- 1PyFlink核心知识点_pyflink richsourcefunction
- 23038. 相同分数的最大操作数目 I(Rust模拟击败100%Rust用户)
- 3Git——本地分支&远程分支_本地分支和远程分支
- 4OneDrive 遇到的坑--0x8004deed,目前的免费网盘分析
- 5嵌入式技术学习——c51——串口_c51 rs485tong
- 6瑞典保险公司百万客户数据泄露_保险公司用户数据泄露
- 7git的push以及遇到冲突解决_git push 冲突解决办法
- 8最强开源模型来了!一文详解 Stable Diffusion 3 Medium 特点及用法_sd3微调模型
- 9机器人操作系统ROS(十):机器人建模URDF_urdf机器人建模
- 10HarmonyOS开发案例:【音乐播放器】_鸿蒙开发音乐播放器
CVPR2024自动驾驶挑战赛获奖作品汇总
赞
踩
编辑 | 具身智能之心
点击下方卡片,关注“自动驾驶之心”公众号
戳我-> 领取自动驾驶近15个方向学习路线
本文只做学术分享,如有侵权,联系删文

2024CVPR自动驾驶国际挑战赛是由上海人工智能实验室联合清华大学、图宾根大学、美团等国内外高校和科技企业共同举办的比赛。大赛围绕当下自动驾驶前沿技术、实践落地场景难题等共设置7个赛道。
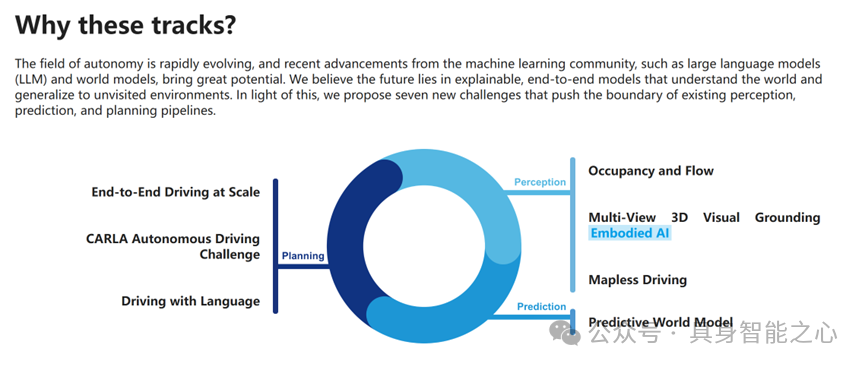
本文汇总了CVPR2024自动驾驶挑战赛每个赛道的获奖作品(https://opendrivelab.com/challenge2024/,可点击阅读原文查看),整理了原文链接和内容摘要,大家有需要自取~
赛道1:大规模端到端驾驶
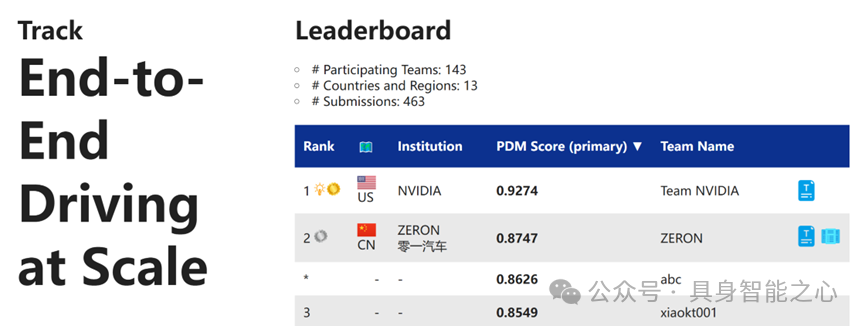
Rank1:美国 英伟达
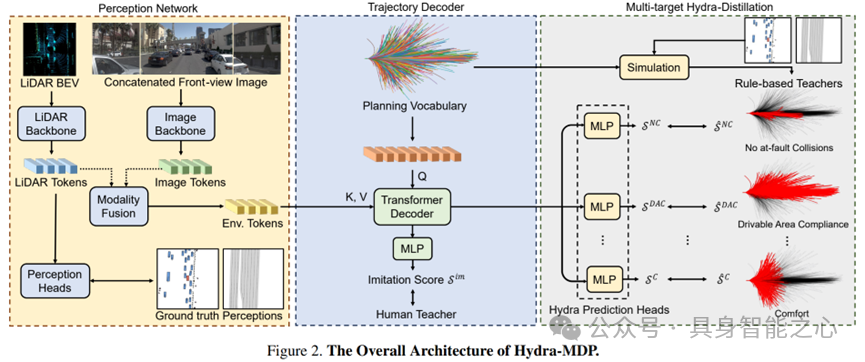
Hydra-MDP: End-to-end Multimodal Planning with Multi-target Hydra-Distillation
链接:https://opendrivelab.github.io/Challenge%202024/e2e_Team%20NVIDIA.pdf
论文提出了Hydra-MDP,这是一种新颖的端到端多模态规划范式,它采用了多教师(multiple teachers)模型。
该方法利用来自人类和基于规则(rule-based)的教师的知识蒸馏(knowledge distillation)来训练学生模型,学生模型具有多头解码器,能够学习适应不同评估指标的多样化候选轨迹(trajectory candidates)。
Hydra-MDP通过端到端的方式学习环境对规划的影响,而不是依赖于不可微分的后处理(post-processing)。
该方法在Navsim挑战中取得了第一名,展示了在不同驾驶环境和条件下的泛化能力有显著提升。
这篇论文主要关注于自动驾驶领域中如何通过多教师模型和知识蒸馏技术来提升自动驾驶系统的规划能力,特别是在多模态和多目标规划方面。
Rank2:中国 零一汽车
End-to-End Autonomous Driving Using Vision Language Model
链接:https://opendrivelab.com/challenge2024/#end_to_end_driving_at_scale
团队ZERON的研究表明,将端到端的架构设计与知识丰富的VLM相结合,在驾驶任务上取得了显著的性能。
