
大模型系统和应用——Transformer&预训练语言模型_基于transformer预训大模型
赞
踩
引言
最近在公众号中了解到了刘知远团队退出的视频课程《大模型交叉研讨课》,看了目录觉得不错,因此拜读一下。
观看地址: https://www.bilibili.com/video/BV1UG411p7zv
目录:
- 自然语言处理&大模型基础
- 神经网络基础
- Transformer&PLM
- Prompt Tuning & Delta Tuning
- 高效训练&模型压缩
- 基于大模型的文本理解与生成
- 大模型与生物医学
- 大模型与法律智能
- 大模型与脑科学
注意力机制
原理
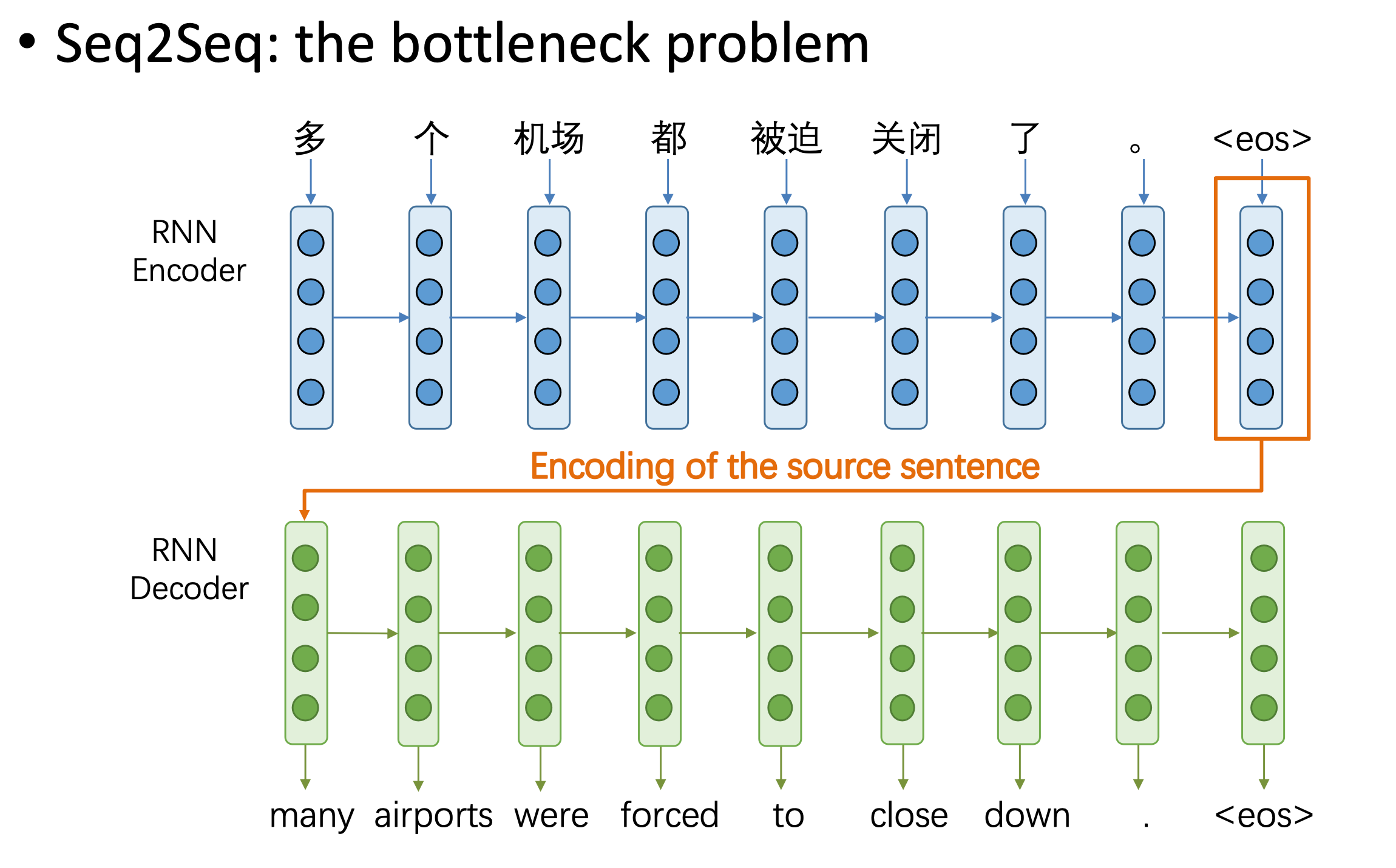
我们先看常规的seq2seq模型,该模型存在一个信息瓶颈的问题。
