
- 1事理图谱的构建:知识图谱_事理图谱构建
- 2怎么理解np.random.seed()?
- 3【Linux】基础I/O——FILE,用户缓冲区_linux file定义
- 4windows:Opencv使用Cmake & VS 编译, C++、python、Cuda、Qt 环境详细教学及踩坑 一 :编译篇
- 5国家开放大学计算机应用基础形考作业四,国家开放大学“计算机应用基础”形考作业2...
- 6京东面试官倾囊相授:Java程序员准备面试的正确姿势_java面试官
- 7常见安全算法_主动安全算法授权方法有哪些
- 801. Hibernate 教程简介
- 9IDEA 2023.2 最新的UI(菜单栏/导航栏被隐藏)的问题解决_为什么idea2023.2顶部界面不一样
- 10Mac M1:通过docker安装RocketMQ、RocketMQ-Dashboard_mac安装rocketmq
基于分类算法的学习失败预警(机器学习课程期末设计报告)
赞
踩
目录
3.1.2.8 逻辑回归(Logistic Regression)
一.课设背景
在现代教育体系中,学生的学习情况和学业表现受到广泛关注。随着教育信息化的发展,越来越多的学校和教育机构开始使用各种信息技术手段来提升教学质量和学生管理水平。学习失败,即学生在学业上未能达到预期的学习目标,是教育过程中一个亟需解决的问题。如何利用数据分析和机器学习技术,提前预警学生可能的学习失败,从而采取有效的干预措施,成为一个重要的研究课题。
传统的学生管理和学业预警多依赖于教师的经验和直觉,这种方式不仅耗费大量的人力和时间,而且存在主观判断偏差,难以及时和准确地发现潜在的学习问题。随着教育大数据的不断积累,利用数据驱动的方法进行学生学业表现的分析和预测成为可能。通过对学生在校期间的各种数据进行分析,可以挖掘出影响学生学业表现的关键因素,进而实现对学习失败的有效预警。
1.1 设计要求
本课题主要使用机器学习中比较常见的算法,包括常用的随机森林、支持向量机(SVM)、逻辑回归、Adaboost、多层感知机(MLP)、决策树,借助机器学习,以研究大学生综合素养的预警机制并比较不同算法之间的优劣性。
因为本实验使用了网格搜索,所以在参数较多时使用cpu运行时间比较长,大概为20分钟,因为本文只做简单的实验,所以随机森林算法之外所选择使用的参数和参数数量不足,有能力的建议使用gpu或者服务器运行使用网格搜索更多参数得到的结果才会更快更好。
1.2 项目概述
通过对学习者的学习过程、学习日志、学习结果进行多维分析,综合判断学生的学习情况,能够提前发现存在失败风险的学生,对其进行系统干预和人工干预。
学生失败风险需要分析学生历史学习情况,分析学生在班级中的学习情况,分析学生和标准学习过程的偏离,从横向纵向多维度进行分析。
本课程设计的目的在于开发一个基于分类算法的学习失败预警系统。通过对学生的个人信息、学业成绩、课堂表现、课外活动等多维度数据进行分析,构建分类模型,识别出可能面临学习困难的学生,并提前发出预警。这不仅有助于学校和教师及时采取干预措施,帮助学生改善学习状况,提升整体教学质量;同时,也为教育管理部门制定教育政策和改进教育方法提供数据支持。
二.实验环境
操作系统: Windows 11
版本:23H
操作系统版本:22631.3447;
硬件平台: Legion Y9000P 2021H;
设计软件: Visual Studio Code;
三.设计原理
3.1 理论知识
3.1.1 学习失败风险预测流程

图1.学习失败风险预测流程
3.1.2 数据预处理
3.1.2.1 缺失值处理(空值填充)
空值填充是一种数据处理技术,当数据集中存在缺失值或空值时,空值填充的目的是通过一些方法或规则来填补这些缺失的数值,以便进行后续的分析或建模。
空值填充是确保数据质量和准确性的重要步骤,能够提高数据分析和建模的效果,并且避免丢失有用的信息。
3.1.2.2 数据平衡
不平衡数据(Imbalanced Datasets)
所谓的不平衡数据集指的是数据集各个类别的样本量极不均衡。以二分类问题为例,假设正类的样本数量远大于负类的样本数量,通常情况下通常情况下把多数类样本的比例接近100:1这种情况下的数据称为不平衡数据。不平衡数据的学习即需要在分布不均匀的数据集中学习到有用的信息。
不平衡数据集的处理方法主要分为两个方面:
从数据的角度出发,主要方法为采样,分为欠采样和过采样以及对应的一些改进方法。
过采样(Oversampling): 增加数据集中样本数量较少的类别的样本数量,使得两个类别的样本数量相近。常见的过采样方法包括随机复制样本、SMOTE(Synthetic Minority Over-sampling Technique)等。
