
- 1【Python】已解决TypeError: unsupported operand type(s) for ...报错方案合集
- 2【C++】——【 STL简介】——【详细讲解】
- 3仅从一点就可看出,c++是最不可能被淘汰的一种计算机语言了!
- 4SRAM DRAM时序分析_sram时序
- 5关于Js的数组方法是否会修改原数据的问题_js会改变原数组吗
- 6C++实现排序算法之计数排序_计数排序 cnt[i+1] += cnt[i]
- 7Python自然语言处理 7 从文本提取信息_python自然语言处理-从文本提取信息
- 8AI大模型的就业岗位及薪资(附学习指南)_ai大模型找工作
- 9java多线程同步的四种方法_java中实现多线程的两种方法
- 10什么是迁移学习?迁移学习的场景与应用_迁移学习的应用场景
如何识破“换脸“?DeepFake 数据集:真假难辨_lav-df
赞
踩

最初,Reddit 社区出现了一系列利用深度学习技术制作的明星换脸小视频,这些视频将一位明星的脸替换成另一位明星的脸,但保留了原始视频中的面部表情和动作。这一现象引起了大量用户的关注,随之而来的是这一技术被命名为“DeepFake”。
如今,由 AI 合成的换脸视频已经不再罕见,但也伴随着各种法律和伦理问题。如果被恶意使用,DeepFake 技术可能在诸如色情制造、虚假新闻、视频语音诈骗等领域被用来误导舆论、扰乱社会秩序,甚至危害国家主权安全。因此,如何精确地检测出这些经过篡改的 DeepFake 视频和图像,仍是一个迫切需要解决的热点问题。
本文将梳理常用的 DeepFake 数据集,以协助研究人员更好地开展相关领域的工作。
LAV-DF
LAV-DF 是一个多模态(视频篡改和音频篡改)数据集,源自 VoxCeleb2 数据集,包含 136304 段视频,其中 36431 段真实视频,99873 段伪造视频。
发布时间:2022年。
-
下载地址:https://github.com/ControlNet/LAV-DF
-
论文地址:https://arxiv.org/abs/2204.06228