该方法通过整合视觉和语言信息,直接在输入图像和输出控制命令之间建立映射关系,简化了自动驾驶的架构,提高了效率和可扩展性。
值得注意的是,该方法仅使用一个摄像头,并在排行榜上成为最佳的仅使用摄像头的解决方案,证明了基于视觉的驾驶方法的有效性和端到端驾驶任务的潜力。同时,仅使用一个摄像头也降低了硬件成本和数据收集的难度。

赛道2:CARLA自动驾驶挑战
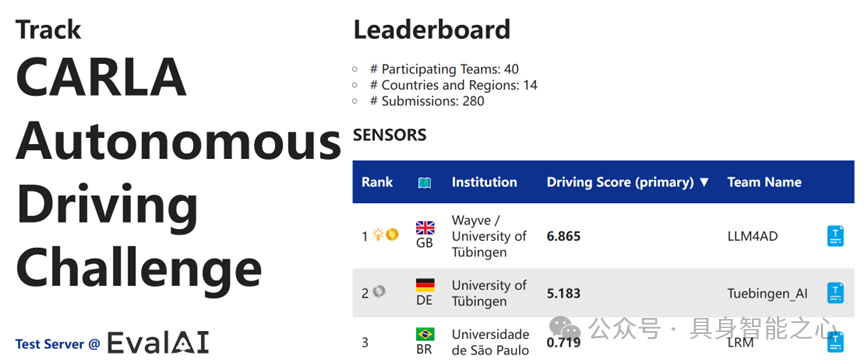
2.1 传感器
Rank1:英国 Wayve / University of Tübingen
CarLLaVA: Vision language models for camera-only closed-loop driving
链接:https://opendrivelab.github.io/Challenge%202024/carla_LLM4AD.pdf
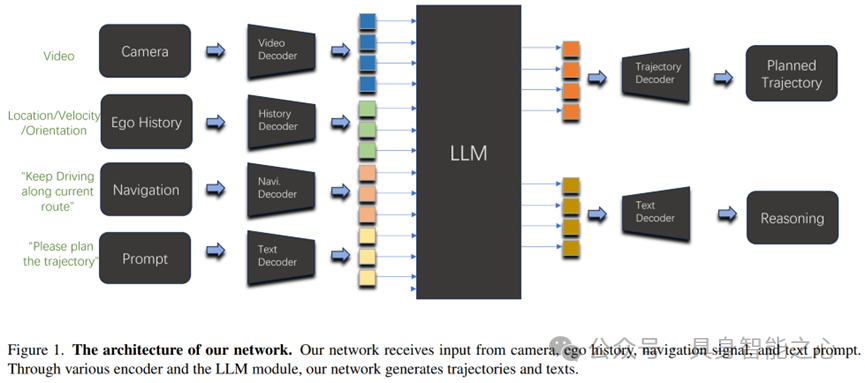
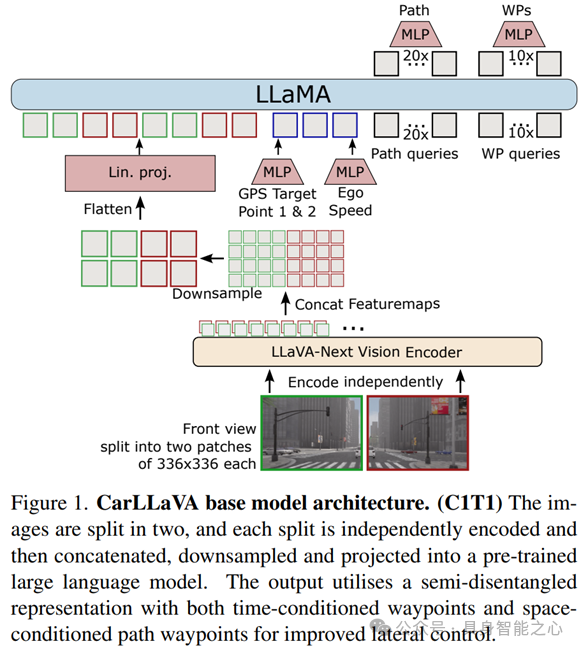
文章介绍了CarLLaVA,一种仅使用相机输入的视觉语言模型(VLM)。该技术通过摄像头输入实现高级闭环驾驶,无需复杂标签,且仅依赖相机数据,降低了成本。
CarLLaVA采用半解耦(semi-disentangled)输出表示法,结合时空条件路点(waypoint),提供卓越的横向与纵向控制,展示了视觉语言模型在自动驾驶领域的巨大潜力。
该技术利用LLaVA-NeXT视觉编码器将预训练成果有效转移到驾驶任务中,提升了驾驶性能。特别是通过分割输入图像为多个补丁,CarLLaVA能够访问更高分辨率的输入,进一步优化驾驶效果。此外,系统采用PID控制器进行纵向和横向控制,并通过标准时间条件的路标点显著提高了碰撞避免能力。
Rank2:德国 University of Tübingen
Hidden Biases of End-to-End Driving Datasets
链接:https://opendrivelab.github.io/Challenge%202024/carla_Tuebingen%20AI.pdf
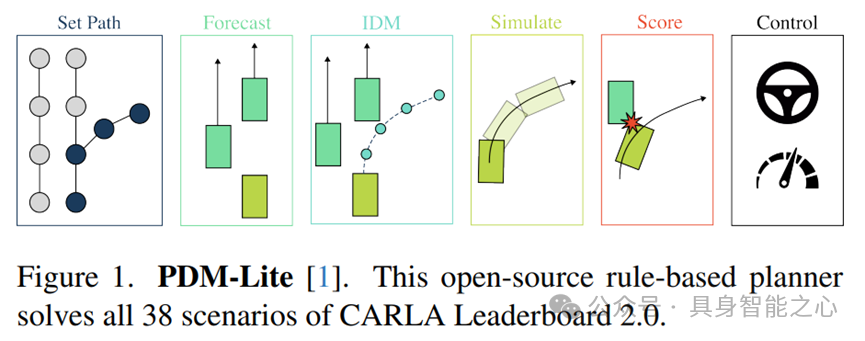
本研究深入探讨了训练数据集对端到端驾驶系统性能的影响,特别是在CARLA Leaderboard 2.0平台上的表现。
研究团队采用TransFuser模型,并结合PDM-Lite规划器,应对高速行驶和动态障碍物处理等新挑战。他们通过数据过滤优化数据集,为自动驾驶数据集设计和模型训练提供了新的视角。在Town13short基准测试中,TransFuser 8实现了优异的性能,证明了其在新场景下的适应性。
此外,研究还使用动态自行车模型将提案转化为自动驾驶车辆预期序列边界框,该方法结合了端到端的模仿学习,并通过模拟边界框相交情况来评估自车运动,有效提升了自动驾驶系统的安全性和准确性。
在CARLA 2.0的Town13地图上,他们利用20条官方验证路线,通过拆分和精细评估,为自动驾驶模型的场景适应性提供了更准确的评估方法。
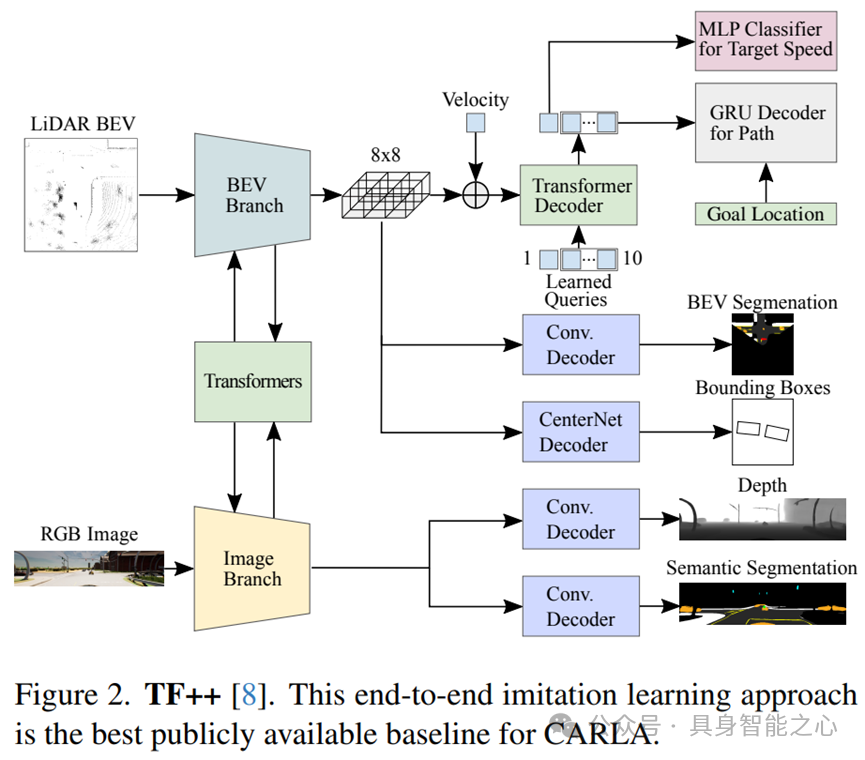
Rank3:巴西 Universidade de São Paulo
A Hybrid Autonomous Driving Navigation Architecture for the 2024 CARLA Autonomous Driving Challenge
