
- 1测试开发 | 词嵌入(Word Embeddings):赋予语言以向量的魔力_词嵌入是将词汇表中的每个词映射到
- 2OpenMV:21控制多个舵机(需要模块PCA9685)_openmv控制双舵机
- 3AIGC内容分享(五十五):AIGC周刊
- 4在NVIDIA Orin中编译Apollo 9_apollo 9.0 orin
- 5大数据项目在线实习_数据测试员实习项目
- 6Elasticsearch 未授权访问_elasticsearch未授权访问
- 7【推荐系统】DeepFM模型分析
- 8跟着我,在PS里成功装上SD插件(终极教程!附基本操作步骤)_ps sd插件
- 9stm32+cubemx+淘晶驰串口屏+收发通信并应用_stm32驱动陶晶驰x系列串口屏
- 10原生php开发学生信息管理系统源码_php学生信息管理系统源代码
【网络安全运维】yarn高可用配置详解_applicationmaster配置
赞
踩
文章目录
-
- 一. 架构
-
- 1. RM故障转移( Failover)
-
- 1.1. 手动切换故障转移
- 1.2. 自动故障转移
- 1.3. RM故障转移的客户端:ApplicationMaster和NodeManager
- 2. 恢复以前的活动RM的状态
- 二、部署方式
-
- 1. 配置说明
- 2. 配置实例
- 3. Admin commands
-
- a. 检查状态
- b. 手动切换主备
本文主要描述了:
- yarn HA架构细节:active/standby、故障转移的方式、故障转移客户端
- 怎么恢复之前提交的任务
- 怎么部署配置YARN HA
- 手动切换主备
一. 架构
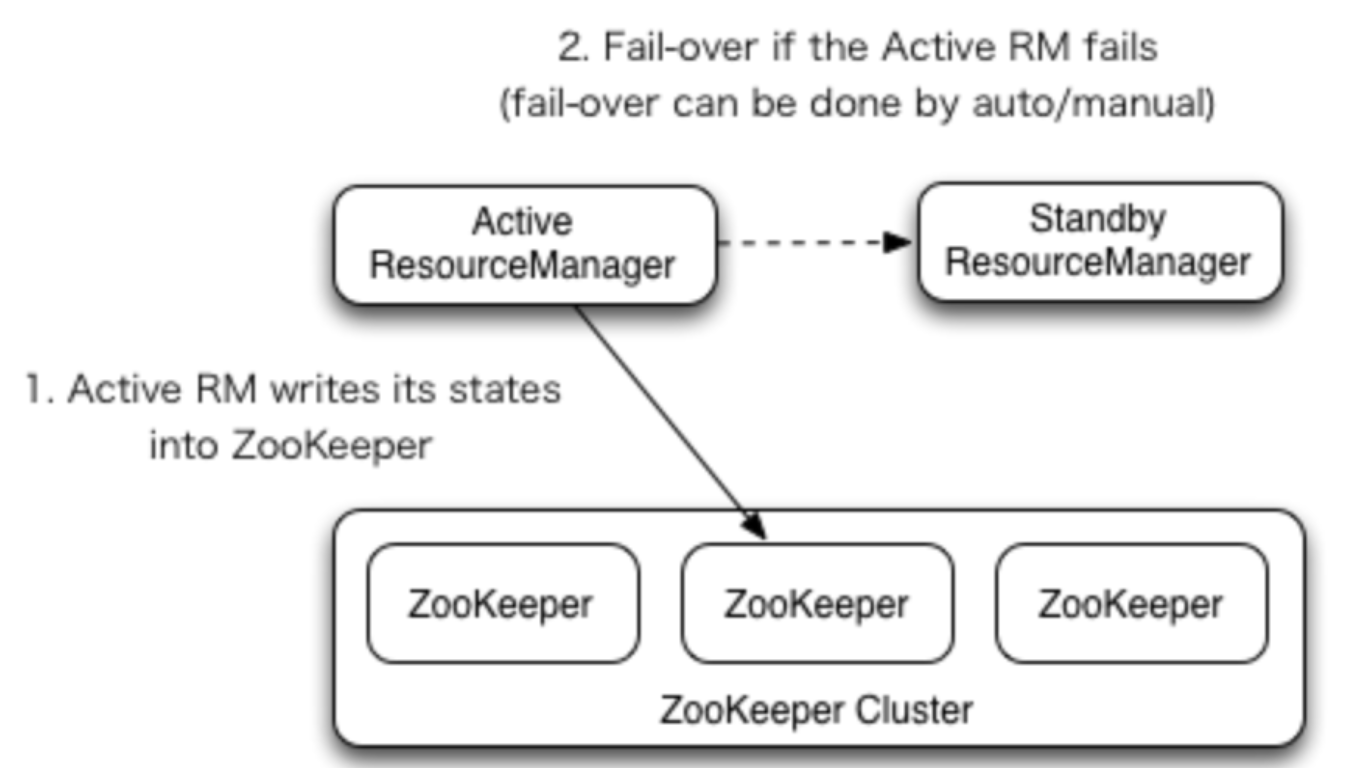
1. RM故障转移( Failover)
ResourceManager HA通过Active / Standby体系结构实现-在任何时间,RM之一都处于活动状态,并且一个或多个 RM处于Standby模式,等待切换为active。启用自动故障转移后,通过admin(通过CLI:手动)或 failover-controller (自动) 将RM转换为active。
1.1. 手动切换故障转移
如果未启用自动故障转移,管理员必须通过手动的方式将其中一个RM转换为Active。要从一个RM到另一个RM进行故障转移,应该先将Active-RM转换为Standby,然后将Standby-RM转换为Active。所有这些可以使用“ yarn rmadmin ” CLI完成。
1.2. 自动故障转移
RM可以选择嵌入基于Zookeeper的ActiveStandbyElector来确定哪个RM是Active。当Active发生故障或无响应时,另一个RM被自动选为Active,然后接管。请注意,无需像HDFS那样运行单独的ZKFC守护程序,因为嵌入在RM中的ActiveStandbyElector充当了故障检测器和领导选举人,而不是单独的ZKFC守护进程。
1.3. RM故障转移的客户端:ApplicationMaster和NodeManager
当有多个RM时,预计客户端和节点使用的配置(yarn-site.xml)会列出所有RM。客户端,ApplicationMaster(AM)和NodeManager(NM)尝试以循环方式连接到RM,直到它们到达活动RM。如果活动服务器出现故障,他们将继续轮询,直到命中“新”活动服务器为止。
默认重试逻辑实现为
org.apache.hadoop.yarn.client.ConfiguredRMFailoverProxyProvider。
可以通过实现org.apache.hadoop.yarn.client.RMFailoverProxyProvider并设置yarn.client.failover-proxy-provider:(实现类名)来覆盖默认重试逻辑。
2. 恢复以前的活动RM的状态
启用yarn.resourcemanager.recovery.enabled(ResourceManagerRestart)后,RM变为active后,它会加载RM的内部状态,并尽可能地处理之前active未处理的请求。
对于之前提交给RM的托管任务,晋升的RM都会重新尝试运行这些任务。
Applications可以定期检查来避免丢失任何任务。
RMStateStore
- Active RM和Standby RM要都能访问状态存储。
- 目前,对RMStateStore的实现有两种FileSystemRMStateStore和ZKRMStateStore。
