
热门标签
热门文章
- 1使用Sklearn中线性回归(LinearRegression)模型与决策树回归(DecisionTreeRegressor)模型解决身高预测问题_多元线性回归与决策树
- 22021阿里技术人的成长路径!
- 3Apache Iceberg简介
- 4Docker简单案例_docker 示例
- 5外网如何访问SQL Server服务_访问 sqlsrv
- 6react-native实践日记--6.ReactNative 项目版本升级,0.61到0.72升级的问题记录(二)_reactnative 0.72.0
- 7蚂蚁 JAVA 架构师面试 136 题含答案:JVM+spring+ 分布式 + 并发编程!_互联网 架构师 面试题
- 8OpenAI的ChatGPT-4和百度文心一言对比_文心一言openapi
- 9gitea mysql8_初试drone1.0+gitea—docker安装
- 10AIGC大时代背景,20美金都付了,一文看看GPT4对Apollo的认知和想法_红外热成像 百度apollo
当前位置: article > 正文
漏洞库:爬取NVD-美国国家信息安全漏洞库_bs4爬nvd漏洞
作者:小舞很执着 | 2024-07-21 14:32:24
赞
踩
bs4爬nvd漏洞
这次的目标是NVD美国国家信息安全漏洞库,爬虫框架依旧选用我钟爱的PySpider
页面分析
写爬虫的第一步就是要先分析好页面,明确如何让爬虫一步步访问到页面,如何采集到页面中的数据,以及如何存储采集到的数据。
根据pyspider框架,首先我们需要找一个first page,经过对官网的一步步摸索,找到了下面这个起始页https://nvd.nist.gov/vuln/full-listing/