链接:https://opendrivelab.github.io/Challenge%202024/carla_LRM.pdf
本文提出了一个混合自动驾驶导航架构,该架构能够进行多源数据融合和高效路径规划。
该研究将模块化与端到端方法融合,通过结合模块化系统(modular system)的模块化和深度学习能力,提高系统的适应性和决策透明度。
此外,文章详细介绍了一种多传感器融合的自动驾驶系统,该系统利用ROS框架实现组件间通信,展示了实时推理和网络泛化能力。
2.2 地图
Rank1:德国 University of Tübingen
同上,Hidden Biases of End-to-End Driving Datasets
Rank2:英国 Wayve / University of Tübingen
同上,CarLLaVA: Vision language models for camera-only closed-loop driving
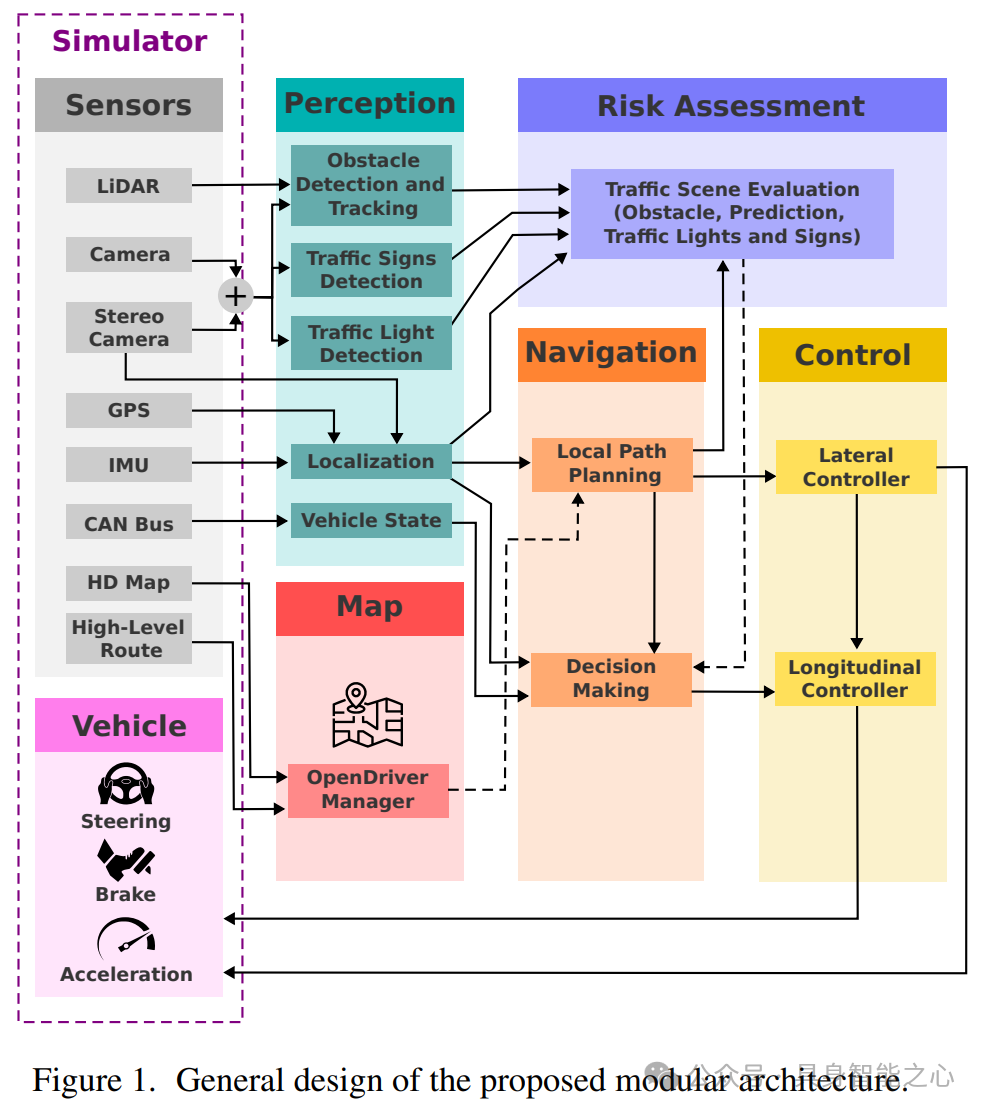
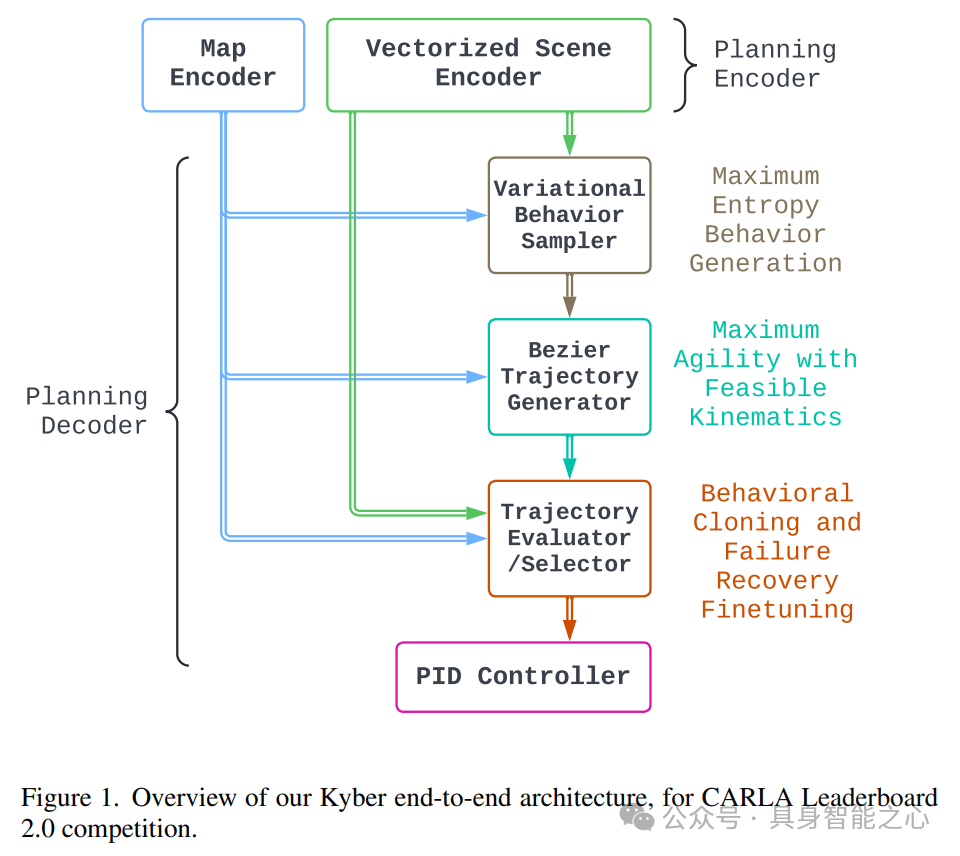
Rank3:中国 华为
Kyber-E2E submission to CVPR’s CARLA Autonomous Driving Challenge
链接:https://opendrivelab.github.io/Challenge%202024/carla_Kyber-E2E.pdf
华为诺亚方舟实验室在2024年CVPR的CARLA自动驾驶挑战中,展示了其创新的Kyber-E2E系统架构,该系统由感知、规划、定位和控制等模块组成,实现了完整的自动驾驶流程。
该系统通过特权代理收集训练数据,在CARLA Leaderboard 2.0中成功应对所有复杂交通场景。其中,感知模块采用多模态传感器融合技术,结合图像和点云数据,提高了检测精度和驾驶安全性。规划模块则通过模仿学习和基于重放的模拟环境进行微调,实现了高效轨迹规划。
此外,系统还具备交通标志检测和识别、对象检测与预测等功能,并通过实验验证了其性能。
赛道3:语言驱动驾驶
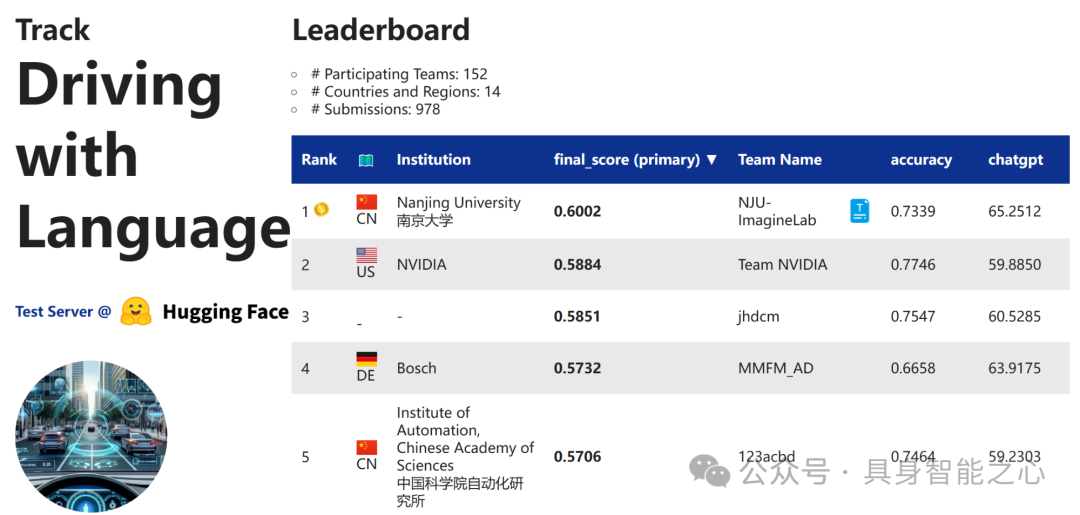
Leaderboard
Rank1:中国 南京大学
Driving with InternVL
链接:https://opendrivelab.github.io/Challenge 2024/language_NJU-ImagineLab.pdf
本文展示了如何结合图像与语言理解以改善自动驾驶决策。报告聚焦于对车辆后方左、中、右三个方向图像的视觉数据分析,旨在通过图像信息提供指导。
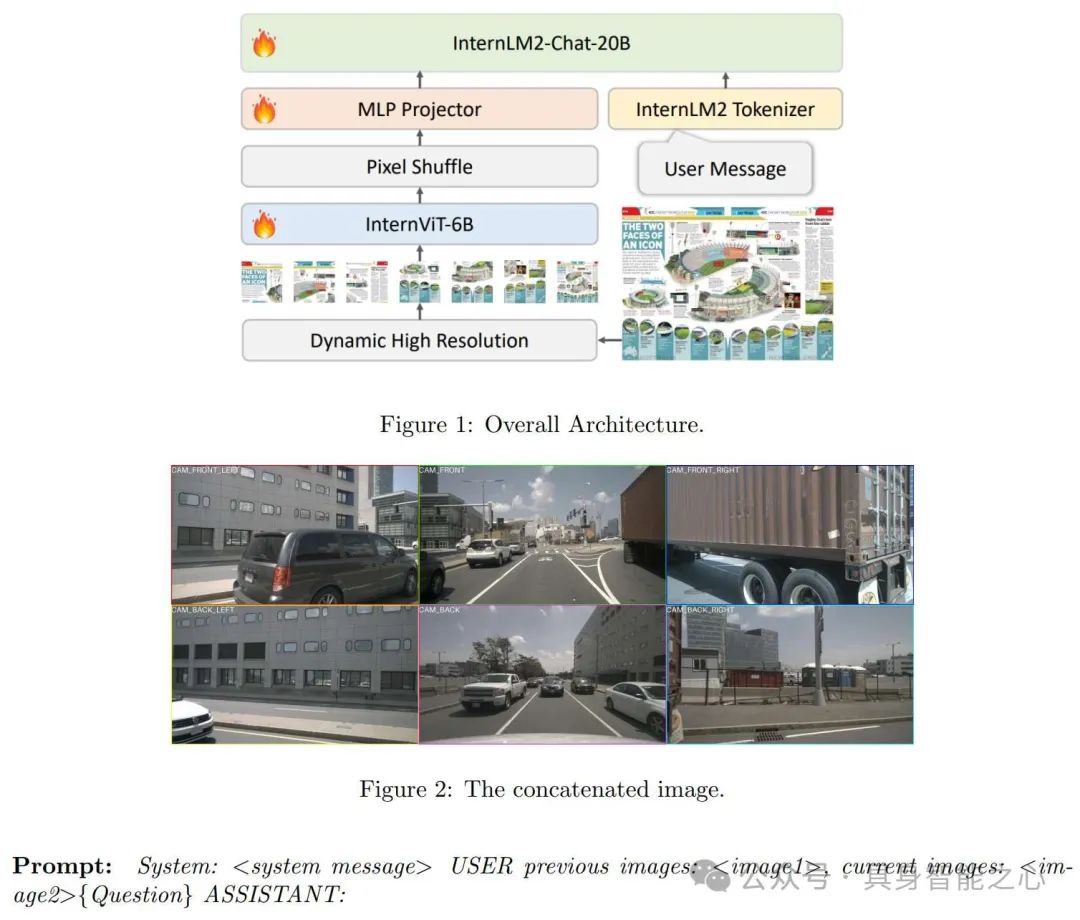
文章介绍了名为InternVL-1.5的模型,这是一个基于多模态数据预训练的模型,旨在处理高分辨率图像和相关的视觉信息。该模型由三个主要组件构成:InternLM-20B语言模型、6B InternViT和连接器(connector)。
其中InternLM-20B语言模型负责处理与图像相关的文本或语言信息,赋予模型上下文理解能力。6B InternViT负责处理输入的图像数据,采用了动态高分辨率训练方法,这种方法通过将图像分割成多个瓦片(tiles)来适应不同分辨率和长宽比的输入图像,从而提高了模型处理详细视觉信息的能力。连接器负责实现跨模态的信息融合。
