
- 1用博奥如何导入单项工程电子表_好易计价小技巧|5分钟教你如何利用造价软件制作电子投标文件...
- 2修改默认Python版本_设置默认python版本
- 3目标检测数据集PASCAL VOC详解_the pascal visual object classes (voc) challenge
- 4Win10如何隐藏Windows Defender任务栏图标_windows defender 关闭不显示托盘
- 5C语言之算法的概念_c语言算法是什么
- 6vscode远程调试配置args参数_vscode args
- 7物联网MQTT框架开源框架推荐~_mqtt开发框架
- 8手把手教你用 ComfyUI 部署 最新开源的Stable diffusion 3,目前最强的AI绘画模型!(附报错和解决方法)
- 9渗透实战-抓取APP流量包_yakit怎么抓包
- 10Apache Flink 入门_org.apache.flink.runtime
编写mapreduce程序实现对输入文件的词频统计排序_1.7 MapReduce基本工作方式
赞
踩
接下来介绍MapReduce。这是一个详细的案例研究,它会展示之前讲过的大部分的思想。
MapReduce是由Google设计,开发和使用的一个系统,相关的论文在2004年发表。Google当时面临的问题是,他们需要在TB级别的数据上进行大量的计算。比如说,为所有的网页创建索引,分析整个互联网的链接路径并得出最重要或者最权威的网页。如你所知,在当时,整个互联网的数据也有数十TB。构建索引基本上等同于对整个数据做排序,而排序比较费时。如果用一台计算机对整个互联网数据进行排序,要花费多长时间呢?可能要几周,几个月,甚至几年。所以,当时Google非常希望能将对大量数据的大量运算并行跑在几千台计算机上,这样才能快速完成计算。对Google来说,购买大量的计算机是没问题的,这样Google的工程师就不用花大量时间来看报纸来等他们的大型计算任务完成。所以,有段时间,Google买了大量的计算机,并让它的聪明的工程师在这些计算机上编写分布式软件,这样工程师们可以将手头的问题分包到大量计算机上去完成,管理这些运算,并将数据取回。
如果你只雇佣熟练的分布式系统专家作为工程师,尽管可能会有些浪费,也是可以的。但是Google想雇用的是各方面有特长的人,不一定是想把所有时间都花在编写分布式软件上的工程师。所以Google需要一种框架,可以让它的工程师能够进行任意的数据分析,例如排序,网络索引器,链接分析器以及任何的运算。工程师只需要实现应用程序的核心,就能将应用程序运行在数千台计算机上,而不用考虑如何将运算工作分发到数千台计算机,如何组织这些计算机,如何移动数据,如何处理故障等等这些细节。所以,当时Google需要一种框架,使得普通工程师也可以很容易的完成并运行大规模的分布式运算。这就是MapReduce出现的背景。
MapReduce的思想是,应用程序设计人员和分布式运算的使用者,只需要写简单的Map函数和Reduce函数,而不需要知道任何有关分布式的事情,MapReduce框架会处理剩下的事情。
抽象来看,MapReduce假设有一些输入,这些输入被分割成大量的不同的文件或者数据块。所以,我们假设现在有输入文件1,输入文件2和输入文件3,这些输入可能是从网上抓取的网页,更可能是包含了大量网页的文件。

