
- 1史上最全项目管理工具排行榜(包含国内外25款软件)_项目管理软件
- 2Gson 、FastJson、Jackson 使用对比_jackson gson
- 3第一篇博客------自我介绍_如何介绍自己的博客
- 4C#梳理【事件Event】
- 5Django自定义错误处理机制_django apiexception code
- 6C语言 | Leetcode C语言题解之第198题打家劫舍
- 7【任务调度】遗传算法求解任务调度优化问题【含Matlab源码 4542期】_遗传算法解决调度问题
- 8CompletableFuture——异步编程艺术
- 9大华股份轻量化AI技术斩获CVPR视觉顶会ISP赛道冠军_大华 mobile ai
- 10ES是什么?看完这篇就不要再问这种低级问题了!(1)_[????-????]??es???
外挂级OCR神器:免费文档解析、表格识别、手写识别、古籍识别、PDF转Word_表格ocr
赞
踩
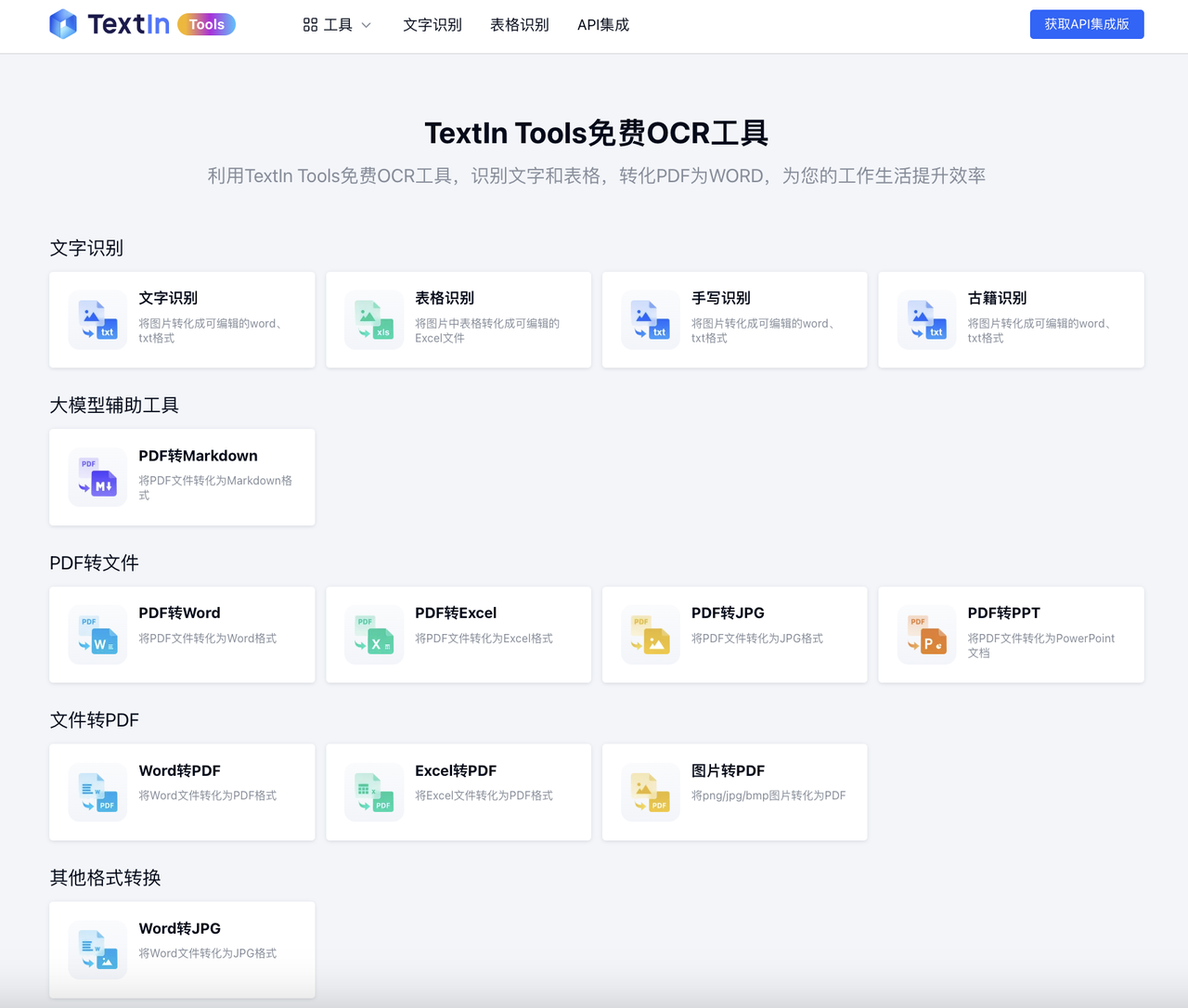