Submissions with Offline Label
Rank1:中国 华东师范大学
The System Description of CPS Team for Track on Driving with Language of CVPR 2024 Autonomous Grand Challenge
链接:https://opendrivelab.github.io/Challenge 2024/language_CPS.pdf
通过结合视觉语言模型(VLMs)和深度估计技术,基于LLaVA模型,结合LoRA和DoRA方法,并使用DriveLM-nuScenes数据集训练,成功提升了自动驾驶系统的决策能力。该系统能够融合视觉与语言信息,实现准确的环境感知和可泛化、可解释的驾驶行为。
此外,团队还利用nuScenes 2数据集和DepthAnything模型,进一步提升了对象深度信息的精度,并通过转化为文本距离描述,使深度信息更易于应用。

Rank2:中国 长安汽车 / 重庆邮电大学
BeVLM: GoT-based Integration of BEV and LLM for Driving with Language
链接:https://opendrivelab.github.io/Challenge 2024/language_ADLM.pdf
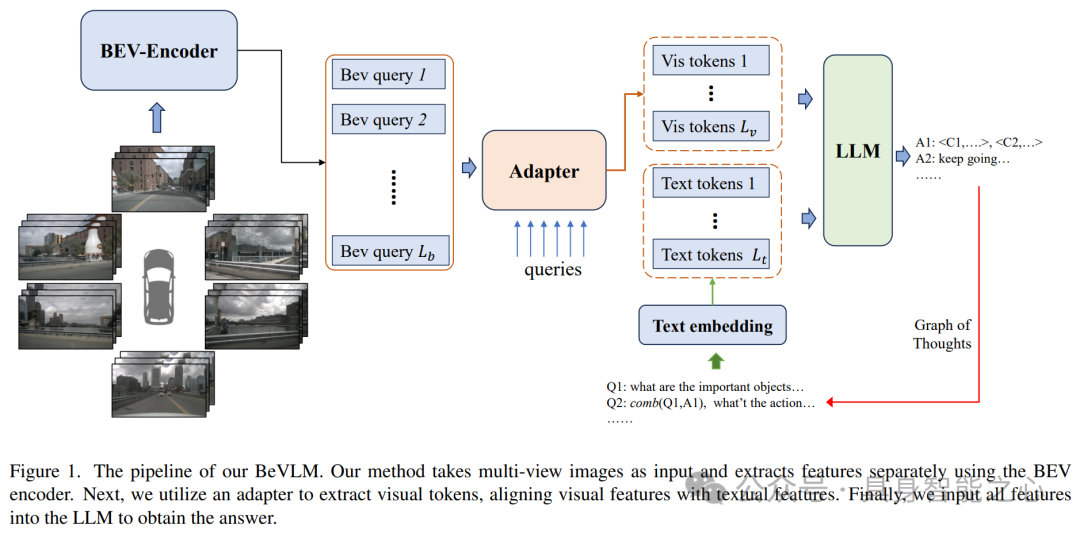
本文介绍了一种创新的自动驾驶集成系统BeVLM。BeVLM通过BEV编码器提取视觉特征,并通过适配器模块与文本特征对齐,实现了对摄像头视角和重要物体位置的敏感捕捉。此外,该系统还利用图思维(graph-of-thought (GoT))增强了上下文理解,并通过广泛的数据集和精细调整验证了其有效性。实验表明,BeVLM能有效提升自动驾驶任务中语言模型对4D特征的理解能力,为跨模态理解提供了新的解决方案。
此外,研究者还开发了一种融合音频和文本特征的VQA系统,通过细化“思维图”(graph-of-thought (GoT))方案提高了VQA性能。
赛道4:Occupancy and Flow
Rank1:中国 浪潮信息
3D Occupancy and Flow Prediction based on Forward View Transformation
链接:https://opendrivelab.github.io/Challenge 2024/occ_IEIT-AD.pdf
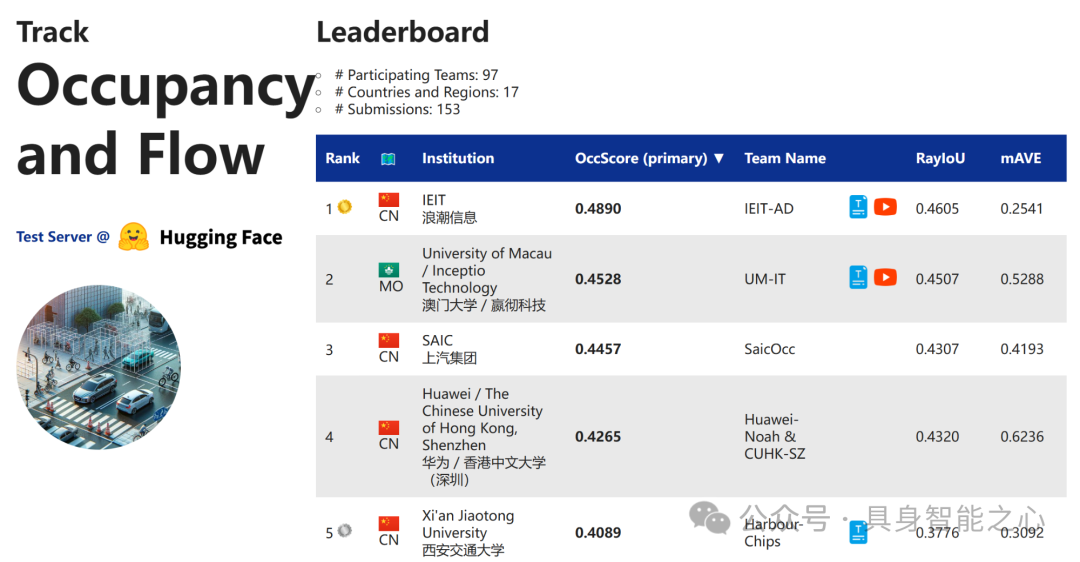
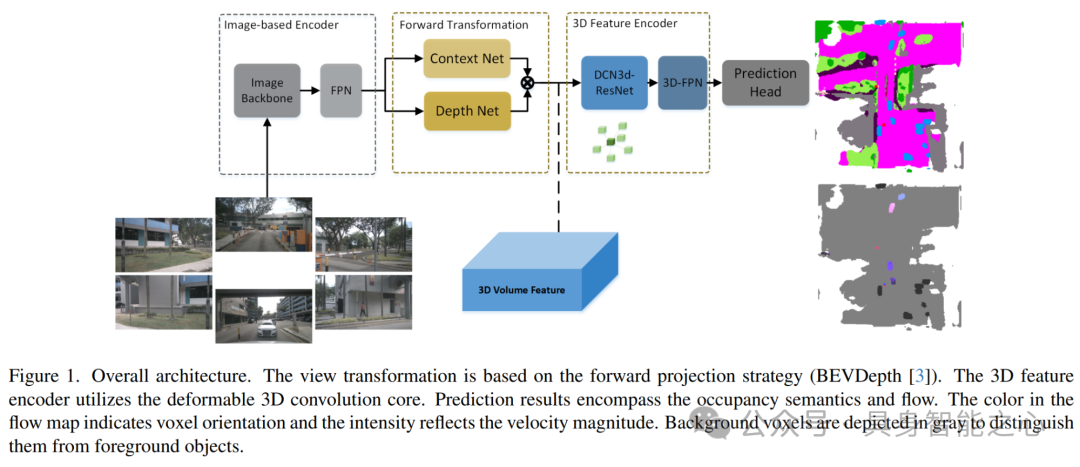
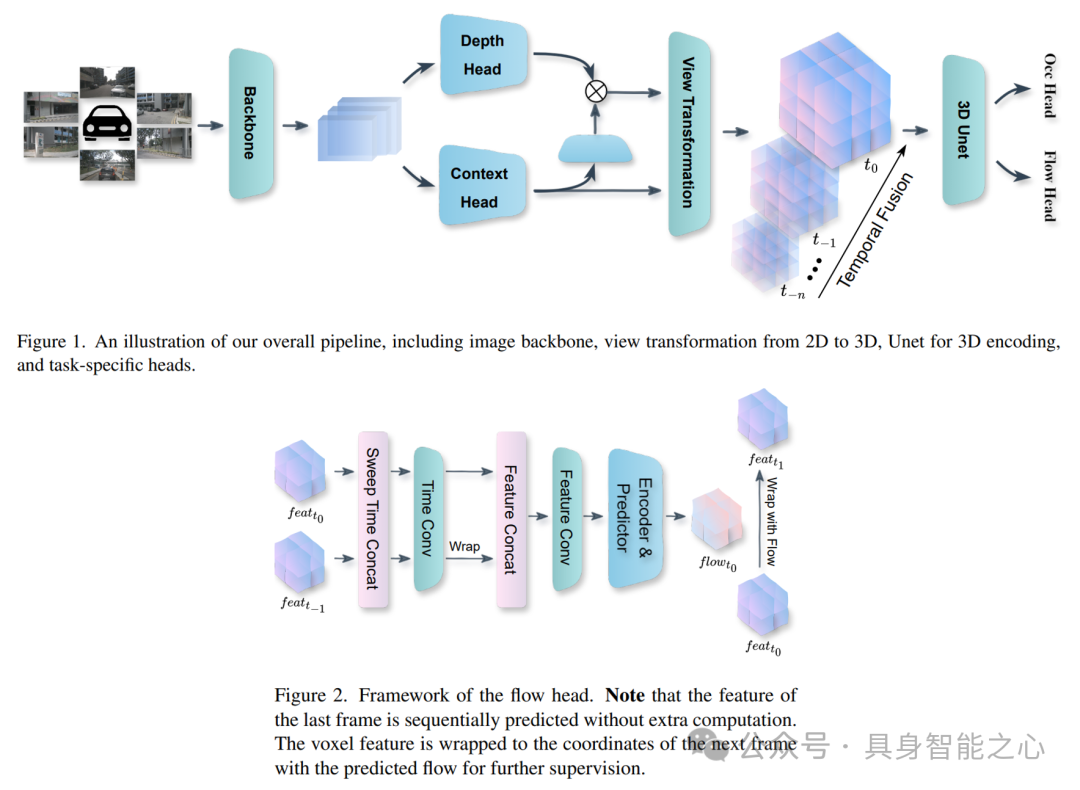
文章提出了一种基于前向投影(forward projection)的3D感知框架,该框架将图像特征根据相机的外参和内参投影到以自我为中心的坐标系中。在前向框架的基础上,文章设计了一个改进的3D编码器模块,并提出了几种针对3D占用率(occupancy)和流量(flow)预测任务的优化方法,包括生成可见掩码(visible mask)。本文的方法在nuScenes OpenOcc数据集上达到了最高的占用率得分0.489。
Rank2:中国澳门 澳门大学 / 嬴彻科技
AdaOcc: Adaptive Forward View Transformation and Flow Modeling for 3D Occupancy and Flow Prediction