欠采样(Undersampling): 减少数据集中样本数量较多的类别的样本数量,使得两个类别的样本数量相近。欠采样的方法包括随机删除样本、近邻少数类(NearMiss)等。
从算法的角度出发,考虑不同误分类情况代价的差异性对算法进行优化,主要是基于代价敏感学习算法(Cost-Sensitive Learning),代表的算法有Adacost;
另外可以将不平衡数据集的问题考虑为一分类(One Class Learning)或者异常检测(Novelty Detection)问题,代表的算法有One-class SVM。
3.1.2.3 标准化处理
数据标准化是一个常用的数据预处理操作,目的是处理不同规模和量纲的数据,使其缩放到相同的数据区间和范围,以减少规模、特征、分布差异等对模型的影响。
比如线性回归模型、逻辑回归模型或包含矩阵的模型,它们会受到输入尺度(量纲)的影响。相反,那些基于树的模型则根本不在乎输入尺度(量纲)有多大。如果模型对输入特征的尺度(量纲)很敏感,就需要进行特征缩放。顾名思义,特征缩放会改变特征的尺度,有些人将其称为特征归一化。特征缩放通常对每个特征独立进行。下面讨论几种常用的特征缩放操作,每种操作都会产生一种不同的特征值分布。
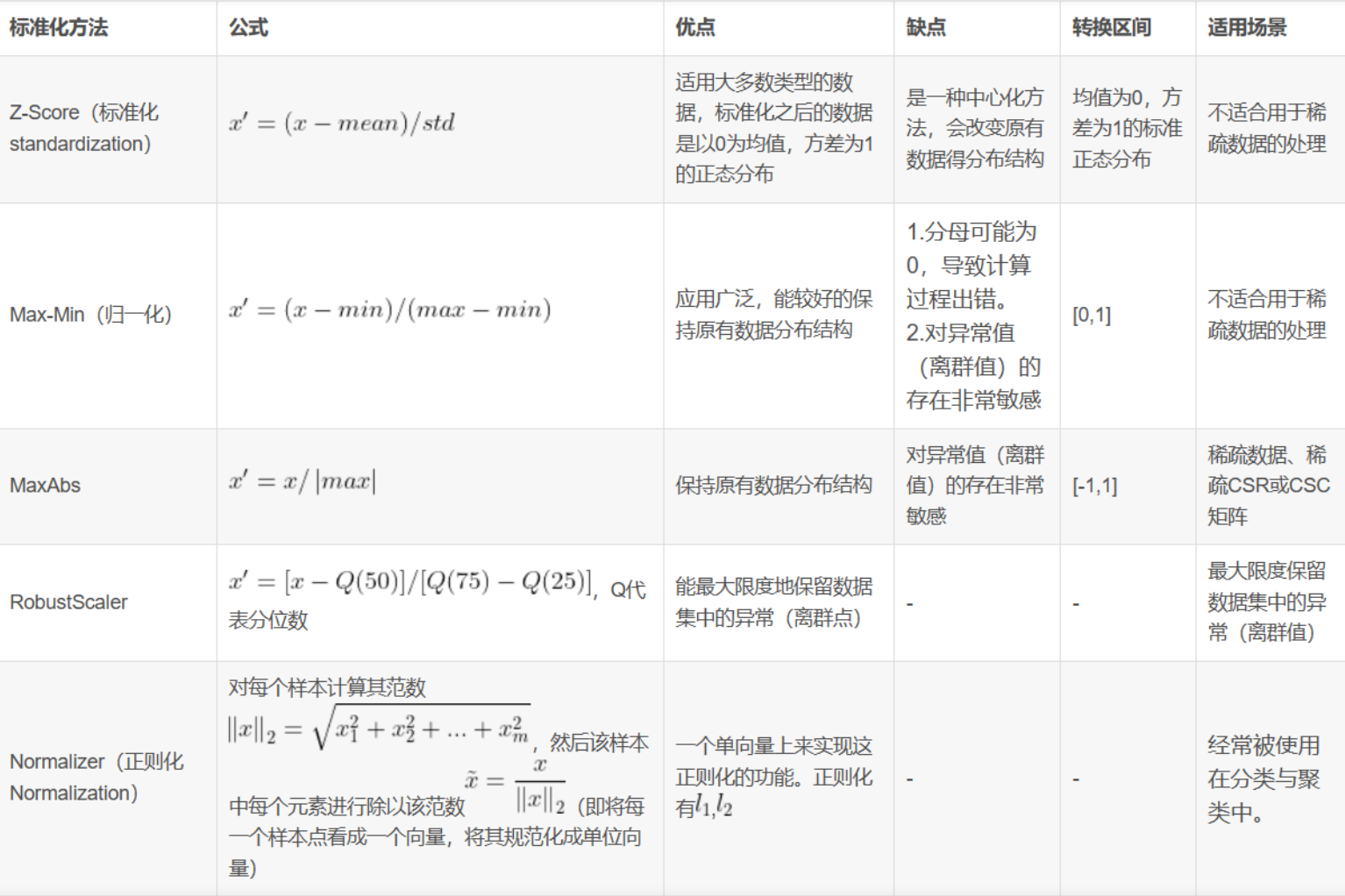
图2.数据的标准化
标准化可以帮助解决数据的尺度差异问题,提高模型的稳定性、收敛速度和泛化能力,是许多机器学习算法中的重要预处理步骤之一。
3.1.3 构建模型进行训练
3.1.3.1 网格搜索
网格搜索(grid search)用于选取模型的最优超参数。获取最优超参数的方式可以绘制验证曲线,但是验证曲线只能每次获取一个最优超参数。如果多个超参数有很多排列组合的话,就可以使用网格搜索寻求最优超参数的组合。
网格搜索针对超参数组合列表中的每一个组合,实例化给定的模型,做cv次交叉验证,将平均得分最高的超参数组合作为最佳的选择,返回模型对象。
3.1.3.2 随机森林算法
将多个决策树结合在一起,每次数据集是随机有放回的选出,同时随机选出部分特征作为输入,所以该算法被称为随机森林算法。可以看到随机森林算法是以决策树为估计器的Bagging算法。
随机森林算法利用多棵子树对样本进行训练,通过引入投票机制实现多棵决策树预测结果的汇总,对于多维特征的分析效果较优,并且可以用其进行特征的重要性分析,运行效率和准确率方面均比较高。
3.1.2.3 混淆矩阵
在机器学习领域,混淆矩阵(Confusion Matrix),又称为可能性矩阵或错误矩阵。混淆矩阵是可视化工具,特别用于监督学习,在无监督学习一般叫做匹配矩阵。在图像精度评价中,主要用于比较分类结果和实际测得值,可以把分类结果的精度显示在一个混淆矩阵里面。
混淆矩阵要表达的含义:
混淆矩阵的每一列代表了预测类别,每一列的总数表示预测为该类别的数据的数目;
每一行代表了数据的真实归属类别,每一行的数据总数表示该类别的数据实例的数目;每一列中的数值表示真实数据被预测为该类的数目。
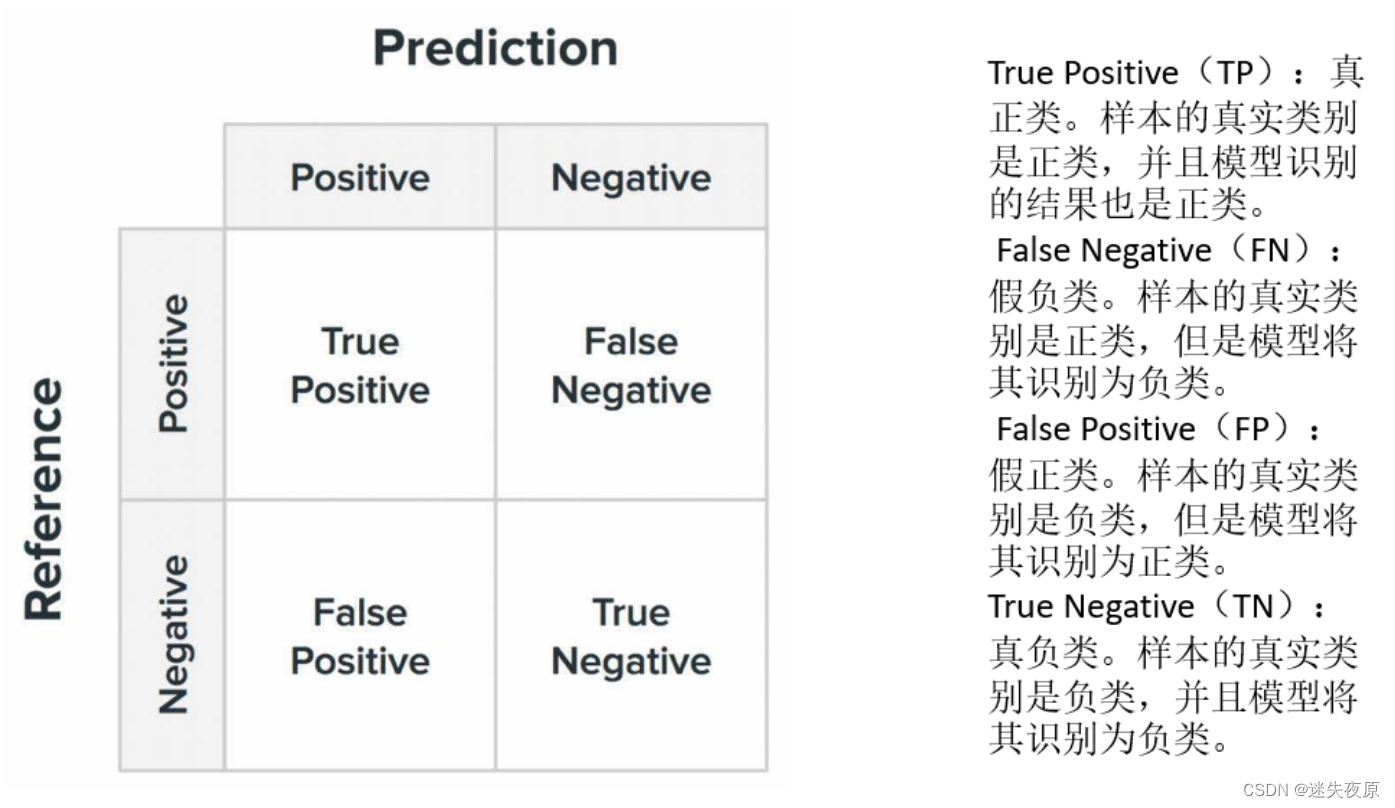
图3.混淆矩阵
混淆矩阵是对分类问题的预测结果的总结。使用计数值汇总正确和不正确预测的数量,并按每个类进行细分,这是混淆矩阵的关键所在。混淆矩阵显示了分类模型的在进行预测时会对哪一部分产生混淆。它不仅可以让您了解分类模型所犯的错误,更重要的是可以了解哪些错误类型正在发生。正是这种对结果的分解克服了仅使用分类准确率所带来的局限性。
3.1.2.4 分类指标
精确率(Accuracy):精确率是最常用的分类性能指标。可以用来表示模型的精度,即模型识别正确的个数/样本的总个数。
Accuracy = (TP+TN)/(TP+FN+FP+TN)
正确率或者准确率(Precision):又称为查准率,表示在模型识别为正类的样本中,真正为正类的样本所占的比例。
Precision = TP/(TP+FP)
召回率(Recall):又称为查全率,召回率表现出在实际正样本中,分类器能预测出多少。Recall(召回率) = Sensitivity(敏感指标,True Positive Rate,TPR)= 查全率表示的是,模型正确识别出为正类的样本的数量占总的正类样本数量的比值。
Recall = TP/(TP+FN)
查准率和查全率是一对矛盾的指标。一般来说,查准率高时,查全率往往偏低;二查全率高时,查准率往往偏低。
Fβ_Score:Fβ的物理意义就是将正确率和召回率的一种加权平均,在合并的过程中,召回率的权重是正确率的β倍。F1分数认为召回率和正确率同等重要,F2分数认为召回率的重要程度是正确率的2倍,而F0.5分数认为召回率的重要程度是正确率的一半。比较常用的是F1分数(F1 Score),是统计学中用来衡量二分类模型精确度的一种指标。