ForgeryNe
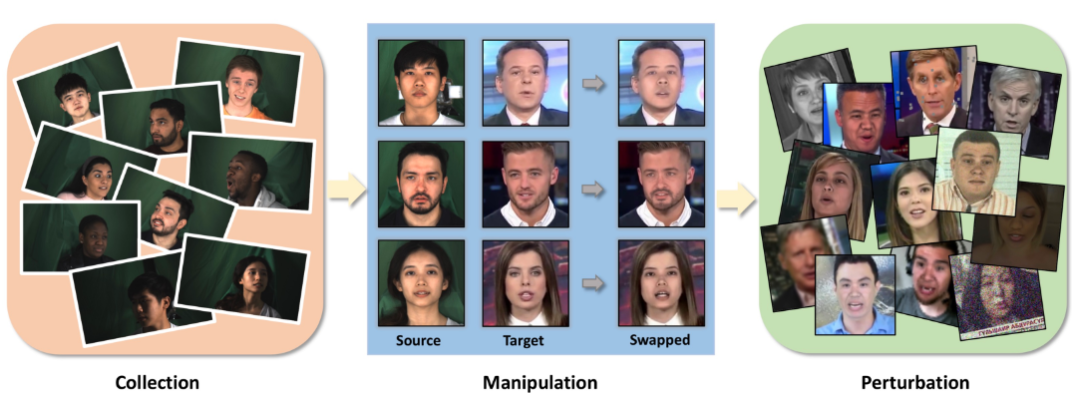
ForgeryNet 是一个大规模人脸伪造数据集,特点如下:
-
data-scale:290 万张图像、221 247 个视频
-
manipulations:7 种图像级方法,8 种视频级方法
-
perturbations:36 种独立扰动和更多混合扰动
-
annotations:630 万个分类标签、290 万个操作区域标注和 221 247 个时间伪造段标签
可用于以下四项任务:
-
图像伪造分类,包括双向(真实/伪造)、三向(真实/伪造与身份替换伪造方法/伪造与身份保留伪造方法)和 n 向(真实与 15 种伪造方法)分类。
-
空间伪造定位,与相应的真实图像相比,对伪造图像的操纵区域进行分割。
-
视频伪造分类,重新定义视频级伪造分类,并在随机位置上对帧进行处理。
-
时间伪造定位,定位哪些视频的哪些时间段是被伪造过的。
相比同期数据集,ForgeryNet 数据来源广泛、伪造方法和质量多样、标注更丰富。
发布时间:2021年。
-
下载地址:https://yinanhe.github.io/projects/forgerynet.html#download
-
论文地址:https://arxiv.org/abs/2103.05630
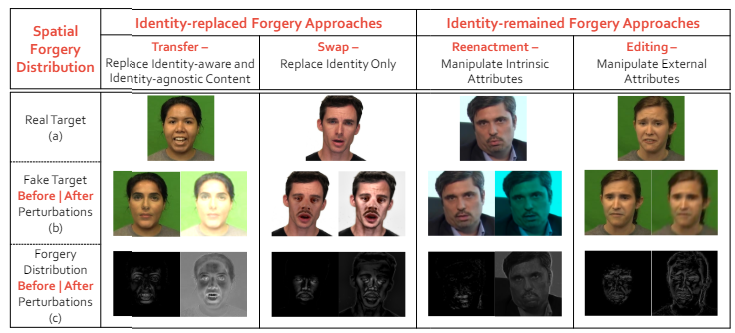
(a)真实图像, (b)伪造图像, (c)相应空间标注的示例。
OpenForensics
OpenForensics 是首个专为人脸伪造检测和分割任务创建的大规模数据集,由 115K 幅无限制图像和 334K 张人脸组成。与同期数据集相比,它包含各种背景和不同年龄、性别、姿势、位置和人脸遮挡的多人图像。所有图像都有丰富的人脸标注,支持多种任务,如伪造类别、边界框、分割掩码、伪造边界和通用人脸关键点。
-
下载地址:https://sites.google.com/view/ltnghia/research/openforensics
-
论文地址:https://arxiv.org/abs/2107.14480
发布时间:2021年。

FFIW10K
FFIW-10K 数据集是由从 Youtube 收集的 10000 个高质量伪造视频组成,每帧视频中平均有三张人脸,每个视频都包含真实人脸和伪造人脸,更加接近现实复杂场景
发布时间:2021 年。
-
下载地址:https://github.com/tfzhou/FFIW
-
论文地址:https://arxiv.org/abs/2103.16076
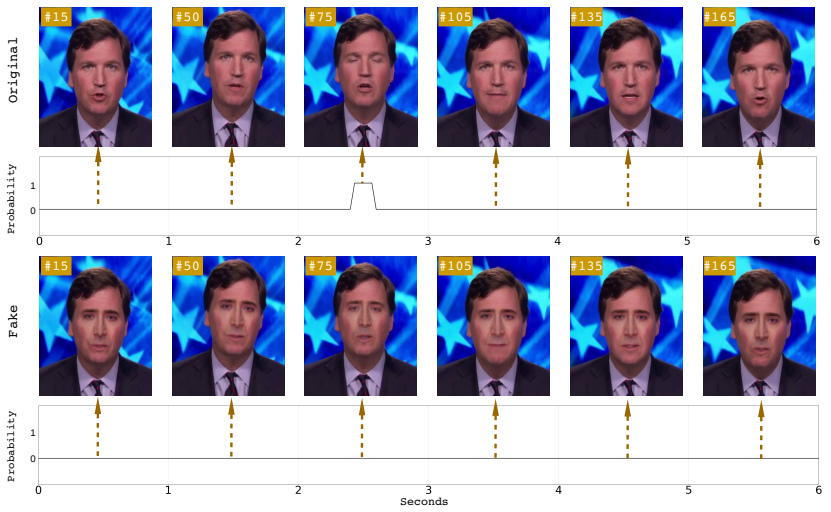
real
fake
WildDeepfake
WildDeepfake 数据集包含从互联网完全收集的 707 个 deepfake 视频中提取的 7314 个人脸序列。该数据集虽规模小,但数据集中视频场景和人物活动更加丰富,背景、光照等条件更加多元化。
发布时间:2021年。
-
下载地址:https://github.com/deepfakeinthewild/deepfake-in-the-wild
-
论文地址:https://arxiv.org/abs/2101.01456