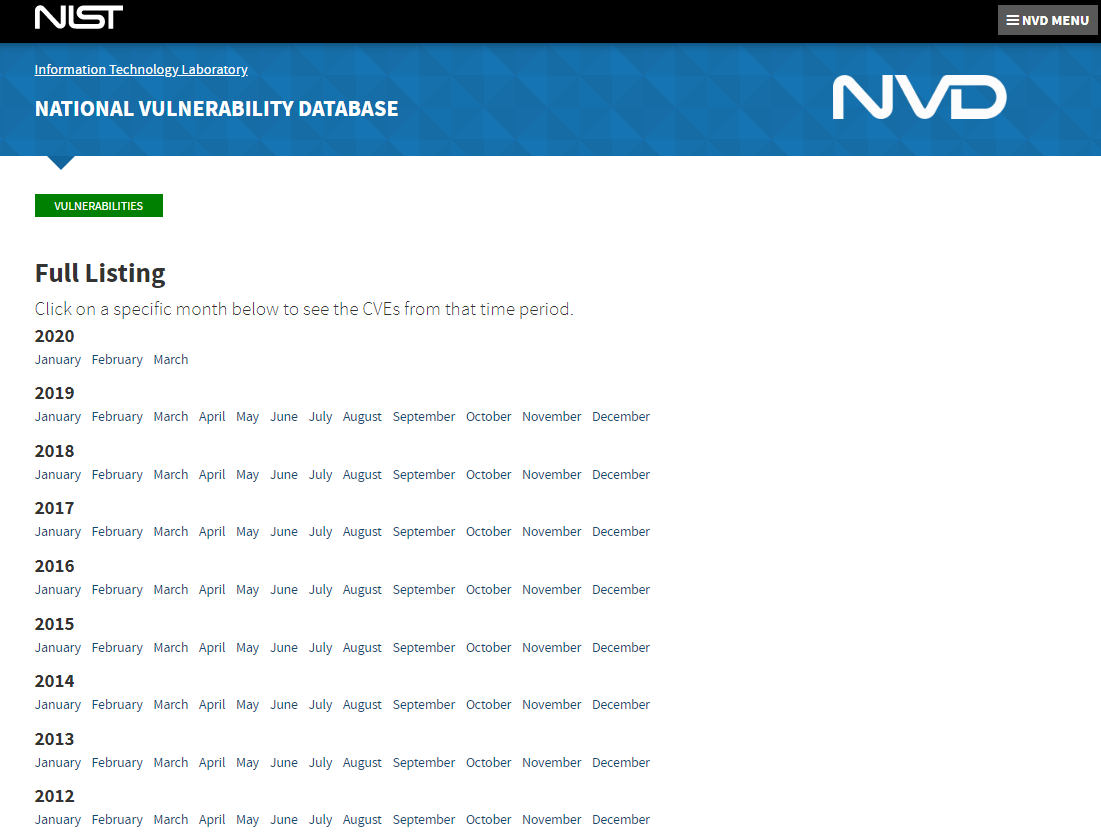
图中可见,页面是以年月来对收集的漏洞进行分类的
继续进入链接
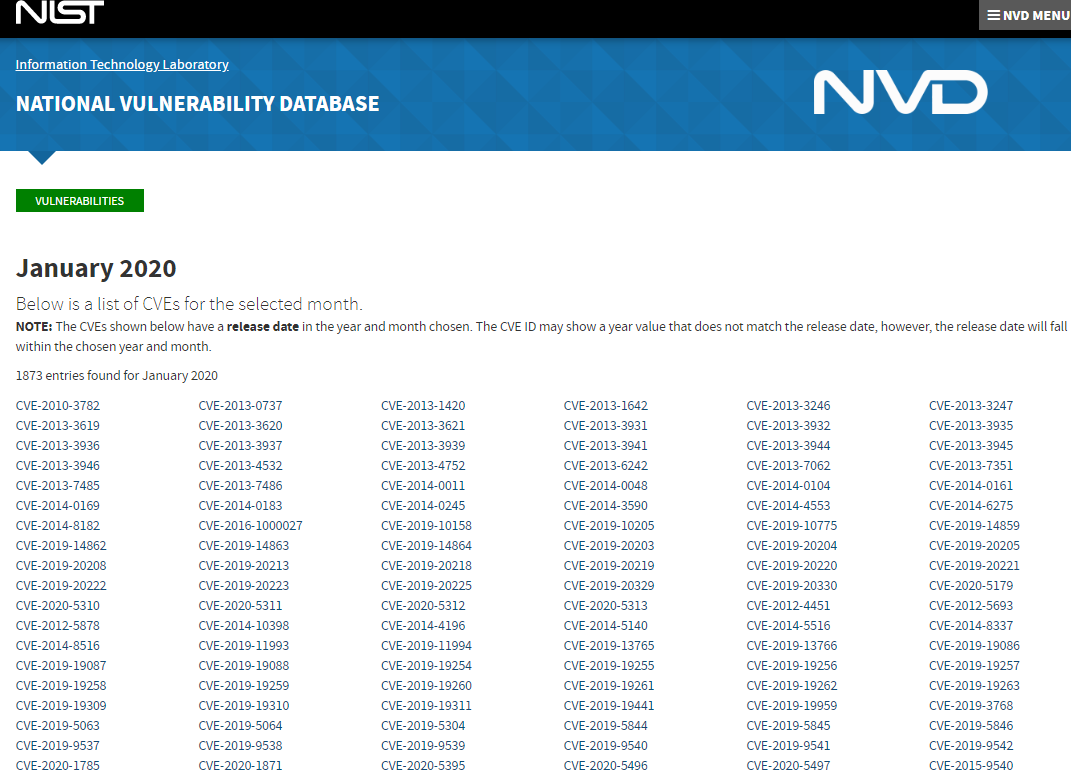
可以发现这里的漏洞链接都是CVE编号来构成的,但不是以 CVE-年份-编号这种规则来归类的了
比如 https://nvd.nist.gov/vuln/detail/CVE-2010-3782页面
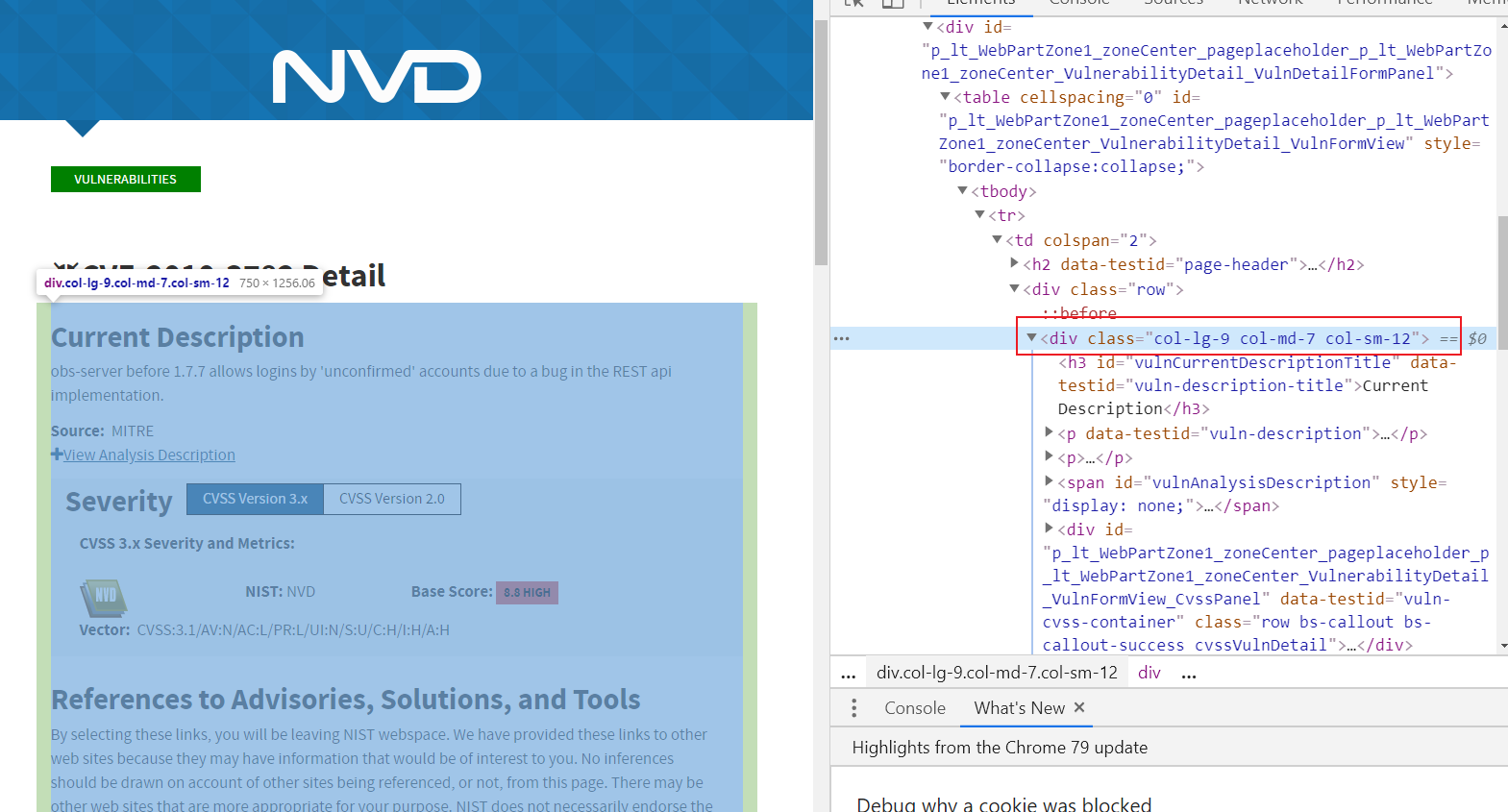 漏洞详情都在此div框架下
漏洞详情都在此div框架下
- <div class="col-lg-9 col-md-7 col-sm-12">
- ....