F1_Score:数学定义为 F1分数(F1-Score),又称为平衡 F分数(Balanced Score),它被定义为正确率和召回率的调和平均数。在 β=1 的情况,F1-Score的值是从0到1的,1是最好,0是最差。
计算Precision,Recall,Specificity等只是计算某一分类的特性,而Accuracy和F1-Score是判断分类模型总体的标准。
3.1.2.5 ROC曲线和AUC面积
我们通常说的ROC曲线的中文全称叫做接收者操作特征曲线(receiver operating characteristic curve),也被称为感受性曲线。
该曲线有两个维度,横轴为fpr(假正率),纵轴为tpr(真正率)
准确率(accuracy):(TP+TN)/ ALL ,准确率是所有预测为正确的样本除以总样本数,用以衡量模型对正负样本的识别能力。
错误率(error rate):(FP+FN)/ ALL ,错误率就是识别错误的样本除以总样本数。
假正率(fpr):FP / (FP+TN) ,假正率就是真实负类中被预测为正类的样本数除以所有真实负类样本数。
真正率(tpr):TP / (TP+FN),真正率就是真实正类中被预测为正类的样本数除以所有真实正类样本数。
上面说了什么是ROC曲线,横轴为fpr,纵轴为tpr,fpr就是假正率,就是真实的负类被预测为正类的样本数除以所有真实的样本数,而tpr是真正率,是正式的正类被预测为正类的数目除以所有正类的样本数,所以我们的目标就是让假正率越小,真正率越大(负样本被误判的样本数越少,正样本被预测正确的样本数越大),那么对应图中ROC曲线来说,我们希望的是fpr越小,tpr越大,即曲线越靠近左上方越好,那么下面的面积也就成为了我们的衡量指标,俗称AUC(Area Under Curve)。
3.1.2.6 袋外误差OOB
袋外样本OOB (Out of bag):在随机森林中,n个训练样本会通过bootstrap (有放回的随机抽样) 的抽样方式进行T次抽样每次抽样产生样本数为n的采样集,进入到并行的T个决策树中。
有放回的抽样方式会导致有部分训练集中的样本(约36.8%)未进入决策树的采样集中,而这部分未被采集的的样本就是袋外数据oob。袋外数据就可以用来检测模型的泛化能力,和交叉验证类似。
3.1.2.7 支持向量机(SVM)
支持向量机(SVM)是一种二类分类模型。它的基本模型是定义在特征空间上的间隔最大的线性分类器,间隔最大使它有别于感知机;支持向量机还包括核技巧,这使它成为实质上的非线性分类器。支持向量机的学习策略就是间隔最大化,可形式化为一个求解凸二次规划的问题,支持向量机的学习算法是求解凸二次规划的最优算法。
3.1.2.8 逻辑回归(Logistic Regression)
Logistic Regression 虽然被称为回归,但其实际上是分类模型,并常用于二分类。Logistic 回归的本质是:假设数据服从这个分布,然后使用极大似然估计做参数的估计。
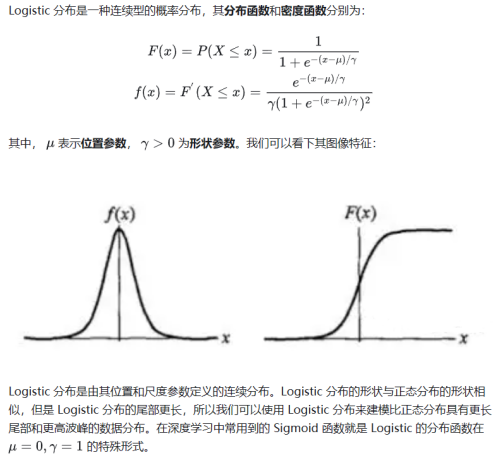
图4.逻辑回归
3.1.2.9 AdaBoost
AdaBoost的全称为adaptive boosting(自适应boosting),可以将其运行过程归结为以下几点:
训练数据集中的每个样本都会被赋予一个相同的权重值,这些权重会构成一个向量,暂称为D。
分类器在训练数据集之后会计算出该分类器的错误率,即分错样本的概率,并且依据错误率更新分类器的权重。
在下一个分类器训练之前,会依据上一个分类器的权重调整每一个样本的权重,上一次分对的样本权重降低,分错的样本权重提高。
迭代次数是人为设置的,在达到迭代次数或者满足某个条件后,以加权求和的方式确定最终的分类结果。
3.1.2.10 多层感知机(MLP)
多层感知机(Multilayer Perceptron,简称MLP),是一种基于前馈神经网络(Feedforward Neural Network)的深度学习模型,由多个神经元层组成,其中每个神经元层与前一层全连接。多层感知机可以用于解决分类、回归和聚类等各种机器学习问题。
多层感知机的每个神经元层由许多神经元组成,其中输入层接收输入特征,输出层给出最终的预测结果,中间的隐藏层用于提取特征和进行非线性变换。每个神经元接收前一层的输出,进行加权和和激活函数运算,得到当前层的输出。通过不断迭代训练,多层感知机可以自动学习到输入特征之间的复杂关系,并对新的数据进行预测。
3.1.2.11 决策树
决策树算法是一种基于树形结构的监督学习算法,用于解决分类和回归问题。在决策树中,每个内部节点表示一个特征或属性,每个分支表示该特征或属性的一个可能的取值,每个叶节点表示一个类别或一个数值。决策树通过递归地将数据集划分为更小的子集,并在每个子集上应用相同的过程来构建树。
