
- 1软考高项第四版必背知识点简略版6_项目管理第四版考点汇总
- 2(18-4-06)Agents(智能代理): ReAct代理_react agent
- 3MIPS的冒泡排序的流程图_mips流程图
- 4【MySQL】——概念、逻辑、物理结构设计_mysql物理结构设计要点
- 5【转载】【C语言】浅析C语言之uint8_t / uint16_t / uint32_t /uint64_t_define uint64
- 6「小白必读」国内超火的 8 款 AI 大模型,你的副业都来自它_ai模型
- 7php软件开发微信分享功能,微信小程序实例:自定义分享功能的实现代码
- 8SpringBoot 集成 MongoDB_@field(index = indexdirection.ascending)
- 9「43」让多个视频,秒变电脑虚拟直播摄像头_电脑虚拟摄像头
- 10查看项目中的angular版本_查看angular版本
【机器学习】生成对抗网络 GAN_生成对抗网络 目标函数
赞
踩
GAN能干什么?
要问生成对抗网络(GAN)为什么这么火,就得看看它能干什么。
GAN是最近2年很热门的一种无监督算法,他能生成出非常逼真的照片,图像甚至视频。我们手机里的照片处理软件中就会使用到它。
GAN的核心思想是通过学习真实训练数据,生成“以假乱真”的数据。
GAN的设计初衷
一句话来概括 GAN 的设计动机就是——自动化。
-
从人工提取特征——到自动提取特征
深度学习最特别最厉害的地方就是能够自己学习特征提取。
机器的超强算力可以解决很多人工无法解决的问题。自动化后,学习能力更强,适应性也更强。 -
从人工判断生成结果的好坏——到自动判断和优化
监督学习中,训练集需要大量的人工标注数据,这个过程是成本很高且效率很低的。
而人工判断生成结果的好坏也是如此,有成本高和效率低的问题。
而 GAN 能自动完成这个过程,且不断的优化,这是一种效率非常高,且成本很低的方式。
下面我们通过GAN的原理来理解它是如何实现自动化的。
GAN 的基本原理(大白话)
生成对抗网络(GAN)由2个重要的部分构成
- 生成器(Generator):通过机器生成数据(大部分情况下是图像),目的是“骗过”判别器。
- 判别器(Discriminator):判断这张图像是真实的还是机器生成的,目的是找出生成器做的“假数据”。
生成模型的任务是生成看起来自然真实的、和原始数据相似的实例。判别模型的任务是判断给定的实例看起来是自然真实的还是人为伪造的(真实实例来源于数据集,伪造实例来源于生成模型)。

训练过程
- 第一阶段:固定“判别器D”,训练“生成器G”
我们使用一个还 OK 的判别器,让一个“生成器G”不断生成“假数据”,然后给这个“判别器D”去判断。
一开始,“生成器G”还很弱,所以很容易被揪出来。
但是随着不断的训练,“生成器G”技能不断提升,最终骗过了“判别器D”。
到了这个时候,“判别器D”基本属于瞎猜的状态,判断是否为假数据的概率为50%。 - 第二阶段:固定“生成器G”,训练“判别器D”
当通过了第一阶段,继续训练“生成器G”就没有意义了。这个时候我们固定“生成器G”,然后开始训练“判别器D”。