- </div>
所以第一步就需使用xpath来定位到这个节点的所有数据
items = response.etree.xpath('//div[@class="col-lg-9 col-md-7 col-sm-12"]')下面来获取一个很有价值的信息:CVSS 评分
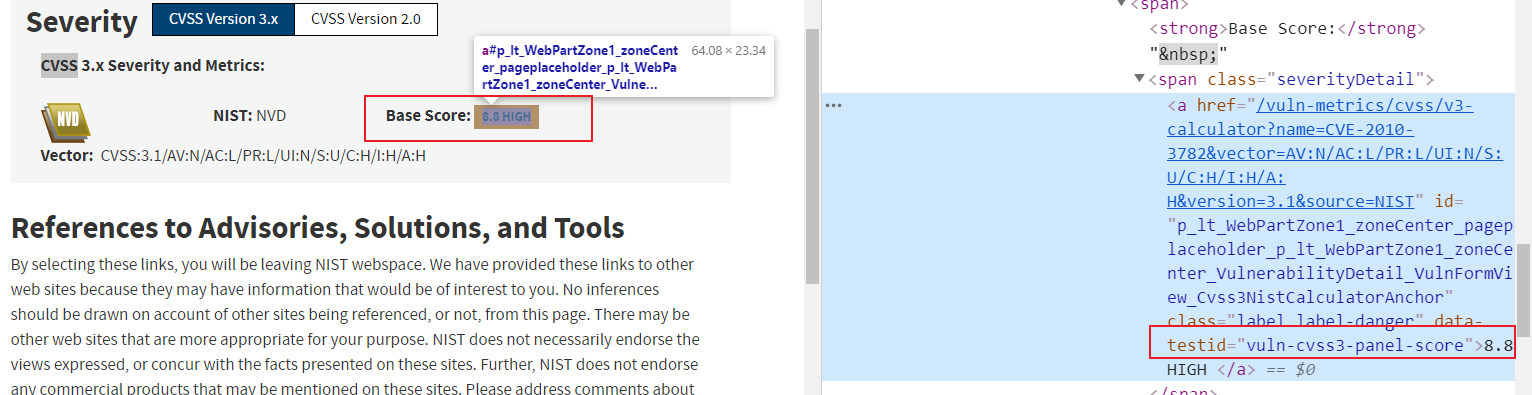
- cvss3_nvd_base_score = ''.join(item.xpath('//*[@data-testid="vuln-cvss3-panel-score"]/text()')).strip()#显式数据提取
- cvss3_nvd_vector = ''.join(item.xpath('//*[@data-testid="vuln-cvss3-nist-vector"]/text()')).strip()
需要注意的是,NVD页面提供来CVSS3和CVSS2两种评分,所以要一并采集出来
还有一个重要的信息就是:CPE
- 通用平台枚举(CPE)是一种标准化方法,用于描述和识别企业计算资产中存在的应用程序,操作系统和硬件设备的类。IT管理工具可以收集有关已安装产品的信息,使用其CPE名称识别这些产品,然后使用此标准化信息来帮助制定有关资产的完全或部分自动化决策。例如,识别XYZ Visualizer Enterprise Suite的存在可能会触发漏洞管理工具来检查系统中是否存在软件中的已知漏洞,还会触发配置管理工具以验证是否根据组织的策略安全地配置了软件。此示例说明了如何将CPE名称用作标准化信息源,以便跨工具实施和验证IT管理策略。