智能文档解析:大模型友好的文档解析工具
PDF转Markdown
支持将任意格式的文件(图片、PDF、Doc/Docx、网页等)解析为Markdown或Json格式,以对LLM友好的方式呈现。
-
更高速度:100页PDF最快1.5s完成解析
-
更大文件:目前同步接口支持文件最大可达500MB
-
更长文件:支持最长1000页
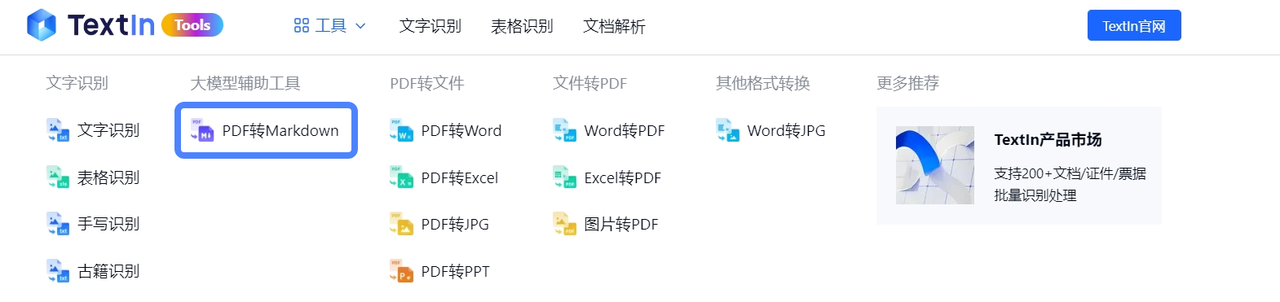
选择工具,点击PDF转Markdown

点击/拖拽上传文件,等待在线转换
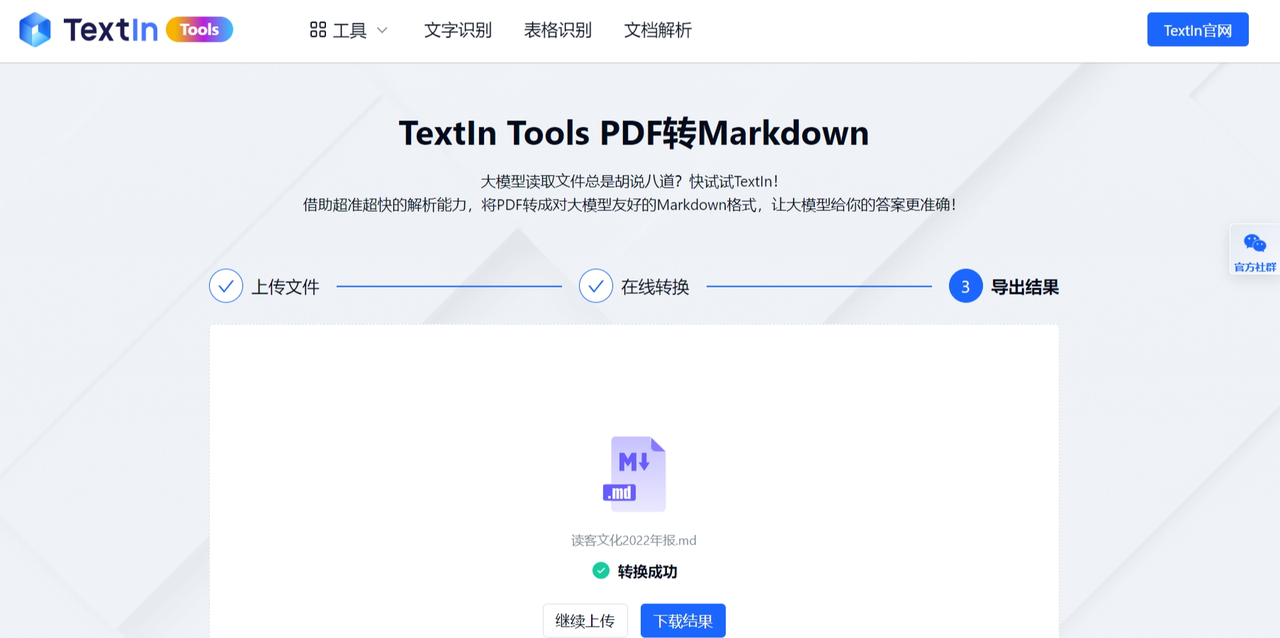
点击下载markdown文件
下面我们进行一个简单的测试。
首先,在国内某通用大模型问答C端产品上传一份PDF版企业年报,并提出金融分析领域的常见问题:请介绍公司的资产结构。
大模型给出了多个方面的介绍,但答案笼统,数据信息较为粗略。
我们尝试替换文档解析工具,将PDF文件上传至平台进行解析,并把解析后的Markdown文件上传,向大模型提出同一个问题。此次,大模型给出了货币资金、长期股权投资等数据信息。
