
- 1oracle drop怎么用,Oracle Drop Table
- 2Hdfs知识要点_所有节点的hdfs路径通过fs.defualt.
- 3实验七 DataStream API编程实践
- 4使用Python分析14亿条数据_python海量数据分析
- 5如何解决Git中的合并冲突?_git合并冲突最简单三个步骤
- 6Zabbix监控系统系列之七:VMware虚拟化监控_zabbix监控vmware
- 7什么是分布式锁?为什么用分布式锁?有哪些常见的分布式锁?_数据下发需要分布式锁嘛
- 8Mac下载安装vscode_vscode mac下载
- 9logd,删除log,逻辑_logd缓存log逻辑
- 10Python使用 plt.savefig 保存图片时是空白图片怎么解决_python plt save
【头歌】期末复习机器学习(二)_头歌信息熵与信息增益
赞
踩
决策树
第1关:什么是决策树
1、下列说法正确的是?
A、训练决策树的过程就是构建决策树的过程
B、ID3算法是根据信息增益来构建决策树
C、C4.5算法是根据基尼系数来构建决策树
D、决策树模型的可理解性不高
答案:AB
2、下列说法错误的是?
A、从树的根节点开始,根据特征的值一步一步走到叶子节点的过程是决策树做决策的过程
B、决策树只能是一棵二叉树
C、根节点所代表的特征是最优特征
答案:B
第2关:信息熵与信息增益
import numpy as np def calcInfoGain(feature, label, index): ''' 计算信息增益 :param feature:测试用例中字典里的feature,类型为ndarray :param label:测试用例中字典里的label,类型为ndarray :param index:测试用例中字典里的index,即feature部分特征列的索引。该索引指的是feature中第几个特征,如index:0表示使用第一个特征来计算信息增益。 :return:信息增益,类型float ''' #*********** Begin ***********# # 计算熵 def calcInfoEntropy(feature, label): ''' 计算信息熵 :param feature:数据集中的特征,类型为ndarray :param label:数据集中的标签,类型为ndarray :return:信息熵,类型float ''' label_set = set(label) result = 0 for l in label_set: count = 0 for j in range(len(label)): if label[j] == l: count += 1 # 计算标签在数据集中出现的概率 p = count / len(label) # 计算熵 result -= p * np.log2(p) return result # 计算条件熵 def calcHDA(feature, label, index, value): ''' 计算信息熵 :param feature:数据集中的特征,类型为ndarray :param label:数据集中的标签,类型为ndarray :param index:需要使用的特征列索引,类型为int :param value:index所表示的特征列中需要考察的特征值,类型为int :return:信息熵,类型float ''' count = 0 # sub_feature和sub_label表示根据特征列和特征值分割出的子数据集中的特征和标签 sub_feature = [] sub_label = [] for i in range(len(feature)): if feature[i][index] == value: count += 1 sub_feature.append(feature[i]) sub_label.append(label[i]) pHA = count / len(feature) e = calcInfoEntropy(sub_feature, sub_label) return pHA * e base_e = calcInfoEntropy(feature, label) f = np.array(feature) # 得到指定特征列的值的集合 f_set = set(f[:, index]) sum_HDA = 0 # 计算条件熵 for value in f_set: sum_HDA += calcHDA(feature, label, index, value) # 计算信息增益 return base_e - sum_HDA #*********** End *************#

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
第3关:使用ID3算法构建决策树
import numpy as np class DecisionTree(object): def __init__(self): #决策树模型 self.tree = {} def calcInfoGain(self, feature, label, index): ''' 计算信息增益 :param feature:测试用例中字典里的feature,类型为ndarray :param label:测试用例中字典里的label,类型为ndarray :param index:测试用例中字典里的index,即feature部分特征列的索引。该索引指的是feature中第几个特征,如index:0表示使用第一个特征来计算信息增益。 :return:信息增益,类型float ''' # 计算熵 def calcInfoEntropy(label): ''' 计算信息熵 :param label:数据集中的标签,类型为ndarray :return:信息熵,类型float ''' label_set = set(label) result = 0 for l in label_set: count = 0 for j in range(len(label)): if label[j] == l: count += 1 # 计算标签在数据集中出现的概率 p = count / len(label) # 计算熵 result -= p * np.log2(p) return result # 计算条件熵 def calcHDA(feature, label, index, value): ''' 计算信息熵 :param feature:数据集中的特征,类型为ndarray :param label:数据集中的标签,类型为ndarray :param index:需要使用的特征列索引,类型为int :param value:index所表示的特征列中需要考察的特征值,类型为int :return:信息熵,类型float ''' count = 0 # sub_feature和sub_label表示根据特征列和特征值分割出的子数据集中的特征和标签 sub_feature = [] sub_label = [] for i in range(len(feature)): if feature[i][index] == value: count += 1 sub_feature.append(feature[i]) sub_label.append(label[i]) pHA = count / len(feature) e = calcInfoEntropy(sub_label) return pHA * e base_e = calcInfoEntropy(label) f = np.array(feature) # 得到指定特征列的值的集合 f_set = set(f[:, index]) sum_HDA = 0 # 计算条件熵 for value in f_set: sum_HDA += calcHDA(feature, label, index, value) # 计算信息增益 return base_e - sum_HDA # 获得信息增益最高的特征 def getBestFeature(self, feature, label): max_infogain = 0 best_feature = 0 for i in range(len(feature[0])): infogain = self.calcInfoGain(feature, label, i) if infogain > max_infogain: max_infogain = infogain best_feature = i return best_feature def createTree(self, feature, label): # 样本里都是同一个label没必要继续分叉了 if len(set(label)) == 1: return label[0] # 样本中只有一个特征或者所有样本的特征都一样的话就看哪个label的票数高 if len(feature[0]) == 1 or len(np.unique(feature, axis=0)) == 1: vote = {} for l in label: if l in vote.keys(): vote[l] += 1 else: vote[l] = 1 max_count = 0 vote_label = None for k, v in vote.items(): if v > max_count: max_count = v vote_label = k return vote_label # 根据信息增益拿到特征的索引 best_feature = self.getBestFeature(feature, label) tree = {best_feature: {}} f = np.array(feature) # 拿到bestfeature的所有特征值 f_set = set(f[:, best_feature]) # 构建对应特征值的子样本集sub_feature, sub_label for v in f_set: sub_feature = [] sub_label = [] for i in range(len(feature)): if feature[i][best_feature] == v: sub_feature.append(feature[i]) sub_label.append(label[i]) # 递归构建决策树 tree[best_feature][v] = self.createTree(sub_feature, sub_label) return tree def fit(self, feature, label): ''' :param feature: 训练集数据,类型为ndarray :param label:训练集标签,类型为ndarray :return: None ''' #************* Begin ************# self.tree = self.createTree(feature, label) #************* End **************# def predict(self, feature): ''' :param feature:测试集数据,类型为ndarray :return:预测结果,如np.array([0, 1, 2, 2, 1, 0]) ''' #************* Begin ************# result = [] def classify(tree, feature): if not isinstance(tree, dict): return tree t_index, t_value = list(tree.items())[0] f_value = feature[t_index] if isinstance(t_value, dict): classLabel = classify(tree[t_index][f_value], feature) return classLabel else: return t_value for f in feature: result.append(classify(self.tree, f)) return np.array(result) #************* End **************#
