
热门标签
热门文章
- 1mssql 数据库审计账户_SQL Server 创建服务器和数据库级别审计
- 2linux进程间通讯指南-打通IPC大门,高效沟通无阻_linux ipc通讯的最好方式
- 3Uniapp启动编译报错问题_uniapp parsing failed at character position 14 nea
- 4hiveserver2连接数与hivemetastore连接数详解_查看hivemetastore连接数
- 5unity 用LineRender画四边形并测面积
- 6【信息安全】DES加密算法
- 7深度学习环境完整安装(Python+Pycharm+Pytorch cpu版)_深度学习环境安装
- 8大语言模型原理与工程实践:全参数微调
- 9[677]python操作SQLite数据库_python sqliteutil
- 10微软Edge浏览器搜索引擎切换全攻略_edge浏览器修改默认搜索引擎
当前位置: article > 正文
SQL Server知识点_sql server基础语法大全
作者:小舞很执着 | 2024-07-19 00:18:38
赞
踩
sql server基础语法大全
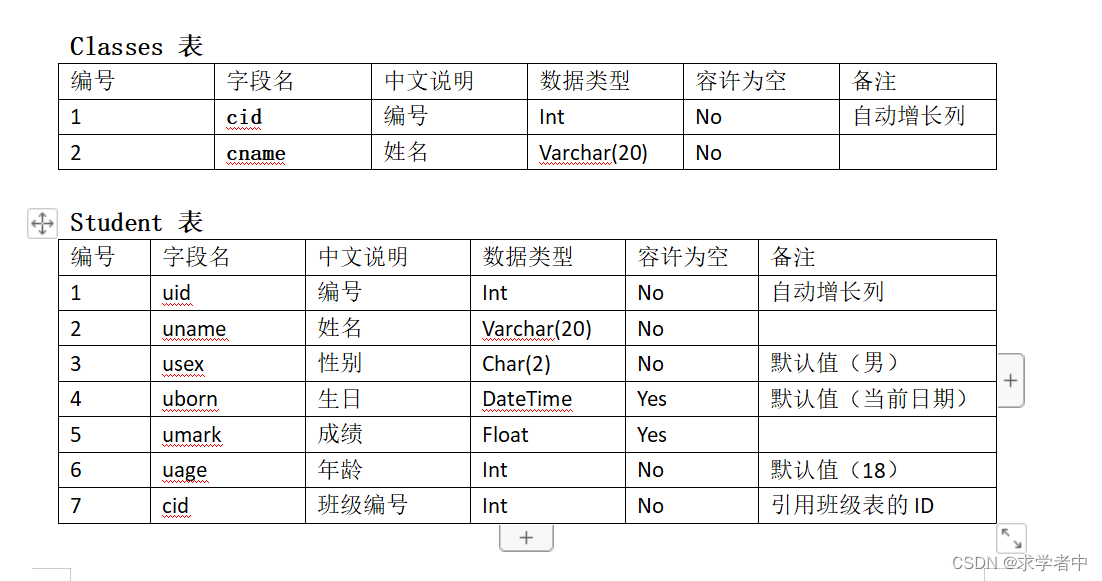
一、SQL 语句的基本语法
前言:
–选择系统数据库
use master
–创建数据库
create database 数据库名称
–删除数据库
drop database 数据库名称
–判断查询是否有 这个数据库名称,有就删除
if exists(select * from [sys].[databases] where name=‘数据库名称’)
drop database 数据库名称
create database 数据库名称
go
1、添加数据
语法:Insert Into 表名 (字段1,字段2,...)Values(值1,值2,...)