即解码器需要从编码器最后生成的向量中得到句子的所有信息。但由于该向量时定长的,它并不一定能表达任意长度的句子信息。
而注意力机制(Attention)就是为了解决该问题而提出的。
其核心思想是在解码器中每一步都能看到编码器中所有时间步生成的向量(隐藏状态)。这样解码器根据自己当前的状态来自动选择需要使用的信息和向量。
下面我们通过一个具体的例子来理解。
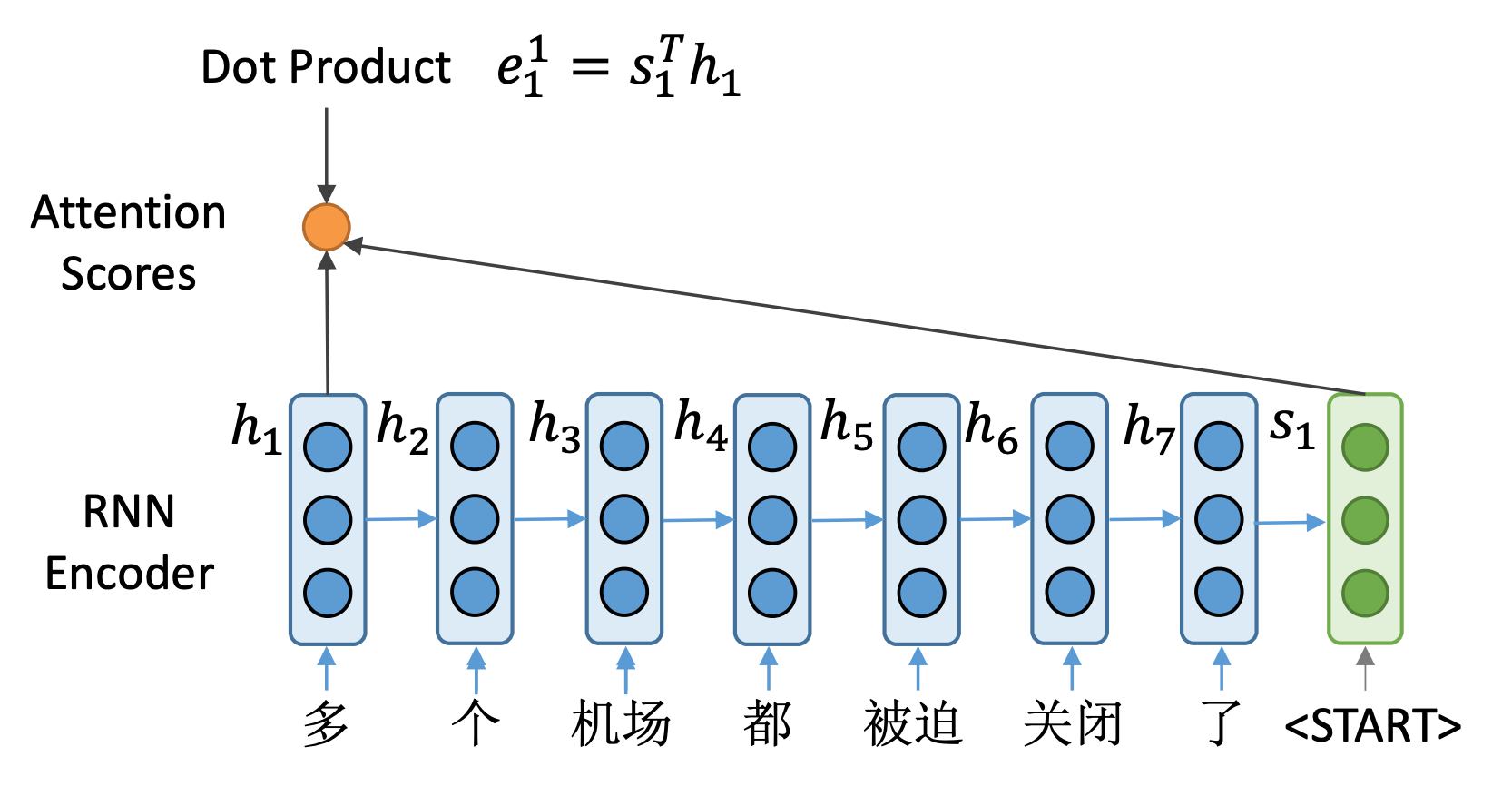
首先看到的是一个编码器, 用蓝色来表示。而解码器,用绿色来表示。
这里编码器得到了7个隐藏状态向量。这里可以看到解码器的第一个隐藏状态 s 1 s_1 s1。
与之前的不同的是,我们不是用这个 s 1 s_1
s1来计算这一步生成的单词概率,而是利用它来选关注输入句子中的哪些部分。并计算一个新的隐向量,来计算生成单词的概率。
具体地,首先计算所谓注意力分数,怎么做呢?
