
- 1List的Stream流操作_list stream
- 2Python保存为json中文Unicode乱码解决json.dump()_python json dump中文
- 3《产品经理面试攻略》PART 12:产品总监职业生涯访谈_课程产品总监 面谈
- 4LeetCode 算法:二叉树的直径 c++
- 501 x86 32位Linux进程虚拟地址空间区域划分_32位linux x86架构cpu,应用进程内存空间范围
- 6【ChatGPT修改论文】【中/英双语】GPT论文指令合集(润色、语法修改、降重)_chatgpt英文论文修改指令
- 77 年算法工程师的工作总结,太精辟了!
- 8电子邮件收发原理和实现(POP3, SMTP) [整理]
- 9elasticsearch7.x在k8s中的部署_kubect部署elasticsearch
- 1030个Kafka常见错误小集合_kafka无法查看topic报错
Transformer31_transformer网络需要现在imagenet1k数据上先预训练吗?
赞
踩
这次是用于密集预测任务的视觉 Transformer Adapter , ViT-Adapter
一种用于使得 ViT 架构适配下游密集预测任务的 Adapter。简单的 ViT 模型,加上这种 Adapter 之后,下游密集预测任务的性能变强不少。本文给出的 ViT-Adapter-L 在 COCO 数据集上达到了 60.9 的 box AP 和 59.3 的 mask AP。
我们之前使用 Vision Transformer 做下游任务的时候,因为 ViT 缺乏局部归纳偏置,所以人们提出一些为了下游任务而设计的 ViT 替代增强版,作者称之为:Vision-Specific Transformer,比如 Swin,PVT 等等。但是,你仔细观察就会发现这些模型只是名字和 ViT 相像,但却再也不是真正的 ViT 了,或多或少都掺杂了 CNN 的影子,初心没了。
为了弥补这个遗憾,本文提出了 ViT-Adapter,只用 ViT 作为密集预测任务的基本架构,不使用任何花里胡哨的替代增强版 (Vision-Specific Transformer)。使用最原始的 ViT,就是为了利用它跨模态学习 (multi-modal pre-training) 的强大潜质。当迁移到下游的密集预测任务时,使用一个无需预训练的 Adapter 将与图像相关的归纳偏置引入 ViT,使其适合这些任务。
本文给出的 ViT-Adapter-L 在 COCO 数据集上达到了 60.9 的 box AP 和 59.3 的 mask AP。
ViT-Adapter:用于密集预测任务的视觉 Transformer Adapter
论文名称:Vision Transformer Adapter for Dense Predictions
论文地址:
https://arxiv.org/pdf/2205.08534.pdf
近年来,Transformer 模型,得益于其动态建模的能力和长程依赖性,在计算机视觉领域取得了巨大的成功。使用 Vision Transformer 做下游任务的时候,用到的模型主要分为两大类:第1种是最朴素的直筒型 ViT[1],第2种是金字塔形状的 ViT 替代增强版,比如 Swin[2],CSwin[3],PVT[4] 等。一般来说,第2种可以产生更好的结果,人们认为这些模型通过使用局部空间操作将 CNN 存在的归纳偏置引入到 ViT 结构中。但是,你仔细观察就会发现这些模型只是名字和 ViT 相像,但却再也不是真正的 ViT 了,或多或少都掺杂了 CNN 的影子,初心没了。
问:为什么希望重新研究最朴素的直筒型 ViT 呢?
