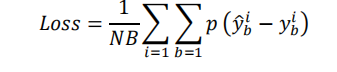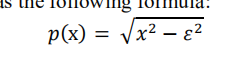- 1XUbuntu22.04之安装OBS30.0强大录屏工具(一百九十五)_ubuntu22.04.3安装录屏软件
- 2基于STM32的倒车雷达系统设计_rd-3雷达模块stm32
- 3SpringBoot+redis实现消息队列(发布/订阅)_org.springframework.data.redis.listener.redismessa
- 4AIGC - 高考语文作文全国篇
- 5编译原理:算符优先分析实验_算符优先分析法实验
- 6机器人学:(3)机器人运动学
- 7PaddleHub一键OCR中文识别 身份证识别_paddlehub 身份证识别
- 8探索微软Edge浏览器:一款现代浏览器的详细评测
- 9生信数据分析——GO+KEGG富集分析_go富集分析
- 10智能建筑与物联网技术:重塑未来空间的智慧交响曲
Triple Attention Mixed Link Network for Single Image Super Resolution_三重注意力机制
赞
踩
该文章主要内容为通过添加三重注意力机制来增强超分效果,实则就是提出了一个三重注意力机制的炒粉模型,首先从底层分析,三重注意力机制:①为一个传统的通道注意力机制,不过在此将全连接层变为卷积层实施升维和降维代码如下:


②提出了一个核注意力机制并列为该论文的创新点:主要思路是将不同卷积核提取出的不同感受野下的特征图提取出来进行融合(即逐元素相加)后通过一个通道注意力机制形成一个参数,注意这里为一个参数图上写了一个w1一个w2,最后在做一次特征融合形成核注意力机制后的特征图,这里其实一开始有个问题就是为什么要进行融合后统一进行一次通道注意力机制而不是在每一条支路上各自进行一次通道注意力机制,看似后者要比前者效果好,后来发现其实该注意力机制目的是为了注意不同感受野下的特征图,也就是说如果每条支路上都添加一个通道注意力机制则无法起到约束卷积核的效果即无法探测到参数为多少时可以使不同感受野下的融合的特征图效果达到最好。即通过反向传播设55的卷积卷积出的特征图为x,33卷积核卷积出的特征图为y,首先算出的损失误差反向传播到倒数第一层即xw,yw估算这两个参数对误差的贡献,在此之后为了估算哪些参数造成了损失的误差所以会对x,y,w作约束而注意这里对w作约束的时候其实是做了两个约束一个与x有关一个与y有关,通过两次约束约束生成的参数使参数尽量向关注33和55两个感受野的方向发展,从而生成了核注意力机制,以下为代码和示例图:

其中frm为上面定义的通道注意力机制
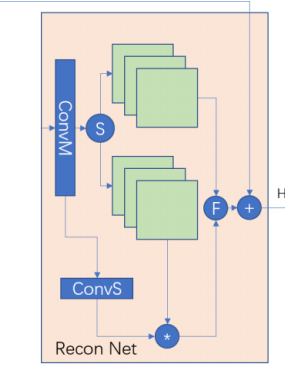
③空间注意力机制此处空间注意力机制加在重构网络中,先通过卷积使通道数加倍后将加倍后的通道均匀分割成大小相等的两部分,比如输入为64先升维至128后将其分割成64,64因为这里其实是为了自适应的得到全局信息因此分割方法并不影响结果,只要融合了全局信息即可,在此之后将一部分(即64通道的特征图)作为局部特征图,另一部分与通过初始状态降维(即将升维后的特征图经过卷积降维到1),即通过卷积非线性映射自适应的生成的一个单通道包含全局信息(此处全局信息指的不为卷积核感受野大小而是通道维度的全局信息)的权值矩阵进行逐元素相乘将全局信息融合进特征图,在此之后将两部分特征图进行融合从而利用端到端将全局信息与局部信息融合入特征图
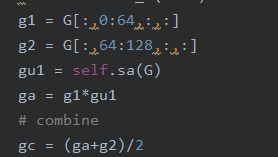
此处代码最后/2因为将生成的128张特征图拆为两部分融合全局信息后在相加会使许多局部特征*2因此这里作/2处理。
从全局来看此网络用了Mixed link net 该网络通过局部残差和局部密集来减小残差网络和密集网络带来的问题即残差网络大部分时间都会在高频部分叠加信息,可能会造成信息覆盖阻断信息流,而密集网络则是许多曾提取到的特征相同会造成冗余,因此提出该网络通过不断在网络左端进行拼接和残差从而减小冗余和信息流失,另外还大量减少了参数,此处mixed link net在上周论文博客有详细解释。而这样使用残差和密集也会带来一个问题即残差和密集不完整,特别是密集可能会导致损失掉部分信息,为了缓解这种情况,该论文使用了多级监督,从而通过损失函数约束各级块减少信息损失,每个块内先通过一个核注意力机制再通过一个通道注意力机制生成一个小块,后经过mixed link net 连接生成一个大块并用重建网络和损失函数进行约束生成高分辨率图片,训练过程中每个块都会进行一次损失监督生成特征图,而再测试阶段只会取最后一个块生成的高分辨率图片作为最终结果。

其中一开始从第一层浅特征提取层连接的残差为连接到各层块中并不是只连接到最后一个块上,下面为一个块的细化结构


该网络的损失为一个简单的均方差损失,不过在最后设置了一个极小的数为了约束其损失不能为0防止过拟合