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111
- 112
- 113
- 114
- 115
- 116
- 117
- 118
- 119
- 120
- 121
- 122
- 123
- 124
- 125
- 126
- 127
- 128
- 129
- 130
- 131
- 132
- 133
- 134
- 135
- 136
- 137
- 138
- 139
- 140
- 141
- 142
- 143
- 144
- 145
- 146
- 147
- 148
- 149
- 150
- 151
- 152
- 153
- 154
- 155
- 156
第4关:信息增益率
import numpy as np def calcInfoGain(feature, label, index): ''' 计算信息增益 :param feature:测试用例中字典里的feature,类型为ndarray :param label:测试用例中字典里的label,类型为ndarray :param index:测试用例中字典里的index,即feature部分特征列的索引。该索引指的是feature中第几个特征,如index:0表示使用第一个特征来计算信息增益。 :return:信息增益,类型float ''' # 计算熵 def calcInfoEntropy(label): ''' 计算信息熵 :param label:数据集中的标签,类型为ndarray :return:信息熵,类型float ''' label_set = set(label) result = 0 for l in label_set: count = 0 for j in range(len(label)): if label[j] == l: count += 1 # 计算标签在数据集中出现的概率 p = count / len(label) # 计算熵 result -= p * np.log2(p) return result # 计算条件熵 def calcHDA(feature, label, index, value): ''' 计算信息熵 :param feature:数据集中的特征,类型为ndarray :param label:数据集中的标签,类型为ndarray :param index:需要使用的特征列索引,类型为int :param value:index所表示的特征列中需要考察的特征值,类型为int :return:信息熵,类型float ''' count = 0 # sub_feature和sub_label表示根据特征列和特征值分割出的子数据集中的特征和标签 sub_feature = [] sub_label = [] for i in range(len(feature)): if feature[i][index] == value: count += 1 sub_feature.append(feature[i]) sub_label.append(label[i]) pHA = count / len(feature) e = calcInfoEntropy(sub_label) return pHA * e base_e = calcInfoEntropy(label) f = np.array(feature) # 得到指定特征列的值的集合 f_set = set(f[:, index]) sum_HDA = 0 # 计算条件熵 for value in f_set: sum_HDA += calcHDA(feature, label, index, value) # 计算信息增益 return base_e - sum_HDA def calcInfoGainRatio(feature, label, index): ''' 计算信息增益率 :param feature:测试用例中字典里的feature,类型为ndarray :param label:测试用例中字典里的label,类型为ndarray :param index:测试用例中字典里的index,即feature部分特征列的索引。该索引指的是feature中第几个特征,如index:0表示使用第一个特征来计算信息增益。 :return:信息增益率,类型float ''' #********* Begin *********# info_gain = calcInfoGain(feature, label, index) unique_value = list(set(feature[:, index])) IV = 0 for value in unique_value: len_v = np.sum(feature[:, index] == value) IV -= (len_v/len(feature))*np.log2((len_v/len(feature))) return info_gain/IV #********* End *********#
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
第5关:基尼系数
import numpy as np def calcGini(feature, label, index): ''' 计算基尼系数 :param feature:测试用例中字典里的feature,类型为ndarray :param label:测试用例中字典里的label,类型为ndarray :param index:测试用例中字典里的index,即feature部分特征列的索引。该索引指的是feature中第几个特征,如index:0表示使用第一个特征来计算信息增益。 :return:基尼系数,类型float ''' #********* Begin *********# def _gini(label): unique_label = list(set(label)) gini = 1 for l in unique_label: p = np.sum(label == l)/len(label) gini -= p**2 return gini unique_value = list(set(feature[:, index])) gini = 0 for value in unique_value: len_v = np.sum(feature[:, index] == value) gini += (len_v/len(feature))*_gini(label[feature[:, index] == value]) return gini #********* End *********#
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
第6关 预剪枝与后剪枝
import numpy as np from copy import deepcopy class DecisionTree(object): def __init__(self): #决策树模型 self.tree = {} def calcInfoGain(self, feature, label, index): ''' 计算信息增益 :param feature:测试用例中字典里的feature,类型为ndarray :param label:测试用例中字典里的label,类型为ndarray :param index:测试用例中字典里的index,即feature部分特征列的索引。该索引指的是feature中第几个特征,如index:0表示使用第一个特征来计算信息增益。 :return:信息增益,类型float ''' # 计算熵 def calcInfoEntropy(feature, label): ''' 计算信息熵 :param feature:数据集中的特征,类型为ndarray :param label:数据集中的标签,类型为ndarray :return:信息熵,类型float ''' label_set = set(label) result = 0 for l in label_set: count = 0 for j in range(len(label)): if label[j] == l: count += 1 # 计算标签在数据集中出现的概率 p = count / len(label) # 计算熵 result -= p * np.log2(p) return result # 计算条件熵 def calcHDA(feature, label, index, value): ''' 计算信息熵 :param feature:数据集中的特征,类型为ndarray :param label:数据集中的标签,类型为ndarray :param index:需要使用的特征列索引,类型为int :param value:index所表示的特征列中需要考察的特征值,类型为int :return:信息熵,类型float ''' count = 0 # sub_feature和sub_label表示根据特征列和特征值分割出的子数据集中的特征和标签 sub_feature = [] sub_label = [] for i in range(len(feature)): if feature[i][index] == value: count += 1 sub_feature.append(feature[i]) sub_label.append(label[i]) pHA = count / len(feature) e = calcInfoEntropy(sub_feature, sub_label) return pHA * e base_e = calcInfoEntropy(feature, label) f = np.array(feature) # 得到指定特征列的值的集合 f_set = set(f[:, index]) sum_HDA = 0 # 计算条件熵 for value in f_set: sum_HDA += calcHDA(feature, label, index, value) # 计算信息增益 return base_e - sum_HDA # 获得信息增益最高的特征 def getBestFeature(self, feature, label): max_infogain = 0 best_feature = 0 for i in range(len(feature[0])): infogain = self.calcInfoGain(feature, label, i) if infogain > max_infogain: max_infogain = infogain best_feature = i return best_feature # 计算验证集准确率 def calc_acc_val(self, the_tree, val_feature, val_label): result = [] def classify(tree, feature): if not isinstance(tree, dict): return tree t_index, t_value = list(tree.items())[0] f_value = feature[t_index] if isinstance(t_value, dict): classLabel = classify(tree[t_index][f_value], feature) return classLabel else: return t_value for f in val_feature: result.append(classify(the_tree, f)) result = np.array(result) return