决策树算法有多种不同的实现方式,最常见的是 CART(Classification and Regression Trees)算法和ID3(Iterative Dichotomiser 3)算法。
四.设计代码
本文不仅提供了全部代码,还提供PPT和Word版本的实验报告,下载链接为
https://pan.baidu.com/s/1OBi5YBE23UVn_7aAkwnT0A?pwd=gnz6
提取码:gnz6
五.实验测试和结果分析
5.1 随机森林算法和网格搜索
5.1.1 实验代码
- param_grid = {
- 'min_samples_split': range(2, 10),
- 'n_estimators' : [10,50,100,150],
- 'max_depth': [5, 10,15,20],
- 'max_features': [5, 10, 20]
- }
-
- scorers = {
- 'precision_score': make_scorer(precision_score),
- 'recall_score': make_scorer(recall_score),
- 'accuracy_score': make_scorer(accuracy_score)
- }
-
- classifier=RandomForestClassifier(criterion='entropy',oob_score=True,random_state = 42)
- refit_score='precision_score'
- skf = StratifiedKFold(n_splits=3)
- grid_search=GridSearchCV(classifier,param_grid,refit=refit_score,cv=skf, return_train_score=True,scoring=scorers, n_jobs=-1)
- grid_search.fit(X_train, y_train)
-
- y_pred = grid_search.predict(X_test)
- print(grid_search.best_params_)
- print(pd.DataFrame(confusion_matrix(y_test,
- y_pred),columns=['pred_neg', 'pred_pos'],
- index=['neg', 'pos']))
-
- print("accuracy:",accuracy_score(y_test, y_pred))
- print("recall:",recall_score(y_test, y_pred))
- print("roc_auc:",sklearn.metrics.roc_auc_score(y_test,
- grid_search.predict_proba(X_test)[:,1]))
- print("f1:",sklearn.metrics.f1_score(y_test, y_pred))

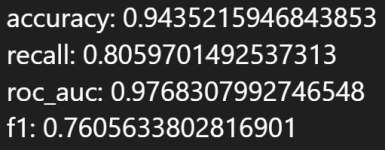
5.1.2 实验结果
1.refit_score = 'precision_score'
最佳参数:

混淆矩阵:

性能指标:
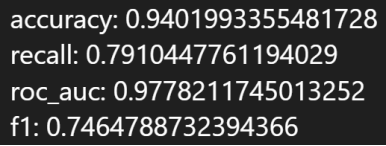
2.refit_score = 'recall_score'
最佳参数:

混淆矩阵:

性能指标:
5.2 ROC曲线
5.2.1 实验代码
- from scipy import interp
- params = {'legend.fontsize': 'x-large',
- 'figure.figsize': (12, 9),
- 'axes.labelsize': 'x-large',
- 'axes.titlesize':'x-large',
- 'xtick.labelsize':'x-large',
- 'ytick.labelsize':'x-large'}
- plt.rcParams.update(params)
5.2.2 实验结果
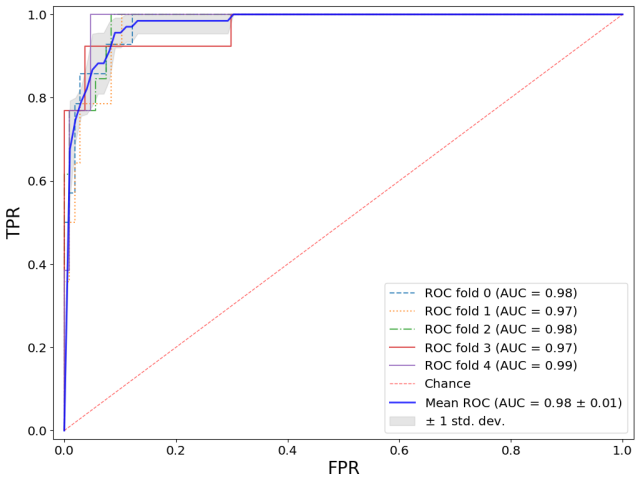
图5.ROC曲线
实现本模型的ROC曲线绘制,将测试集划分为3部分,即fold 0、fold 1、fold 2, 绘制其ROC曲线,并分别计算它们的AUC值。
横坐标表示假正类率FPR,纵坐标表示真正类率TPR,实线部分为平均ROC曲线,其下面积用AUC的值表示,随机森林算法的AUC均值可达0.98.可以看到,平均ROC曲线效果较好。