将 s 1 s_1 s1与编码器中所有时间步的向量进行点积,比如,第一步是与 h 1 h_1 h1进行点积,得到一个标量 e 1 1 = s 1 T h
1 e1_1=s_1Th_1 e11=s1Th1,作为分数表示。
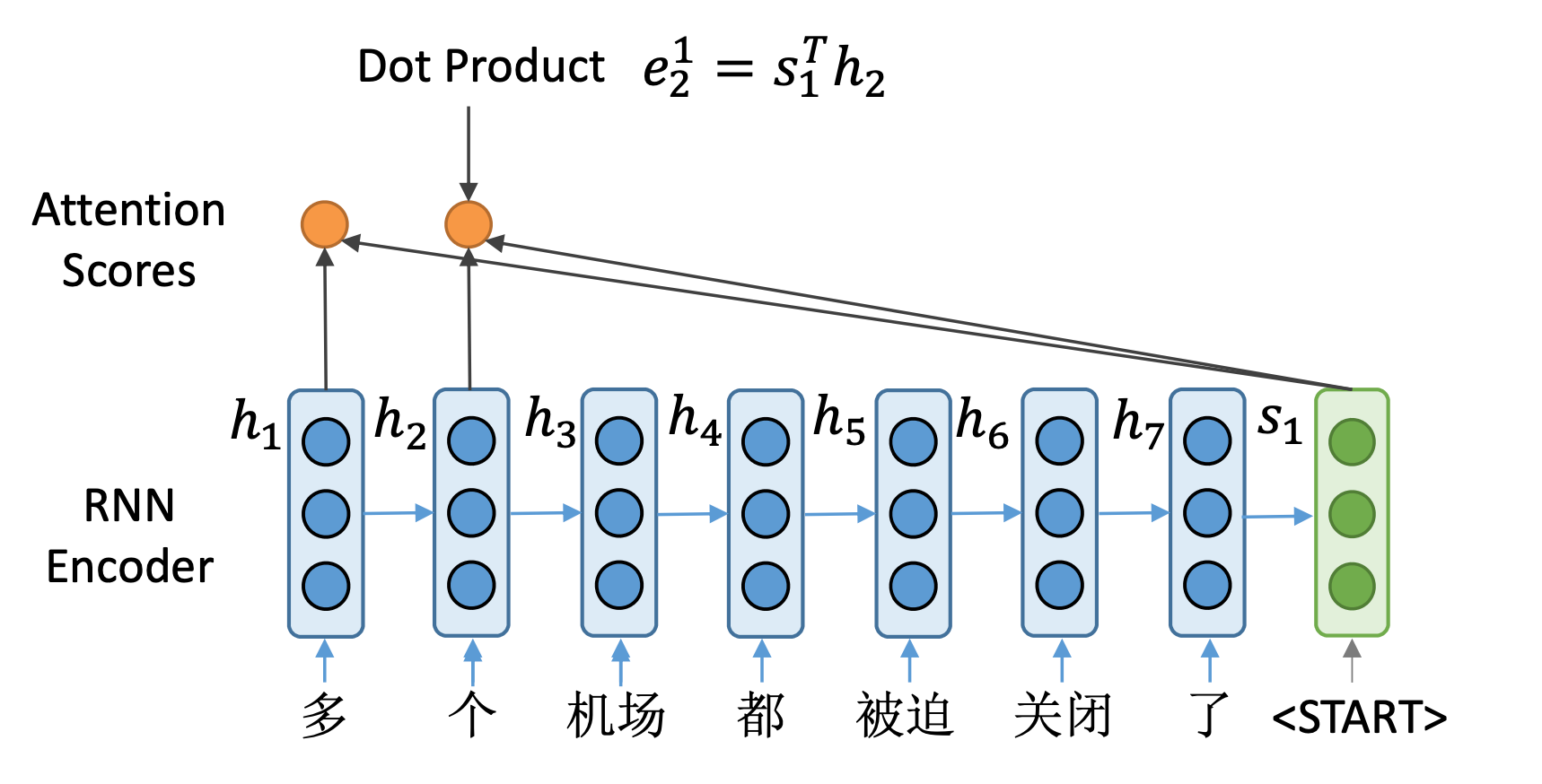