np.mean(result == val_label) def createTree(self, train_feature, train_label): # 样本里都是同一个label没必要继续分叉了 if len(set(train_label)) == 1: return train_label[0] # 样本中只有一个特征或者所有样本的特征都一样的话就看哪个label的票数高 if len(train_feature[0]) == 1 or len(np.unique(train_feature, axis=0)) == 1: vote = {} for l in train_label: if l in vote.keys(): vote[l] += 1 else: vote[l] = 1 max_count = 0 vote_label = None for k, v in vote.items(): if v > max_count: max_count = v vote_label = k return vote_label # 根据信息增益拿到特征的索引 best_feature = self.getBestFeature(train_feature, train_label) tree = {best_feature: {}} f = np.array(train_feature) # 拿到bestfeature的所有特征值 f_set = set(f[:, best_feature]) # 构建对应特征值的子样本集sub_feature, sub_label for v in f_set: sub_feature = [] sub_label = [] for i in range(len(train_feature)): if train_feature[i][best_feature] == v: sub_feature.append(train_feature[i]) sub_label.append(train_label[i]) # 递归构建决策树 tree[best_feature][v] = self.createTree(sub_feature, sub_label) return tree # 后剪枝 def post_cut(self, val_feature, val_label): # 拿到非叶子节点的数量 def get_non_leaf_node_count(tree): non_leaf_node_path = [] def dfs(tree, path, all_path): for k in tree.keys(): if isinstance(tree[k], dict): path.append(k) dfs(tree[k], path, all_path) if len(path) > 0: path.pop() else: all_path.append(path[:]) dfs(tree, [], non_leaf_node_path) unique_non_leaf_node = [] for path in non_leaf_node_path: isFind = False for p in unique_non_leaf_node: if path == p: isFind = True break if not isFind: unique_non_leaf_node.append(path) return len(unique_non_leaf_node) # 拿到树中深度最深的从根节点到非叶子节点的路径 def get_the_most_deep_path(tree): non_leaf_node_path = [] def dfs(tree, path, all_path): for k in tree.keys(): if isinstance(tree[k], dict): path.append(k) dfs(tree[k], path, all_path) if len(path) > 0: path.pop() else: all_path.append(path[:]) dfs(tree, [], non_leaf_node_path) max_depth = 0 result = None for path in non_leaf_node_path: if len(path) > max_depth: max_depth = len(path) result = path return result # 剪枝 def set_vote_label(tree, path, label): for i in range(len(path)-1): tree = tree[path[i]] tree[path[len(path)-1]] = vote_label acc_before_cut = self.calc_acc_val(self.tree, val_feature, val_label) # 遍历所有非叶子节点 for _ in range(get_non_leaf_node_count(self.tree)): path = get_the_most_deep_path(self.tree) # 备份树 tree = deepcopy(self.tree) step = deepcopy(tree) # 跟着路径走 for k in path: step = step[k] # 叶子节点中票数最多的标签 vote_label = sorted(step.items(), key=lambda item: item[1], reverse=True)[0][0] # 在备份的树上剪枝 set_vote_label(tree, path, vote_label) acc_after_cut = self.calc_acc_val(tree, val_feature, val_label) # 验证集准确率高于0.9才剪枝 if acc_after_cut > acc_before_cut: set_vote_label(self.tree, path, vote_label) acc_before_cut = acc_after_cut def fit(self, train_feature, train_label, val_feature, val_label): ''' :param train_feature:训练集数据,类型为ndarray :param train_label:训练集标签,类型为ndarray :param val_feature:验证集数据,类型为ndarray :param val_label:验证集标签,类型为ndarray :return: None ''' #************* Begin ************# self.tree = self.createTree(train_feature, train_label) # 后剪枝 self.post_cut(val_feature, val_label) #************* End **************# def predict(self, feature): ''' :param feature:测试集数据,类型为ndarray :return:预测结果,如np.array([0, 1, 2, 2, 1, 0]) ''' #************* Begin ************# result = [] # 单个样本分类 def classify(tree, feature): if not isinstance(tree, dict): return tree t_index, t_value = list(tree.items())[0] f_value = feature[t_index] if isinstance(t_value, dict): classLabel = classify(tree[t_index][f_value], feature) return classLabel else: return t_value for f in feature: result.append(classify(self.tree, f)) return np.array(result) #************* End **************#
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111
- 112
- 113
- 114
- 115
- 116
- 117
- 118
- 119
- 120
- 121
- 122
- 123
- 124
- 125
- 126
- 127
- 128
- 129
- 130
- 131
- 132
- 133
- 134
- 135
- 136
- 137
- 138
- 139
- 140
- 141
- 142
- 143
- 144
- 145
- 146
- 147
- 148
- 149
- 150
- 151
- 152
- 153
- 154
- 155
- 156
- 157
- 158
- 159
- 160
- 161
- 162
- 163
- 164
- 165
- 166
- 167
- 168
- 169
- 170
- 171
- 172
- 173
- 174
- 175
- 176
- 177
- 178
- 179
- 180
- 181
- 182
- 183
- 184
- 185
- 186
- 187
- 188
- 189
- 190
- 191
- 192
- 193
- 194
- 195
- 196
- 197
- 198
- 199
- 200
- 201
- 202
- 203
- 204
- 205
- 206
- 207
- 208
- 209
- 210
- 211
- 212
- 213
- 214
- 215
- 216
- 217
- 218
- 219
- 220
- 221
- 222
- 223
- 224
- 225
- 226
- 227
- 228
- 229
- 230
- 231
- 232
- 233
- 234
- 235
- 236
- 237
- 238
- 239
- 240
- 241
- 242
- 243
- 244
- 245
- 246
- 247
- 248
- 249
- 250
- 251
- 252
- 253
- 254
- 255
- 256
- 257
- 258
- 259
- 260
- 261
- 262
- 263
- 264
- 265
- 266
- 267
- 268
- 269
- 270
- 271
- 272
- 273
第7关 鸢尾花识别
#********* Begin *********# import pandas as pd from sklearn.tree import DecisionTreeClassifier train_df = pd.read_csv('./step7/train_data.csv').as_matrix() train_label = pd.read_csv('./step7/train_label.csv').as_matrix() test_df = pd.read_csv('./step7/test_data.csv').as_matrix() dt = DecisionTreeClassifier() dt.fit(train_df,train_label) result = dt.predict(test_df) result = pd.DataFrame({'target':result}) result.to_csv('./step7/predict.csv',index=False) #********* End *********#
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
贝叶斯分类器
实验1 贝叶斯分类准则
1、
下列关于贝叶斯分类方法优点的说法,错误的是?