答: 因为这种最朴素的结构具有一些不可忽视的优势,即:多模态预训练 (multi-modal pre-training) 方面的优势。代表性的工作有:[5][6]。朴素的直筒型 ViT 和 Transformer 架构很类似,没有输入数据的假设。普通的 ViT 可以使用大量多模态数据进行预训练,包括图像、视频和文本,这鼓励模型学习到丰富的语义表示。
但是,这种最朴素的结构由于缺乏必要的与图像相关的归纳偏置,相较于 ViT 替代增强版会导致较慢的收敛过程和较低的下游任务性能。所以,这篇文章提出了一种用于使得 ViT 架构适配下游密集预测任务的 Adapter。ViT 模型,加上这种 Adapter 之后,下游下游密集预测任务的性能变强不少,即:
朴素的 ViT + 本文的 Adapter → 更强的下游任务性能
如下图1所示,Backbone 是一个普通 ViT,不仅可以用图像,还可以用多模态数据进行预训练。使用最原始的 ViT,就是为了利用它跨模态学习 (multi-modal) 的强大潜质。当迁移到下游的密集预测任务时,使用一个无需预训练的 Adapter 将与图像相关的归纳偏置引入 ViT,使其适合这些任务。
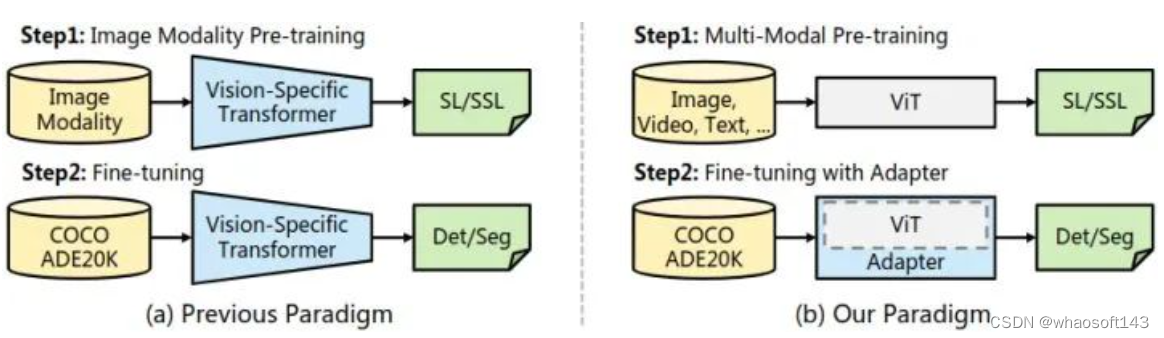
图1:ViT-Adpater 范式
对于密集预测任务的迁移学习,我们使用一个随机初始化的 Adapter,将与图像相关的先验知识 (归纳偏差) 引入预训练的 Backbone,使模型适合这些任务。Adapter 是一种无需预训练的附加网络,可以使得最原始的 ViT 模型适应下游密集预测任务,且无需修改 ViT 架构。这里面就需要做一件事情就是将 ViT 模型所缺乏的图像相关的先验知识引入到普通 ViT 里面。因此,作者为 ViT- adapter 设计了3个定制模块:
-
空间先验模块 (图2 (c)):用于从输入图像中捕获局部语义 (空间先验)。
-
空间特征注入器 (图2 (d)):用于将空间先验纳入 ViT。
-
多尺度特征提取器 (图2 (e)):用于重建密集预测任务所需的多尺度特征。
ViT-Adapter 架构
如下图2所示,我们的模型可以分为两部分。第一部分是普通 ViT,即图2(a)。第二部分是 ViT- adapter,即图2(b)。它包含一个空间先验模块,空间特征注入器,多尺度特征提取器。