随后让 s 1 s_1 s1与编码器第二个向量进行点乘,得到 e 2 1 e^1_2 e21。可以看到, e 2 1 e^1_2
e21表示由解码器第一个时间步的向量与编码器第二个时间步的向量计算。
以此类推,我们计算编码器所有这7个隐藏状态向量的注意力得分。
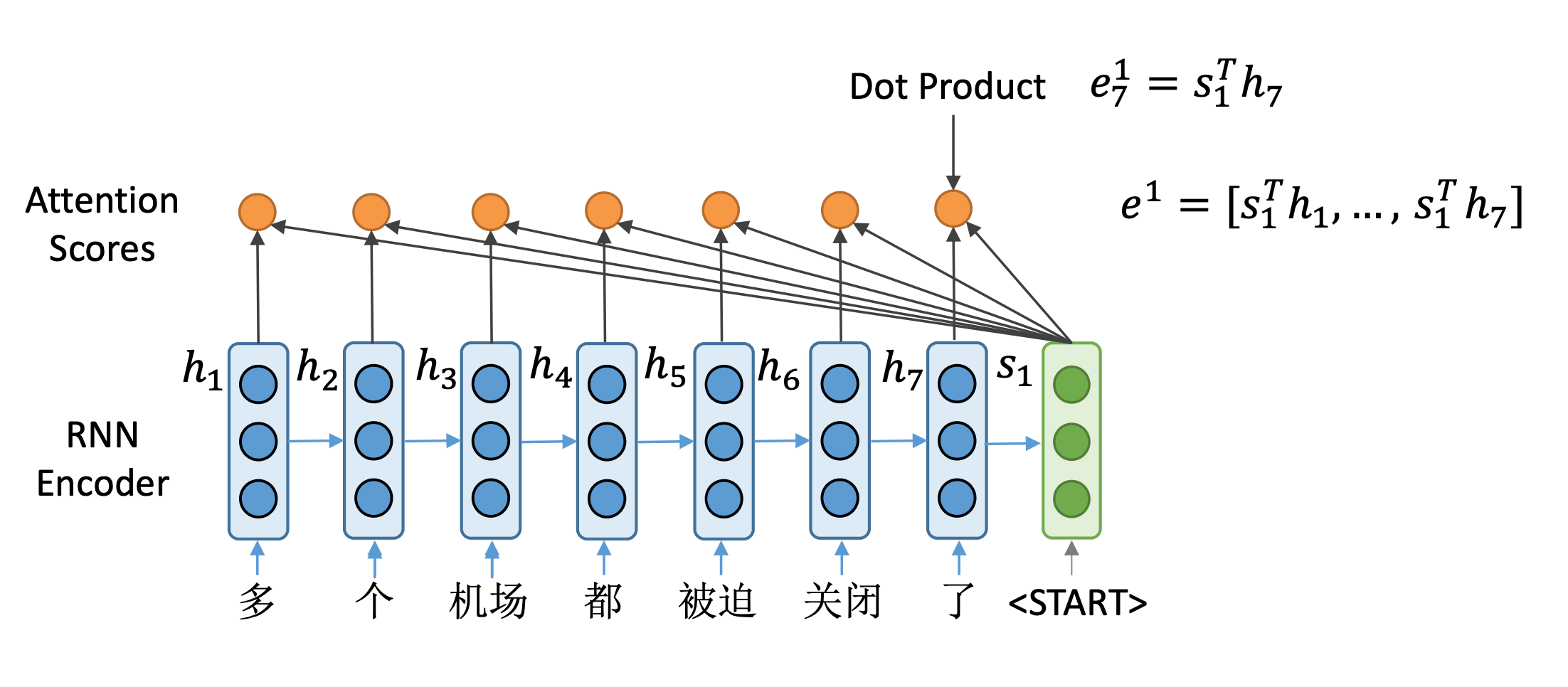