说明:值列表中的值要与字段名列表一一对应
例如:向学生表中添加一条记录
Insert into Student(uname,usex,uborn,umark,cid) values(‘tom’,’男’,’1999-9-9’,90,1)
- 1
- 2
- 3
- 4
2、修改数据
语法:Update 表名 Set 字段1=值1,字段2=值2,...[Where 条件]
说明:[...] 中的内容可以不加,不加的时候即修改当前表中所有记录,否则修改满足 Where
关键字后面条件的记录
例如:
A.给每个学生的成绩加10分
Update Student Set umark=umark+10
B.给tom加10分
Update Student Set umark=umark+10 Where uname=’tom’
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
3、删除数据
语法:1.Delete [From] 表名 [Where 条件] 2.Truncate Table 表名 3.删除数据库:Drop Database 数据库名 说明:1.[...] 中的内容可以不写,不写的时候即删除当前表中的所有记录,否则删除满足Where关键字后面条件的记录 2.使用Truncate Table 删除表格数据,不可以带条件即删除当前表中的所有记录 例如: A.删除学生表中的所有数据 Delete From Student B.只删除tom的信息 Delete From Student Where uname=’tom’ C.用Truncate Table删除学生表中的所有数据 Truncate Table Student 异同点: 1)Delete可以带Where条件,可以全删 也可以删一部分 Truncate不能带Where条件 只能全部删除 2)Delete和Truncate如果删除所有数据 Delete不会重置表中自动增长列,继续按照顺序增长 而Truncate会重置自动增长列,从新开始

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
4、查询数据
语法:Select 字段1,字段2,...From 表名 [Where 条件]
说明:如果为查询该表中的所有数据可以写成 Select * From 表名,
“*”即代表表中的所有的别名
例如:
A.查询学生表中的所有列、所有数据
Select * From Student
B.查询成绩为90分的学生的姓名和成绩
Select uname,umark From Student Where umark=90
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
5、创建数据库
语法:Create Database 数据库名
说明:创建数据库时有时需要判断是否已经有这个数据库了,所以要用一个if语句进行判断,若有就删除重建,若没有就直接创建。
并且和exists配合使用。
例如:创建一个新的数据库
If exists(select * from [sys].[databases] Where name=’数据库名’)
BEGIN
Drop database 数据库名
END
create database 数据库名
注释:在数据库中,是没有大括号的,若只有一行代码,则只需要换行空一格,若是多行代 码,那么可以使用BEGIN(开头)、END(结尾)关键字将其代码包起来
[sys].[databases]:表示系统数据库里的系统视图:数据库-系统数据库-master-视图- 系统视图(表示位置)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
6、创建表格
语法:create table 表名 ( 字段1名字 数据类型, 字段2名字 数据类型 ... ) 说明:创建一个表格前要先选择对应的数据库,数据库中的数据都保存在数据表中,一般情 况下,同种类型的数据保存在同一张表中,也就是说,一个类型的就保存在一张表里。 a.表分为实体表和关系表: 实体表:用于保存生活中实体对象,也就是实物 关系表:生活中事物之间的关系,也就是表与表之间的关系 b.表的行和列: 行:表示一个对象的信息 列:表示每个对象对应的属性 c.数据类型: Int 整数型 Varchar(长度)可变长度,无n用来保存普通的字母或数字,占用空间由储存内容决定 Char(长度) 固定长度 不管内容多少,全部用完 Nvarchar/nchar 有n用来保存中文字符串 Date 日期型 Datetime 日期时间型 Text 文本类型 Bit 比特型 0:表示false 1:表示true d.数据库完整性: 制定一些个、规则,用来保证数据的有效性,这些规则就是数据完整性 数据类型:我们给数据表添加列的时候,指定了数据类型,也就是说列只能保存指定类型的数据不符合要求的数据是无法保存的。 Primary key:主键 用来表示唯一性,通过这个主键字段,来区分数据表中的不同的行,默认不能空,不能重复,唯一的 Not null:非空 必须有数据,不允许不填数据,必须赋值 Default(值):默认值 有时候为了操作方便,我们不给字段赋值,那么系统会自动分配一个指定的数据,增长数据时可填写default,也可自己赋值 Check(判断条件):约束【and】【or】 可以给列添加检查判断条件,只有符合要求的数据才能储存 Identity(基础数,增长数):自动增长列 不需要给字段指点数据,系统自动按照顺序给他分配数据,只有整数列才可以,有自动增长的,添加数据时,一律不管,一个表里只能写一个自动增长,只有自动增长不用管。可以为空。 Unique:唯一键 References 外表名(外表主键字段):外键 Foregin key 表中某个字段的值,来自于另外一张表的某个字段,这个字段就应该设置为外键。 外键的特点: 1)外键字段的值必须来自与关联表对应字段 2)如果表某个字段的值被另为一张表中的某个字段引用,那么该值对应的记录不得删除。 主键和唯一键异同点: 相同点:都不能重复 不同点: a.主键不得为空,唯一键可以为空 b.主键的不重复和唯一键不重复的目地是不一样的,主键不重复的目地是为了区分不同数据行,唯一键不重复的目地就是为了避免数据的重复。 c.一个表只能有一个主键,但是唯一键可以有多个