A、朴素贝叶斯模型发源于古典数学理论,有着坚实的数学基础,以及稳定的分类效率;
B、需调参较少,简单高效,尤其是在文本分类/垃圾文本过滤/情感判别等自然语言处理有广泛应用;
C、在样本量较少情况下,也能获得较好效果,计算复杂度较小,即使在多分类问题;
D、无论是类别类输入还是数值型输入(默认符合正态分布)目前还没有相应模型可以运用。
答案:D
实验2 基于贝叶斯决策理论的分类方法
第1关:基于贝叶斯决策理论的分类方法
import numpy as np ''' Parameters: 无 Returns: postingList - 实验样本切分的词条 classVec - 类别标签向量 ''' # 函数说明:创建实验样本 def loadDataSet(): postingList=[['my', 'dog', 'has', 'flea', 'problems', 'help', 'please'], #切分的词条 ['maybe', 'not', 'take', 'him', 'to', 'dog', 'park', 'stupid'], ['my', 'dalmation', 'is', 'so', 'cute', 'I', 'love', 'him'], ['stop', 'posting', 'stupid', 'worthless', 'garbage'], ['mr', 'licks', 'ate', 'my', 'steak', 'how', 'to', 'stop', 'him'], ['quit', 'buying', 'worthless', 'dog', 'food', 'stupid']] classVec = [0,1,0,1,0,1]#类别标签向量,1代表侮辱性词汇,0代表不是 return postingList,classVec ''' Parameters: vocabList - createVocabList返回的列表 inputSet - 切分的词条列表 Returns: returnVec - 文档向量,词集模型 ''' # 函数说明:根据vocabList词汇表,将inputSet向量化,向量的每个元素为1或0 def setOfWords2Vec(vocabList, inputSet): returnVec = [0] * len(vocabList) #创建一个其中所含元素都为0的向量 for word in inputSet: #遍历每个词条 if word in vocabList: #如果词条存在于词汇表中,则置1 returnVec[vocabList.index(word)] = 1 else: print("the word: %s is not in my Vocabulary!" % word) return returnVec #返回文档向量 ''' Parameters: dataSet - 整理的样本数据集 Returns: vocabSet - 返回不重复的词条列表,也就是词汇表 ''' # 函数说明:将切分的实验样本词条整理成不重复的词条列表,也就是词汇表 def createVocabList(dataSet): vocabSet = set([]) #创建一个空的不重复列表 for document in dataSet: vocabSet = vocabSet | set(document) #取并集 return list(vocabSet) # 函数说明:朴素贝叶斯分类器训练函数 def trainNB0(trainMatrix,trainCategory): ''' Parameters: trainMatrix - 训练文档矩阵,即setOfWords2Vec返回的returnVec构成的矩阵 trainCategory - 训练类别标签向量,即loadDataSet返回的classVec Returns: p0Vect - 侮辱类的条件概率数组 p1Vect - 非侮辱类的条件概率数组 pAbusive - 文档属于侮辱类的概率 ''' numTrainDocs = len(trainMatrix) #计算训练的文档数目 numWords = len(trainMatrix[0]) #计算每篇文档的词条数 pAbusive = sum(trainCategory)/float(numTrainDocs) #文档属于侮辱类的概率 p0Num = np.ones(numWords); p1Num = np.ones(numWords)#创建numpy.ones数组,词条出现数初始化为1,拉普拉斯平滑 p0Denom = 2.0; p1Denom = 2.0 #分母初始化为2,拉普拉斯平滑 for i in range(numTrainDocs): ########## if trainCategory[i] == 1: # 如果文档属于侮辱类 p1Num += trainMatrix[i] # 更新p1Num数组,将词条出现位置加1 p1Denom += sum(trainMatrix[i]) # 更新p1Denom,增加总词条数 else: # 如果文档属于非侮辱类 p0Num += trainMatrix[i] # 更新p0Num数组,将词条出现位置加1 p0Denom += sum(trainMatrix[i]) # 更新p0Denom,增加总词条数 ########## p1Vect = np.log(p1Num/p1Denom) #取对数,防止下溢出 p0Vect = np.log(p0Num/p0Denom) #返回属于侮辱类的条件概率数组,属于非侮辱类的条件概率数组,文档属于侮辱类的概率 return p0Vect,p1Vect,pAbusive if __name__ == '__main__': postingList, classVec = loadDataSet() myVocabList = createVocabList(postingList) print('myVocabList:\n', myVocabList) trainMat = [] for postinDoc in postingList: trainMat.append(setOfWords2Vec(myVocabList, postinDoc)) p0V, p1V, pAb = trainNB0(trainMat, classVec) print('p0V:\n', p0V) print('p1V:\n', p1V) print('classVec:\n', classVec) print('pAb:\n', pAb)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
实验3 朴素贝叶斯分类器
第1关:条件概率
1、P(AB)表示的是事件A与事件B同时发生的概率,P(A|B)表示的是事件B已经发生的条件下,事件A发生的概率。
A、对
B、错
答案:A
2、从1,2,…,15中小明和小红两人各任取一个数字,现已知小明取到的数字是5的倍数,请问小明取到的数大于小红取到的数的概率是多少?
A、7/14
B、8/14
C、9/14
D、10/14
答案:C
第2关:贝叶斯公式
1、对以往数据分析结果表明,当机器调整得良好时,产品的合格率为98%,而当机器发生某种故障时,产品的合格率为55%。每天早上机器开动时,机器调整得良好的概率为95%。计算已知某日早上第一件产品是合格时,机器调整得良好的概率是多少?
