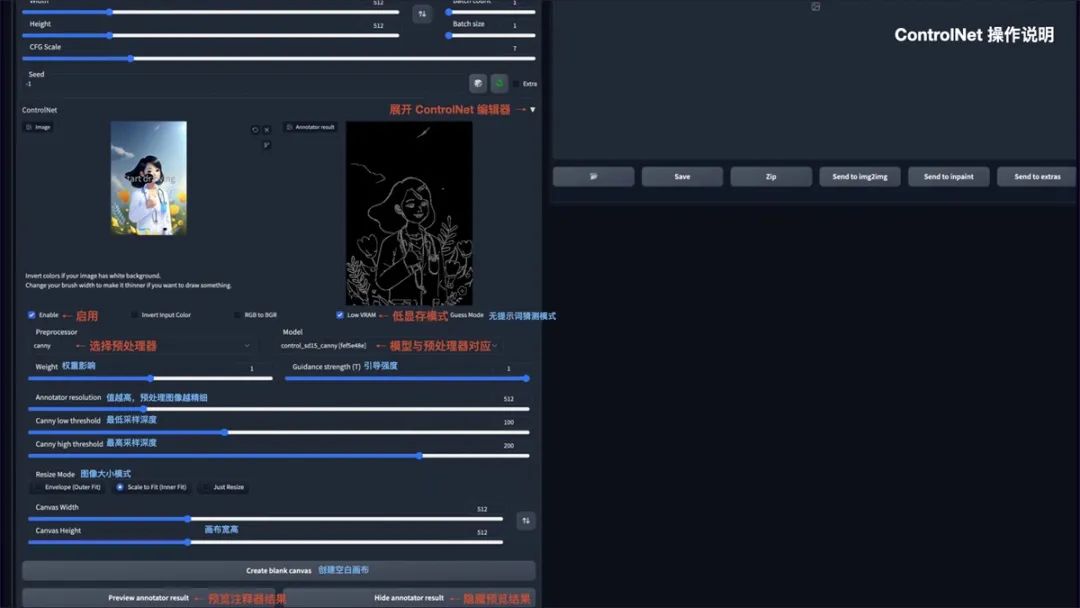
ControlNet
安装完 ControlNet 后,在 txt2img 和 img2img 参数面板中均可以调用 ControlNet。操作说明:
Enable: 启用 ControlNet
Low VRAM: 低显存模式优化,建议 8G 显存以下开启
Guess mode: 猜测模式,可以不设置提示词,自动生成图片
Preprocessor: 选择预处理器主要有 OpenPose、Canny、HED、Scribble、MIsd.Seg、Normal Map、Depth
Model: ControlNet 模型,模型选择要与预处理器对应
Weight: 权重影响,使用 ControlNet 生成图片的权重占比影响
Guidance strength(T): 引导强度,值为 1时,代表每选代 1 步就会被 ControlNet引导1次
Annotator resolution: 数值越高,预处理图像越精细Canny low/high threshold: 控制最低和最高采样深度Resize mode: 图像大小模式,默认选择缩放至合适
Canvas width/height: 画布宽高
Create blank canvas: 创建空白画布
Preview annotator result: 预览注释器结果,得到一张 ControlNet 模型提取的特征图片
Hide annotator result: 隐藏预览图像窗
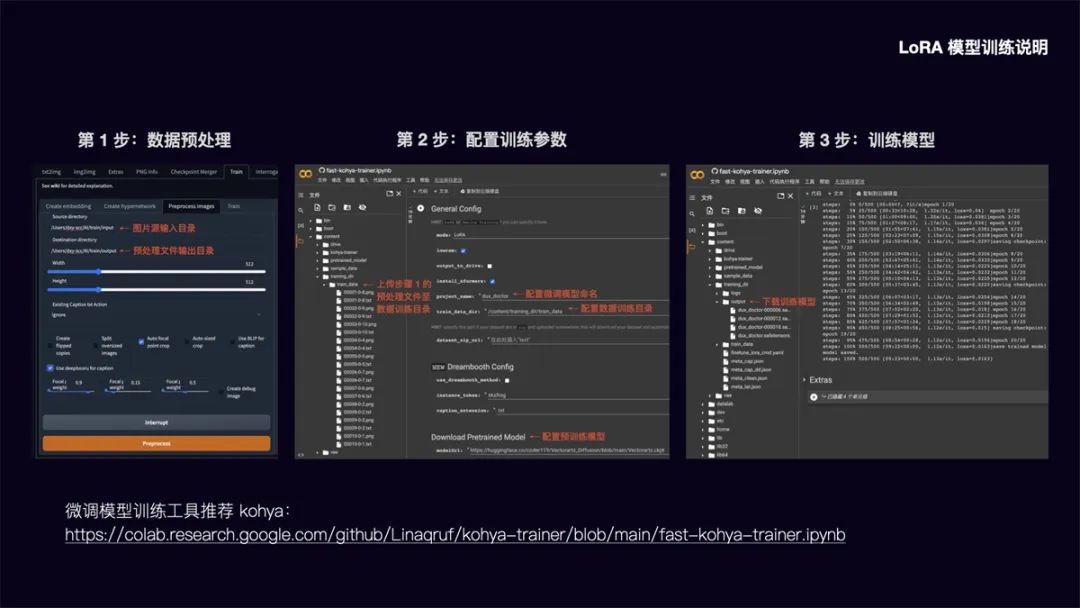
LORA 模型训练说明
前面提到 LORA 模型具有训练速度快,模型大小适中 (100MB 左右),配置要求低 (8G 显存),能用少量图片训练出风格效果的优势。
以下简要介绍该模型的训练方法:
第 1步:数据预处理
在Stable Diffusion WebUl 功能面板中,选择 Train 训练功能,点选 Preprocess images 预处理图像功能。在 Source directory 栏填入你要训练的图片存放目录,在 Destinationdirectory 栏填入预处理文件输出目录。width 和 height 为预处理图片的宽高,默认为512x512,建议把要训练的图片大小统一改成这个尺寸,提升处理速度。勾选 Auto focalpoint crop 自动焦点裁剪,勾选 Use deepbooru for caption 自动识别图中的元素并打上标签。点击 Preprocess 进行图片预处理。
第 2 步: 配置模型训练参数