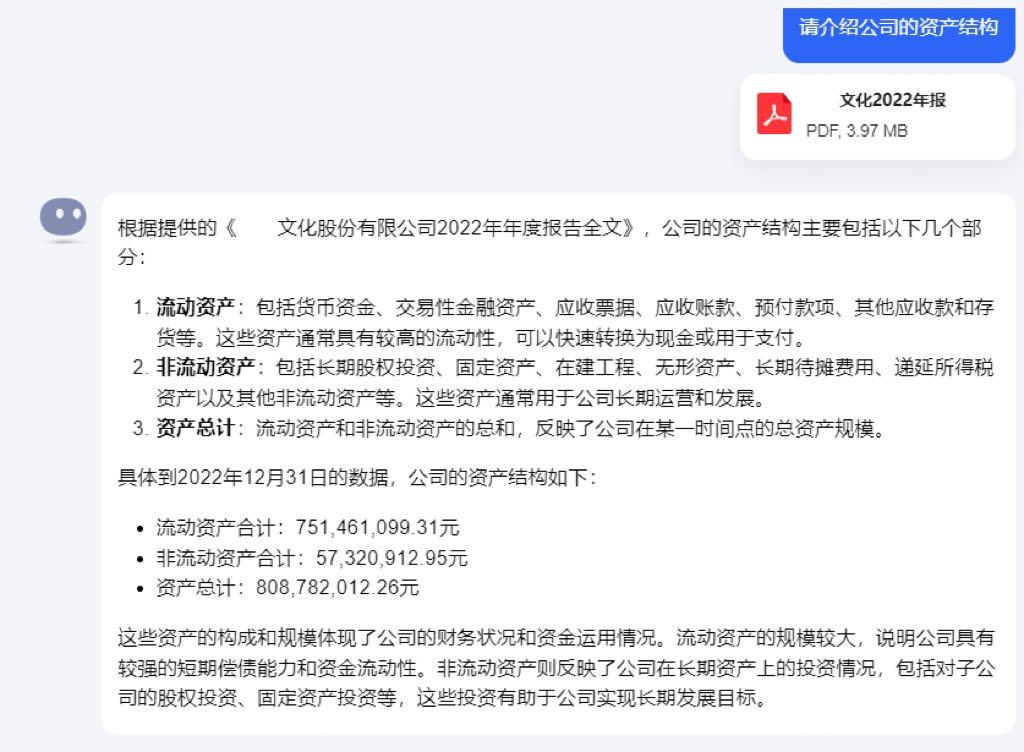
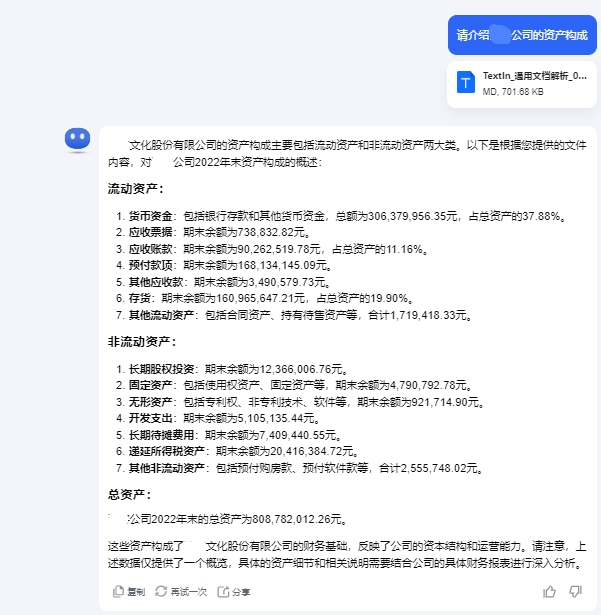
我们回到年报原文档进行验证,以排除幻觉干扰。在以下表格中可以看到,在改变解析工具后,大模型的回答来自于年报中表格数据,信息准确。
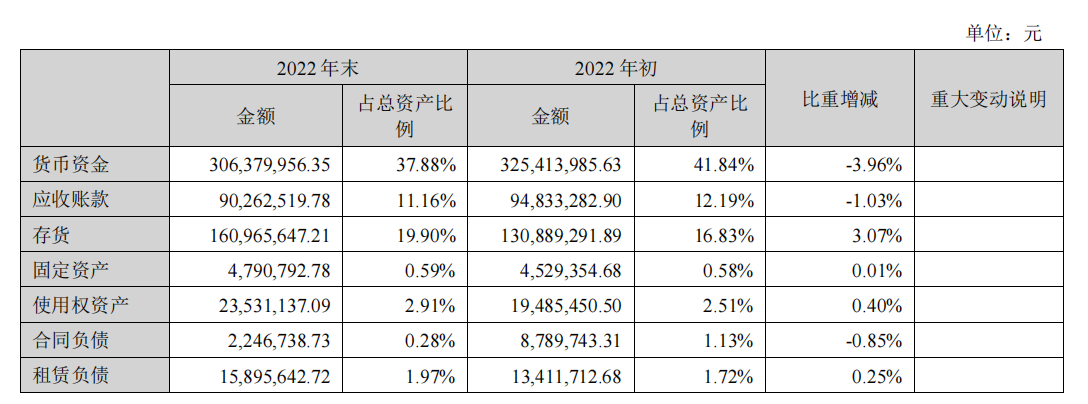
在这一类案例中,文档解析工具性能对问答类产品表现的影响显著可见。
应用场景
大模型问答
支持解析各类型的知识库内容,包括企业内部的文档库和公开的文章报告。通过将解析内容提供给问答系统,让大模型在合成答案时言之有物,从而减少幻觉的产生,提升问答质量。
大模型训练语料处理
识别并还原各类文档中的内容,并以markdown序列的格式进行输出,适配生成式语言模型的训练。高质量的文档解析结果,也能减少人工纠错数据的时间,从而加快模型训练的整体节奏。
文档翻译