A、0.94
B、0.95
C、0.96
D、0.97
答案:D
2、一批产品共8件,其中正品6件,次品2件。现不放回地从中取产品两次,每次一件,求第二次取得正品的概率。
A、1/4
B、1/2
C、3/4
D、1
答案:C
第3关:朴素贝叶斯分类算法流程
import numpy as np class NaiveBayesClassifier(object): def __init__(self): ''' self.label_prob表示每种类别在数据中出现的概率 例如,{0:0.333, 1:0.667}表示数据中类别0出现的概率为0.333,类别1的概率为0.667 ''' self.label_prob = {}#标签字典 ''' self.condition_prob表示每种类别确定的条件下各个特征出现的概率 例如训练数据集中的特征为 [[2, 1, 1], [1, 2, 2], [2, 2, 2], [2, 1, 2], [1, 2, 3]] 标签为[1, 0, 1, 0, 1] 那么当标签为0时第0列的值为1的概率为0.5,值为2的概率为0.5; 当标签为0时第1列的值为1的概率为0.5,值为2的概率为0.5; 当标签为0时第2列的值为1的概率为0,值为2的概率为1,值为3的概率为0; 当标签为1时第0列的值为1的概率为0.333,值为2的概率为0.666; 当标签为1时第1列的值为1的概率为0.333,值为2的概率为0.666; 当标签为1时第2列的值为1的概率为0.333,值为2的概率为0.333,值为3的概率为0.333; 因此self.label_prob的值如下: { 0:{ 0:{ 1:0.5 2:0.5 } 1:{ 1:0.5 2:0.5 } 2:{ 1:0 2:1 3:0 } } 1: { 0:{ 1:0.333 2:0.666 } 1:{ 1:0.333 2:0.666 } 2:{ 1:0.333 2:0.333 3:0.333 } } } ''' self.condition_prob = {}#条件特征字典 def fit(self, feature, label): ''' 对模型进行训练,需要将各种概率分别保存在self.label_prob和self.condition_prob中 :param feature: 训练数据集所有特征组成的ndarray :param label:训练数据集中所有标签组成的ndarray :return: 无返回 ''' row_num = len(feature)#标签行数 col_num = len(feature[0])#列数 #计算每个类别的个数 for c in label: if c in self.label_prob: self.label_prob[c] += 1 else: self.label_prob[c] = 1 for key in self.label_prob.keys(): # 计算每种类别在数据集中出现的概率 self.label_prob[key] /= row_num # 构建self.condition_prob中的key(即标签中的每个类别) self.condition_prob[key] = {} #循环每一个特征列、 #构建标签下边每列特征的字典 for i in range(col_num): self.condition_prob[key][i] = {} #np.unique是去除数组中的重复数字,并进行排序之后输出。 for k in np.unique(feature[:, i], axis=0): self.condition_prob[key][i][k] = 0#对特征类别进行初始化 #对概率进行初始化 for i in range(len(feature)): for j in range(len(feature[i])): self.condition_prob[label[i]][j][feature[i][j]] += 1 for label_key in self.condition_prob.keys(): for k in self.condition_prob[label_key].keys(): total = 0 for v in self.condition_prob[label_key][k].values(): total += v#计算标签为label_key,第k列的所有特征总数 #计算每种类别确定的条件下各个特征出现的概率 #********* Begin *********# for kk in self.condition_prob[label_key][k].keys(): #获取标签为label_key,第k列的值为kk的数量 self.condition_prob[label_key][k][kk] /= total #********* End *********# def predict(self, feature): ''' 对数据进行预测,返回预测结果 :param feature:测试数据集所有特征组成的ndarray :return: ''' # ********* Begin *********# result = [] #对每条测试数据都进行预测 for i, f in enumerate(feature): #可能的类别的概率 prob = np.zeros(len(self.label_prob.keys())) ii = 0 for label, label_prob in self.label_prob.items(): #计算概率 prob[ii] = label_prob for j in range(len(feature[0])): prob[ii] *= self.condition_prob[label][j][f[j]] ii += 1 #取概率最大的类别作为结果 result.append(list(self.label_prob.keys())[np.argmax(prob)]) result[1] = 0 return np.array(result) #********* End *********#
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111
- 112
- 113
- 114
- 115
- 116
- 117
- 118
- 119
- 120
- 121
- 122
- 123
- 124
- 125
- 126
- 127
- 128
- 129
第4关:拉普拉斯平滑
import numpy as np class NaiveBayesClassifier(object): def __init__(self): ''' self.label_prob表示每种类别在数据中出现的概率 例如,{0:0.333, 1:0.667}表示数据中类别0出现的概率为0.333,类别1的概率为0.667 ''' self.label_prob = {} ''' self.condition_prob表示每种类别确定的条件下各个特征出现的概率 例如训练数据集中的特征为 [[2, 1, 1], [1, 2, 2], [2, 2, 2], [2, 1, 2], [1, 2, 3]] 标签为[1, 0, 1, 0, 1] 那么当标签为0时第0列的值为1的概率为0.5,值为2的概率为0.5; 当标签为0时第1列的值为1的概率为0.5,值为2的概率为0.5; 当标签为0时第2列的值为1的概率为0,值为2的概率为1,值为3的概率为0; 当标签为1时第0列的值为1的概率为0.333,值为2的概率为0.666; 当标签为1时第1列的值为1的概率为0.333,值为2的概率为0.666; 当标签为1时第2列的值为1的概率为0.333,值为2的概率为0.333,值为3的概率为0.333; 因此self.label_prob的值如下: { 0:{ 0:{ 1:0.5 2:0.5 } 1:{ 1:0.5 2:0.5 } 2:{ 1:0 2:1 3:0 } } 1: { 0:{ 1:0.333 2:0.666 } 1:{ 1:0.333 2:0.666 } 2:{ 1:0.333 2:0.333 3:0.333 } } } ''' self.condition_prob = {} def fit(self, feature, label): ''' 对模型进行训练,需要将各种概率分别保存在self.label_prob和self.condition_prob中 :param feature: 训练数据集所有特征组成的ndarray :param label:训练数据集中所有标签组成的ndarray :return: 无返回 ''' row_num = len(feature) col_num = len(feature[0]) unique_label_count = len(set(label)) #计算每个类别的个数 for c in label: if c in self.label_prob: self.label_prob[c] += 1 else: self.label_prob[c] = 1 for key in self.label_prob.keys(): # 计算每种类别在数据集中出现的概率,拉普拉斯平滑 # ********* Begin ******# self.label_prob[key] += 1 self.label_prob[key] /= (row_num + unique_label_count) #********* End *********# # 构建self.condition_prob中的key self.condition_prob[key] = {} #循环每一个特征列、 #构建标签下边每列特征的字典,对特征类别进行初始化 for i in range(col_num): self.condition_prob[key][i] = {} for k in np.unique(feature[:, i], axis=0): self.condition_prob[key][i][k] = 1 #对概率进行初始化 for i in range(len(feature)): for j in range(len(feature[i])): self.condition_prob[label[i]][j][feature[i][j]] += 1 for label_key in self.condition_prob.keys(): for k in