这样得到了一个长度为7的向量 e 1 e^1 e1,它就是解码器端隐藏状态向量的一个注意力分数。表示了 s 1 s_1
s1与每一个编码器端隐向量的相似程度。
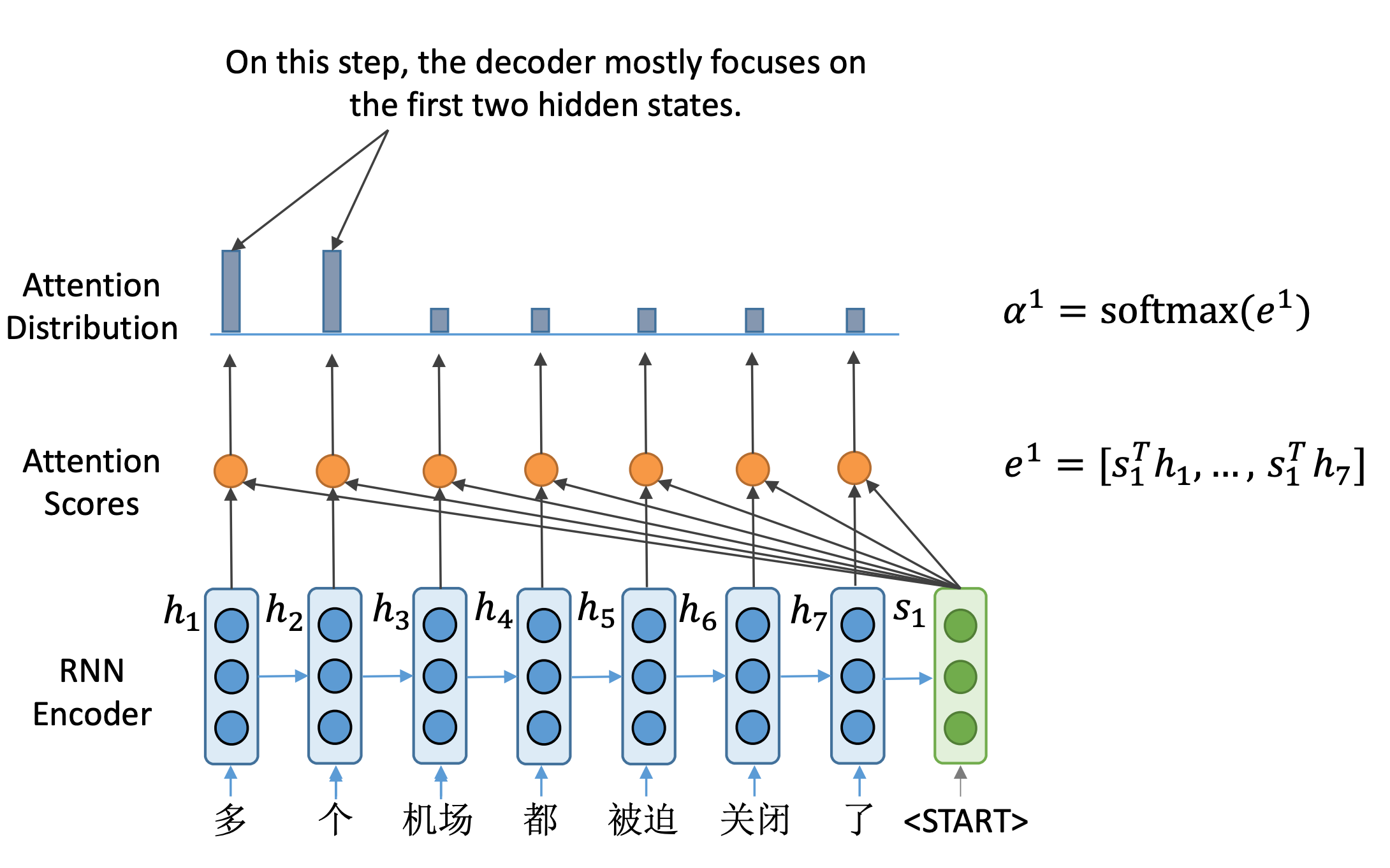
有了这样一个注意力分数之后呢,经过Softmax就可以变成一个概率分布。可以看到,在本例中前两个向量的概率值比较高,说明解码器在第一步最关心的是前两个输入。