通过文档内容解析,完成原始信息的提取,以下游机器翻译任务友好的方式还原文档内容,从而加快翻译任务的执行。
通用文字识别
表格+手写识别
支持对各种版式图像中的多方向文字、表格文字等进行提取和识别,同时支持文档版面分析与还原。解决图像模糊、歪斜、反光、形变、光照不均、阴影、低像素、背景复杂、字体复杂、多语言融合等复杂场景的识别问题。
-
中文印刷体平均字符识别准确率99.7%
-
识别引擎支持50+主流语言
点击手写识别
点击/拖拽上传文件

手写表格识别效果:手写文字完全准确、合并单元格精准识别
应用场景
内容审核与管理
识别图像中的不良文字,如社交和电商等应用中的不文明内容,提示相应风险,协助用户进行审核处理,帮助用户有效规避业务风险,及时发现违规行为,大大降低人力成本,广泛应用于电商内容治理场景
随手拍扫描
支持快速识别路标、指示牌、广告牌、街边店铺招牌、商品包装、购物小票等生活场景中的实体文字信息,应用于地图、翻译、搜索、生活出行等移动应用中,方便用户进行文本的提取或录入,有效提升产品易用性和用户使用体验。
古籍识别
利用光学字符识别技术(简称OCR),可以识别古籍中的内容、文字,分析版面并进行结构化输出,这对于复杂版式的古籍保护(比如族谱、地方志等)、检索,乃至信息挖掘和知识发现,都有非常重大的意义。
点击古籍识别
点击/拖拽上传文件
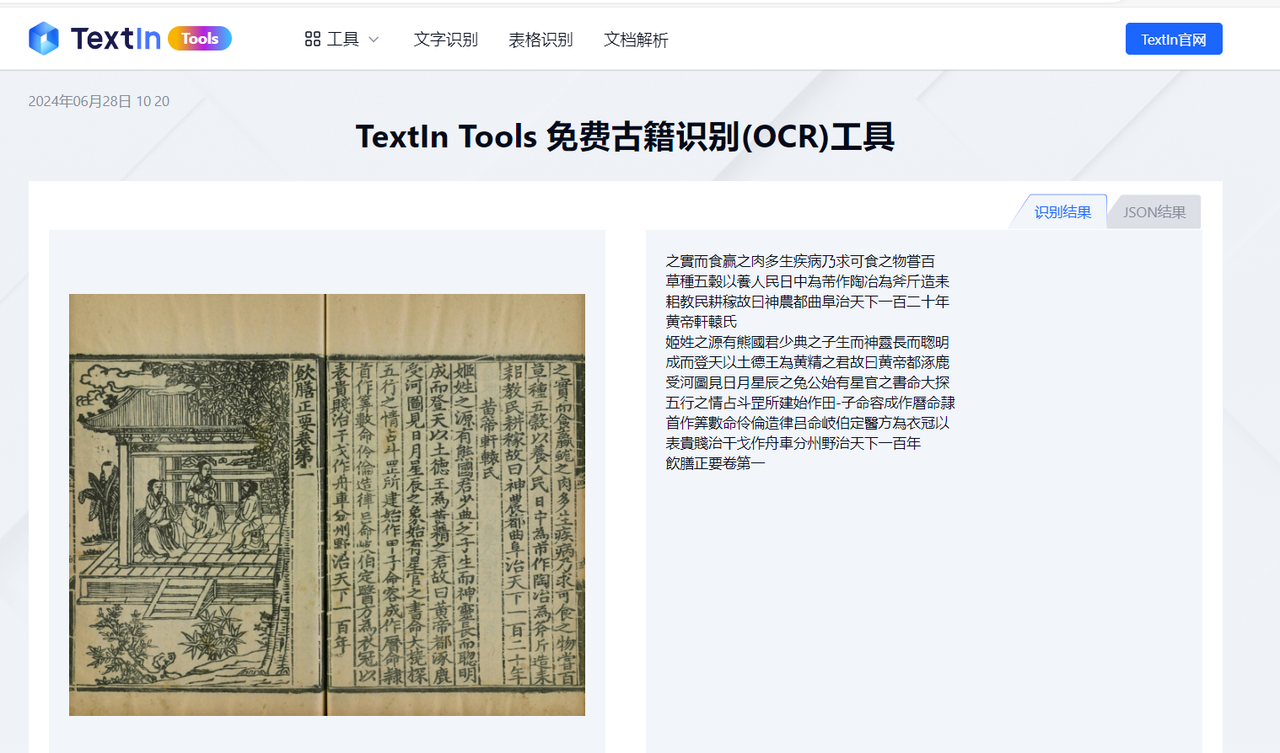
古籍识别效果:文字识别准确率高,还原语序
文档格式转换
提供PDF/Word/Excel/PPT及图片多种格式的高精度转换,高保真输出,并支持自定义水印等功能,提升文件处理效率。可用于教育文件处理、办公文档处理等场景。
-
服务安全稳定:TextIn提供服务可靠、安全、稳定的格式转换服务,具备ISO认证和等保认证,服务可用性高于99%。
-
具备多种自定义功能:可实现自定义水印、zip包加密等功能,根据场景进行个性化定制。
点击/拖拽上传文件


PDF转Word效果展示
目前,TextIn Tools支持在线试用,如在使用过程中遇到问题,可在官网扫描二维码加入用户社群,会有专人一对一解答您的问题,也欢迎与TextIn团队进行技术交流,提出宝贵的意见或建议。