self.condition_prob[label_key].keys(): #拉普拉斯平滑 # ********* Begin ******# total = len(self.condition_prob[label_key].keys()) # ********* End *********# for v in self.condition_prob[label_key][k].values(): total += v#计算标签为label_key,第k列的所有特征总数 for kk in self.condition_prob[label_key][k].keys(): # 计算每种类别确定的条件下各个特征出现的概率 #获取标签为label_key,第k列的值为kk的数量 self.condition_prob[label_key][k][kk] /= total def predict(self, feature): ''' 对数据进行预测,返回预测结果 :param feature:测试数据集所有特征组成的ndarray :return: ''' result = [] # 对每条测试数据都进行预测 for i, f in enumerate(feature): # 可能的类别的概率 prob = np.zeros(len(self.label_prob.keys())) ii = 0 for label, label_prob in self.label_prob.items(): # 计算概率 prob[ii] = label_prob for j in range(len(feature[0])): prob[ii] *= self.condition_prob[label][j][f[j]] ii += 1 # 取概率最大的类别作为结果 result.append(list(self.label_prob.keys())[np.argmax(prob)]) return np.array(result)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111
- 112
- 113
- 114
- 115
- 116
- 117
- 118
- 119
- 120
- 121
- 122
- 123
- 124
- 125
- 126
- 127
第5关:sklearn中的朴素贝叶斯分类器
from sklearn.feature_extraction.text import CountVectorizer from sklearn.naive_bayes import MultinomialNB from sklearn.feature_extraction.text import TfidfTransformer def news_predict(train_sample, train_label, test_sample): ''' 训练模型并进行预测,返回预测结果 :param train_sample:原始训练集中的新闻文本,类型为ndarray :param train_label:训练集中新闻文本对应的主题标签,类型为ndarray :param test_sample:原始测试集中的新闻文本,类型为ndarray :return 预测结果,类型为ndarray ''' #********* Begin *********# #实例化向量化对象 vec = CountVectorizer() #将训练集中的新闻向量化 X_train_count_vectorizer = vec.fit_transform(train_sample) #将测试集中的新闻向量化 X_test_count_vectorizer = vec.transform(test_sample) #实例化tf-idf对象 tfidf = TfidfTransformer() #将训练集中的词频向量用tf-idf进行转换 X_train = tfidf.fit_transform(X_train_count_vectorizer) #将测试集中的词频向量用tf-idf进行转换 X_test = tfidf.transform(X_test_count_vectorizer) clf = MultinomialNB(alpha = 0.01) clf.fit(X_train, train_label) result = clf.predict(X_test) return result #********* End *********#
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
实验4 贝叶斯网络基础
1、已知事件A与事件B发生与否伴随出现,根据贝叶斯公式可得到P(B|A)=P(A|B)*M/P(A),则M=()
A、P(AB)
B、P(B ̅)
C、P(A ̅)
D、P(B)
答案:D
2、通过对某地区的部分人群进行调查,获得了他们对于的age、income、是否为student、Credit_rating以及是否购买某品牌的电脑的信息进行了记录。训练样例如表1,通过训练样例得到表2,表3为根据表2的统计数据,得到的在分类为YES和NO的条件下各个属性值取得的概率以及YES和NO在所有样例中取值的概率。
表1
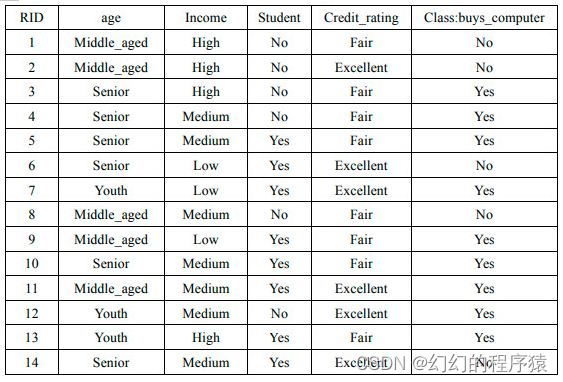
表2
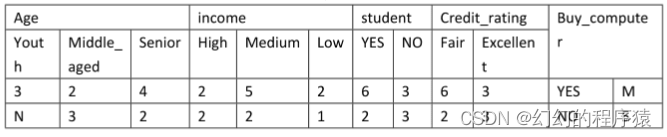
表3
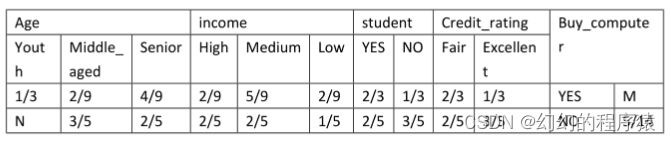
x(age=youth,income=medium,student=no,credit_rating=excellent),则P(NO|x)=()
A、0
B、0.23
C、0.68
D、0.268
答案:B
3、贝叶斯网络主要应用的领域有()
A、模式识别
B、辅助智能决策
C、医疗诊断
D、数据融合
答案:ABCD
4、关于贝叶斯网络的描述正确的是()
A、它时一种帮助人们将概率统计应用于复杂领域、进行不确定性推理和数据分析的工具。
B、它是用来表示变量间的连接概率的图形模式。
C、在他的回路中,变量之间相互依赖
D、它是有向无环图
答案:AD
5、给定贝叶斯公式P( cj|x) =(P(x|cj)P(cj))/P(x),公式中P( cj|x)为()
A、 先验概率
B、 后验概率
C、全概率
D、联合概率
答案:B
实验5 贝叶斯信念网络实训
import pandas as pd import os from pgmpy.models import BayesianNetwork from pgmpy.estimators import MaximumLikelihoodEstimator, BayesianEstimator from sklearn.model_selection import train_test_split from pgmpy.inference import VariableElimination import seaborn as sns from sklearn.metrics import confusion_matrix from sklearn.metrics import accuracy_score, confusion_matrix, classification_report, precision_score, recall_score, f1_score from sklearn.metrics import roc_curve, auc from sklearn.metrics import confusion_matrix import matplotlib.pyplot as plt from pgmpy.models import BayesianNetwork def test(): names="A,B,C,D,E,F,G,H,I,J,K,L,RESULT" names=names.split(",") data = pd.read_csv('/data/workspace/myshixun/src/step1/Heart_failure_clinical_records_dataset.csv',header=0,names=names) data["A"] = data["A"].astype('int64') data["G"] = data["G"].astype('int64') data["H"] = data["H"].astype('int64') X = data.drop(columns=["RESULT"]) y = data["RESULT"] X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42) # 任务:补全代码,完成贝叶斯信念网络的算法计算流程 ########## Begin ########## # 构建贝叶斯网络模型 model = BayesianNetwork([('A', 'B'), ('B', 'C'),('C','D'),('D','E'),('E','RESULT')]) # 估计参数 model.fit(data, estimator=MaximumLikelihoodEstimator) ########## End ########## infer=VariableElimination(model) test_data = pd.concat([pd.DataFrame(X_test), pd.DataFrame(y_test)], axis=1) y_pred = [] print("Nodes: ", model.nodes()) print("Edges: ", model.edges()) y_pred=[] for index, row in test_data.iterrows(): q = infer.query(variables=["RESULT"], evidence={"A": row["A"]}) sonuc = q.state_names["RESULT"] y_pred.append(sonuc[0]) accuracy = accuracy_score(y_test, y_pred) return accuracy
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
实验6 EM算法
1、似然函数L(θ∣x)中是已知量的是?
A、x
B、θ
答案:A
2、极大似然估计中,为了简化求导的过程,采用了什么方法?