链接:https://opendrivelab.github.io/Challenge 2024/occ_UM-IT.pdf
本文提出了AdaOcc方法,用于解决nuScenes Open-Occ Dataset Challenge中的Vision-Centric 3D占用率和流量(Occupancy and Flow)预测任务。本文的方法采用了一个双阶段框架,通过结合自适应前向视图转换(adaptive forward view transformation)和流量建模(flow modeling)来增强3D占用率和流量预测。首先独立训练占用率模型,然后利用序列帧集成(sequential frame integration)进行流量预测。我们的方法结合了回归与分类来处理不同场景中的尺度变化,并利用预测的流量来转换当前体素特征(current voxel features)至未来帧(future frames),以未来帧的真实数据为指导。在nuScenes数据集上的实验结果表明,我们的方法在准确性和鲁棒性方面取得了显著改进,我们的单模型在公开排行榜上排名第二,验证了该方法在推进自动驾驶感知系统中的潜力。
Rank5(第三名):中国 西安交通大学
CascadeFlow: 3D Occupancy and Flow Prediction with Cascaded Sparsity Sampling Refinement Framework
链接:https://opendrivelab.github.io/Challenge 2024/occ_Harbour-Chips.pdf
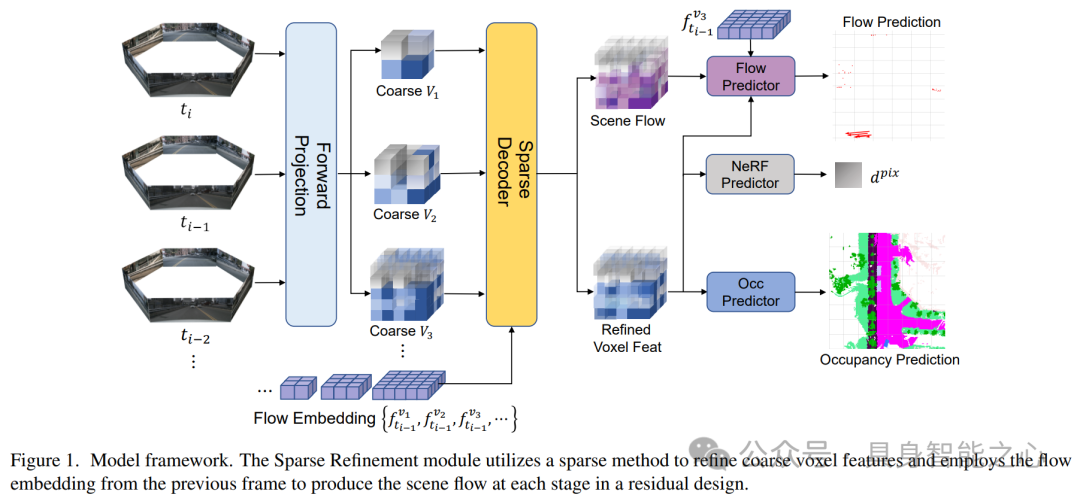
本文提出了CascadeFlow,一种用于基于视觉的3D占用率和流量预测的解决方案。CascadeFlow建立在CascadeOcc的基础上,这是一个用于视觉占用预测(vision-based occupancy prediction)的级联稀疏采样细化框架(cascade sparsity sampling refinement framework)。考虑到场景流(scene flow)的尺度不变性和时间一致性,CascadeFlow引入了一种流量嵌入(flow embedding),该嵌入学习3D场景中相邻占用(adjacent occupancy)之间的关系,并在级联框架( cascade framework)内逐步细化它们。由于稀疏细化和级联设计,CascadeFlow在仅使用7.3GB内存训练的情况下,取得了优异成绩:在RayIoU中排名第5,得分为37.8;在MAVE中排名第2,得分为0.31;在占用率得分中排名第5,得分为40.89。以上测试均在没有TTA(test-time augmentation)、后处理(post-processing)或模型集成(model ensembling)的情况下实现。
赛道5:多视角三维视觉定位
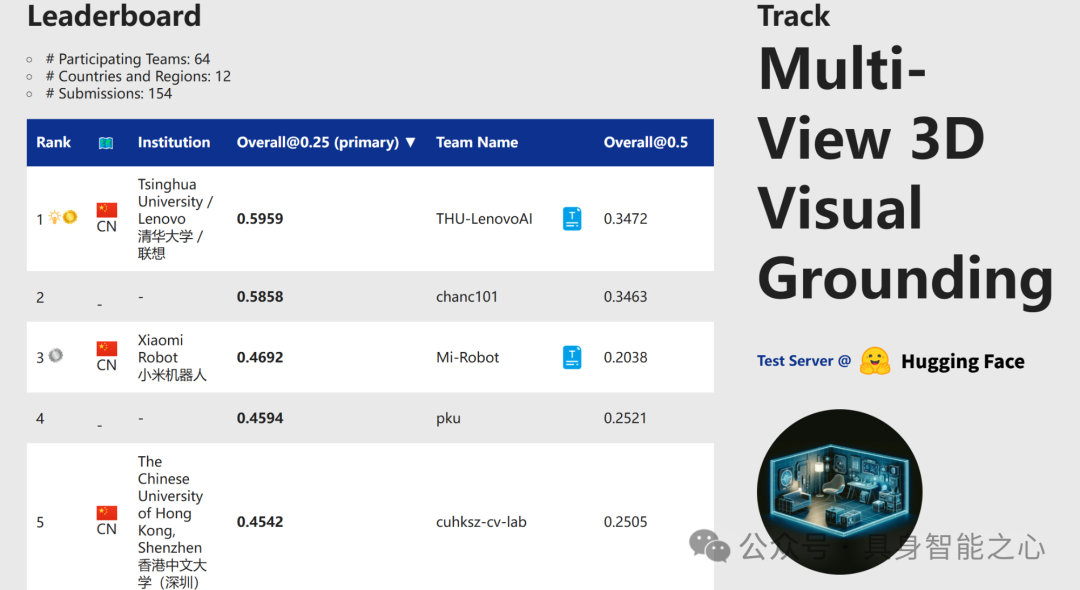
Rank1:中国 清华大学 / 联想
DenseG: Alleviating Vision-Language Feature Sparsity in Multi-View 3D Visual Grounding
链接:https://opendrivelab.github.io/Challenge 2024/multiview_THU-LenovoAI.pdf