“判别器D”通过不断训练,提高了自己的鉴别能力,最终他可以准确的判断出所有的假图片。
到了这个时候,“生成器G”已经无法骗过“判别器D”。 - 循环阶段一和阶段二
通过不断的循环,“生成器G”和“判别器D”的能力都越来越强。
最终我们得到了一个效果非常好的“生成器G”,我们就可以用它来生成我们想要的图片了。
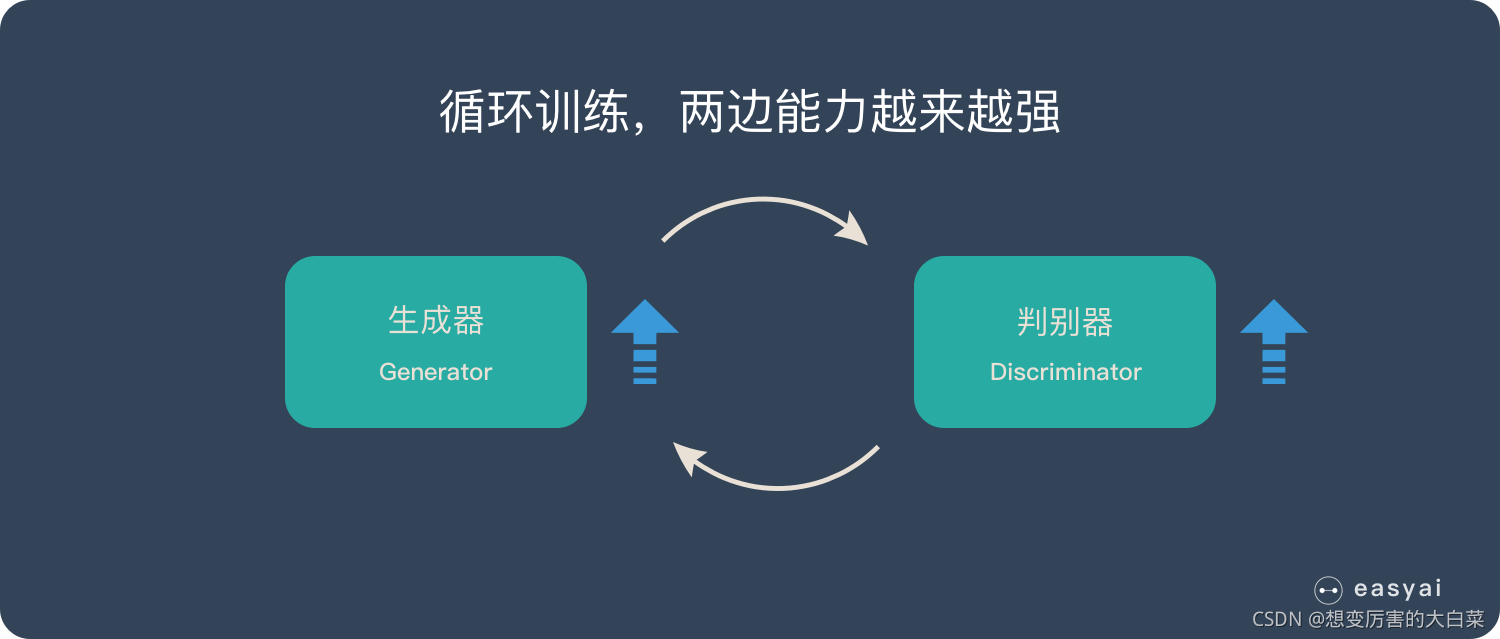
也就是说,生成器(generator)试图欺骗判别器(discriminator),判别器则努力不被生成器欺骗。
模型经过交替优化训练,两种模型都能得到提升,但最终我们要得到的是效果提升到很高很好的生成模型(造假团伙),这个生成模型(造假团伙)所生成的产品能达到真假难分的地步。
这样我们就可以使用这个生成器来生成我们想要的图片了(用于做训练集之类的)。
GAN的总结
- GAN(Generative Adversarial Networks) 是一种深度学习模型,是近年来复杂分布上无监督学习最具前景的方法之一。
- 模型通过框架中(至少)两个模块:生成模型(Generative Model)和判别模型(Discriminative Model)的互相博弈学习产生相当好的输出。
- 原始 GAN 理论中,并不要求 G 和 D 都是神经网络,只需要是能拟合相应生成和判别的函数即可。但实用中一般均使用深度神经网络作为 G 和 D 。
- 一个优秀的GAN应用需要有良好的训练方法,否则可能由于神经网络模型的自由性而导致输出不理想。
GAN的提出:“Generative Adversarial Networks”(2014NIPS)
-
文章总结:
框架中同时训练两个模型:捕获数据分布的生成模型G,和估计样本来自训练数据的概率的判别模型D。
G的训练程序是将D错误的概率最大化。这个框架对应一个最大值集下限的双方对抗游戏。
可以证明在任意函数G和D的空间中,存在唯一的解决方案,使得G重现训练数据分布,而D=0.5。
在G和D由多层感知器定义的情况下,整个系统可以用反向传播进行训练。
在训练或生成样本期间,不需要任何马尔可夫链或展开的近似推理网络。实验通过对生成的样品的定性和定量评估证明了本框架的潜力。 -
解释
1.生成模型(Generative Model)和判别模型(Discriminative Model)的工作
判别模型对输入变量进行预测。
生成模型是给定某种隐含信息,来随机产生观测数据。
举个简单的例子:
— 判别模型:给定一张图,判断这张图里的动物是猫还是狗。
— 生成模型:给一系列猫的图片,生成一张新的猫咪(不在数据集里)。
2.它们两的损失函数
对于判别模型,损失函数是容易定义的,因为输出的目标相对简单。
但生成模型的损失函数的定义就不是那么容易。我们对于生成结果的期望,往往是一个暧昧不清,难以数学公理化定义的范式。所以不妨把生成模型的回馈部分,交给判别模型处理。这就是Goodfellow将机器学习中的两大类模型,Generative和Discrimitive给紧密地联合在了一起。
3.原理
GAN的基本原理其实非常简单,这里以生成图片为例进行说明。
假设我们有两个网络,G(Generator)和D(Discriminator)。
正如它的名字所暗示的那样,它们的功能分别是:
— G是一个生成图片的网络,它接收一个随机的噪声z,通过这个噪声生成图片,记做G(z)。
— D是一个判别网络,判别一张图片是不是“真实的”。它的输入参数是x,x代表一张图片,输出D(x)代表x为真实图片的概率,如果为1,就代表100%是真实的图片,而输出为0,就代表不可能是真实的图片。
如图,GAN网络整体示意如下:
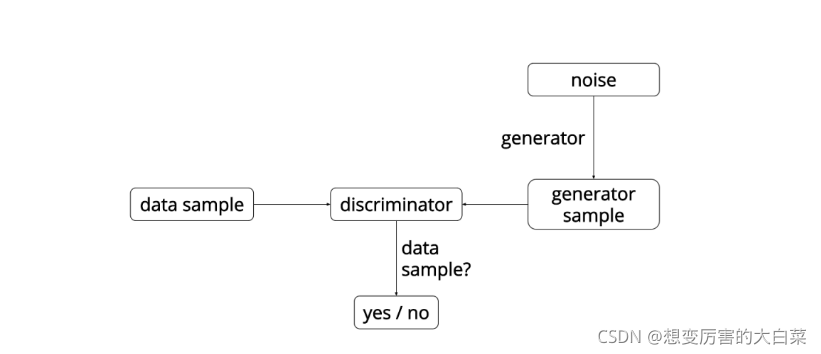
在训练过程中,生成网络G的目标就是尽量生成真实的图片去欺骗判别网络D。而D的目标就是尽量把G生成的图片和真实的图片分别开来。这样,G和D构成了一个动态的“博弈过程”。
最后博弈的结果是什么?在最理想的状态下,G可以生成足以“以假乱真”的图片G(z)。对于D来说,它难以判定G生成的图片究竟是不是真实的,因此D(G(z)) = 0.5。
(插一嘴:纳什均衡,它是指博弈中这样的局面,对于每个参与者来说,只要其他人不改变策略,他就无法改善自己的状况。对应的,对于GAN,情况就是生成模型 G 恢复了训练数据的分布(造出了和真实数据一模一样的样本),判别模型再也判别不出来结果,准确率为 50%,约等于乱猜。这是双方网路都得到利益最大化,不再改变自己的策略,也就是不再更新自己的权重。)
这样我们的目的就达成了:我们得到了一个生成式的模型G,它可以用来生成图片。 -
Goodfellow从理论上证明了该算法的收敛性,以及在模型收敛时,生成数据具有和真实数据相同的分布(保证了模型效果)。GAN模型的目标函数如下:
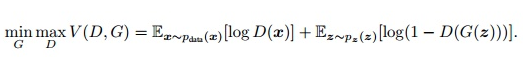
公式中x表示真实图片,z表示输入G网络的噪声,G(z)表示G网络生成的图片,D(·)表示D网络判断图片是否真实的概率。
在这里,训练判别器D使得最大概率地分辩训练样本的标签(最大化log D(x)和log(1 – D(G(z)))),训练网络G最小化log(1 – D(G(z))),即最大化判别器D的损失。
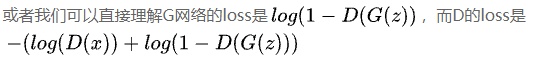
而训练过程中固定一方,更新另一个网络的参数,交替迭代,使得对方的错误最大化,最终,G 能估测出样本数据的分布,也就是生成的样本更加的真实。
对以上阐述的进一步解释:
1.交替优化,每轮迭代中,先优化D,再保持D不变,优化G,如此迭代多次。
2.需要平衡D和G的训练次数。G的目标函数里包含D,训练出优秀G的前提是训练出优秀的D,因此一般在每轮迭代中,先训练k次D(k为大于等于1的整数),再训练一次G。
3.训练G时,一般固定D,此时目标函数中的Ex~pdata(x)[logD(x)]相当于常数,可以忽略,因此G的优化目标变成原始目标函数的后一项,即最小化Ez~pz(z)[log(1-D(G(z)))]。
4.在训练早期阶段,G的生成能力较弱,D能轻松分辨出真假样本,此时log(1-D(G(z)))接近0,其导数在0附近变化较小,不利于梯度下降优化。一般会将G的优化目标从最小化Ez~pz(z)[log(1-D(G(z)))]改为最大化Ez~pz(z)[logD(G(z))],便于早期学习。