5.3 准确率和查全率
5.3.1 实验结果
为了将迭代计算随机森林评估器的准确率和查全率,将3份数据的平均准确率和平均查全率变化趋势可视化。
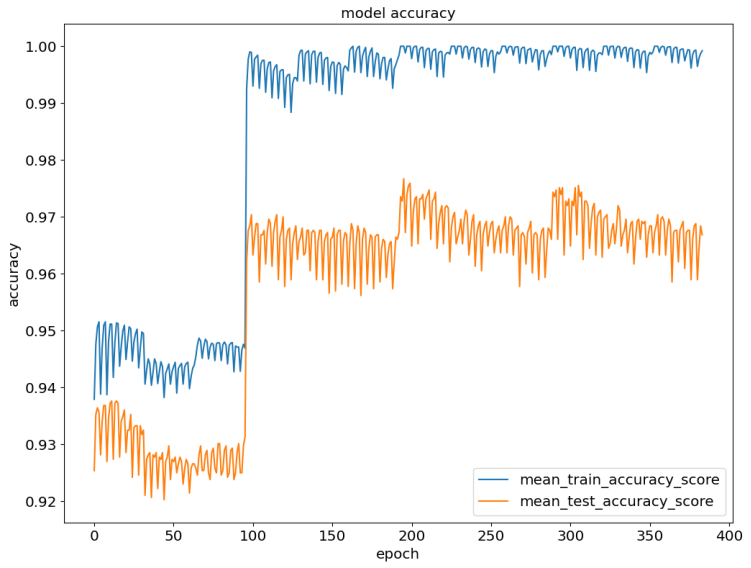
图6.准确率

图7.查全率
5.4 OOB曲线
5.4.1 实验代码
- min_estimators = 1
- max_estimators = 149
- clf = grid_search.best_estimator_
- errs = []
- for i in range(min_estimators, max_estimators + 1):
- clf.set_params(n_estimators=i)
- clf.fit(X_train, y_train)
- oob_error = 1 - clf.oob_score_
- errs.append(oob_error)
5.4.2 实验结果
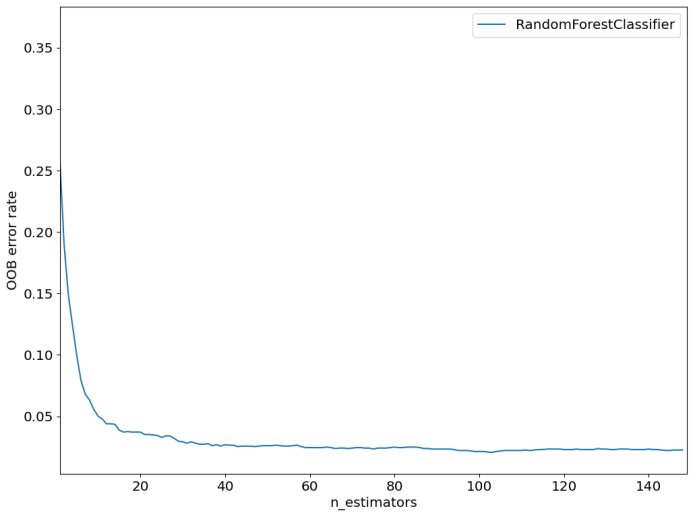
图8.OOB曲线
为了评估随机森林的模型性能,绘制其袋外误差(OOB error rate)曲线,随着评估器的增加,模型的误差逐渐下降,在超过100个评估器之后,基本达到最低值,其后下降趋势放缓,并趋于稳定。
5.5 输入特征重要性
5.5.1 实验代码
- classifier = grid_search.best_estimator_
- importances = classifier.feature_importances_
- indices = np.argsort(importances)[::-1]
- for f in range(X.shape[1]):
- print("%d.feature%d(%f)"%(f+1,indices[f],importances[indices[f]]))
5.5.2 实验结果
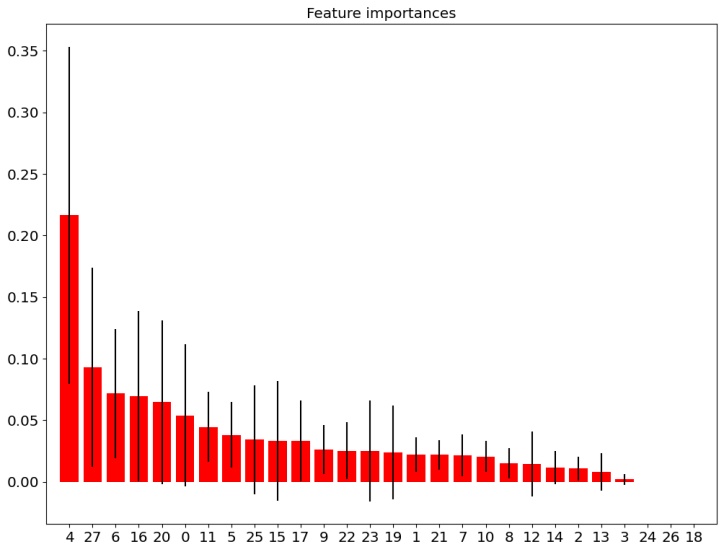
图9.特征重要性
模型的目标是找到不及格学生,即标识存在学习失败风险的学生,所以在网格搜索过程中,优化指标选择为查全率(Recall)作为参数确认依据,使得训练之后得到分类模型尽可能识别不及格学生的特征。classifier是随机森林的最优子树,其feature_importances_属性表示重要的特征列表,按列(X.shape[1])遍历输入特征,输出其特征列号及重要度的值。
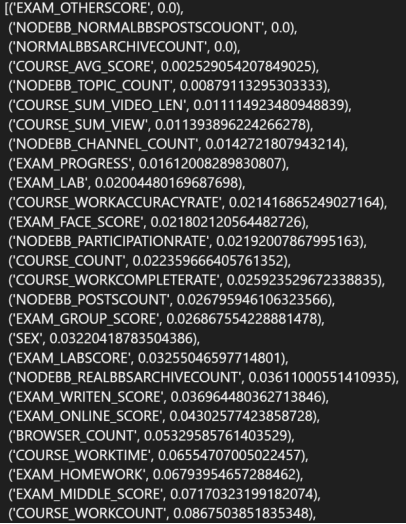
图10.特征重要性排列
可以看出最重要的特征是课程实践平均成绩,形考成绩,作业答题数、浏览次数等。
5.6 支持向量机SVM
5.6.1实验代码
- from sklearn.model_selection import GridSearchCV
- from sklearn.svm import SVC
- from sklearn.metrics import accuracy_score
- svm_model = SVC(max_iter=10000)
- param_grid = {
- 'C': [0.1, 1, 10],
- 'kernel': ['linear', 'rbf', 'poly'],
- 'gamma': ['scale', 'auto']
- }
- grid_search=GridSearchCV(svm_model,param_grid,cv=5,scoring='accuracy')
- grid_search.fit(X_train, y_train)
- print("最优的参数组合:", grid_search.best_params_)
-
- clf=sklearn.svm.SVC(C=10,gamma='scale',kernel='rbf',max_iter=10000).fit(X_train, y_train)
- y_pred = clf.predict(X_test)
- print(pd.crosstab(y_test,y_pred,rownames=['Actual'],colnames=['Predicted']))
- print("svm_accuracy_score:",accuracy_score(y_test, y_pred))
- print("svm_recall_score:",recall_score(y_test, y_pred))
- print("svm_roc_auc_score:",sklearn.metrics.roc_auc_score(y_test, y_pred))
- print("svm_f1_score:",sklearn.metrics.f1_score(y_test, y_pred))