ViT 模型用的就是最原始的 ViT[1]架构,首先将输入图片分成 16×16 大小的不重叠的 Patch。之后进行 Patch Embedding 形成特征,特征分辨率降低到原始图像的 1/16。然后加上位置编码,得到的特征通过 个 Encoder Layer 向前传播。
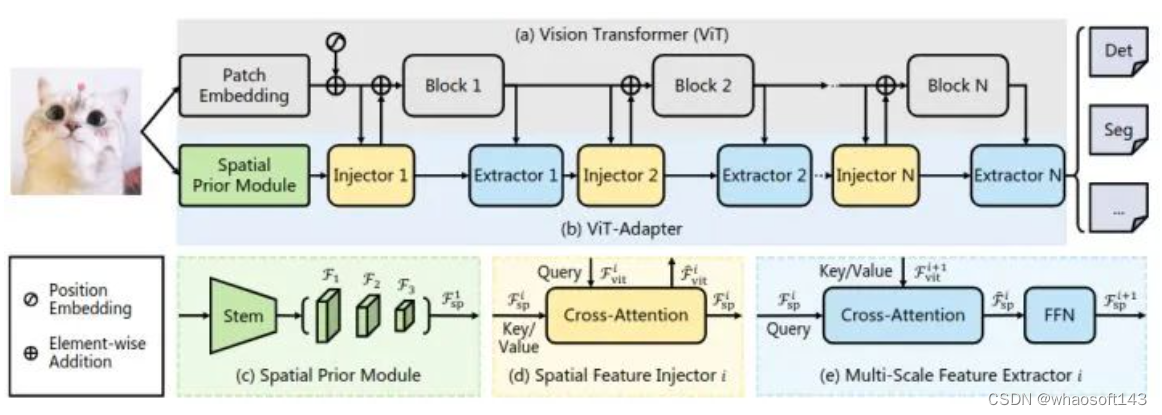
图2:ViT-Adapter 架构

空间先验模块

空间特征注入器
最简单的 ViT 结构由于缺乏必要的与图像相关的归纳偏置,相较于 ViT 替代增强版会导致较慢的收敛过程和较低的下游任务性能。为了缓解这一问题,作者提出了空间特征注入器 (Spatial Feature Injector) 和多尺度特征提取器 (Multi-Scale Feature Extractor)。

多尺度特征提取器

具体配置
作者为4种不同大小的 ViT 构建了 ViT-Adapter,包括 ViT-T,ViT-S,ViT-B,ViT-L。对于这些型号,Adapter 参数量分别为 2.5M、5.8M、14.0M 和 23.7M。作者使用[7]Deformable Attention 作为默认的稀疏注意力,采样点的数量固定为4。此外,作者将 FFN 的 Expansion Ratio 设置为0.25以节省计算开销。对于4个不同的适配器,FFN 的 Embedding diemnsion 大小分别为48、96、192和256。具体配置如下图3所示。

图3:ViT-Adapter 的具体配置
在本研究中,作者将重点放在如何更好地使现成的预训练 ViT 模型适应于下游的密集预测任务上,希望该方法也有助于上游预训练任务和下游微调过程的解耦。
COCO 目标检测实验结果
ImageNet-1K 预训练模型实验结果
使用 COCO 数据集,基于4种检测器:Mask R-CNN,Cascade Mask R-CNN,ATSS,GFL。为了节省时间和内存,作者参考 ViTDet [8]的做法并修改 LL 层 ViT 以使用 14×14 窗口注意力。使用 AdamW 优化器, Batch Size 设置为16,初始学习率为 1 × 10−4,权重衰减为0.05。
实验结果如下图4和5所示。
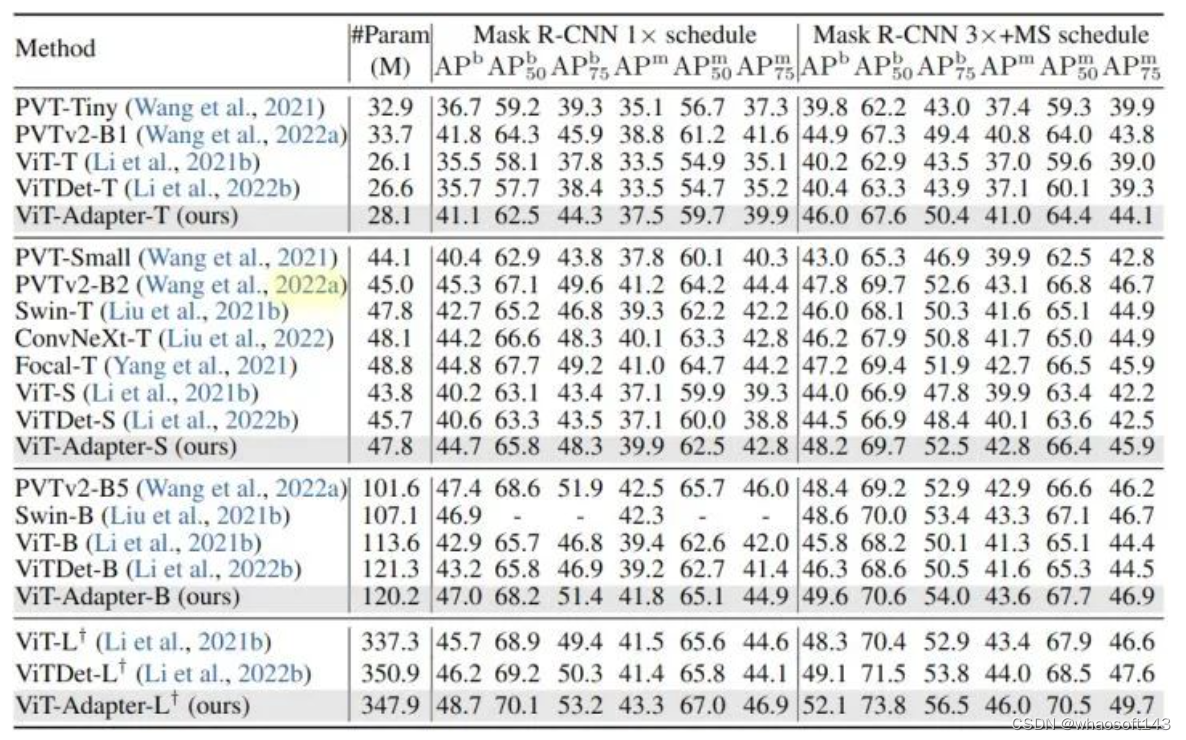 图4:COCO 目标检测和实例分割实验结果,使用 Mask R-CNN