从式子中理解对抗: 我们知道G网络的训练是希望使判别器对其生成的数据的判别D(G(z))趋近于1,也就是正类,这样G的loss就会最小。而D网络的训练就是一个2分类,目标是分清楚真实数据和生成数据,也就是希望真实数据的D输出趋近于1,而生成数据的输出即D(G(z))趋近于0,或是负类。这里就是体现了对抗的思想。 -
对 Goodfellow的GAN模型的目标函数的详细解释
1.x为真实数据的随机向量,各元素服从某个特定的分布pdata(x)。假设真实数据为28×28的灰度图像,那么x可以为784维向量;假设真实数据为长度252的时间序列,那么x为252维向量。
2.z为噪音向量,也称为隐变量(Latent Variable),各元素服从分布pz(z),一般将z的各元素设为独立同分布,且服从标准正态分布或[0,1]的均匀分布。噪音的维度可自由定义,例如将z设为100维向量。
3.x~pdata(x)相当于真实数据的一次采样,每次采样得到一条真实样本,例如一张真实图像、一条真实股价序列;z~pz(z)相当于噪音数据的一次采样。
4.生成器G的结构为神经网络,神经网络本质上是某个从输入到输出的非线性映射。G的输入为噪音向量z,输出为虚假数据G(z),G(z)的维数和真实数据x相同。假设真实数据为长度252的时间序列,x为252维向量,那么G(z)也是252维向量。
5.判别器D的结构为神经网络。D的输入为真实数据x或虚假数据G(z),输出为0~1之间的实数,相当于判别器对样本的真假判断。输出越接近1代表判别器认为输入数据偏向于真样本,越接近0代表判别器认为输入数据偏向于假样本。
6.对判别器D的输出取对数log,如logD(x)及log(1-D(G(z))),是常见的判别模型损失函数构建方式。对数的作用是将[0,1]区间内的数映射到(-∞,0]的范围,以便对其求导而后进行梯度下降优化。
7.Ex~pdata(x)[logD(x)]代表判别器对真实样本判断结果的期望。对于最优判别器D*,真实样本判断结果D(x)应为1,logD(x)为0;若判别器非最优,logD(x)小于0。换言之,若希望判别器达到最优,E~pdata(x)[logD(x)]应越大越好。
8.类似地,Ez~pz(z)[log(1-D(G(z)))]代表判别器对虚假样本判断结果的期望。对于最优判别器D*,虚假样本判断结果D(G(z))应为0,1-D(G(z))为1,log(1-D(G(z)))为0;若判别器非最优,log(1-D(G(z)))小于0。换言之,若希望判别器达到最优,Ez~pz(z)[log(1-D(G(z)))]应越大越好。
9.V(D,G)为上述两项的加总,称为价值函数(Value Function),相当于目标函数,本质是交叉熵损失函数。判别器真假识别能力越强,V(D,G)应越大。
10.GAN求解的是minimax(极小化极大)问题。第一步,我们希望寻找最优判别器D*,使得优化目标V(D,G)取最大值,即maxDV(D,G)部分,第一步的逻辑参见上一点。关键在于第二步,我们希望继续寻找最优生成器G*,使得最优判别器下的目标函数取最小值,即生成的样本令判别器表现越差越好,即minGmaxDV(D,G)部分,博弈的思想正体现在此处。 -
另一种解释帮助理解
