
Megatron-LM源码系列(四):重计算(recompute)_recompute-granularity
赞
踩
1. recompute参数配置
在megatron/arguments.py中有重计算的参数配置如下:
group.add_argument('--recompute-activations', action='store_true', help='recompute activation to allow for training ' 'with larger models, sequences, and batch sizes.') group.add_argument('--recompute-granularity', type=str, default=None, choices=['full', 'selective'], help='Checkpoint activations to allow for training ' 'with larger models, sequences, and batch sizes. ' 'It is supported at two granularities 1) full: ' 'whole transformer layer is recomputed, ' '2) selective: core attention part of the transformer ' 'layer is recomputed.') group.add_argument('--distribute-saved-activations', action='store_true', help='If set, distribute recomputed activations ' 'across model parallel group.') group.add_argument('--recompute-method', type=str, default=None, choices=['uniform', 'block'], help='1) uniform: uniformly divide the total number of ' 'Transformer layers and recompute the input activation of ' 'each divided chunk at specified granularity, ' '2) recompute the input activations of only a set number of ' 'individual Transformer layers per pipeline stage and do the ' 'rest without any recomputing at specified granularity' 'default) do not apply activations recompute to any layers') group.add_argument('--recompute-num-layers', type=int, default=1, help='1) uniform: the number of Transformer layers in each ' 'uniformly divided recompute unit, ' '2) block: the number of individual Transformer layers ' 'to recompute within each pipeline stage.')

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
说明:
--recompute-activations: 设置recompute_activations等同于recompute_granularity为selective;selective运行效率更高,大部分场景只设置这个就可以。如果显存更紧张时,再通过recompute-granularity来进行full的设置。--recompute-granularity: 支持不同颗粒度的重计算,设为full会重计算整个transformer层,设为selective只会重算transformer中的core_attention部分。--distribute-saved-activations: 按TP并行度分开存储activation。--recompute-method:uniform计算会把所有的transformer layer分为若干组,分别把每组的input activation保存在内存中, GPU显存不足时,可通过设大每个组内的layer数来运行更大的model;block是针对pipeline并行的每个stage,checkpoint部分transformer layer的input activation, 剩余部分不进行checkpoint缓存,对于一个pipeline stage中有8层的来说,当设为5时,前5层中每一层的input activation都会被缓存,后3层在反向的时候正常计算。--recompute-num-layers: 对于uniform类型,表示设置在每个重计算的transformer layer group中的层数, 默认为1表示对每一层transformer layer都分别进行checkpoint;对于block类型,设为N表示单个pipeline stage中的前N个layers会缓存input activation。
2. 源码详解
2.1 --recompute-activations
设置recompute_activations等同于recompute_granularity为selective,设置后会覆盖recompute_granularity的值。
if args.recompute_activations:
args.recompute_granularity = 'selective'
del args.recompute_activations
- 1
- 2
- 3
2.2 --recompute-granularity
支持不同颗粒度的重计算,设为full会重计算整个transformer层,设为selective只会重算transformer中的core_attention部分。下图红框中为选择重计算的部分:
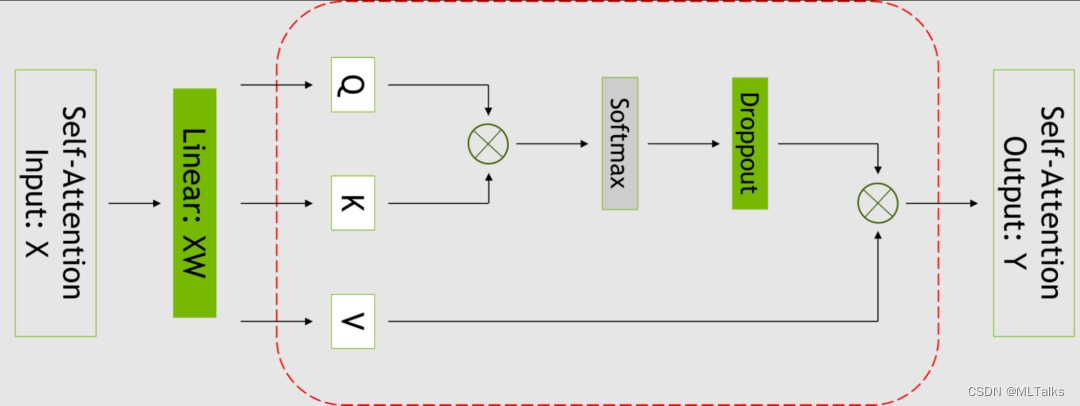
入口是在megatron/model/transformer.py文件中的ParallelTransformer函数中, 在forward中如果为full的话会对整个前向进行checkpoint操作。
class ParallelTransformer(MegatronModule): def forward(self, hidden_states, attention_mask, encoder_output=None, enc_dec_attn_mask=None, retriever_input=None, retriever_output=None, retriever_attn_mask=None, inference_params=None, rotary_pos_emb=None): ... # Forward pass. if self.recompute_granularity == 'full': hidden_states = self._checkpointed_forward(hidden_states, attention_mask, encoder_output, enc_dec_attn_mask, rotary_pos_emb, is_first_microbatch) ...
