
- 1重温CLR(十二) 委托
- 2LLM大模型实战项目--基于Stable Diffusion的电商平台虚拟试衣
- 3GPT-4o mini 比gpt-3.5更便宜(2024年7月18日推出)
- 4Git实战攻略:分支、合并与提交技巧_git合并分支提交分支
- 5银河麒麟V10桌面操作系统安装教程_银河麒麟操作系统v10
- 6tensorflow 车牌识别项目(一)_车牌定位的标签文件时json吗
- 7单链表(二)_建立一个非递减有序单链表(不少于5个元素结点),输出该链表中重复的元素以及重复次
- 8在安卓手机上用termux安装完整kali linux的办法_安卓完整linux
- 9 [推荐]dotNET中进程间同步/通信的经典框架_christoph ruegg
- 10平衡二叉树与java实现_java实现平衡二叉树
Hadoop之Yarn 详细教程
赞
踩
1、yarn 的基本介绍和产生背景
YARN 是 Hadoop2 引入的通用的资源管理和任务调度的平台,可以在 YARN 上运行
MapReduce、Tez、Spark 等多种计算框架,只要计算框架实现了 YARN 所定义的
接口,都可以运行在这套通用的 Hadoop 资源管理和任务调度平台上。
yarn 的优点:
-
支持多种计算框架
YARN 是通用的资源管理和任务调度平台,只要实现了 YARN 的接口的计算框架都可以运行在 YARN 上。 -
资源利用率高
多种计算框架可以共用一套集群资源,让资源充分利用起来,提高了利用率。 -
运维成本低
避免一个框架一个集群的模式,YARN 降低了集群的运维成本。 -
数据可共享
共享集群模式可以让多种框架共享数据和硬件资源,减少数据移动带来的成本
2、yarn 集群的架构和工作原理
YARN 的基本设计思想是将 MapReduce V1 中的 JobTracker 拆分为两个独立的服务:ResourceManager 和 ApplicationMaster。ResourceManager 负责整个系统的资源管理和分配,ApplicationMaster 负责单个应用程序的的管理
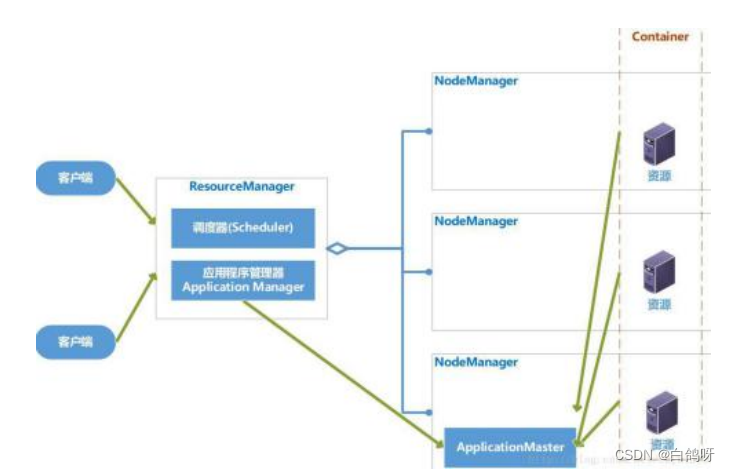
ResourceManager
RM 是一个全局的资源管理器,负责整个系统的资源管理和分配,它主要由两个部分组成:调度器(Scheduler)和应用程序管理器(Application Manager)。
调度器根据容量、队列等限制条件,将系统中的资源分配给正在运行的应用程序,在保证容量、公平性和服务等级的前提下,优化集群资源利用率,让所有的资源都被充分利用 。应用程序管理器负责管理整个系统中的所有的应用程序,包括应用程序的提交、与调度器协商资源以启动 ApplicationMaster、监控 ApplicationMaster 运行状态并在失败时重启它
ApplicationMaster
用户提交的一个应用程序会对应于一个 ApplicationMaster,它的主要功能有:
- 与 RM 调度器协商以获得资源,资源以 Container 表示。
- 将得到的任务进一步分配给内部的任务。
- 与 NM 通信以启动/停止任务。
- 监控所有的内部任务状态,并在任务运行失败的时候重新为任务申请资源以重启任务。
nodeManager
NodeManager 是每个节点上的资源和任务管理器
- 一方面,它会定期地向 RM 汇报本节点上的资源使用情况和各个 Container 的运行状态;
- 另一方面,他接收并处理来自 AM 的 Container 启动和停止请求。
container
Container 是 YARN 中的资源抽象,封装了各种资源。一个应用程序会分配一个Container,这个应用程序只能使用这个 Container 中描述的资源。
不同于 MapReduceV1 中槽位 slot 的资源封装,Container 是一个动态资源的划
分单位,更能充分利用资源。
3、Yarn 的任务提交流程
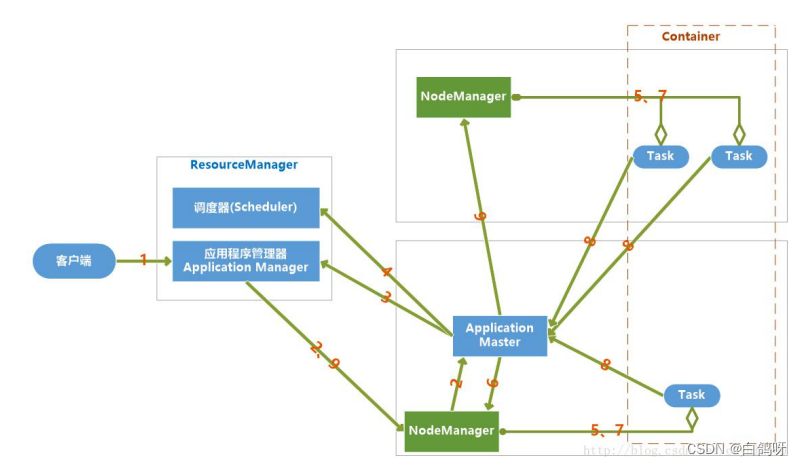
当 jobclient 向 YARN 提交一个应用程序后,YARN 将分两个阶段运行这个应用程序:一是启动 ApplicationMaster;第二个阶段是由 ApplicationMaster 创建应用程序,为它申请资源,监控运行直到结束。
具体步骤如下:
-
用户向 YARN 提交一个应用程序,并指定 ApplicationMaster 程序、启动ApplicationMaster 的命令、用户程序。
-
RM 为这个应用程序分配第一个 Container,并与之对应的 NM 通讯,要求它在这个Container 中启动应用程序 ApplicationMaster。