生成器的作用是,通过学习训练集数据的特征,在判别器的指导下,将随机噪声分布尽量拟合为训练数据的真实分布,从而生成具有训练集特征的相似数据。而判别器则负责区分输入的数据是真实的还是生成器生成的假数据,并反馈给生成器。两个网络交替训练,能力同步提高,直到生成网络生成的数据能够以假乱真,并与判别网络的能力达到一定均衡。
GAN的优缺点
-
优势
1.能更好建模数据分布(图像更锐利、清晰)
2.G的参数更新不是直接来自数据样本,而是使用来自D的反向传播。
3.理论上,GANs 能训练任何一种生成器网络(只要是可微分函数都可以用于构建D和G,能够与深度神经网络结合做深度生成式模型)。其他的框架需要生成器网络有一些特定的函数形式,比如输出层是高斯的。
4.GANs可以比完全明显的信念网络(NADE,PixelRNN,WaveNet等)更快的产生样本,因为它不需要在采样序列生成不同的数据。
5.模型只用到了反向传播,无需利用马尔科夫链反复采样(GANs生成实例的过程只需要模型运行一次,而不是以马尔科夫链的形式迭代很多次),无需在学习过程中进行推断,没有复杂的变分下界,避开近似计算棘手的概率的难题。 -
缺陷
1.难训练,不稳定。生成器和判别器之间需要很好的同步,但是在实际训练中很容易D收敛,G发散。D/G 的训练需要精心的设计。(训练GAN需要达到纳什均衡,有时候可以用梯度下降法做到,有时候做不到。我们还没有找到很好的达到纳什均衡的方法,所以训练GAN相比VAE或者PixelRNN是不稳定的)
2.模式缺失(Mode Collapse)问题。GANs的学习过程可能出现模式缺失,生成器开始退化,总是生成同样的样本点,无法继续学习。
3.它很难去学习生成离散的数据,就像文本。(所以GAN的应用领域都在图像方面)
相比玻尔兹曼机,GANs很难根据一个像素值去猜测另外一个像素值,GANs天生就是做一件事的,那就是一次产生所有像素,你可以用BiGAN来修正这个特性,它能让你像使用玻尔兹曼机一样去使用Gibbs采样来猜测缺失值。
4.可解释性差,生成模型的分布 Pg(G)没有显式的表达。
GAN 的实际应用
-
生成图像数据集
人工智能的训练是需要大量的数据集的,如果全部靠人工收集和标注,成本是很高的。
GAN 可以自动的生成一些数据集,提供低成本的训练数据。
例如在人脸识别、行人重识别等任务中,可以通过GAN来生成具有多样高级语义特征的样本来充实训练集数据,以帮助提升模型精度。(数据增强) -
图像到图像的转换
简单说就是把一种形式的图像转换成另外一种形式的图像,就好像加滤镜一样神奇。例如:
— 把草稿转换成照片
— 把卫星照片转换为Google地图的图片
— 把照片转换成油画
— 把白天转换成黑夜 -
文字到图像的转换
-
语意 – 图像 – 照片 的转换
-
自动生成模特
-
照片到Emojis
GANs 可以通过人脸照片自动生成对应的表情(Emojis)。 -
照片编辑
使用GAN可以生成特定的照片,例如更换头发颜色、更改面部表情、甚至是改变性别。 -
预测不同年龄的长相
给一张人脸照片, GAN 就可以帮你预测不同年龄阶段你会长成什么样。 -
提高照片分辨率,让照片更清晰
给GAN一张照片,他就能生成一张分辨率更高的照片,使得这个照片更加清晰。 -
照片修复