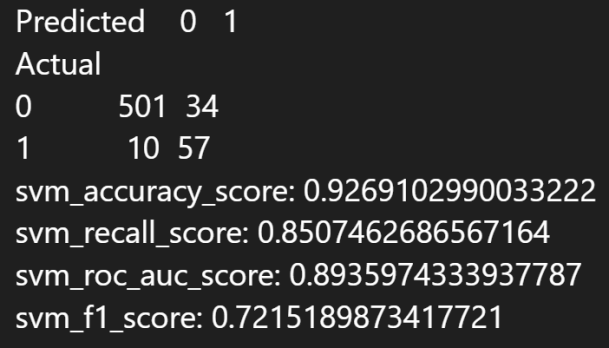
5.6.2 实验结果
最优参数:

最优参数下的混淆矩阵和性能指标:
5.7 逻辑回归Logistic Regression
5.7.1 实验代码
- from sklearn.model_selection import GridSearchCV
- from sklearn.linear_model import LogisticRegression
- model = LogisticRegression(max_iter=10000)
- param_grid = {
- 'solver': ['liblinear', 'saga'],
- 'penalty': ['l1', 'l2'],
- 'C': [0.01, 0.1, 0.5,1.0, 10.0]
- }
- grid_search=GridSearchCV(model,param_grid,cv=5,scoring='accuracy')
- grid_search.fit(X_train, y_train)
- print("最优的参数组合:", grid_search.best_params_)
-
- from sklearn import model_selection
- from sklearn.linear_model import LogisticRegression
- model=LogisticRegression(C=1.0,solver='saga',penalty='l1',max_iter=10000)
- model.fit(X_train, y_train)
- y_pred = model.predict(X_test)
- print("LogisticRegression_accuracy_score:",accuracy_score(y_test, y_pred))
- print("LogisticRegression_recall_score:",recall_score(y_test, y_pred))
- print("LogisticRegression_roc_auc_score:",sklearn.metrics.roc_auc_score(y_test, model.predict_proba(X_test)[:,1]))
- print("LogisticRegression_f1_score",sklearn.metrics.f1_score(y_test, y_pred))
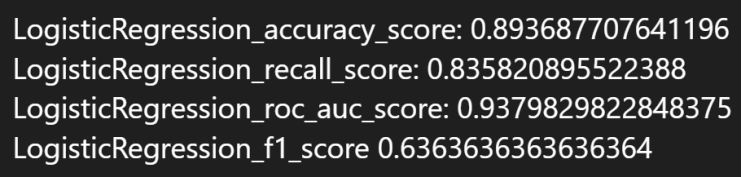
5.7.2 实验结果
最优参数:

最优参数下的性能指标:
5.8 AdaBoost
5.8.1 实验代码
- from sklearn.ensemble import AdaBoostClassifier
- from sklearn.tree import DecisionTreeClassifier
- base_classifier = DecisionTreeClassifier()
- adaboost = AdaBoostClassifier(base_classifier)
- param_grid = {
- 'n_estimators': [100, 200, 300, 400, 500],
- 'learning_rate': [0.1, 0.5, 1.0, 2.0],
- 'base_estimator__max_depth': [3, 5, 7],
- 'algorithm': ['SAMME', 'SAMME.R']
- }
- grid_search=GridSearchCV(adaboost,param_grid,cv=5,scoring='accuracy')
- grid_search.fit(X_train, y_train)
- print("最优的参数组合:", grid_search.best_params_)
-
-
- y_pred = bdt_discrete.predict(X_test)
- print("AdaBoost_accuracy_score:",accuracy_score(y_test, y_pred))
- print("AdaBoost_recall_score:",recall_score(y_test, y_pred))
- print(sklearn.metrics.roc_auc_score(y_test, y_pred))
-