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
二、SQL 中的简单查询语句
1、Top
语法:Select top 数量 * From 表名 [Where 条件]
说明:Top 关键字用来控制我们所要查询数据的行数,有时我们不需要查询表中的所有数据就可以使用Top 关键字来获取我们所需要数据的行数。
例如:查询前三个学生的所有信息
Select Top 3 * From Student
- 1
- 2
- 3
- 4
2、Like
语法:Select * From 表名 Where 字段名 like‘张%’ 说明:like关键字用于字符串比配,是模糊查询 1)与“%”配合使用: 在字符前,表示以某字符结尾 在字符后,表示以某字符开头 在字符两头,表示包含某字符 2)与“_”占位符配合使用: Like ‘ \_a%’表示第一个字符是任意字符,第二个是a Like ‘%a\_’表示倒数第一个是任意字符,倒数第二个是a 3)与“[]”配合使用: Like ‘[asd]%’表示开头asd中任选一个字符 4)与“[^ ]”配合使用: Like ‘[^asd]%’表示开头除asd任意字符 例如:查询名字以“张”字开头的所有学生 Selcet * From Student Where uname like‘张%’
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
3、Not like
语法:Select * From 表名 Where 字段名 Not like‘张%’
说明:Not like 关键字与like关键字意思相反
例如:查询名字不以“张”字开头的所有学生
Selcet * From Student Where uname Not like‘张%’
- 1
- 2
- 3
- 4
4、Or
语法:Select * From 表名 Where 字段1=值1 or 字段2=值2 (用于查询语句)
说明:or,从字面上就可以看出他所包含的意思,即“或”的意思(满足条件1或者条件2的数据),一般用于查询语句的查询条件中。
例如:查询名字为tom或者 编号为1的学生姓名
Select * From Student Where uname=’tom’or uid=1
- 1
- 2
- 3
- 4
5、And
语法与Or关键字的类似,只是为并列条件(既满足条件 1也满足条件2的数据)。
- 1
6、Between
语法:Select * From 表名 Where 字段1 [Not] Between 值1 And 值1
说明:条件包含起点和终点(即上面所查询的学生包含80和90分的),该查询语句可以使用一下语句替换:
Select * From Student Where umark >=80 And umark <=90
例如:查询成绩在80到90之间的学生信息
Select * From Student Where umark Between 80 And 90
- 1
- 2
- 3
- 4
- 5
7、In
语法:Select * From 表名 Where 字段 in (值1,值2,值3,...)
说明:In 关键字可以简化我们的查询语句、并且更容易读解,括号内的值是或者的关系, 其实我们也可以使用我们上面所学到的Or 关键字来实现这个查询语句:
Select * From Student Where uname=’tom’ Or uname=’jack’Or uname=’kite’
相比之下很明显的体现了in 关键字的优点。
例如:查询姓名为“tom”、“jack”、“kite”的学生信息
Select * From Student Where uname In (‘tom’,‘jack’,‘kite’)
- 1
- 2
- 3
- 4
- 5
- 6
8、Null
语法:Select * From 表名 Where 字段 Is Null/Is Not Null
说明:Null 即什么都没有,当该字段为字符型的时候Null并不等于 “空值”
例如:查询缺考学生的姓名
Select uname From Student Where umark Is Null
Select uname From Student Where umark=’’
- 1
- 2
- 3
- 4
- 5
9、Group by
语法:Select 字段 from 表 Where 条件 group by 字段1(字段2,字段3...)
Select 字段 from 表 group by 字段1(字段2,字段2...)having 过滤条件
说明:对哪个字段(哪几个字段)进行分组。可以根据给定数据列的每个成员对查询结果进行分组统计,最终得到一个分组汇总表。
Where 是先过滤,再分组;having 是先分组再过滤,且只能用聚合函数为条件
例如:通过编号给Student表分组
Select uid from Student group by uid
- 1
- 2
- 3
- 4
- 5
- 6
10、Order By
语法:Select * from 表名 Where 条件 Order By 字段1,字段2,...[Asc/Desc]
说明:Order By 排序,默认 Asc(从小到大排序),Desc(从大到小排列)。
如果在order by子句中指定了不止一列,排序就是嵌套的。
Select * from Student Where Order By usex,remark.