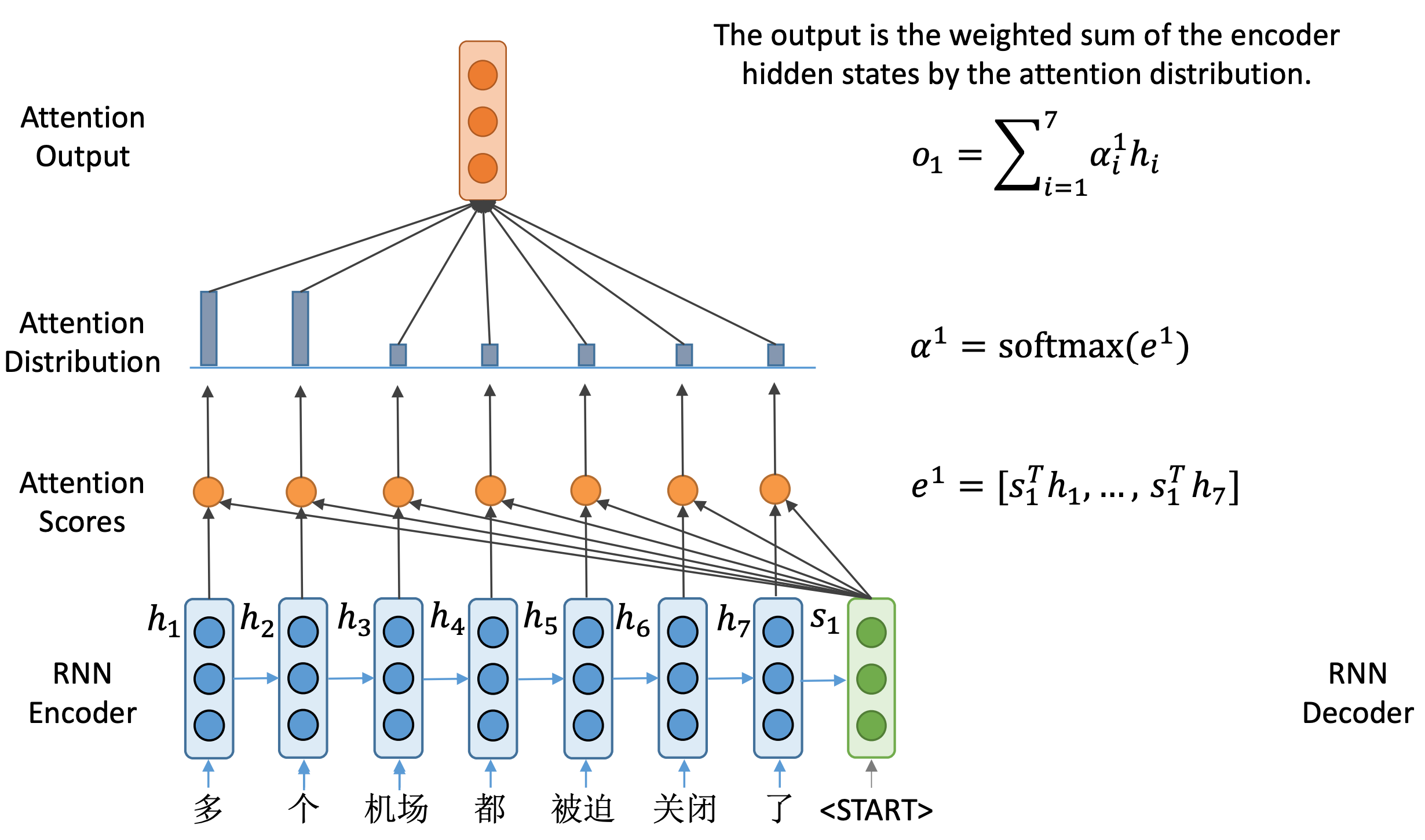
我们然后通过这样一个注意力概率分布对编码器端的隐藏状态做一个加权和,得到与隐藏状态维度相同的输出向量 o 1 o_1
o1。该向量包含了解码器当前所需要的编码器端的所有信息。