在这里可以将模型训练放到 Google Colab 上进行,调用 Colab 的免费 15G GPU 将大大提升模型训练速度。LoRA 微调模型训练工具我推荐使用 Kohya,运行
KohyaColab: https://colab.research.google.com/github/Linaqruf/kohyatrainer/blob/main/fast-kohya-traineripynb
配置训练参数
先在 content 目录建立 training_dir/training_data 目录,将步骤 1 中的预处理文件上传至该数据训练目录。然后配置微调模型命名和数据训练目录,在 Download Pretrained Model 栏配置需要参考的预训练模型文件。其余的参数可以根据需要调整设置。
第 3 步: 训练模型
参数配置完成后,运行程序即可进行模型训练。训练完的模型将被放到 training dir/output目录,我们下载 safetensors 文件格式的模型,存放到 stable-diffusion-webui/models/Lora 日录中即可调用该模型。由于直接从 Colab 下载速度较慢,另外断开Colab 连接后也将清空模型文件,这里建议在 Extras 中配置 huggingface 的 Write Token.将模型文件上传到 huggingface 中,再从 huggingface File 中下载,下载速度大大提升,文件也可进行备份。
2.Prompt 语法技巧
文生图模型的精髓在于 Prompt 提示词,如何写好 Prompt 将直接影响图像的生成质量
提示词结构化
Prompt 提示词可以分为 4 段式结构: 质风 + 面主体 + 面细节 + 风格参考画面画风: 主要是大模型或 LORA 模型的 Tag、正向画质词、画作类型等画面主体: 画面核心内容、主体人/事/物/景、主体特征/动作等
画面细节: 场景细节、人物细节、环境灯光、画面构图等
风格参考: 艺术风格、渲染器、Embedding Tag 等

提示词语法
提示词排序:越前面的词汇越受 AI 重视,重要事物的提示词放前面
增强/减弱: (提示词:权重数值),默认 1,大于 1 加强,低于 1 减弱。如(doctor:1.3)混合: 提示词|提示词,实现多个要素混合,如[red blue] hair 红蓝色头发混合
+ 和 AND: 用于连接短提示词,AND 两端要加空格
分步染:[提示词 A:提示词 B:数值],先按提示词 A 生成,在设定的数值后朝提示词 B 变化。如[dog
Copyright © 2003-2013 www.wpsshop.cn 版权所有,并保留所有权利。