本文介绍了一种通过多角度定位和逻辑调整来提高目标对象描述准确性的方法。首先,通过利用场景中物体的多种位置关系,确保足够的可靠锚点来减少干扰。其次,对于依赖于视角的文本,采用相反视角重新表述并调整空间关系;对于不依赖于视角的文本,则通过增加锚点来丰富上下文。最后,确保所有修改,包括新增的位置关系和视角,都具备高度的准确性。这种方法旨在保持目标对象及其位置关系的一致性,从而提高整体描述的准确性和可靠性。

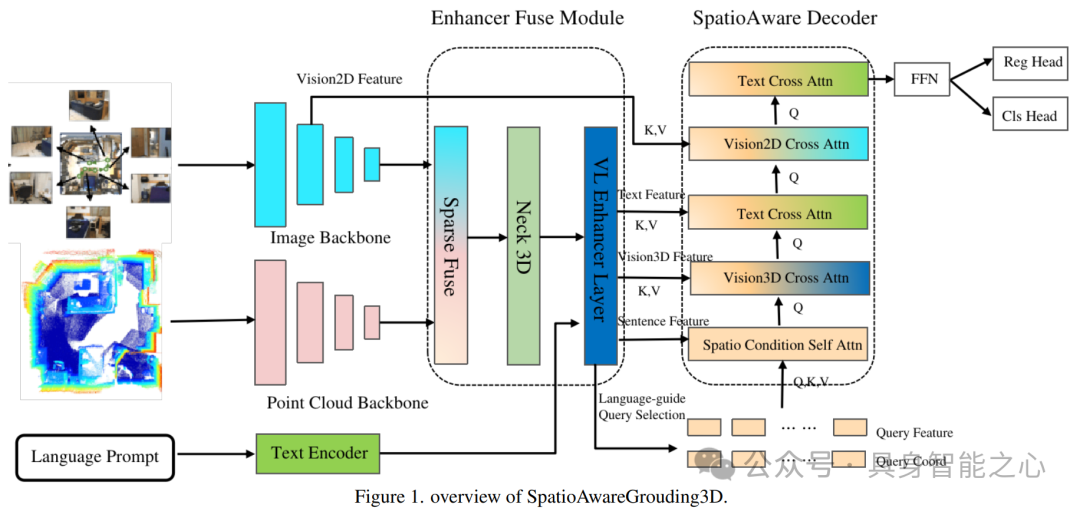
Rank3:中国 小米机器人
SpatioAwareGrouding3D : A Spatio Aware Model For Improving 3D Vision Grouding
链接:https://opendrivelab.github.io/Challenge 2024/multiview_Mi-Robot.pdf
本文提出了SpatioAwareGrounding3D,该模型通过引入视觉语言增强层(Visual Language Enhancer Layer)、空间感知解码器(Spatio-aware Decoder)及集成技术(ensemble technique),有效提升了场景理解和视觉定位能力。其中,视觉语言增强层融合了多模态输入,包括图像、点云和文本,通过跨模态特征融合提高了视觉和文本特征的对齐能力。空间感知解码器则通过空间条件自注意力层挖掘视觉特征中的空间信息,实现了对空间关系的深入理解。此外,模型还采用了查询选择层的语言指导方法和模型集成算法,进一步提升了预测结果的准确性和鲁棒性。
赛道6:无图驾驶
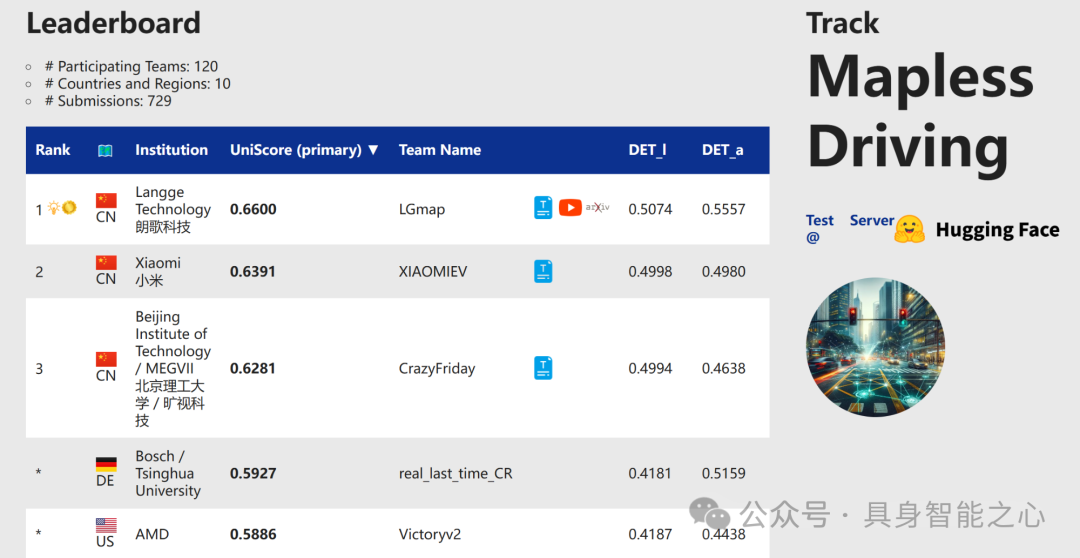
Rank1:中国 朗歌科技
LGmap: Local-to-Global Mapping Network for Online Long-Range Vectorized HD Map Construction
链接:https://opendrivelab.github.io/Challenge 2024/mapless_LGmap.pdf
本文介绍了一种创新的地图融合方法LGmap,该方法结合了前后投影策略、SD地图融合及深度监督,实现从近及远的地图融合。同时,提出了一个适用于短距离和长距离在线地图绘制的流程,融合了流处理和堆叠策略。针对行人过马路场景,将行人穿越简化为四角,并在每条边上均匀采样六点。实验部分验证了该方法在多个方面的有效性,包括对称VT、时间融合、交通元素和车道段识别。整体而言,本文提出的地图融合和在线映射技术为自动驾驶和智能交通系统提供了新的视角和解决方案。
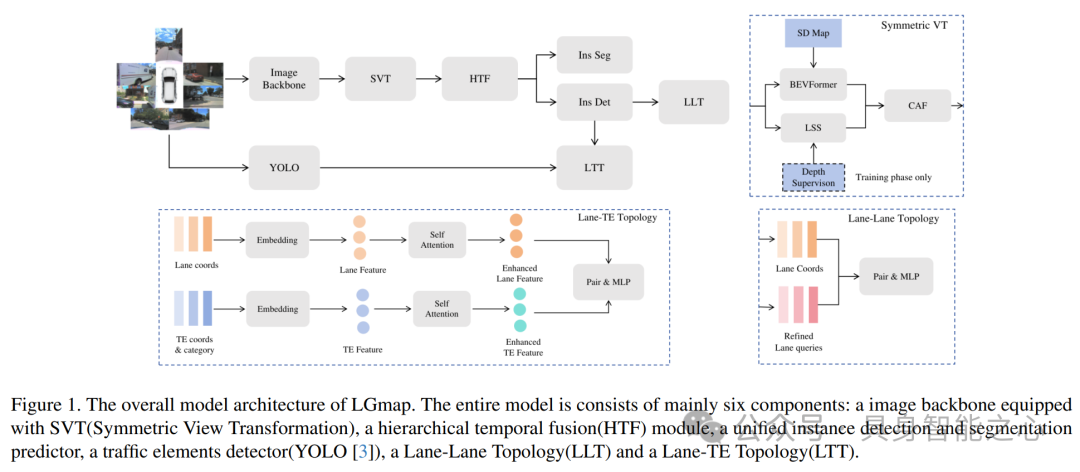
Rank2:中国 小米
Leveraging SD Map to Assist the OpenLane Topology
链接:https://opendrivelab.github.io/Challenge 2024/mapless_XIAOMIEV.pdf
本文提出了一种基于标准定义(SD)地图和Transformer架构的先进方法,以解决自动驾驶中的OpenLane拓扑理解问题。该方法通过整合SD地图中的道路信息和动态位置编码方案,有效提升了在多种驾驶场景中的定位精度。在OpenLane Topology Challenge 2024中,该方法取得了显著成绩,验证了其有效性。研究涵盖了车道检测、区域检测等关键任务,并强调了SD地图在自动驾驶中的重要性。通过设计SD地图编码器,结合多视图图像和Bird Eye's View(BEV)特征,提高了道路元素感知能力和导航准确性。此外,本文还介绍了一种改进的跨注意力层Lane Attention,通过动态位置编码方案提升了道路元素坐标预测的准确性。