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
具体执行checkpoint的方法有两种,分别是uniform和block。对于uniform方法来说,每次会过self.recompute_num_layers个layer保存一次input activation。custom(l, l + self.recompute_num_layers), custom函数是用于执行自定义的前向计算。对于block方法,对于小于self.recompute_num_layers的layer执行input activation的checkpoint, 对于大于等于self.recompute_num_layers的layer还执行原有操作。
示例代码如下:
class ParallelTransformer(MegatronModule): def _checkpointed_forward(self, hidden_states, attention_mask, encoder_output, enc_dec_attn_mask, rotary_pos_emb, is_first_microbatch): def custom(start, end): def custom_forward(*args, **kwargs): x_, *args = args for index in range(start, end): layer = self._get_layer(index) x_ = layer(x_, *args, **kwargs) return x_ return custom_forward if self.recompute_method == 'uniform': # Uniformly divide the total number of Transformer layers and # checkpoint the input activation of each divided chunk. # A method to further reduce memory usage reducing checkpoints. l = 0 while l < self.num_layers: if self.transformer_impl == 'transformer_engine': ... else: hidden_states = tensor_parallel.checkpoint( custom(l, l + self.recompute_num_layers), self.distribute_saved_activations, hidden_states, attention_mask, encoder_output, enc_dec_attn_mask, None, None, None, None, rotary_pos_emb) l += self.recompute_num_layers elif self.recompute_method == 'block': # Checkpoint the input activation of only a set number of individual # Transformer layers and skip the rest. # A method fully use the device memory removing redundant re-computation. for l in range(self.num_layers): if l < self.recompute_num_layers: if self.transformer_impl == 'transformer_engine': ... else: hidden_states = tensor_parallel.checkpoint( custom(l, l + 1), self.distribute_saved_activations, hidden_states, attention_mask, encoder_output, enc_dec_attn_mask, None, None, None, None, rotary_pos_emb) else: if self.transformer_impl == 'transformer_engine': ... else: hidden_states = custom(l, l + 1)( hidden_states, attention_mask, encoder_output, enc_dec_attn_mask, None, None, None, None, rotary_pos_emb) ...
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
对于selective颗粒度的重计算目前不支持重计算方法的选择。
if args.recompute_granularity == 'selective':
assert args.recompute_method is None, \
'recompute method is not yet supported for ' \
'selective recomputing granularity'
- 1
- 2
- 3
- 4
在计算ParallelTransformer时会只针对attention的input activation进行checkpoint。
class ParallelTransformer(MegatronModule): """Transformer class.""" def __init__(...): ... self.checkpoint_core_attention = args.recompute_granularity == 'selective' ... def forward(self, hidden_states, attention_mask, encoder_output=None, inference_params=None, rotary_pos_emb=None): ... if not self.use_flash_attn: if self.checkpoint_core_attention: context_layer = self._checkpointed_attention_forward( query_layer, key_layer, value_layer, attention_mask) ... def _checkpointed_attention_forward(self, query_layer, key_layer, value_layer, attention_mask, rotary_pos_emb=None): """Forward method with activation checkpointing.""" def custom_forward(*inputs): query_layer = inputs[0] key_layer = inputs[1] value_layer = inputs[2] attention_mask = inputs[3] output_ = self.core_attention(query_layer, key_layer, value_layer, attention_mask) return output_ q_pos_emb, k_pos_emb = (None, None) if rotary_pos_emb is None \ else rotary_pos_emb hidden_states = tensor_parallel.checkpoint( custom_forward, False, query_layer, key_layer, value_layer, attention_mask, q_pos_emb, k_pos_emb) return hidden_states