假如照片中有一个区域出现了问题(例如被涂上颜色或者被抹去),GAN可以修复这个区域,还原成原始的状态。 -
自动生成3D模型
给出多个不同角度的2D图像,就可以生成一个3D模型。
应用总结:
图像生成 :GAN最常使用的地方就是图像生成,如超分辨率任务,语义分割等等。
(观察以上应用,感觉GAN的应用都是和图像处理相关的。)
数据增强 :用GAN生成的图像来做数据增强。
主要解决的问题是:对于小数据集,数据量不足, 如果能生成一些就好了。GAN 生成数据是可以用在实际的图像问题上的。(感觉也是和图像相关的)
至于给GAN 生成的数据有分配标签的方式, 有以下三类:(假设我们做五分类)
- 把生成的数据都当成新的一类, 六分类,那么生成图像的 label 就可以是 (0, 0, 0, 0, 0, 1) 这样给。
- 按照置信度最高的 动态去分配,那个概率高就给谁 比如第三类概率高(0, 0, 1, 0, 0)。
- 既然所有类都不是,那么可以参考inceptionv3,搞label smooth,每一类置信度相同(0.2, 0.2, 0.2, 0.2, 0.2)。
GAN的一些经典变种
1. DCGAN:
DCGAN原文:Unsupervised Representation Learning with Deep Convolutional Generative Adversarial Networks
DCGAN是继GAN之后比较好的改进,其主要的改进主要是在网络结构上,到目前为止,DCGAN的网络结构还是被广泛的使用,DCGAN极大的提升了GAN训练的稳定性以及生成结果质量。
DCGAN把上述的G和D用了两个卷积神经网络(CNN)。同时对卷积神经网络的结构做了一些改变,以提高样本的质量和收敛的速度,这些改变有:
- 取消所有pooling层。G网络中使用转置卷积(transposed convolutional layer)进行上采样,D网络中用加入stride的卷积代替pooling。
- 在D和G中均使用batch normalization
- 去掉FC层,使网络变为全卷积网络
- G网络中使用ReLU作为激活函数,最后一层使用tanh
- D网络中使用LeakyReLU作为激活函数
2. WGAN和WGAN-GP:
WGAN原文:Wasserstein GAN
WGAN主要从损失函数的角度对GAN做了改进,损失函数改进之后的WGAN即使在全链接层上也能得到很好的表现结果,具体的来说,WGAN对GAN的改进有:
- 判别器最后一层去掉sigmoid。
- 生成器和判别器的loss不取log。
- 对更新后的权重强制截断到一定范围内,比如[-0.01,0.01],以满足论文中提到的lipschitz连续性条件。
- 论文中也推荐使用SGD, RMSprop等优化器,不要基于使用动量的优化算法,比如adam。
WGAN-GP原文:Improved Training of Wasserstein GANs
之前的WGAN虽然理论上有极大贡献,但在实验中却发现依然存在着训练困难、收敛速度慢的问题,这个时候WGAN-GP就出来了,它的贡献是:
- 提出了一种新的lipschitz连续性限制手法—梯度惩罚,解决了训练梯度消失梯度爆炸的问题。