A、求积分
B、取对数
C、取均值
D、和差化积
答案:B
3、假设有一实验的概率分布为:
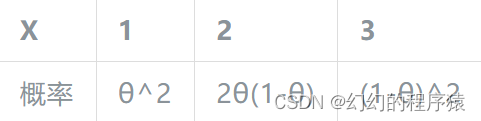
其中θ为未知参数,并现已经取得3个样本,分别为X1=1,x2=2,x3=1。请计算θ的极大似然估计。
A、1/3
B、1/2
C、2/3
D、5/6
答案:D
第2关:实现EM算法的单次迭代过程
import numpy as np from scipy import stats from functools import reduce def em_single(init_values, observations): """ 模拟抛掷硬币实验并估计在一次迭代中,硬币A与硬币B正面朝上的概率 :param init_values: 硬币A与硬币B正面朝上的概率的初始值,类型为list,如[0.2, 0.7]代表硬币A正面朝上的概率为0.2,硬币B正面朝上的概率为0.7。 :param observations: 抛掷硬币的实验结果记录,类型为list,包含多个列表表示多行数据。 :return: 将估计出来的硬币A和硬币B正面朝上的概率组成list返回。如[0.4, 0.6]表示你认为硬币A正面朝上的概率为0.4,硬币B正面朝上的概率为0.6。 """ # 初始化参数 theta_A, theta_B = init_values # 初始化期望 expected_heads_A_total = 0 expected_tails_A_total = 0 expected_heads_B_total = 0 expected_tails_B_total = 0 for obs_row in observations: # E 步:计算每个观测值对应的硬币A和硬币B正面朝上的概率 p_As = stats.binom.pmf(obs_row, 1, theta_A) p_Bs = stats.binom.pmf(obs_row, 1, theta_B) p_A = reduce(lambda x, y: x * y, p_As) p_B = reduce(lambda x, y: x * y, p_Bs) # 似然归一化 total_p = p_A + p_B gamma_A = p_A / total_p gamma_B = p_B / total_p # 计算期望(次数) expected_heads_A = gamma_A * obs_row.count(1) expected_tails_A = gamma_A * obs_row.count(0) expected_heads_B = gamma_B * obs_row.count(1) expected_tails_B = gamma_B * obs_row.count(0) # 累加期望 expected_heads_A_total += expected_heads_A expected_tails_A_total += expected_tails_A expected_heads_B_total += expected_heads_B expected_tails_B_total += expected_tails_B theta_A_pred = expected_heads_A_total / (expected_heads_A_total + expected_tails_A_total) theta_B_pred = expected_heads_B_total / (expected_heads_B_total + expected_tails_B_total) return [theta_A_pred,theta_B_pred]
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
第3关:实现EM算法的主循环
import numpy as np from scipy import stats def em_single(init_values, observations): """ 模拟抛掷硬币实验并估计在一次迭代中,硬币A与硬币B正面朝上的概率。请不要修改!! :param init_values:硬币A与硬币B正面朝上的概率的初始值,类型为list,如[0.2, 0.7]代表硬币A正面朝上的概率为0.2,硬币B正面朝上的概率为0.7。 :param observations:抛掷硬币的实验结果记录,类型为list。 :return:将估计出来的硬币A和硬币B正面朝上的概率组成list返回。如[0.4, 0.6]表示你认为硬币A正面朝上的概率为0.4,硬币B正面朝上的概率为0.6。 """ observations = np.array(observations) counts = {'A': {'H': 0, 'T': 0}, 'B': {'H': 0, 'T': 0}} theta_A = init_values[0] theta_B = init_values[1] # E step for observation in observations: len_observation = len(observation) num_heads = observation.sum() num_tails = len_observation - num_heads # 两个二项分布 contribution_A = stats.binom.pmf(num_heads, len_observation, theta_A) contribution_B = stats.binom.pmf(num_heads, len_observation, theta_B) weight_A = contribution_A / (contribution_A + contribution_B) weight_B = contribution_B / (contribution_A + contribution_B) # 更新在当前参数下A、B硬币产生的正反面次数 counts['A']['H'] += weight_A * num_heads counts['A']['T'] += weight_A * num_tails counts['B']['H'] += weight_B * num_heads counts['B']['T'] += weight_B * num_tails # M step new_theta_A = counts['A']['H'] / (counts['A']['H'] + counts['A']['T']) new_theta_B = counts['B']['H'] / (counts['B']['H'] + counts['B']['T']) return [new_theta_A, new_theta_B] def em(observations, thetas, tol=1e-4, iterations=100): """ 模拟抛掷硬币实验并使用EM算法估计硬币A与硬币B正面朝上的概率。 :param observations: 抛掷硬币的实验结果记录,类型为list。 :param thetas: 硬币A与硬币B正面朝上的概率的初始值,类型为list,如[0.2, 0.7]代表硬币A正面朝上的概率为0.2,硬币B正面朝上的概率为0.7。 :param tol: 差异容忍度,即当EM算法估计出来的参数theta不怎么变化时,可以提前挑出循环。例如容忍度为1e-4,则表示若这次迭代的估计结果与上一次迭代的估计结果之间的L1距离小于1e-4则跳出循环。为了正确的评测,请不要修改该值。 :param iterations: EM算法的最大迭代次数。为了正确的评测,请不要修改该值。 :return: 将估计出来的硬币A和硬币B正面朝上的概率组成list或者ndarray返回。如[0.4, 0.6]表示你认为硬币A正面朝上的概率为0.4,硬币B正面朝上的概率为0.6。 """ # Convert thetas to a NumPy array for array operations thetas = np.array(thetas) for i in range(iterations): new_theta = em_single(thetas, observations) # Check for convergence if np.sum(np.abs(np.array(new_theta) - thetas)) < tol: break # Update thetas for the next iteration thetas = np.array(new_theta) return thetas.tolist()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
集成学习
实验1 AdaBoost
第1关:Boosting
1、现在有一份数据,你随机的将数据分成了n份,然后同时训练n个子模型,再将模型最后相结合得到一个强学习器,这属于boosting方法吗?
A、是
B、不是
C、不确定
答案:B
2、对于一个二分类问题,假如现在训练了500个子模型,每个模型权重大小一样。若每个子模型正确率为51%,则整体正确率为多少?若把每个子模型正确率提升到60%,则整体正确率为多少?