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
2.3 --distribute-saved-activations
只支持设置TP>1, 并且是full粒度的重计算, 对于uniform和block重计算都支持。
# Activation recomputing.
if args.distribute_saved_activations:
assert args.tensor_model_parallel_size > 1, 'can distribute ' \
'recomputed activations only across tensor model ' \
'parallel groups'
assert args.recompute_granularity == 'full', \
'distributed recompute activations is only '\
'application to full recompute granularity'
assert args.recompute_method is not None, \
'for distributed recompute activations to work you '\
'need to use a recompute method '
assert TORCH_MAJOR >= 1 and TORCH_MINOR >= 10, \
'distributed recompute activations are supported for pytorch ' \
'v1.10 and above (Nvidia Pytorch container >= 21.07). Current ' \
'pytorch version is v%s.%s.' % (TORCH_MAJOR, TORCH_MINOR)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
实现是在megatron/core/tensor_parallel/random.py文件的CheckpointFunction中,前向计算时使用no_grad()的上下文,不保存grad,在存activation的时候会把tensor展成一维的,每个rank只存自己的那一部分。
class CheckpointFunction(torch.autograd.Function): def forward(ctx, run_function, distribute_saved_activations, *args): ... with torch.no_grad(): outputs = run_function(*args) # Divide hidden states across model parallel group and only keep # the chunk corresponding to the current rank. if distribute_saved_activations: ctx.input_0_shape = args[0].data.shape safely_set_viewless_tensor_data( args[0], split_tensor_into_1d_equal_chunks(args[0].data, new_buffer=True)) ... # Store everything. ctx.save_for_backward(*args) return outputs
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
反向会在model_group中先通过gather_split_1d_tensor函数进行all_gather操作, 再进行backward的计算。
class CheckpointFunction(torch.autograd.Function): def backward(ctx, *args): if not torch.autograd._is_checkpoint_valid(): raise RuntimeError("Checkpointing is not compatible with .grad(), " "please use .backward() if possible") inputs = ctx.saved_tensors if ctx.distribute_saved_activations: safely_set_viewless_tensor_data( inputs[0], gather_split_1d_tensor(inputs[0].data).view(ctx.input_0_shape)) ... # Compute the forward pass. detached_inputs = detach_variable(inputs) with torch.enable_grad(): outputs = ctx.run_function(*detached_inputs) ... torch.autograd.backward(outputs, args) grads = tuple(inp.grad if isinstance(inp, torch.Tensor) else inp for inp in detached_inputs) return (None, None) + grads
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
3. 配置选择
3.0 对比说明
随着模型大小的增加,sequence parallel和recompute都会节省内存,将内存需求减少约5倍。
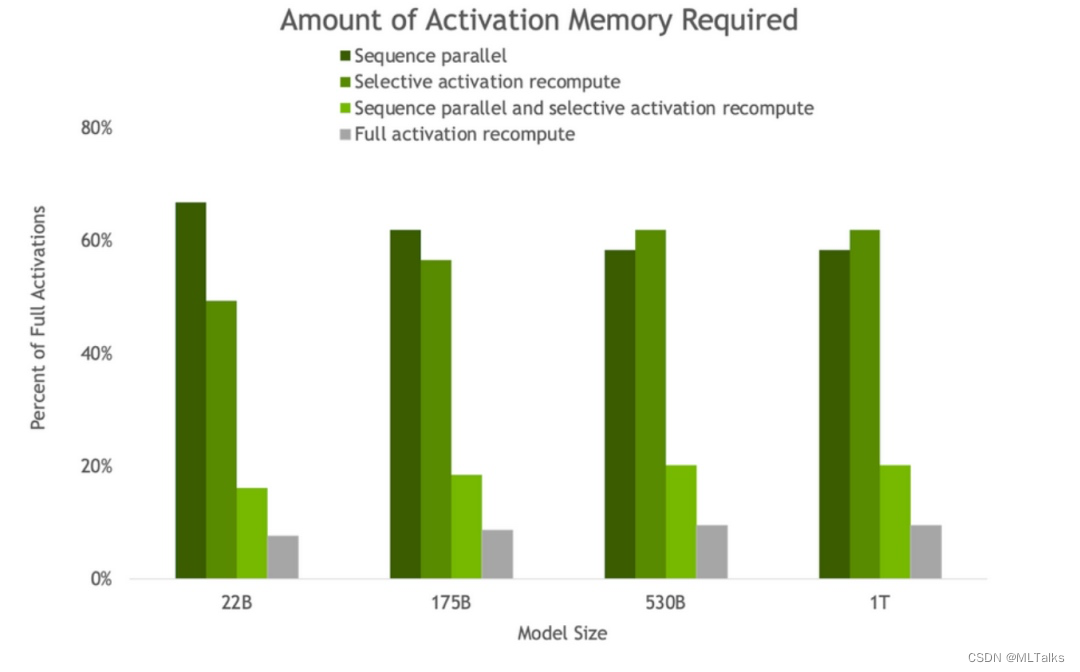
条形图表示每层的前向、反向和重计算时间细分。基线代表没有重计算和序列并行时的情况。这些技术有效地减少了所有激活被重计算而不是保存时产生的开销。最大模型的开销从36%下降到仅为2%。

3.1 selective方式
只设--recompute-activations相当于只用了selective, 只对core_attention的input activation进行缓存。selective优点是新增的计算量相比较其他方案较少,性价比高。
--recompute-activations
- 1
3.2 block方式
使用block策略,前N层每一层都保存对应的input activation。可在pipeline并行中配合使用。--distribute-saved-activations可看情况使用。N等于pipeline stage中的layer数,可以最大限度使用重计算,节省显存。
--recompute-granularity full \
--recompute-method block \
--recompute-num-layers [N] \
--distribute-saved-activations \
- 1
- 2
- 3
- 4
3.3 uniform方式
使用uniform策略,每N个layer进行一次分组,每组会缓存输入input activation用于后续重计算,默认N为1表示对所有层都会,N等于1可以最大限度使用重计算,节省显存。在使用uniform基础上增加使用--distribute-saved-activations, 存activation时可以一个TP组进行分开存储。
--recompute-granularity full \
--recompute-method uniform \
--recompute-num-layers 1 \
--distribute-saved-activations \
- 1
- 2
- 3
- 4