DFDC
DFDC 是由 Meta(原名:Facebook)主办的 Deepfake 检测挑战赛(DFDC)中分享的一个大规模 Deepfake 数据集,包含来自 3426 名付费演员的 10 万多个视频片段。这些视频通过多种 Deepfake、GAN 和 non-learned 方法生成。
相比其它数据集,它的一大亮点在于,所有对象均同意数据集使用其图像或视频,并允许在数据集构建过程中对其数据进行修改。
发布时间:2020年。
-
下载地址:https://ai.meta.com/datasets/dfdc/
-
论文地址:https://arxiv.org/abs/2006.07397

DeeperForensics-1.0
DeeperForensics-1.0 数据集是由从 26 个不同国籍、20 岁到 45 岁不等的 100 名付费男女演员中收集的人脸数据组成,包含 6 万个视频,共 1760 万帧,是同期已有同类数据集的 10 倍。
为模拟现实情况,以 35 种不同的方式扭曲每个视频,从而最终数据集包含 5 万个未操纵的视频和 1 万个操纵的视频。
相比同期同类数据集,它的规模更大,质量和多样性更高,以及更加接近现实世界场景。
发布时间:2020年。
-
下载地址:https://liming-jiang.com/projects/DrF1/DrF1.html
-
论文地址:https://arxiv.org/abs/2001.03024
Celeb-DF
Celeb-DF 数据集是由纽约州立大学吕思伟教授团队与中国科学院大学齐洪钢教授团队针对 DeepFake 数据集的视觉质量问题合作提出的大规模 DeepFake 视频数据集,共包含不同名人的 5639 条 DeepFake 高质量视频。该数据集的伪造人脸质量更高、更逼真。
发布时间:2020年。
-
下载地址:https://ai.meta.com/datasets/dfdc/
-
论文地址:https://arxiv.org/pdf/1909.12962.pdf

DeepfakeTIMIT
DeepfakeTIMIT 数据集包括一组 64 x 64 大小的低质量视频和另一组 128 x 128 的高质量视频,其中包含从每个质量集的 320 个视频中提取的总共 10537 个原始图像和 34023 个虚构图像。
-
下载地址:https://www.idiap.ch/en/scientific-research/data/deepfaketimit

EEG Eye State Data Set
EEG Eye State 是一个眨眼数据集,其中所有数据均来自 Emotiv 脑电图神经头戴式耳机的一次连续脑电图测量,测量持续时间为 117 秒。
-
下载地址:https://archive.ics.uci.edu/dataset/264/eeg+eye+state
-
论文地址:https://arxiv.org/abs/1806.02877
Deepfake 的技术不断进步,质量持续提高,因此对检测方法性能的要求也应继续提升。面对这一挑战,开发者们积极采取各种措施应对,从构建大规模数据集到引入先进的深度学习技术,不断涌现各种方法以适应伪造技术的不断演变。然而,技术的升级离不开算力的支持。作为算力服务商,趋动云拥有高性能的计算资源,能够快速处理海量数据,为开发人员提供强大的支持。
❝趋动云是面向企业、科研机构和个人 AI 开发者构建的开发和推理训练服务,也是全球首个基于 GPU 算力池化云的服务。
趋动云的使命是连接算力·连接人:
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/小舞很执着/article/detail/900446
Copyright © 2003-2013 www.wpsshop.cn 版权所有,并保留所有权利。