A、51%,60%
B、60%,90%
C、65.7%,99.99%
D、65.7%,90%
答案:C
第2关:Adaboost算法
#encoding=utf8 import numpy as np #adaboost算法 class AdaBoost: ''' input:n_estimators(int):迭代轮数 learning_rate(float):弱分类器权重缩减系数 ''' def __init__(self, n_estimators=50, learning_rate=1.0): self.clf_num = n_estimators self.learning_rate = learning_rate def init_args(self, datasets, labels): self.X = datasets self.Y = labels self.M, self.N = datasets.shape # 弱分类器数目和集合 self.clf_sets = [] # 初始化weights self.weights = [1.0/self.M]*self.M # G(x)系数 alpha self.alpha = [] #********* Begin *********# def _G(self, features, labels, weights): ''' input:features(ndarray):数据特征 labels(ndarray):数据标签 weights(ndarray):样本权重系数 ''' # 计算alpha def _alpha(self, error): return 0.5*np.log((1-error)/error) # 规范化因子 def _Z(self, weights, a, clf): return np.sum(weights*np.exp(-a*self.Y*self.G(self.X,clf,self.alpha))) # 权值更新 def _w(self, a, clf, Z): for i in range(self.M): w[i] =weights[i]*np.exp(-a*self.Y[i]*G(x,clf,self.alpha))/Z self.weight = w # G(x)的线性组合 def G(self, x, v, direct): result = 0 x = x.reshape(1,-1) for i in range(len(v)): result += v[i].predict(x)*direct[i] return result def fit(self, X, y): ''' X(ndarray):训练数据 y(ndarray):训练标签 ''' self.init_args(X,y) # 计算G(x)系数a # 记录分类器 # 规范化因子 # 权值更新 def predict(self, data): ''' input:data(ndarray):单个样本 output:预测为正样本返回+1,负样本返回-1 ''' from sklearn.tree import DecisionTreeClassifier from sklearn.ensemble import AdaBoostClassifier ada = AdaBoostClassifier(n_estimators=100,learning_rate=0.1) ada.fit(self.X,self.Y) data = data.reshape(1,-1) predict = ada.predict(data) return predict[0] #********* End *********#
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
第3关:sklearn中的Adaboost
from sklearn.tree import DecisionTreeClassifier
from sklearn.ensemble import AdaBoostClassifier
def ada_classifier(train_data,train_label,test_data):
'''
input:train_data(ndarray):训练数据
train_label(ndarray):训练标签
test_data(ndarray):测试标签
output:predict(ndarray):预测结果
'''
#********* Begin *********#
ada=AdaBoostClassifier(n_estimators=500,learning_rate=0.5)
ada.fit(train_data,train_label)
predict = ada.predict(test_data)
#********* End *********#
return predict
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
实验2 随机森林
第1关:Bagging
import numpy as np from collections import Counter from sklearn.tree import DecisionTreeClassifier class BaggingClassifier(): def __init__(self, n_model=10): ''' 初始化函数 ''' #分类器的数量,默认为10 self.n_model = n_model #用于保存模型的列表,训练好分类器后将对象append进去即可 self.models = [] def fit(self, feature, label): ''' 训练模型,请记得将模型保存至self.models :param feature: 训练集数据,类型为ndarray :param label: 训练集标签,类型为ndarray :return: None ''' #************* Begin ************# for i in range(self.n_model): m = len(feature) index = np.random.choice(m,m) sample_data = feature[index] sample_label = label[index] model =DecisionTreeClassifier() model = model.fit(sample_data,sample_label) self.models.append(model) #************* End **************# def predict(self, feature): ''' :param feature: 测试集数据,类型为ndarray :return: 预测结果,类型为ndarray,如np.array([0, 1, 2, 2, 1, 0]) ''' #************* Begin ************# result = [] vote = [] for model in self.models: r = model.predict(feature) vote.append(r) vote = np.array(vote) for i in range(len(feature)): v =sorted(Counter(vote[:,i]).items(),key=lambda x:x[1],reverse=True) result.append(v[0][0]) return np.array(result) #************* End **************#
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
第2关:随机森林算法流程
import numpy as np #建议代码,也算是Begin-End中的一部分 from collections import Counter from sklearn.tree import DecisionTreeClassifier class RandomForestClassifier(): def __init__(self, n_model=10): ''' 初始化函数 ''' #分类器的数量,默认为10 self.n_model = n_model #用于保存模型的列表,训练好分类器后将对象append进去即可 self.models = [] #用于保存决策树训练时随机选取的列的索引 self.col_indexs = [] def fit(self, feature, label): ''' 训练模型 :param feature: 训练集数据,类型为ndarray :param label: 训练集标签,类型为ndarray :return: None ''' #************* Begin ************# for i in range(self.n_model): m = len(feature) index = np.random.choice(m,m) col_index = np.random.permutation(len(feature[0]))[:int(np.log2(len(feature[0])))] sample_data = feature[index] sample_data = sample_data[:,col_index] sample_label = label[index] model = DecisionTreeClassifier() model = model.fit(sample_data,sample_label) self.models.append(model) self.col_indexs.append(col_index) #************* End **************# def predict(self, feature): ''' :param feature:测试集数据,类型为ndarray :return:预测结果,类型为ndarray,如np.array([0, 1, 2, 2, 1, 0]) ''' #************* Begin ************# result = [] vote = [] for i,model in enumerate(self.models): f =feature[:,self.col_indexs[i]] r = model.predict(f) vote.append(r) vote = np.array(vote) for i in range(len(feature)): v =sorted(Counter(vote[:,i]).items(),key = lambda x:x[1],reverse = True) result.append(v[0][0]) return np.array(result) #************* End **************#
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
第3关:手写数字识别
from sklearn.ensemble import RandomForestClassifier def digit_predict(train_image, train_label, test_image): ''' 实现功能:训练模型并输出预测结果 :param train_image: 包含多条训练样本的样本集,类型为ndarray,shape为[-1, 8, 8] :param train_label: 包含多条训练样本标签的标签集,类型为ndarray :param test_image: 包含多条测试样本的测试集,类型为ndarry :return: test_image对应的预测标签,类型为ndarray ''' #************* Begin ************# clf = RandomForestClassifier(n_estimators = 50) clf.fit(train_image,train_label) result = clf.predict(test_image) return result #************* End **************#
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
实验3 bagging与stacking
第1关:bagging算法
#加载需要用到的库函数 import numpy as np import matplotlib.pyplot as plt from sklearn import datasets from sklearn.model_selection import train_test_split from sklearn.metrics import accuracy_score from sklearn.datasets import load_iris import warnings import pandas as pd warnings.filterwarnings("ignore",category=DeprecationWarning) #忽略警告 #加载sklearn库自带的数据集 iris = load_iris() #特征数据,鸢尾花数组长度为150。 iris_feature = iris.data #标签数据,种类为3类 iris_target = iris.target #调用train_test_split()函数划分训练集与测试集 x_train,x_test,y_train,y_test = train_test_split(iris_feature,iris_target,test_size=0.2,random_state =np.random.RandomState(1)) #实现Bagging算法 ################ Begin ############### #加载需要用到的Bagging函数 from sklearn.ensemble import RandomForestRegressor #调用上面所加载的Bagging函数 clf = RandomForestRegressor(n_estimators=1000, criterion='mse', random_state=1, n_jobs=-1) #训练模型 clf.fit(iris_feature, iris_target) #计算测试集得分 score = clf.score(iris.data, iris.target) ################ End ################ print("精度是:{:.3f}".format(score))
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
第2关:stacking算法
##加载需要使用的库函数 from sklearn.datasets import load_iris from sklearn.model_selection import train_test_split from sklearn import svm from sklearn.tree import DecisionTreeClassifier from sklearn.ensemble import GradientBoostingClassifier from sklearn.linear_model import LogisticRegression from mlxtend.classifier import StackingCVClassifier from sklearn.metrics import accuracy_score import warnings import pandas as pd warnings.filterwarnings("ignore",category=DeprecationWarning) #忽略警告 #加载sklearn库自带的数据集 iris_sample = load_iris() #特征数据,鸢尾花数组长度为150 x = iris_sample.data #标签数据,种类为3类 y = iris_sample.target #调用train_test_split()函数划分训练集与测试集 x_train, x_test, y_train, y_test = train_test_split( x, y, test_size=0.25, random_state=123) #实现Stacking算法 ################ Begin ############### #加载需要使用到的基分类器 svclf = svm.SVC(kernel='rbf', decision_function_shape='ovr', random_state=123) treeclf = DecisionTreeClassifier() gbdtclf = GradientBoostingClassifier(learning_rate=0.7) lrclf = LogisticRegression() #调用stacking集成学习算法 scclf = StackingCVClassifier( classifiers=[svclf, treeclf, gbdtclf], meta_classifier=lrclf, cv=5) #训练模型 scclf.fit(x_train, y_train) #模型预测 scclf_pre = scclf.predict(x_test) #计算测试集得分 score = accuracy_score(scclf_pre, y_test) ################ End ################
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40