图4:COCO 目标检测和实例分割实验结果,使用 Mask R-CNN
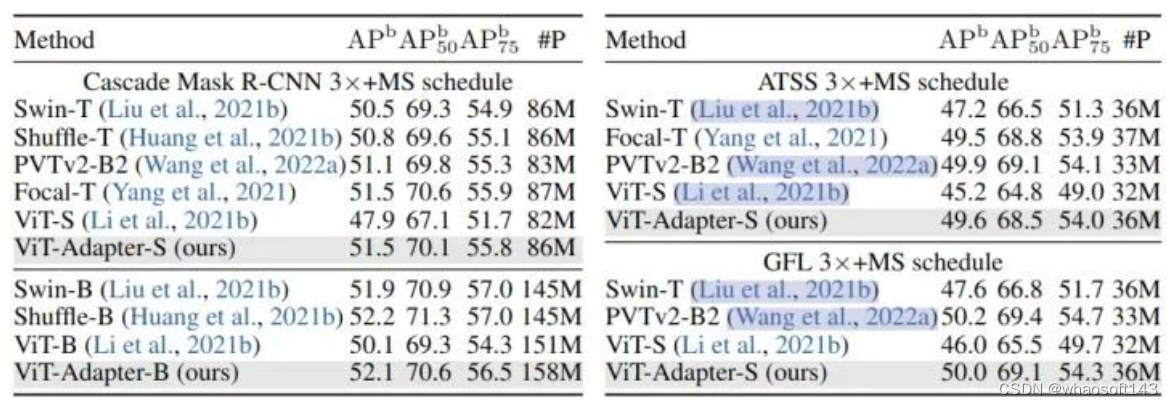
图5:COCO 目标检测实验结果,使用不同检测头
作者使用 DeiT 发布的 ImageNet-1K 权重 (无蒸馏) 作为所有 ViT-T/S/B 模型的初始化,将 ViT-Adapter 与两种相关方法进行了比较。可以看到,当使用常规训练设置进行公平比较时,ViT 和 ViTDet 的检测性能不如 ViT-Adapter。
ViT-S 和 ViTDet-S 分别比 PVTv2-B2 低 3.8 APb 和 3.3 APb。ViT-Adapter-S的性能明显优于这两种方法,甚至比PVTv2-B2 高出 0.4 APb。这种观察也同样适用于其他3个检测器。这些结果表明,仅通过常规的 ImageNet-1K 预训练,ViT- adapter 就可以使普通 ViT 获得与这些 PVT 等模型相似甚至更好的性能。通过更大的 ImageNet-22K 预训练的模型也展示出了类似的结果。
多模态预训练模型实验结果
作者还研究了多模态预训练的效果。使用不同的预训练权重对 ViT-Adapter-B 与 Mask R-CNN 的方案进行微调,实验结果如下图6所示。只需将 ImageNet-22K 预训练替换为多模态预训练,就可以获得0.7的 APb 和 APm 的显著增益。这些结果表明,Adapter 可以很容易地从先进的多模态预训练中获得相当大的收益,这对于 Swin 等特定于视觉的模型来说是很难的。
 图6:多模态预训练模型实验结果
图6:多模态预训练模型实验结果
ADE20K 语义分割实验结果
ImageNet-1K 预训练模型实验结果
使用 ADE20K 数据集,基于4种分割头:Semantic FPN (遵循 PVT 的训练设置,训练模型 80k iterations),UperNet (遵循 Swin 的训练设置,训练模型 160k iterations)。实验结果如下图7所示。