-
ApplicationMaster 向 RM 注册,然后拆分内部各个子任务,为各个内部任务申请资源,并监控这些任务的运行,直到结束。
-
AM 采用轮询的方式向 RM 申请和领取资源。
-
RM 为 AM 分配资源,以 Container 形式返回
-
AM 申请到资源后,便与之对应的 NM 通讯,要求 NM 启动任务。
-
NodeManager 为任务设置好运行环境,将任务启动命令写到一个脚本中,并通过运行这个脚本启动任务
-
各个任务向 AM 汇报自己的状态和进度,以便当任务失败时可以重启任务。
-
应用程序完成后,ApplicationMaster 向 ResourceManager 注销并关闭自己
4、RM功能介绍
1、ResourceManager 基本介绍
ResourceManager 负责集群中所有资源的统一管理和分配,它接收来自各个NodeManager 的资源汇报信息,并把这些信息按照一定的策略分配给各个ApplicationMaster。
2、RM 的职能
- 与客户端交互,处理客户端的请求。
- 启动和管理 AM,并在它运行失败时候重新启动它。
- 管理 NM,接收来自于 NM 的资源汇报信息,并向 NM 下达管理指令。
- 资源管理和调度,接收来自于 AM 的资源请求,并为它分配资源。
3、RM的内部结构
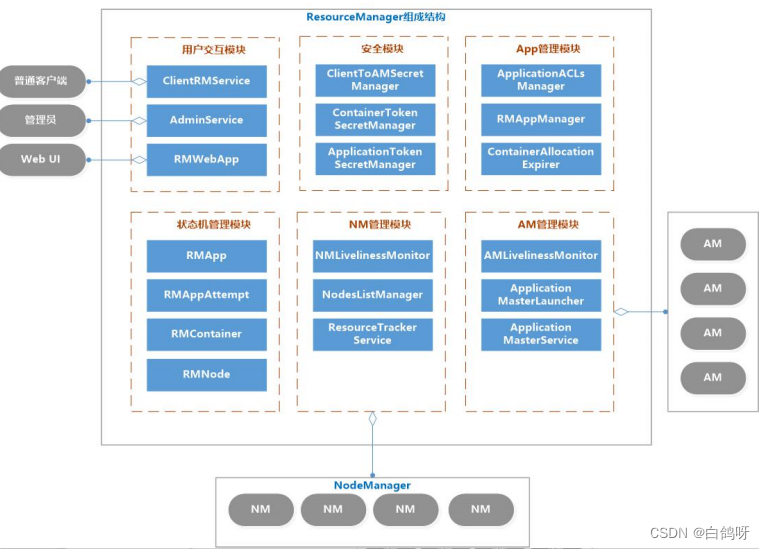
用户交互模块:
-
clientRMService : 为普通用户服务,处理请求,如:提交应用程序、终止程序、获取程序状态
-
adminService : 给管理员提供的服务。普通用户交互模块是 ClientRMService,管理员交互模块是 AdminService,之所以要将两个模块分开,用不同的通信通道发送给ResourceManager,是因为要避免普通用户的请求过多导致管理员请求被阻塞
-
WebApp : 更友好的展示集群资源和程序运行状态
NM 管理模块:
4. NMLivelinessMonitor : 监控 NM 是否活着,如果指定时间内未收到心跳,就从集群中移除。RM 会通过心跳告诉 AM 某个 NM 上的 Container 失效,如果 Am 判断需要重新执行,则 AM 重新向 RM 申请资源。
-
NodesListManager : 维护 inlude(正常)和 exlude(异常)的 NM 节点列表。默认情况下,两个列表都为空,可以由管理员添加节点。exlude 列表里的 NM 不允许与RM 进行通信。
-
ResourceTrackerService : 处理来自 NM 的请求,包括注册和心跳。注册是 NM 动
时的操作,包括节点 ID 和可用资源上线等。心跳包括各个 Container 运行状态,运行 Application 列表、节点健康状态
AM 管理模块:
-
AMLivelinessMonitor : 监控 AM 是否还活着,如果指定时间内没有接受到心跳,将正在运行的 Container 置为失败状态,而 AM 会被重新分配到另一个节点上
-
ApplicationMasterLauncher: 要求某一个 NM 启动 ApplicationMaster,它处理创建AM 的请求和 kill AM 的请求
-
ApplicationMasterService : 处理来自 AM 的请求,包括注册、心跳、清理。注册在 AM 启动时发送给 ApplicationMasterService 的;心跳是周期性的,包括请求资源的型、待释放的 Container 列表;清理是程序结束后发送给 RM,以回收资源清理内存空间;
Application 管理模块:
-
ApplicationACLLsManager : 管理应用程序的访问权限,分为查看权限和修改权限。
-
RMAppManager : 管理应用程序的启动和关闭
-
ContainerAllocationExpirer : RM 分配 Container 给 AM 后,不允许 AM 长时间不对Container 使用,因为会降低集群的利用率,如果超时(时间可以设置)还没有在NM 上启动 Container,RM 就强制回收 Container。
状态机管理模块:
-
RMApp : RMApp 维护一个应用程序的的整个运行周期,一个应用程序可能有多个实
例,RMApp 维护的是所有实例的 -
RMAppAttempt : RMAppAttempt 维护一个应用程序实例的一次尝试的整个生命周
期 -
RMContainer : RMContainer 维护一个 Container 的整个运行周期(可能和任务的周