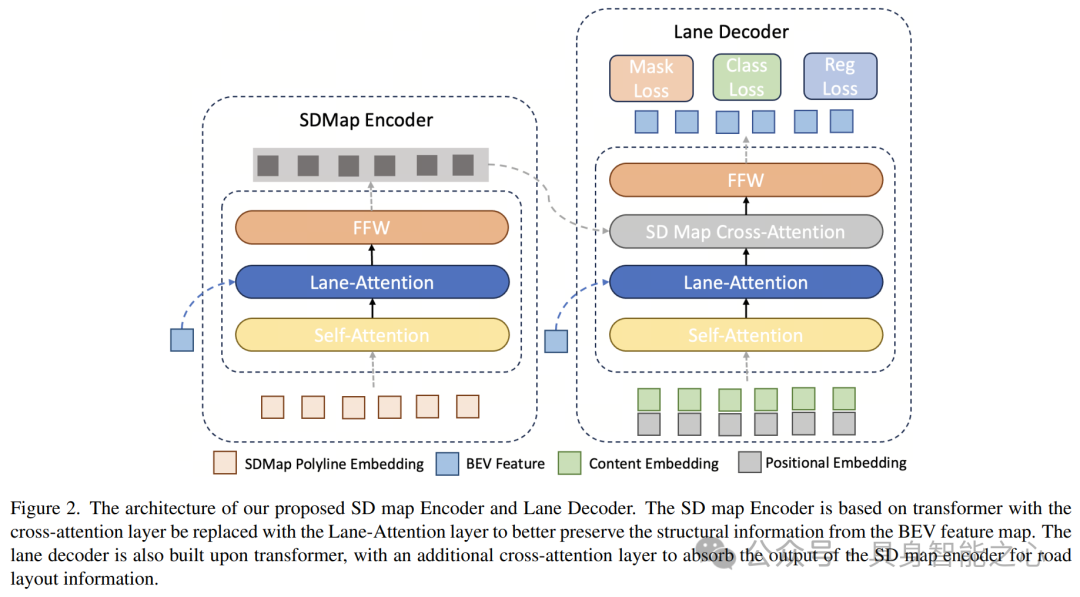
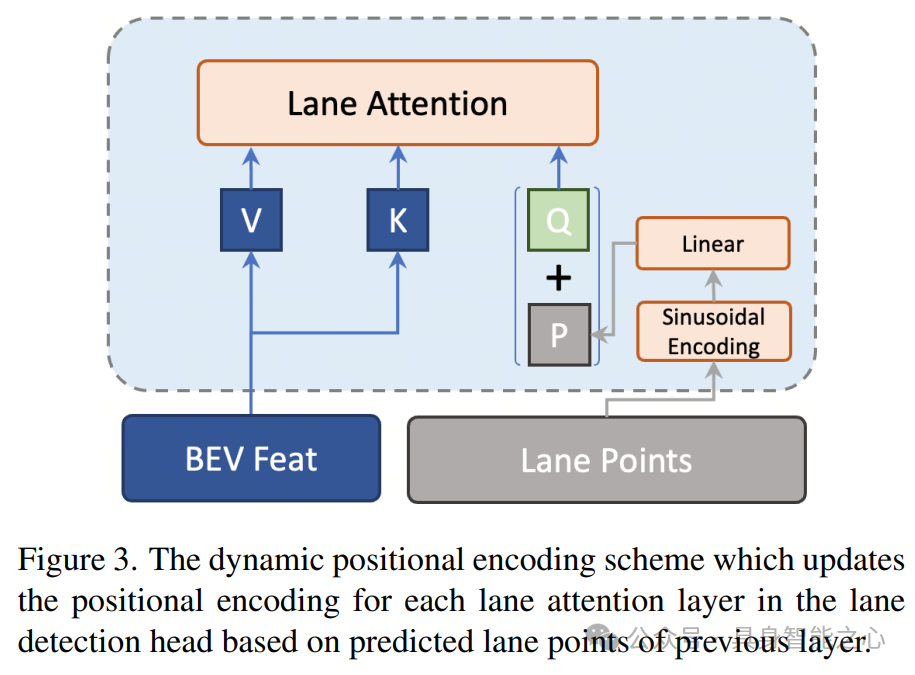
Rank3:中国 北京理工大学 / 旷视科技
UniHDMap: Unified Lane Elements Detection for Topology HD Map Construction
链接:https://opendrivelab.com/challenge2024/#mapless_driving
本文介绍了UniHDMap,一个为无图驾驶设计环境的深度学习框架。UniHDMap通过融合先进的深度学习技术,如ResNet-50、BEV-Former和YOLOv8,成功构建了高精度拓扑地图,实现了对车道、人行横道、道路边界以及交通元素的精准检测,并预测了它们之间的拓扑关系。在CVPR 2024 AutonomousGrand Challenge中,UniHDMap通过引入一系列增强方法,如SDmap注入、辅助PV和BEV监督,显著提升了其在自动驾驶场景中的性能。UniHDMap不仅展现了深度学习在自动驾驶领域的巨大潜力,还为无图驾驶技术的发展提供了新的思路与方向。
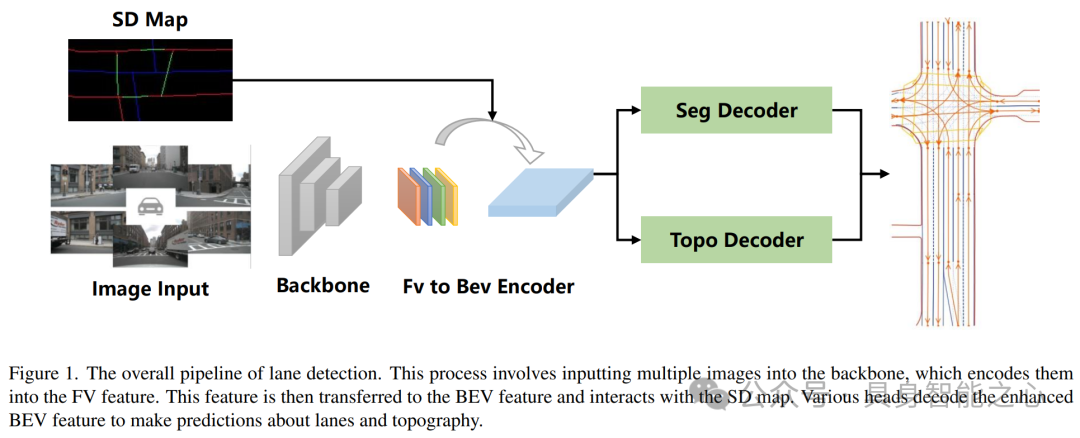
Rank3:中国 滴滴出行
MapVision: CVPR 2024 Autonomous Grand Challenge Mapless Driving Tech Report
链接:https://opendrivelab.github.io/Challenge 2024/mapless_mapvision.pdf
MapVision团队通过结合多视角图像(multi-perspective camera images)和SD地图(standard-definition maps),有效解决了自动驾驶中道路远端和遮挡问题。他们采用预训练的地图编码器强化了几何编码能力,并利用YOLOX提升了交通元素检测的精度。通过创新的区域预测头、mapTRv2辅助任务等技术,显著提高了系统在无图环境下的主动理解能力。研究不仅在OpenLaneV2验证集上取得了优异效果,还通过消融实验验证了SD地图来源、预训练方法和多任务学习对模型性能的影响。此外,团队还通过数据增强和特征融合技术优化了目标检测模型,提升了边界框(boundaries of scene)质量。
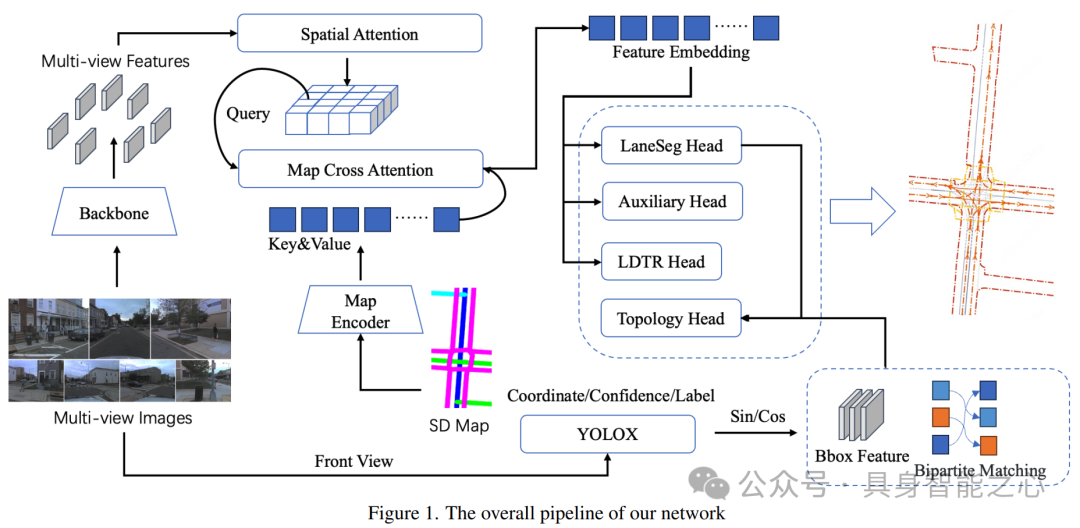
赛道7:现实预测模型
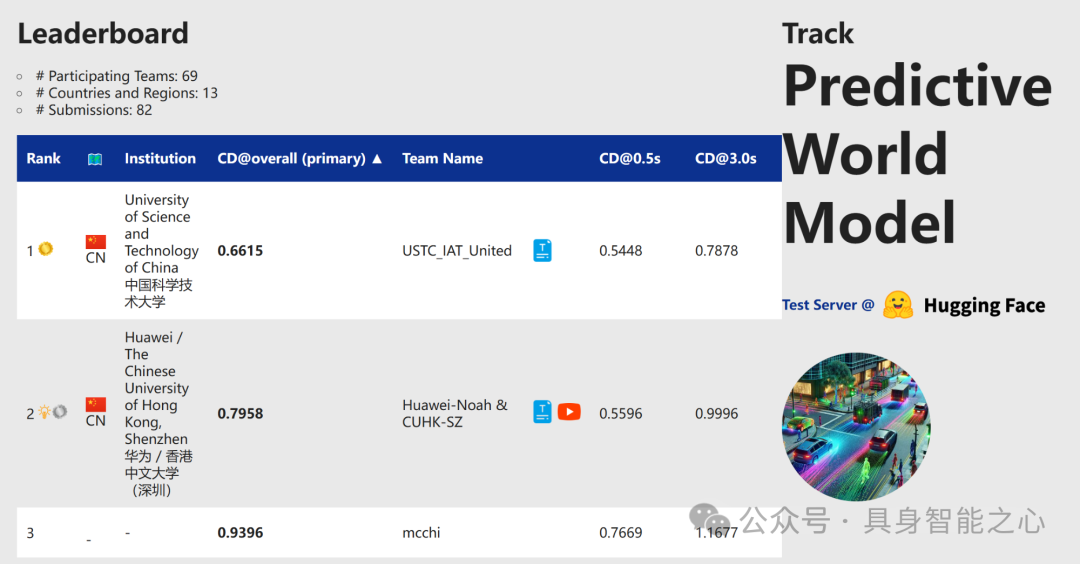
Rank1:中国 中国科学技术大学
The 1st-Place Solution for CVPR 2024 Autonomous Grand Challenge Track on Predictive World Model
链接:https://opendrivelab.github.io/Challenge 2024/predictive_USTC_IAT_United.pdf