作者使用 DeiT 发布的 ImageNet-1K 权重 (无蒸馏) 作为所有 ViT-T/S/B 模型的初始化,可以看到,本文方法 ViT-Adapter 超过了 ViT 和许多具有代表性的视觉 Transformer。ViT-Adapter-S 使用 UperNet 达到了 47.1 MS mIoU,优于 Swin-T。同样,ViT-Adapter-B 达到的 49.7 MS mIoU 比 ViT-B 高2.6分,与 Swin-B 相当。这些结果表明,仅通过常规的 ImageNet-1K 预训练,ViT- adapter 就可以使普通 ViT 获得与这些 Swin 等模型相似甚至更好的性能。通过更大的 ImageNet-22K 预训练的模型也展示出了类似的结果。
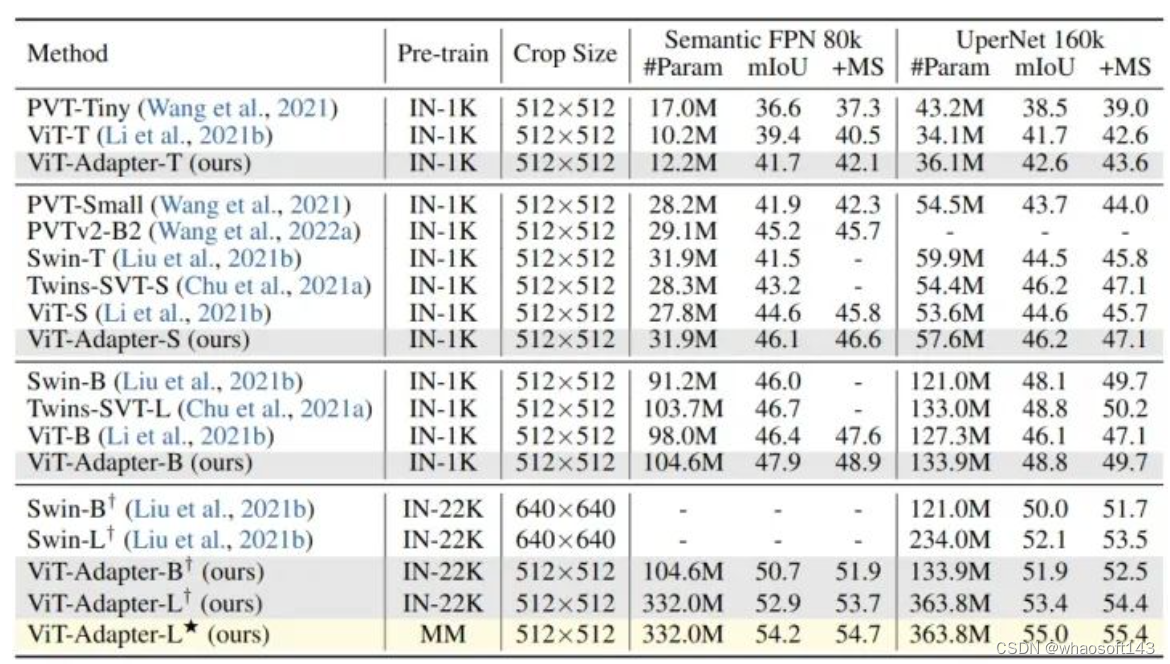 图7:ADE20K 语义分割实验结果
图7:ADE20K 语义分割实验结果
多模态预训练模型实验结果
作者还研究了多模态预训练的效果。使用 Uni-Perceiver[9]的多模态预训练权重进行语义分割。如上图7所示,对于Semantic FPN 和 UperNet,用多模态预训练取代 ImageNet-22K 预训练使得 ViT-Adapter-L 分别获得了 1.3 mIoU 和 1.6 mIoU 的惊人收益。
与检测分割 SOTA 方案的比较
作者将 ViT-Adapter 与最先进的检测/分割框架结合起来,包括 HTC++ 和 Mask2Former,以及最近的多模态预训练 BEiTv2。如下图8所示,ViT-Adapter 达到了最先进的性能。虽然这些结果可能部分归因于高级预训练的有效性,但这也表明,普通的 ViT 检测器/分割器也可以达到金字塔 Backbone 的性能。
 图8:与检测分割 SOTA 方案的比较
图8:与检测分割 SOTA 方案的比较
总结
这篇文章就属于希望使用朴素 ViT 模型做到高性能强于的 Swin 下游任务实验结果的一个工作。看这篇工作应该是受到了 ViTDet [8]的启发,想使用纯 ViT 获得更强的下游任务性能,而且很多做法也都是参考了 ViTDet (比如 Attention)。但是本文的3个针对性模块的设计很有新意,而且使用最原始的 ViT 之后,也利用了它对对模态预训练的强大潜质。当迁移到下游的密集预测任务时,使用一个无需预训练的 Adapter 将与图像相关的归纳偏置引入 ViT,使其适合这些任务。总体来看本文是一个很好的朴素 ViT 实现强下游任务的工作,很值得推广。whaosoft aiot http://143ai.com