期不一致) -
RMNode : RMNode 维护一个 NodeManager 的生命周期,包括启动到运行结束的整个过程。
安全模块:
RM 自带了全面的权限管理机制。主要由 ClientToAMSecretManager、ContainerTokenSecretManager、ApplicationTokenSecretManager 等模块组成。 资源
分配模块:
ResourceScheduler:ResourceScheduler 是资源调度器,他按照一定的约束条件将资源分配给各个应用程序。RM 自带了一个批处理资源调度器(FIFO)和两个多用户调度器 Fair Scheduler 和 Capacity Scheduler
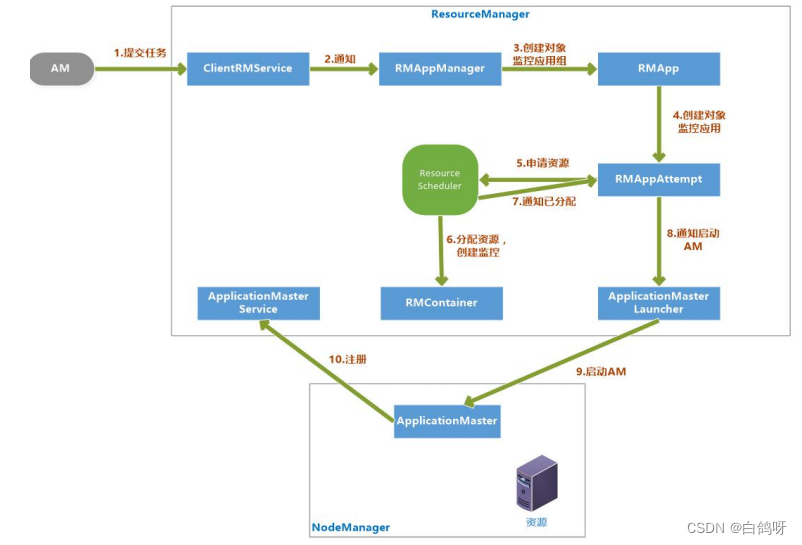
4、启动ApplicationMaster
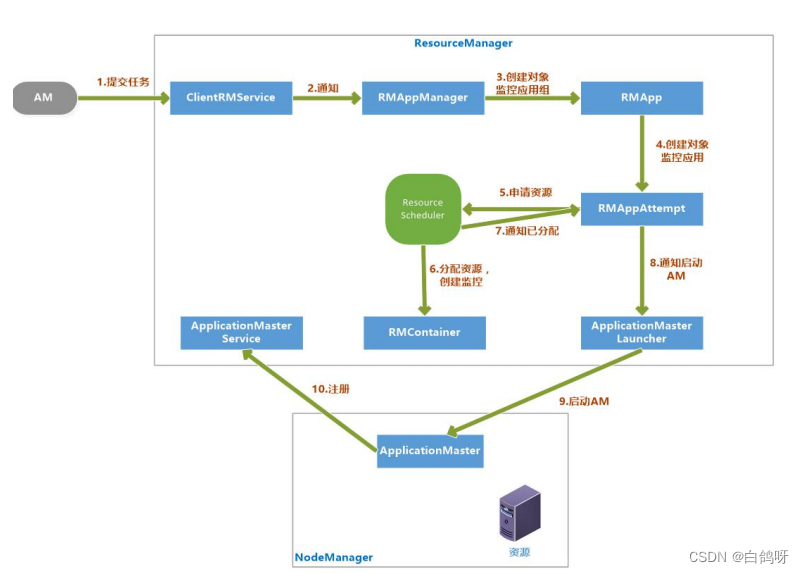
- 客户端提交一个任务给 RM,ClientRMService 负责处理客户端请求
- ClentRMService 通知 RMAppManager。
- RMAppManager 为应用程序创建一个 RMApp 对象来维护任务的状态。
- RMApp 启动任务,创建 RMAppAttempt 对象。
- RMAppAttempt 进行一些初始化工作,然后通知 ResourceScheduler 申请资源。
- ResourceScheduler 为任务分配资源后,创建一个 RMContainer 维护 Container 态并通知 RMAppAttempt,已经分配资源。
- RMAppAttempt 通知 ApplicationMasterLauncher 在资源上启动 AM。
- 在 NodeManager 的已分配资源上启动 AM
- AM 启动后向 ApplicationMasterService 注册
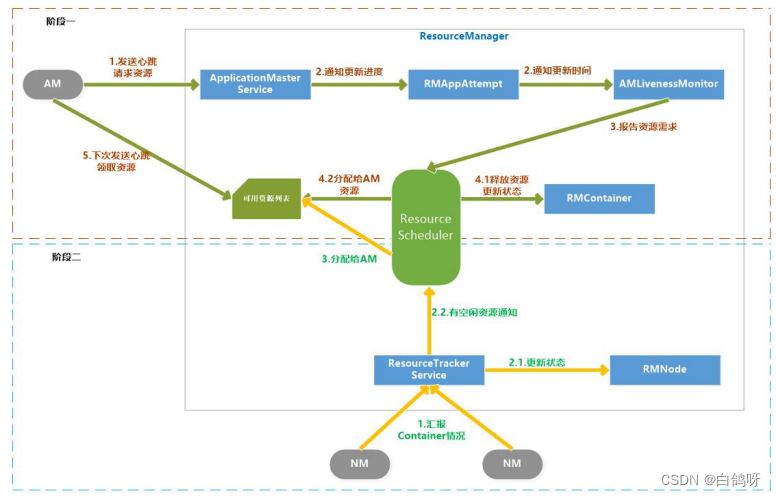
5、申请和分配 container
AM 向 RM 请求资源和 RM 为 AM 分配资源是两个阶段的循环过程:
- 阶段一:AM 请求资源请求并领取资源的过程,这个过程是 AM 发送请求、RM 记录请求。
- 阶段二:NM 向 RM 汇报各个 Container 运行状态,如果 RM 发现它上面有空闲的资源就分配给等待的 AM。
具体过程如下:
阶段一:
-
AM 通过 RPC 函数向 RM 发送资源需求信息,包括新的资源需求描述、待释放的Container 列表、请求加入黑名单的节点列表、请求移除黑名单的节点列表等
-
RM 的 ApplicationMasterService 负责处理 AM 的请求。一旦收到请求,就通知RMAppAttempt,更新应用程序执行进度,在 AMLivenessMonitor 中记录更新时间。
-
ApplicationMasterService 调用 ResourceScheduler,将 AM 的资源需求汇报给ResourceScheduler。
-
ResouceScheduler 首先读取待释放的 Container 列表,通知 RMContainer 更改态,杀死要释放的 Container,然后将新的资源需求记录,如果资源足够就记录已经分配好资源。
阶段二:
-
NM 通过 RPC 向 RM 汇报各自的各个 Container 的运行情况
-
RM 的 ResourceTrackerService 负责处理来自 NM 的汇报,收到汇报后,就通知RMNode 更改 Container 状态,并通知 ResourceScheduler。
-
ResourceScheduler 收到通知后,如果有可分配的空闲资源,就将资源分配给等待资源的 AM,等待 AM 下次心跳将资源领取走。
6、杀死Application
杀死 Application 流程:
Kill Job 通常是客户端发起的,RM 的 ClientRMService 负责处理请求,接收到请求后,先检查权限,确保用户有权限 Kill Job,然后通知维护这个 Application的 RMApp 对象,根据 Application 当前状态调用相应的函数来处理。
这个时候分为两种情况:Application 没有在运行、Application 正在运行。
- Application 没有在运行
向已经运行过的 NodeManger 节点对应的状态维护对象 RMNode 发送通知,进行清理;向 RMAppManager 发送通知,将 Application 设置为已完成状态。 - Application 正在运行