MapReduce启动时,会查找Map函数。之后,MapReduce框架会为每个输入文件运行Map函数。这里很明显有一些可以并行运算的地方,比如说可以并行运行多个只关注输入和输出的Map函数。

Map函数以文件作为输入,文件又是整个输入数据的一部分。Map函数的输出是一个key-value对的列表。假设我们在实现一个最简单的MapReduce Job:单词计数器。它会统计每个单词出现的次数。在这个例子中,Map函数会输出key-value对,其中key是单词,而value是1。Map函数会将输入中的每个单词拆分,并输出一个key-value对,key是该单词,value是1。最后需要对所有的key-value进行计数,以获得最终的输出。所以,假设输入文件1包含了单词a和单词b,Map函数的输出将会是key=a,value=1和key=b,value=1。第二个Map函数只从输入文件2看到了b,那么输出将会是key=b,value=1。第三个输入文件有一个a和一个c。
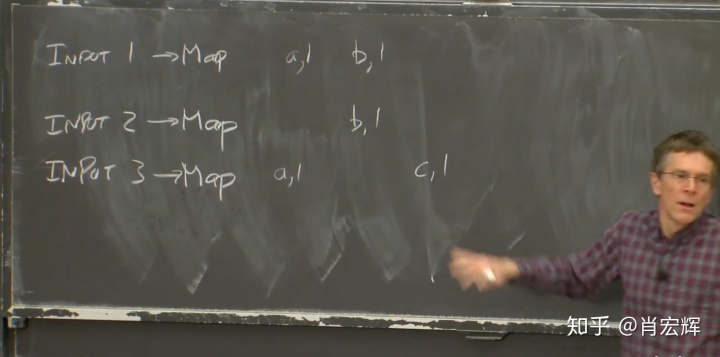
我们对所有的输入文件都运行了Map函数,并得到了论文中称之为中间输出(intermediate output),也就是每个Map函数输出的key-value对。
运算的第二阶段是运行Reduce函数。MapReduce框架会收集所有Map函数输出的每一个单词的统计。比如说,MapReduce框架会先收集每一个Map函数输出的key为a的key-value对。收集了之后,会将它们提交给Reduce函数。
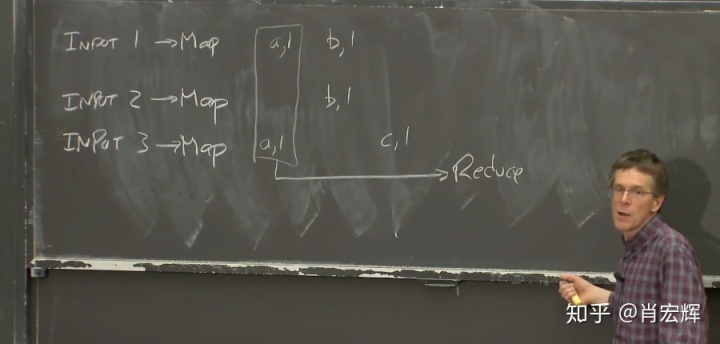
之后会收集所有的b。这里的收集是真正意义上的收集,因为b是由不同计算机上的不同Map函数生成,所以不仅仅是数据从一台计算机移动到另一台(如果Map只在一台计算机的一个实例里,可以直接通过一个RPC将数据从Map移到Reduce)。我们收集所有的b,并将它们提交给另一个Reduce函数。这个Reduce函数的入参是所有的key为b的key-value对。对c也是一样。所以,MapReduce框架会为所有Map函数输出的每一个key,调用一次Reduce函数。
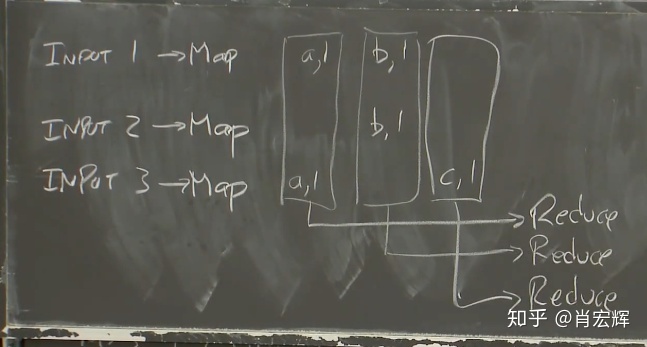
在我们这个简单的单词计数器的例子中,Reduce函数只需要统计传入参数的长度,甚至都不用查看传入参数的具体内容,因为每一个传入参数代表对单词加1,而我们只需要统计个数。最后,每个Reduce都输出与其关联的单词和这个单词的数量。所以第一个Reduce输出a=2,第二个Reduce输出b=2,第三个Reduce输出c=1。
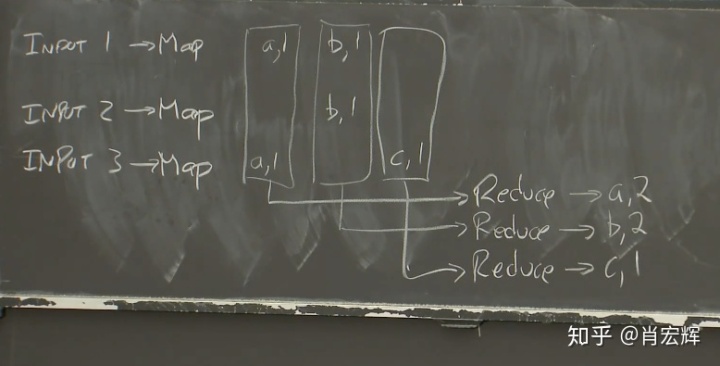
这就是一个典型的MapReduce Job。从整体来看,为了保证完整性,有一些术语要介绍一下:
- Job。整个MapReduce计算称为Job。
- Task。每一次MapReduce调用称为Task。
所以,对于一个完整的MapReduce Job,它由一些Map Task和一些Reduce Task组成。所以这是一个单词计数器的例子,它解释了MapReduce的基本工作方式。
MIT6.824的中文翻译,我也会同步连载在微信公众号: honghui_writing,可以扫码关注
http://weixin.qq.com/r/hyojO3PEFC5rrTdY93_V (二维码自动识别)