- ZKRMStateStore隐式允许在任何时间点对单个RM进行写访问,因此建议在HA群集中使用该存储。使用ZKRMStateStore时,无需使用单独的防护机制来解决潜在的裂脑情况,在这种情况下,多个RM可以潜在地充当主动角色。
tips
使用ZKRMStateStore时,建议不要在Zookeeper群集上设置“ zookeeper.DigestAuthenticationProvider.superDigest ”属性,以确保Zookeeper管理员无法访问YARN应用程序/用户凭证信息。
二、部署方式
1. 配置说明
| 配置属性 | 描述 |
|---|---|
| hadoop.zk.address | ZK仲裁的地址。用于状态存储和leader选举。 |
| yarn.resourcemanager.ha.enabled | 启用RM HA。 |
| yarn.resourcemanager.ha.rm-ids | RM的逻辑ID列表。例如“ rm1,rm2”。 |
| yarn.resourcemanager.hostname.rm-id | 对于每个_rm-id_,指定RM对应的主机名。或者,可以设置RM的每个服务地址。 |
| yarn.resourcemanager.address.rm-id | 对于每个rm-id,请指定host:port以便客户端提交作业。如果设置,将覆盖yarn.resourcemanager.hostname中设置的主机名。rm-id。 |
| yarn.resourcemanager.scheduler.address.rm-id | 对于每个rm-id,为ApplicationMasters指定调度程序host:port以获得资源。如果设置,将覆盖yarn.resourcemanager.hostname中设置的主机名。rm-id。 |
| yarn.resourcemanager.resource-tracker.address.rm-id | 对于每个rm-id,请指定host:port以供NodeManagers连接。如果设置,将覆盖yarn.resourcemanager.hostname中设置的主机名。 |
| yarn.resourcemanager.admin.address.rm-id | 对于每个rm-id,为管理(administrative)命令指定host:port。如果设置,将覆盖yarn.resourcemanager.hostname中设置的主机名。 |
| yarn.resourcemanager.webapp.address.rm-id | 对于每个rm-id,指定RM Web应用程序对应的host:port。如果将yarn.http.policy设置为HTTPS__ONLY,则不需要此选项。如果设置,将覆盖yarn.resourcemanager.hostname中设置的主机名。rm-id。 |
| yarn.resourcemanager.webapp.https.address.rm-id | 对于每个_rm-id_,请指定RM https Web应用程序对应的host:port。你不需要这个,如果你设置yarn.http.policy到HTTP_ONLY。如果设置,将覆盖yarn.resourcemanager.hostname中设置的主机名。 |
| yarn.resourcemanager.ha.id | 在集合中标识RM。可选,不是必须;但是,如果已设置,必须确保所有的RM在配置中都具有自己的ID。 |
| yarn.resourcemanager.ha.automatic-failover.enabled | 启用自动故障转移;默认情况下,仅在启用HA时启用它。 |
| yarn.resourcemanager.ha.automatic-failover.embedded | 启用自动故障转移后,请使用leader-elector选择active RM。默认情况下,仅在启用HA时启用它。 |
| yarn.resourcemanager.cluster-id | 标识集群。由选民使用,以确保RM不会接替另一个群集的活动状态。 |
| yarn.client.failover-proxy-provider | 客户端,AM和NM用于故障转移到活动RM的类。 |
| yarn.client.failover-no-ha-proxy-provider | FailoverProxyProvider应该尝试故障转移的最大次数。 |
| yarn.client.failover-sleep-base-ms | 用于计算故障转移之间指数延迟的睡眠基准(以毫秒为单位)。 |