如果正在运行,也首先像情况一处理一遍,回收运行过的 NodeManager 资源,将Application 设置为已完成。另外 RMApp 还要通知维护任务状态的 RMAppAttempt对象,将已经申请和占用的资源回收,但是真正的回收是由资源调度器ResourceScheduler 异步完成的。
异步完成的步骤是先由 ApplicationMasterLauncher 杀死 AM,并回收它占用的资源,再由各个已经启动的 RMContainer 杀死 Container 并回收资源。
7、Container 超时
YARN 里有两种 Container:运行 AM 的 Container 和运行普通任务的 Container。
-
RM 为要启动的 AM 分配 Container 后,会监控 Container 的状态,如果指定时间内AM 还没有在 Container 上启动的话,Container 就会被回收,AM Container 超时会导致 Application 执行失败。
-
普通 Container 超时会进行资源回收,但是 YARN 不会自动在其他资源上重试,而是通知 AM,由 AM 决定是否重试。
8、安全管理
Hadoop 的安全管理是为了更好地让多用户在共享 Hadoop 集群环境下安全高效地使用集群资源。系统安全机制由认证和授权两大部分构成,Hadoop2.0 中的认证机制采用 Kerberos 和 Token 两种方案,而授权则是通过引入访问控制表(AccessControl List,ACL)实现的。
-
术语
Kerberos 是一种基于第三方服务的认证协议,非常安全。特点是用户只需要输入一次身份验证信息就可以凭借此验证获得的票据访问多个服务。Token 是一种基于共享密钥的双方身份认证机制。
Principal 是指集群中被认证或授权的主体,主要包括用户、Hadoop 服务、
Container、Application、Localizer、Shuffle Data 等。 -
Hadoop 认证机制
Hadoop 同时采用了 Kerberos 和 Token 两种技术,服务和服务之间的认证采用了Kerberos,用户和 NameNode 及用户和 ResourceManager 首次通讯也采用Kerberos 认证,用户和服务之间一旦建立连接后,用户就可以从服务端获取一个 Token,之后就可以使用 Token 认证通讯了。因为 Token 认证要比 Kerberos要高效。Hadoop 里 Kerberos 认证默认是关闭的,可以通过参数
hadoop.security.authentication 设置为 kerberos,这个配置模式是 simple。 -
Hadoop 授权机制
Hadoop 授权是通过访问控制列表(ACL)实现的,Hadoop 的访问控制机制与 UNIX的 POSIX 风格的访问控制机制是一致的,将权限授予对象分为:用户、同组用户、其他用户。默认情况下,Hadoop 公用 UNIX/Linux 下的用户和用户组。- 队列访问控制列表
- 应用程序访问控制列表
- 服务访问控制列表
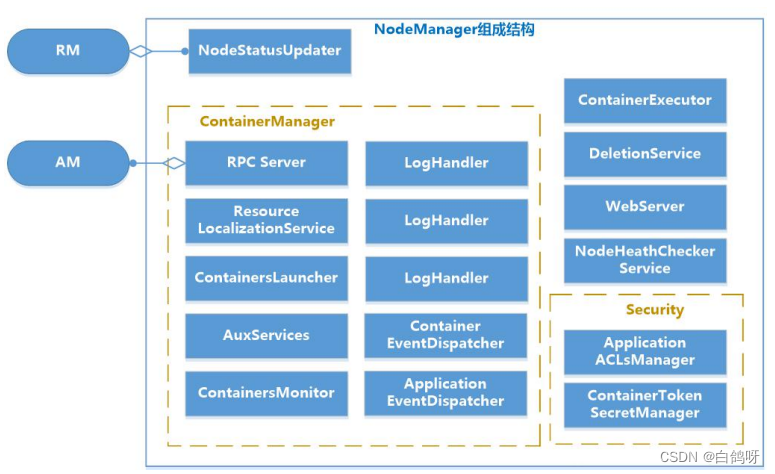
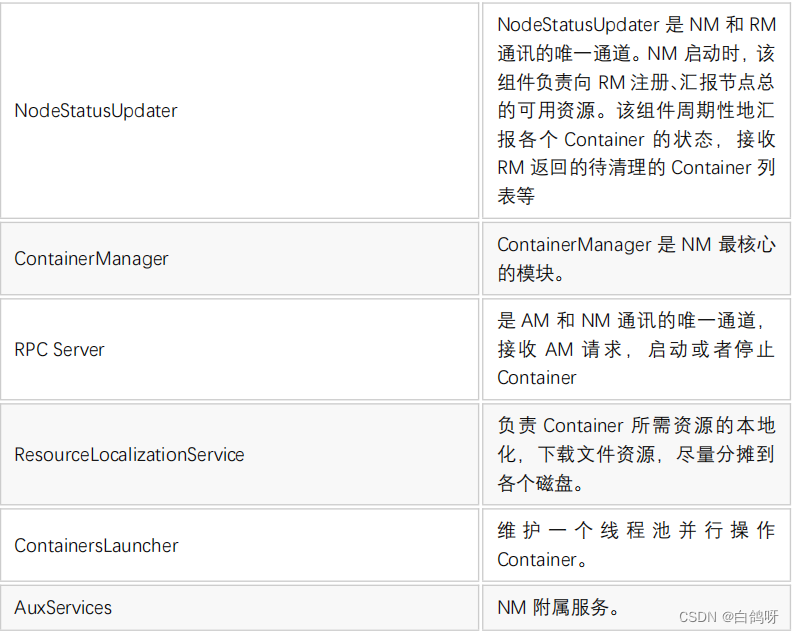
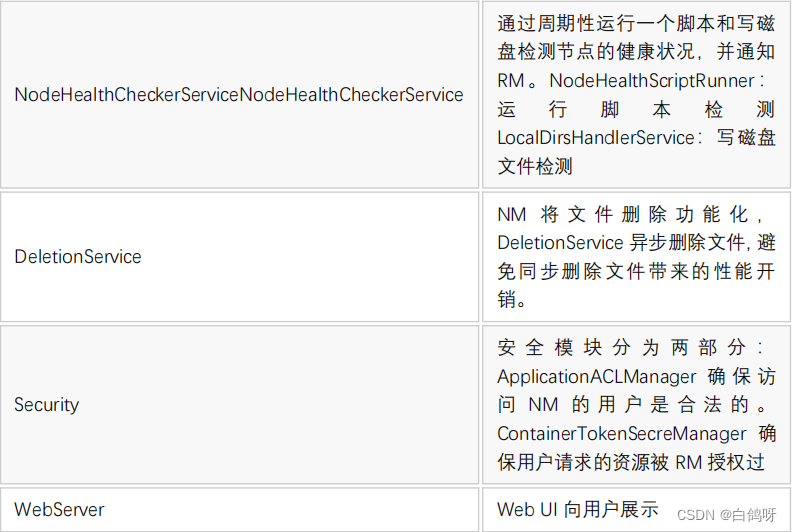
5、NodeManager 功能介绍
NM是单个节点上的代理,功能包括与ResourceManager保持通讯、管理Container的生命周期、监控 Container 的资源使用、追踪节点健康状态、管理日志。
1、基本内部构造

2、状态机管理
NodeManager 维护着三类状态机,分别是 Application、Container、LocalizedResource。
-
Application 状态机
RM 上有一个整个集群上 Application 信息列表,而一个 NM 上也有一个处在它自己节点的Application的信息列表,NodeManager上的Application状态机维护着 NodeManager 上 Application 的状态。这有利于对一个 NM 节点上的同一个 Application 所有的 Container 进行统一管理。 -
Container 状态机
Container 状态机维护 NodeManager 上所有 Container 的生命周期。 -
LocalizedResource 状态机
LocalizedResource 状态是 NodeManager 上用于维护一个资源生命周期的数据结构。资源包括文件、JAR 包等。
3、container 生命周期的管理