- 当前版本的CPE是2.3。 CPE 2.3通过基于堆栈的模型中的一组规范来定义,其中功能基于在堆栈中指定为较低的更简单、更窄定义的元素。这种设计为创新提供了机会,因为可以通过仅组合所需的元素来定义新功能,并且可以更好地划分和管理变更的影响。
- CPE 2.3堆栈图:从下到上:命名,名称匹配,(跨越名称匹配)适用性和字典。
- 内容格式:cpe:/<part>:<vendor>:<product>:<version>:<update>:<edition>:<language>

观察HTML代码可知,CPE的信息都在 <b>标签中,而且有的漏洞页面不止一条CPE信息,那么我们可以用如下xpath表达式获取信息
cpe = '\n'.join(item.xpath('//*[@data-testid="vuln-configurations-container"]//b[@data-testid]/text()')).strip()其他数据可根据分享的脚本,自行修改添加
爬取结果
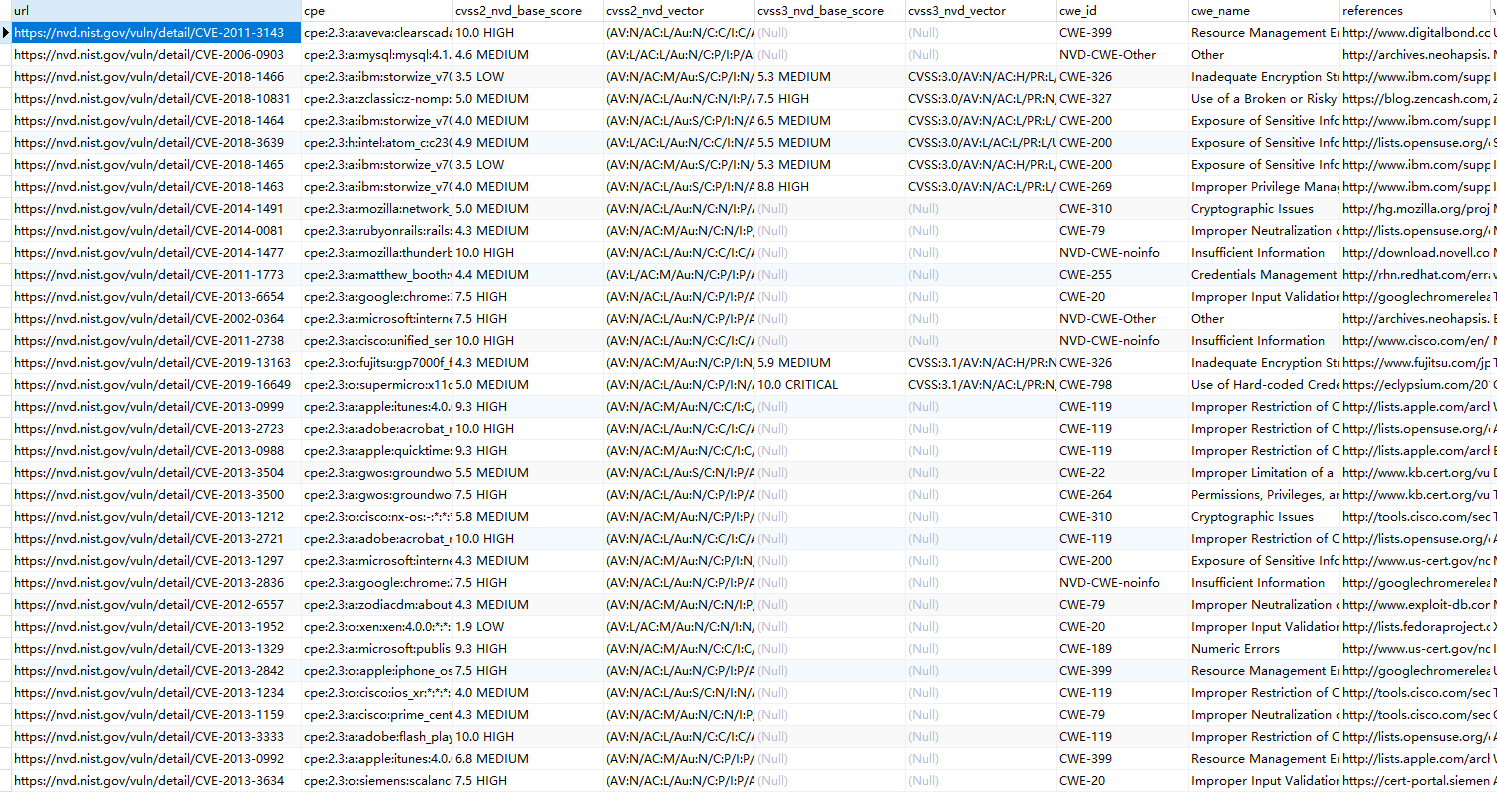
代码分享
https://github.com/hi-KK
原文链接:https://blog.csdn.net/M110K/article/details/112486321
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/小舞很执着/article/detail/861187
推荐阅读
相关标签