如果可以根据第一个字段完全排序,则之后的字段不会加入排序。
例如:按成绩排序
Select * From Student Where umark Is Not Null Order By umark Asc(升序);
Select * From Student Where umark Is Not Null Order By umark Desc(降序);
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
11、Having
语法:Select * from 表名 group by 字段 Having 过滤条件
说明:先通过sql语句将所有数据查询出来,再用group by 进行分组,然后把分完组的数 据用聚合函数进行统计。Having 是对分组进行条件过滤,而where是对记录进行过 滤。Where关键字无法与聚合函数一起使用,所以我们可以通过having与聚合函数 配合使用。
结构:查询语句+group by+having+聚合函数统计
常用的聚合函数:用来统计每个分组的统计信息,要与group by一起使用
Sum():求合计值
Select sum(umark) as 合计值 form Student
Count():计数
Select count(umark) as 数量 form Student
Max():求最大值
Select max(umark) as 最大值 form Student
Min():求最小值
Select min(umark) as 最小值 form Student
Avg():求平均值
Select avg(umark) as 平均值 form Student
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
12、Distinct
语法:Select distinct * from 表名
说明:用来过滤重复记录,往往只是用他来返回不重复的条数,而不是用它来返回不重复记 录的所有值。其原因是distinct 只有用二重循环来解决,而这样对于一个数据量非 常大的站来说,无疑会直接影响到效率的。注意:distinct必须放在select后面。
例如:按成绩排序并去除重复
Select distinct * From Student Where umark Is Not Null Order By umark Asc(升序);
- 1
- 2
- 3
- 4
三、SQL子查询和关联查询
1、子查询
子查询就是在一个查询语句中嵌套一个查询(也可以使用在update、Delete语句中)。就是先执行一次查询,得到的结果作为另一个查询的条件或者作为另一个查询的表,这样的查询就是子查询。子查询一般用来进行一些比较复杂的查询。 A、子查询做条件: 就是将一个查询结果,作为另外一个查询的条件,这样的子查询,就是子查询做条件。 注意: 1.子查询做条件的时候,查询结果只能有一个字段。 2.子查询结果如果不止一个,或者结果数量不确定,那么条件只能用in,不能用等于号。 实例:查询班级编号为1的所有学生信息(姓名、性别、生日、成绩、所属班级名称) 1)查询班级编号为1的信息 Select * from Classes Where cid=1; 2)将1中查询的结果作为条件 Select umane,uborn,umark,cid from Student where cid in ( Select cid from Classes Where cid=1 ); B、子查询做数据表: 将一次查询结果作为下一次查询的数据表,那么这样的查询就是子查询做表。 注意: 1.子查询做表的时候,每个字段都要有名字。 2.子查询内部的统计函数都要必须有别名,用as设置别名。 实例:查询超过20岁的女生 1)先查询超过20岁的同学 Select * from Student Where uage>20 2)将1的结果作为子表查询为女生的结果 Select * from (Select * from Student Where uage>20)a Where usex=’女’;
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
2、关联查询
在真实项目环境下,单表查询的情况不多,大部分情况下都是要多张数据表联合起来进行查询,这些多张有关系的表之间通过主外键进行关联起来的查询,就叫关联查询。关联查询与子查询具有相同的功能,可以实现跨表查询。一般比较复杂的跨表查询我们一般都会使用关联查询,同样的一个跨表查询要比子查询简单些。 语法:Select 字段列表 From a表 inner join b表 on a.字段=b.字段 Left join c表 on a.字段=c.字段 Where 条件 实例:--1、查询销售表 得到销售明细(销售编号 商品编号 商品名称 销量 单价 总价) select saleId as 销售编号, sale.ItemId as 商品编号, ItemName as 商品名称, saleNum as 销量, ItemPrice as 单价, ItemPrice*saleNum as 总价 from sale inner join Item on sale.ItemId=Item.ItemId --2、 获取商品详细信息 包括所属品牌名称 select Item.*,brandName from Item inner join brand on Item.brandId=brand.brandId 注意: (Item.*):表示这个表里的所有信息 (as):可设别名----字段 as 别名-------ItemPrice as 单价 关联查询方式: 方式一:inner join 内联查询 只显示关联上的数据,没有关联上的就不显示。 方式二:left join 左联查询 左表的数据全部显示,右边的关联上的就显示,没有关联上的就不显示。 方式三:right join 右联查询 右边表的数据全部显示,左边的关联上的就显示,没有关联上的就不显示。 关联查询不同语法之间的区别: 1.内关联只显示关联上的记录,没有关联上的不显示; 2.左关联,左表数据行全部显示,右边的关联上的就显示,没有关联上的就不显示; 3.右关联,右表数据全部显示,左表关联上的就显示,没有关联上的就不显示;
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/小舞很执着/article/detail/848444
推荐阅读
相关标签