NodeManager 中的 ContainerManager 负责接收 AM 发来的请求以启动 Container,
Container 的启动过程分三个阶段:资源本地化、启动并运行 Container、资源清理。
-
资源本地化
资源本地化主要是进行分布是缓存工作,分为应用程序初始化和 Container 本地化。 -
运行 Container
Container 运行是由 ContainerLauncher 服务完成启动后,调用ContainerExecutor 来进行的。主要流程为:将待运行的 Container 所需要的环境变量和运行命令写到 Shell 脚本 launch_container.sh 中,并将启动该脚本的命令写入 default_container_executor.sh 中,然后通过运行该脚本启动container。 -
资源清理
container 清理是资源本地化的逆过程,是指当 container 运行完成后,NodeManager 来回收资源。
6、yarn 的 applicationMaster 介绍
ApplicationMaster 实际上是特定计算框架的一个实例,每种计算框架都有自己独特的 ApplicationMaster,负责与 ResourceManager 协商资源,并和NodeManager 协同来执行和监控 Container。MapReduce 只是可以运行在 YARN 上一种计算框架。
1、applicationMaster 的职能
Application 启动后,将负责以下任务:
- 初始化向 ResourceManager 报告自己的活跃信息的进程 (注册)
- 计算应用程序的的资源需求。
- 将需求转换为 YARN 调度器可以理解的 ResourceRequest。
- 与调度器协商申请资源
- 与 NodeManager 协同合作使用分配的 Container。
- 跟踪正在运行的 Container 状态,监控它的运行。
- 对 Container 或者节点失败的情况进行处理,在必要的情况下重新申请资源
2、报告活跃
-
注册
ApplicationMaster 执行的第一个操作就是向 ResourceManager 注册,注册时 AM告诉 RM 它的 IPC 的地址和网页的 URL。IPC 地址是面向客户端的服务地址;网页 URL 是 AM 的一个 Web 服务的地址,客户端可以通过 Http 获取应用程序的状态和信息。注册后,RM 返回 AM 可以使用的信息,包括:YARN 接受的资源的大小范围、应用程序的 ACL 信息。 -
心跳
注册成功后,AM 需要周期性地发送心跳到 RM 确认他还活着。参数yarn.am.liveness-monitor.expiry 配置 AM 心跳最大周期,如果 RM 发现超过这个时间还没有收到 AM 的心跳,那么就判断 AM 已经死掉
3、资源需求
AM 所需要的资源分为静态资源和动态资源。
-
静态资源
在任务提交时就能确定,并且在 AM 运行时不再变化的资源是静态资源,比如MapReduce 程序中的 Map 的数量。 -
动态资源
AM 在运行时确定要请求数量的资源是动态资源
4、调度任务
当 AM 的资源请求数量达到一定数量或者到了心跳时,AM 才会发送心跳到 RM,请求资源,心跳是以 ResourceRequest 形式发送的,包括的信息有:resourceAsks、ContainerID、containersToBeReleased。
RM 响应的信息包括:新分配的 Container 列表、已经完成了的 Container 状态、集群可用的资源上限
5、启动 container
- AM 从 RM 那里得到了 Container 后就可以启动 Container 了。
- AM 首先构造 ContainerLaunchContext 对象,包括分配资源的大小、安全令牌、启
动 Container 执行的命令、进程环境、必要的文件等 - AM 与 NM 通讯,发送 StartContainerRequest 请求,逐一或者批量启Container。
- NM 通过 StartContainerResponse 回应请求,包括:成功启动的 Container 列表失败的 Container 信信息等。
- 整个过程中,AM 没有跟 RM 进行通信。
- AM 也可以发送 StopContainerRequest 请求来停止 Container。
6、完成的 container
当 Container 执行结束时,由 RM 通知 AM Container 的状态,AM 解释 Container状态并决定如何继续操作。所以 YARN 平台只是负责为计算框架提供 Container信息。