- print("AdaBoost_roc_auc_score:",sklearn.metrics.roc_auc_score(y_test, bdt_discrete.predict_proba(X_test)[:,1]))
- print("AdaBoost_f1_score",sklearn.metrics.f1_score(y_test, y_pred))
5.8.2 实验结果
最优参数:
![]()
最优参数下的性能指标:
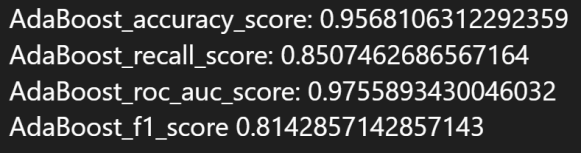
5.9 多层感知机
5.9.1 实验代码
- from sklearn.model_selection import GridSearchCV
- from sklearn.neural_network import MLPClassifier
- mlp = MLPClassifier(max_iter=10000,learning_rate_init=0.001)
- param_grid = {
- 'hidden_layer_sizes': [(100,), (50, 50), (20, 10)],
- 'activation': ['relu', 'tanh'],
- 'solver': ['adam', 'lbfgs'],
- }
- grid_search = GridSearchCV(mlp, param_grid, cv=5, scoring='accuracy')
- grid_search.fit(X_train, y_train)
- print("最优的参数组合:", grid_search.best_params_)
-
- mlp=MLPClassifier(hidden_layer_sizes=(50,50),max_iter=10000,learning_rate_init=0.001,solver='adam',activation='relu')
- mlp.fit(X_train, y_train)
- y_pred = mlp.predict(X_test)
- print("accuracy_score:",accuracy_score(y_test, y_pred))
- print("recall_score:",recall_score(y_test, y_pred))
- print("roc_auc_score:",sklearn.metrics.roc_auc_score(y_test, mlp.predict_proba(X_test)[:,1]))
- print("f1_score",sklearn.metrics.f1_score(y_test, y_pred))
5.9.2 实验结果
最优参数:
![]()
最优参数下的性能指标:

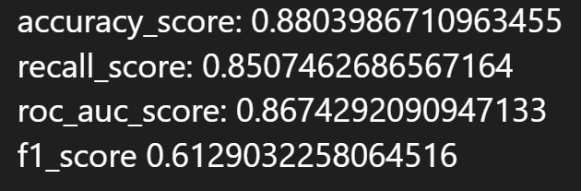
5.10 决策树
5.10.1 实验代码
- from sklearn.model_selection import GridSearchCV
- from sklearn.tree import DecisionTreeClassifier
- from sklearn.metrics import make_scorer, accuracy_score
- decision_tree = DecisionTreeClassifier()
- param_grid = {
- 'max_depth': [3, 5, 7],
- 'min_samples_split': [2, 5, 10],
- 'min_samples_leaf': [1, 2, 4]
- }
- grid_search = GridSearchCV(decision_tree, param_grid, cv=5, scoring='accuracy')
- grid_search.fit(X_train, y_train)
- print("最优的参数组合:", grid_search.best_params_)
-
- from sklearn.tree import DecisionTreeClassifier
- from sklearn.metrics import accuracy_score, recall_score, roc_auc_score, f1_score
- decision_tree=DecisionTreeClassifier(max_depth=7,min_samples_leaf=1, min_samples_split=5)
- decision_tree.fit(X_train, y_train)
- y_pred = decision_tree.predict(X_test)