| yarn.client.failover-sleep-max-ms | 故障转移之间的最大睡眠时间(以毫秒为单位)。 |
| yarn.client.failover-retries | 每次尝试连接到ResourceManager的重试次数。 |
| yarn.client.failover-retries-on-socket-timeouts | 套接字超时时每次尝试连接到ResourceManager的重试次数。 |
| yarn.client.failover-max-attempts | 故障转移最多尝试次数。 |
2. 配置实例
<property> <name>yarn.resourcemanager.ha.enabled</name> <value>true</value> </property> <property> <name>yarn.resourcemanager.cluster-id</name> <value>cluster1</value> </property> <property> <name>yarn.resourcemanager.ha.rm-ids</name> <value>rm1,rm2</value> </property> <property> <name>yarn.resourcemanager.hostname.rm1</name> <value>master1</value> </property> <property> <name>yarn.resourcemanager.hostname.rm2</name> <value>master2</value> </property> <property> <name>yarn.resourcemanager.webapp.address.rm1</name> <value>master1:8088</value> </property> <property> <name>yarn.resourcemanager.webapp.address.rm2</name> <value>master2:8088</value> </property> <property> <name>hadoop.zk.address</name> <value>zk1:2181,zk2:2181,zk3:2181</value> </property>

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
3. Admin commands
yarn rmadmin有几个关于RM状态、健康状况、切换Active/Standby的命令:
HA id 由
yarn.resourcemanager.ha.rm-ids设置决定
a. 检查状态
$ yarn rmadmin -getServiceState rm1
active
$ yarn rmadmin -getServiceState rm2
standby
- 1
- 2
- 3
- 4
- 5
- 6
- 7
b. 手动切换主备
$ yarn rmadmin -transitionToStandby rm1
- 1
- 2
Automatic failover is enabled for org.apache.hadoop.yarn.client.RMHAServiceTarget@1d8299fd
Refusing to manually manage HA state, since it may cause a split-brain scenario or other incorrect state. If you are very sure you know what you are doing, please specify the forcemanual flag.
RMHAServiceTarget 不允许手动管理HA状态,因为这样可能造成脑裂。如果你确定,可以使用强制切换标识 forcemanual ,来切换主备。
学习计划安排
我一共划分了六个阶段,但并不是说你得学完全部才能上手工作,对于一些初级岗位,学到第三四个阶段就足矣~
这里我整合并且整理成了一份【282G】的网络安全从零基础入门到进阶资料包,需要的小伙伴可以扫描下方CSDN官方合作二维码免费领取哦,无偿分享!!!
如果你对网络安全入门感兴趣,那么你需要的话可以
点击这里
Copyright © 2003-2013 www.wpsshop.cn 版权所有,并保留所有权利。