7、AM 的失败和恢复
当 AM 失效后,YARN 只负责重新启动一个 AM,任务恢复到失效前的状态是由 AM自己完成的。AM 为了能实现恢复任务的目标,可以采用以下方案:将任务的状态持久化到外部存储中。比如:MapReduce 框架的 ApplicationMaster 会将已完成的任务持久化,失效后的恢复时可以将已完成的任务恢复,重新运行未完成的任务。
8、applicationMaster 启动过程
7、yarn 的资源调度
1、资源调度器的职能
资源调度器是 YARN 最核心的组件之一,是一个插拔式的服务组件,负责整个集群资源的管理和分配。YARN 提供了三种可用的资源调度器:FIFO、CapacityScheduler、Fair Scheduler。
2、资源调度器的分类
不同的任务类型对资源有着不同的负责质量要求,有的任务对时间要求不是很高(如 Hive),有的任务要求及时返还结果(如 HBase),有的任务是 CPU 密集型的,有的是 I/O 密集型的,所以简单的一种调度器并不能完全符合所有的任务类型。
3、有两种调度器的设计思路:
- 一是在一个物理 Hadoop 集群上虚拟多个 Hadoop 集群,这些集群各自有自己全套的 Hadoop 服务,典型的代表是 HOD(Hadoop On Demand)调度器,Hadoop2.0 中已经过时。
- 另一种是扩展 YARN 调度器。典型的是 Capacity Scheduler、Fair Scheduler。
4、调度器基本架构
插拔式组件
YARN 里的资源调度器是可插拔的,ResourceManager 在初始化时根据配置创建一个调度器,可以通过参数 yarn.resourcemanager.scheduler.class 参数来设置调度器的主类是哪个,默认是 CapacityScheduler,配置值为:
org.apache.hadoop.yarn.server.resourcemanager.scheduler.capacity.CapacityScheduler。
所有的资源调度器都要实现接口
org.apache.hadoop.yarn.server.resourcemanager.scheduler.ResourceScheduler。
事件处理器
YARN 的资源管理器实际上是一个事件处理器,它处理 6 个 SchedulerEventType类型的事件。
事件说明:
- Node_Removed 集群中移除一个计算节点,资源调度器需要收到该事件后从可分配的资源总量中移除相应的资源量。
- Node_Added 集群增加一个节点
- Application_added RM 收到一个新的 Application。
- Application_Remove 表示一个 Application 运行结束
- Container_expired 当一个 Container 分配给 AM 后,如果在一段时间内 AM 没有启动 Container,就触发这个事件。调度器会对该 Container 进行回收。
- Node_Update RM 收到 NM 的心跳后,就会触发 Node_Update 事件。
1、资源调度三种模型介绍
究竟使用哪种调度模型,取决于这个配置项,apache 版本的 hadoop 默认使用的是 capacity scheduler 调度方式。
CDH 版本的默认使用的是 fair scheduler 调度方式 :
yarn-site.xml :yarn.resourcemanager.scheduler.class
1、双层资源调度模型
YARN 使用了双层资源调度模型。
第一层:ResourceManager 中的调度器将资源分配给各个 ApplicationMaster。这一层调度由 YARN 的资源调度器来实现。
第二层:ApplicationMaster 再进一步将资源分配给它内部的各个任务。这一层的调度由用户程序这个计算框架来实现。
YARN 的资源分配过程是异步的,YARN 的调度器分配给 AM 资源后,先将资源存入
一个缓冲区内,当 AM 下次心跳时来领取资源。
资源分配过程如下 7 个步骤:
步骤 1:NodeManager 通过周期性的心跳汇报节点信息 : 告诉resourceManager 当前剩余的资源信息
步骤 2:RM 为 NM 返回一个应答,包括要释放的 Container 列表。
步骤 3:RM 收到 NM 汇报的信息后,会出发资源调度器的 Node_Update 事件。
步骤 4:资源调度器收到 Node_Update 事件后,会按照一定的策略将该节点上资源分配给各个应用程序,并将分配结果存入一个内存数据结构中。