该团队利用多摄像头视角数据集,通过自监督训练优化基线模型,并重点改进了BEV编码器和Transformer解码器内的关键模块,实现了对未来点云数据的精确预测。团队提出的多阶段框架和两阶段点云预测方法,结合多视角自监督训练和对比学习技术,有效提取了BEV特征,并通过时间交叉注意力机制的优化,提升了模型对未来点云数据的预测能力。此外,他们还通过BEV查询、空间交叉注意力和时间自注意力机制,有效整合了多相机图像的空间和时间特征,提高了多相机系统的准确性和鲁棒性。
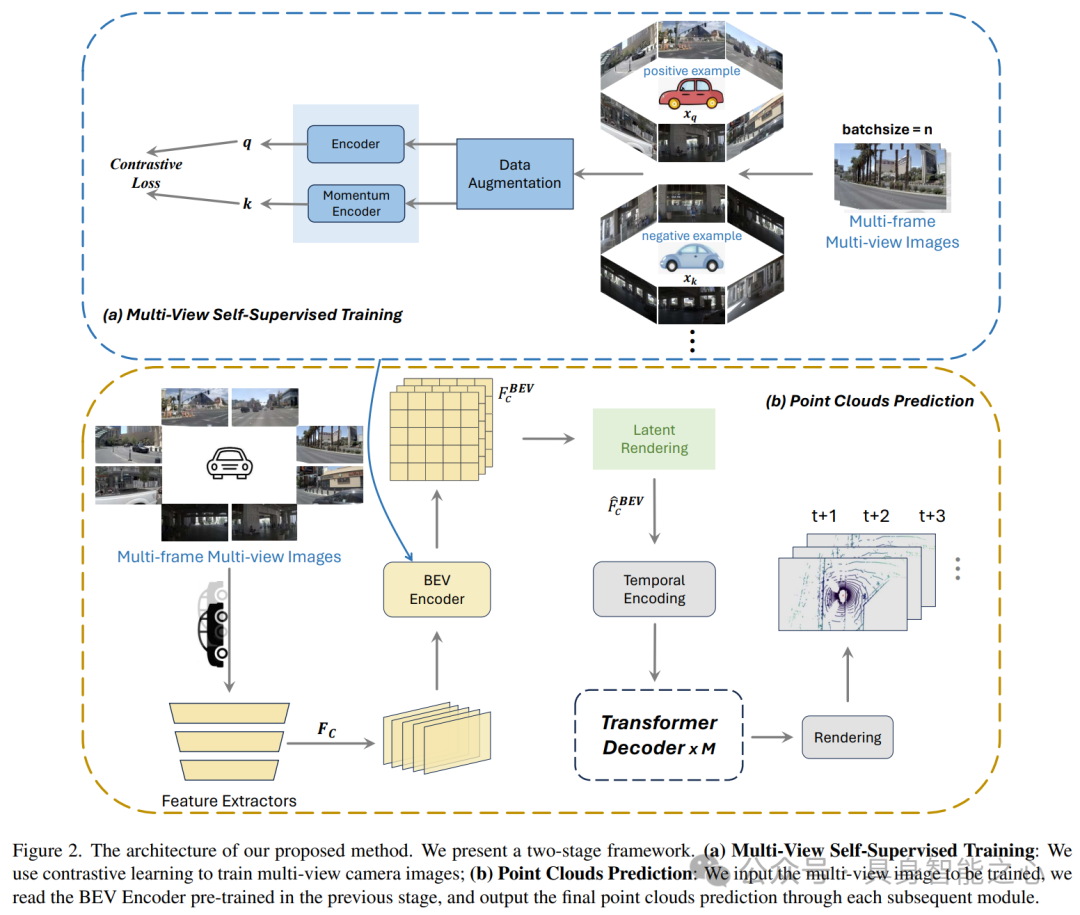
Rank2:中国 华为 / 香港中文大学(深圳)
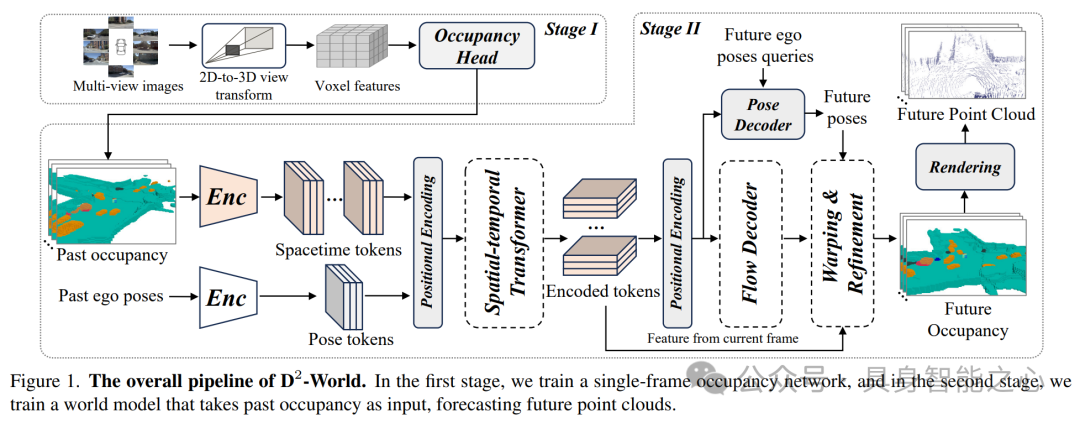
D2 -World: An Efficient World Model through Decoupled Dynamic Flow
链接:https://opendrivelab.github.io/Challenge 2024/predictive_Huawei-Noah & CUHK-SZ.pdf
D2-World通过解耦动态流技术(Decoupled Dynamic flow)精确预测未来点云数据。该方法结合BEVDet等占用网络获取语义信息,并采用非自回归方式生成未来占用(occupancy)情况,显著提高了预测效率和准确性。D2-World通过动态体素解耦策略(dynamic voxel decoupling)简化了任务,实现了静态和动态体素的分离处理,进一步提升了预测精度。在OpenScene PredictiveWorld Model基准测试中,D2-World取得了卓越性能,且训练速度远超基准模型,为自主系统决策提供了高效支持。
该方法通过两阶段实现基于历史相机图像的未来3D点云预测,首先利用视觉占用预测网络预测单帧占用状态和语义信息,然后采用非自回归的4D点云预测框架通过解耦动态流预测未来点云。此外,D2-World还结合了多任务学习框架和时空变换器,解决了类别不平衡问题,并充分利用了时间信息。整体而言,D2-World为自动驾驶领域的3D世界模型预测提供了一种高效、准确的新方法,具有广阔的应用前景。
投稿作者为『自动驾驶之心知识星球』特邀嘉宾,欢迎加入交流!
① 全网独家视频课程
BEV感知、BEV模型部署、BEV目标跟踪、毫米波雷达视觉融合、多传感器标定、多传感器融合、多模态3D目标检测、车道线检测、轨迹预测、在线高精地图、世界模型、点云3D目标检测、目标跟踪、Occupancy、cuda与TensorRT模型部署、大模型与自动驾驶、Nerf、语义分割、自动驾驶仿真、传感器部署、决策规划、轨迹预测等多个方向学习视频(扫码即可学习)

② 国内首个自动驾驶学习社区
国内最大最专业,近3000人的交流社区,已得到大多数自动驾驶公司的认可!涉及30+自动驾驶技术栈学习路线,从0到一带你入门自动驾驶感知(2D/3D检测、语义分割、车道线、BEV感知、Occupancy、多传感器融合、多传感器标定、目标跟踪)、自动驾驶定位建图(SLAM、高精地图、局部在线地图)、自动驾驶规划控制/轨迹预测等领域技术方案、大模型、端到端等,更有行业动态和岗位发布!欢迎扫描下方二维码,加入自动驾驶之心知识星球,这是一个真正有干货的地方,与领域大佬交流入门、学习、工作、跳槽上的各类难题,日常分享论文+代码+视频

③【自动驾驶之心】技术交流群
自动驾驶之心是首个自动驾驶开发者社区,聚焦感知、定位、融合、规控、标定、端到端、仿真、产品经理、自动驾驶开发、自动标注与数据闭环多个方向,目前近60+技术交流群,欢迎加入!扫码添加汽车人助理微信邀请入群,备注:学校/公司+方向+昵称(快速入群方式)

④【自动驾驶之心】全平台矩阵