- accuracy = accuracy_score(y_test, y_pred)
- print("accuracy_score:", accuracy)
- recall = recall_score(y_test, y_pred)
- print("recall_score:", recall)
- roc_auc = roc_auc_score(y_test, y_pred)
- print("roc_auc_score:", roc_auc)
- f1 = f1_score(y_test, y_pred)
- print("f1_score", f1)
5.10.2 实验结果
最优参数:

最优参数下的性能指标:
5.11 各模型性能指标对比
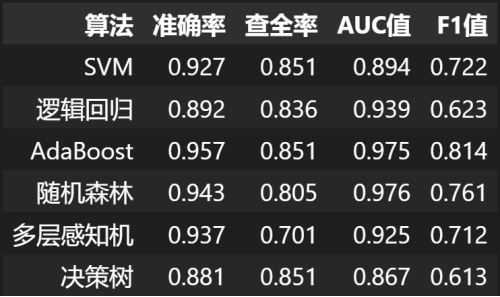
可以看出,AdaBoost算法的结果无论是准确率还是其他性能指标基本上都是最优的,随机森林算法的结果紧随其后,但是基本上所有算法的F1值都有些略低。
六.设计总结
1. 项目背景
在步入大三时,我见到很多学生被辅导员谈话,谈及其学业预警的情况。这使我意识到,若能在平时对学生行为进行分析并及时提醒,就可以避免在毕业时面临毕业预警的问题。同时,本学期学习了多种机器学习算法,激发了我探讨每种算法的优缺点,以及哪种算法在学习失败预警中能有较好的预测效果的兴趣。因此,我选择了基于分类算法的学习失败预警系统作为课题。
2. 项目目标
- 预警目标:在学期早期阶段及时识别可能面临学习失败的学生。
- 提升效率:利用机器学习技术减少人工干预,提高识别效率。
- 精准干预:为有学习困难的学生提供个性化的支持和干预,提升他们的学业表现。
3. 数据收集与预处理
- 数据来源:学生的学业成绩、出勤记录、行为数据、背景信息等。
- 数据预处理:
- 缺失值处理:使用均值填补、插值法或删除缺失数据记录。
- 数据清洗:去除明显的异常值和噪声数据。
- 特征工程:提取和构造有意义的特征,如平均成绩、出勤率、行为表现等。
- 数据标准化:将数据归一化到同一量级,确保算法的稳定性和性能。
4. 算法选择与模型训练
在本课题中,选择了以下几种常见的分类算法进行对比和分析:
- 随机森林算法:集成多棵决策树的优点,具有较强的抗噪能力。
- 支持向量机(SVM)算法:适用于高维空间的分类问题。
- 逻辑回归:简单易实现,适用于二分类问题。
- AdaBoost算法:一种提升方法,通过组合多个弱分类器来提高分类性能。
5. 模型评估与验证
- 评估指标:使用准确率、精确率、召回率、F1值等指标评估模型性能。
- 验证方法:
- 混淆矩阵:分析模型分类结果的正确与错误情况。
- ROC曲线和AUC值:评估分类器的性能和区分能力。
6. 结果与讨论
- 结果分析:经过对比分析,发现AdaBoost算法和随机森林算法在学习失败预警中的表现较好。
- AdaBoost算法:表现优秀,但对数据噪声敏感。
- 随机森林算法:稳定性好,抗噪能力强。
- 问题与挑战:在代码实现过程中,随机森林算法在测试阶段遇到了数据编码和数据类型错误的问题,需进一步优化数据处理流程。
7. 实施与应用
- 系统集成:将模型集成到教育管理系统中,实现自动化预警功能。
- 用户界面:开发友好的用户界面,方便教师和管理员使用系统进行学生监控和干预。
- 实时预警:实现实时数据更新和预警通知,提高系统响应速度和准确性。
8. 经验与教训
- 成功经验:多种分类算法的对比分析有效验证了不同算法在学习失败预警中的性能,特别是AdaBoost和随机森林算法表现优异。
- 改进空间:需优化数据预处理流程,解决数据编码和类型错误问题。同时,探索更多机器学习算法,以期找到更适合学习失败预警的模型。
- 未来工作:随着机器学习技术的发展,将继续关注新算法的应用,进一步提升预警系统的准确性和实用性。
9. 结语
通过设计和实现基于分类算法的学习失败预警系统,可以有效识别有学习困难的学生,帮助他们及时获得支持,提高整体教育质量和学生成功率。未来将进一步优化算法和系统,实现更加精准和高效的预警功能。
参考文献
[1]丁世飞 史忠植.人工智能导论.中国工息出版社,电子公工业出版社,2021(09):16-21.
[2]薛薇.Python机器学习数据建模与分析.机械工业出版社,2023.
[3]CSDN开放平台.https://blog.csdn.net. 2023.
[4]赵卫东 董亮.Python机器学习案例(第二版).清华大学出版社, 2022.
[5]赵卫东 董亮.机器学习[M].北京:人民邮电出版社,2018.
[6]周志华.机器学习[M].北京:清华大学出版社,2016.
[7]Miroslav Kubat.机器学习导论[M].王勇,仲国强,孙鑫,译.北京:机械工业出版社,2016.
- ...
赞
踩