步骤 5:应用程序的 ApplicationMaster 周期性地向 RM 发送心跳,以领
取最新分配的 Container。
步骤 6:RM 收到 AM 的心跳后,将分配给它的 Container 以心跳应答的方式返回给ApplicationMaster
步骤 7:AM 收到新分配的 Container 后,会将这些 Container 进一步分配给他的内部子任务。
资源保证机制
YARN 采用增量资源分配机制来保证资源的分配。
增量资源分配机制是指当 YARN 暂时不能满足应用程序的资源要求时,将现有的一个节点上的资源预留,等到这个节点上累计释放的资源满足了要求,再分配给ApplicationMaster。
这种增量资源分配机制虽然会造成资源的浪费,但是能保证 AM 肯定会得到资源,
不会被饿死。
资源分配算法
YARN 的资源调度器采用了主资源公平调度算法(DRF)来支持多维度资源调度。
资源抢占模型
资源调度器中,每个队列可以设置一个最小资源量和最大资源量。为了提高集群使用效率,资源调度器会将负载较轻的队列资源分配给负载较重的队列使用,当负载较轻的队列突然接到了新的任务时,调度器才会将本属于该队列的资源分配给它,但是此时资源有可能正被其他队列使用,因此调度器必须等待其他队列释放资源,如果一段时间后发现资源还未得到释放,则进行资源抢占。
关于资源抢占的实现,涉及到一下两个问题:
- 如何决定是否抢占某个队列的资源
- 如何使得资源抢占代价最小
资源抢占是通过杀死正在使用的 Container 实现的,由于 Container 已经处于运行状态,直接杀死 Container 会造成已经完成的计算白白浪费,为了尽可能地避免资源浪费,YARN 优先选择优先级低的 Container 做为资源抢占的对象,并且不会立刻杀死 Container,而是将释放资源的任务留给 ApplicationMaster 中的应用程序,以期望他能采取一定的措施来执行释放这些 Container,比如保存一些状态后退出,如果一段时间后,ApplicationMaster 仍未主动杀死 Container,则 RM 再强制杀死这些 Container。
2、层级队列管理机制 FIFO 调度策略
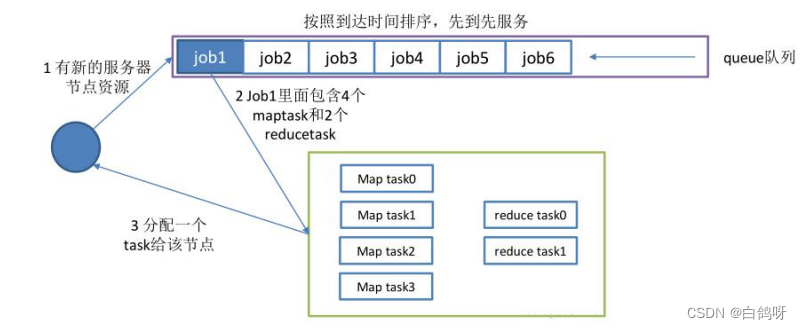
Hadoop1.0 中使用了平级队列的组织方式,而后来采用了层级队列的组织方式。
层级队列的特点:
- 子队列
队列可以嵌套,每个队列都可以包含子队列;用户只能将应用程序提交到叶子队列中。 - 最小容量
每个子队列均有一个最小容量比属性,表示可以使用的父队列容量的百分比。调度器总是优先选择当前资源使用率最低的队列,并为之分配资源。指定了最小容量,但是不会保证会保持最小容量,同样会被分配给其他队列。 - 最大容量
队列指定了最大容量,任何时候队列使用的资源都不会超过最大容量。默认情况下队列的最大容量是无限大。 - 用户权限管理
管理员可以配置每个叶子节点队列对应的操作系统的用户和用户组。 - 系统资源管理
管理员设置了每个队列的容量,每个用户可以用资源的量,调度器根据这些配置来进行资源调度
队列命名规则:
为了防止队列名称的冲突和便于识别队列,YARN 采用了自顶向下的路径命名规则,父队列和子队列名称采用.拼接
3、Capacity Scheduler
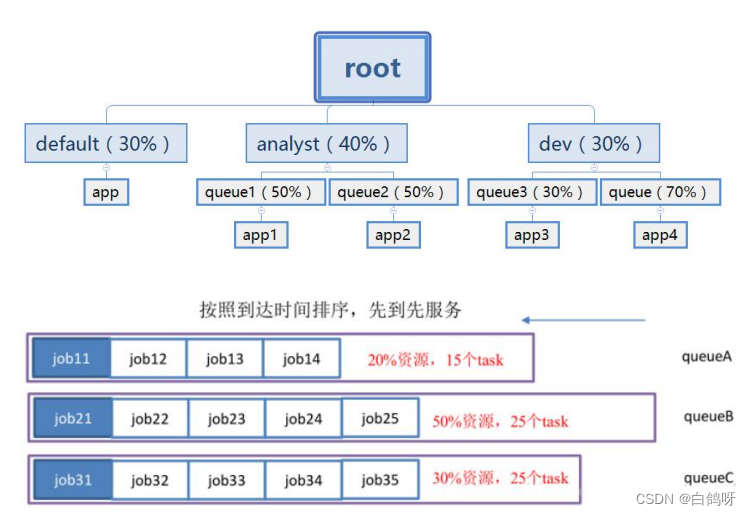
Capacity Scheduler 是 Yahoo!开发的多用户调度器。主要有以下几个特点:
- 容量保证
管理员可以为队列设置最低保证和资源使用上限,同一个队列里的应用程序可以共享使用队列资源。 - 灵活性: 一个队列里的资源有剩余,可以暂时共享给其他队列,一旦该队列有的新任务,其他队列会归还资源,这样尽量地提高了集群的利用率。
- 多重租赁
支持多用户共享集群和多应用程序同时运行 - 安全保证
每个队列有严格的 ACL 列表,限制了用户的权限 - 动态更新配置文件
管理员对参数的配置是动态的。
配置方案:
Capacity Scheduler 的所有配置都在 capactiy-scheduler.xml 里,管理员修改后,要通过命令来刷写队列:yarn mradmin –refreshQueues
Capacity Scheduler 不允许管理员动态地减少队列数目,且更新的配置参数值
应该是合法值。
以下以队列 tongyong 为例来说明参数配置:
<property>
<name>yarn.scheduler.capacity.root.tongyong.capacity</name>
<value>10</value>
<description>队列资源容量百分比</description>