- 比标准WGAN拥有更快的收敛速度,并能生成更高质量的样本。
- 提供稳定的GAN训练方式,几乎不需要怎么调参,成功训练多种针对图片生成和语言模型的GAN架构。
3. Conditional GAN:
因为原始的GAN过于自由,训练会很容易失去方向,从而导致不稳定又效果差。而Conditional GAN就是在原来的GAN模型中加入一些先验条件,使得GAN变得更加的可控制。
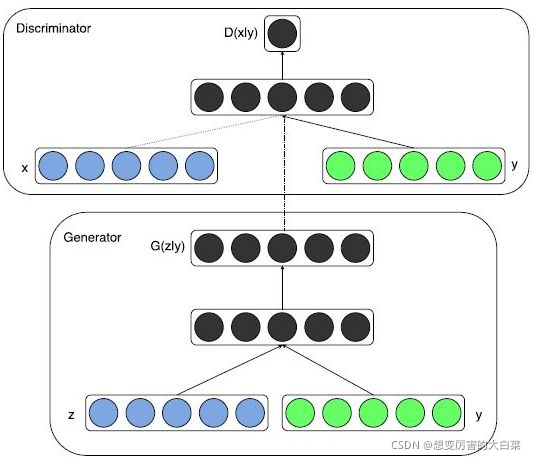
具体的来说,我们可以在生成模型G和判别模型D中同时加入条件约束y来引导数据的生成过程。条件可以是任何补充的信息,如类标签,其它模态的数据等。然后这样的做法应用也很多,比如图像标注,利用text生成图片等等。
对比之前的目标函数,Conditional GAN的目标函数其实差不多:
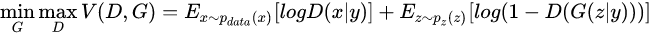
就是多了把噪声z和条件y作为输入同时送进生成器或者把数据x和条件y作为输入同时送进判别器,如图。这样在外加限制条件的情况下生成图片。
其他生成网络简介
前面说过,GAN的目的是得到一个性能优秀的生成模型。
所以说,对抗生成模型GAN首先是一个生成模型,和大家比较熟悉的、用于分类的判别模型不同。
判别模型的数学表示是y=f(x),也可以表示为条件概率分布p(y|x)。当输入一张训练集图片x时,判别模型输出分类标签y。模型学习的是输入图片x与输出的类别标签的映射关系。即学习的目的是在输入图片x的条件下,尽量增大模型输出分类标签y的概率。
而生成模型的数学表示是概率分布p(x)。没有约束条件的生成模型是无监督模型,将给定的简单先验分布π(z)(通常是高斯分布),映射为训练集图片的像素概率分布p(x),即输出一张服从p(x)分布的具有训练集特征的图片。模型学习的是先验分布π(z)与训练集像素概率分布p(x)的映射关系。
其实GAN模型以及所有的生成模型都一样,做的事情只有一件:拟合训练数据的分布。对图片生成任务来说就是拟合训练集图片的像素概率分布。
生成网络并非只有GAN,介绍下其他几种:
- 自回归模型(Autoregressive model)是从回归分析中的线性回归发展而来,只是不用x预测y,而是用x预测 x(自己),所以叫做自回归。多用于序列数据生成如文本、语音。PixelRNN/CNN则使用这种方法生成图片,效果还不错。但是由于是按照像素点去生成图像导致计算成本高, 在可并行性上受限,在处理大型数据如大型图像或视频是具有一定麻烦的。
- 变分自编码器(VAE):VAE是在AE(Autoencoder自编码器)的基础上让图像编码的潜在向量服从高斯分布从而实现图像的生成,优化了数据对数似然的下界,VAE在图像生成上是可并行的, 但是VAE存在着生成图像模糊的问题。
- 基于流的模型(Flow-based Model)包括Glow、RealNVP、NICE等。流模型思想很直观:寻找一种变换 y = f(x)(f 可逆,且 y 与 x 的维度相同) 将数据空间映射到另一个空间,新空间各个维度相互独立。这些年,看着GAN一直出风头,流模型表示各种不服,自从2016年问世以来,一直在“不服中…”。
而GAN模型可以说是生成模型中的“明星”。