</property>
<property>
<name>yarn.scheduler.capacity.root.tongyong.user-limit-factor</name>
<value>3</value>
<description>
每个用户最多可以使用的资源量百分比
</description>
</property>
<property>
<name>yarn.scheduler.capacity.root.tongyong.maximum-capacity</name>
<value>30</value>
<description>
队列资源的使用的最高上限,由于存在资源共享,所以队列使用的资源可能会超过 capacity 设置
的量,但是不会超过 maximum-capacity 设置的量
</description>
</property>
<property>
<name>yarn.scheduler.capacity.root.tongyong.minimum-user-limit-percent</name>
<value>30</value>
<description>用户资源限制的百分比,当值为 30 时,如果有两个用户,每个用户不能超过 50%,
当有 3 个用户时,每个用户不能超过 33%,当超过三个用户时,每个用户不能超过 30%
</description>
</property>
【限制应用程序数目相关参数】
<property>
<name>yarn.scheduler.capacity.root.tongyong.maximum-applications</name>
<value>200</value>
<description>
队列中同时处于等待和运行状态的应用程序的数量,如果多于这个数量的应用程序将被拒绝。
</description>
</property>
<property>
<name>yarn.scheduler.capacity.root.tongyong.maximum-am-resource-percent</na
me>
<value>0.1</value>
<description>
集群中用于运行应用程序 ApplicationMaster 的资源比例上限,该参数通常用于限制处于活
动状态的应用程序的数目。
</description>
</property>
【队列的访问和权限控制参数】
<property>
<name>yarn.scheduler.capacity.root.tongyong.state</name>
<value>RUNNING</value>
<description>
队列状态,可以为 STOPPED 或者为 RUNNING。如果改为 STOPPED,用户将不能向集群中提交作业,
但是正在运行的将正常结束。
</description>
</property>
<property>
<name>yarn.scheduler.capacity.root.tongyong.acl_submit_applications</name>
<value>root,tongyong,user1,user2</value>
<description>
限定哪些用户可以向队列里提交应用程序,该属性有继承性,子队列默认和父队列的配置是一样的。
</description>
</property>
<property>
<name>yarn.scheduler.capacity.root.tongyong.acl_administer_queue</name>
<value>root,tongyong</value>
<description>
限定哪些用户可以管理当前队列里的应用程序。
</description>
</property>
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
4、Fair Scheduler

基本特点:
-
资源公平共享
默认是 Fair 策略分配资源,Fair 策略是一种基于最大最小公平算法实现的,所有应用程序平分资源。 -
支持资源抢占
某个队列中有剩余资源时,调度器会将这些资源共享给其他队列,当该队列有了新的应用程序提交过来后,调度器会回收资源,调度器采用先等待再强制回收的策略。 -
负载均衡
Fair Scheduler 提供了一个基于任务数目的负载均衡机制,尽可能将系统中的任务均匀分布到各个节点上。 -
调度策略配置灵活
可以每个队列选用不同的调度策略:FIFO、Fair、DRF -
提高小应用程序的响应时间
小作业也可以分配大资源,可以快速地运行完成
原文:五分钟学大数据