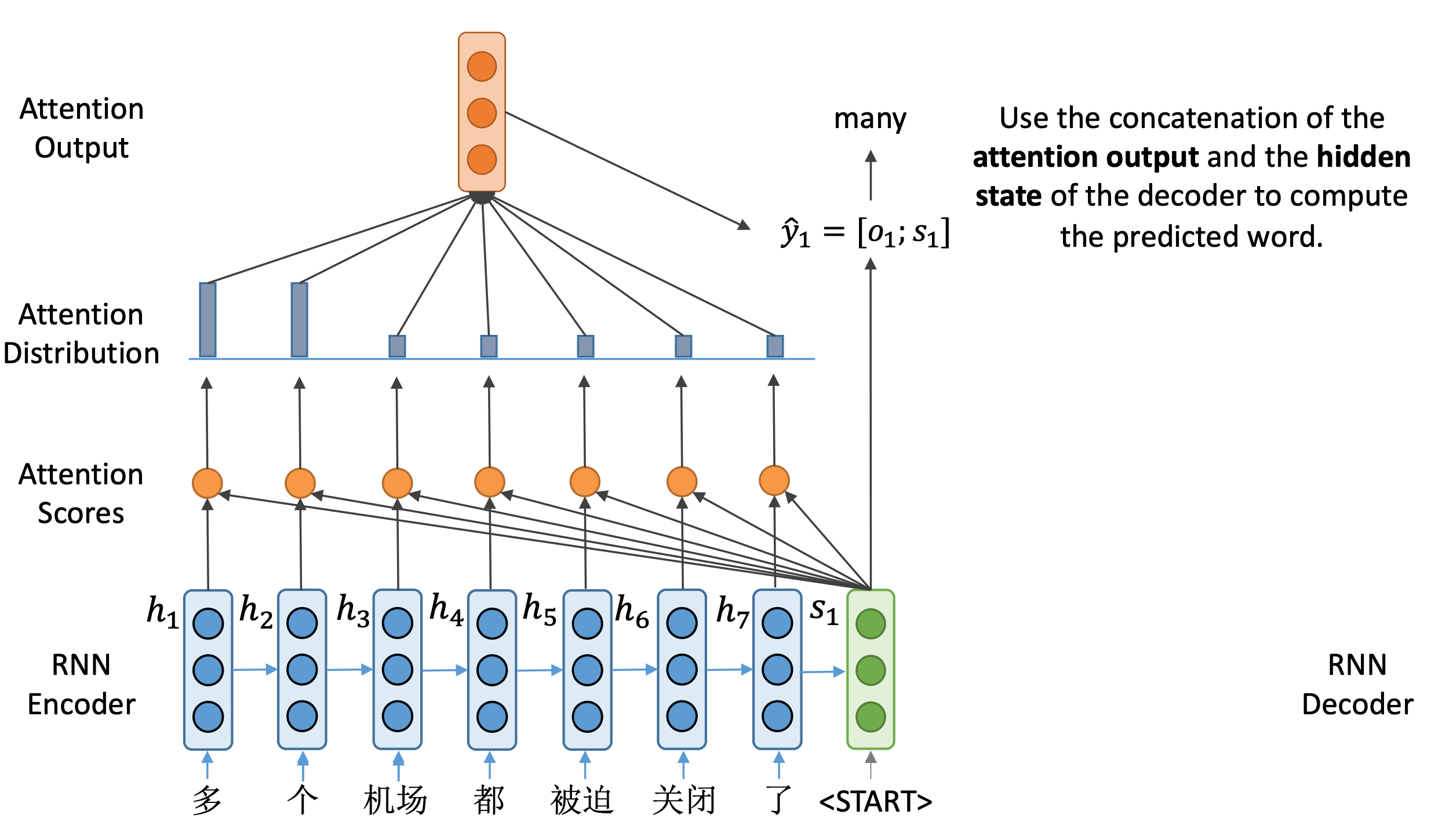
最后让 o 1 o_1 o1与解码器得到的隐藏状态进行拼接得到 y ^ 1 = [ o 1 ; s 1 ] \hat y_1 =[o_1;s_1]
y^1=[o1;s1],来计算当前时刻输出单词的概率分布。在本例中,我们得到many这样一个输出,对应输入中两个字:“多"和"个”。
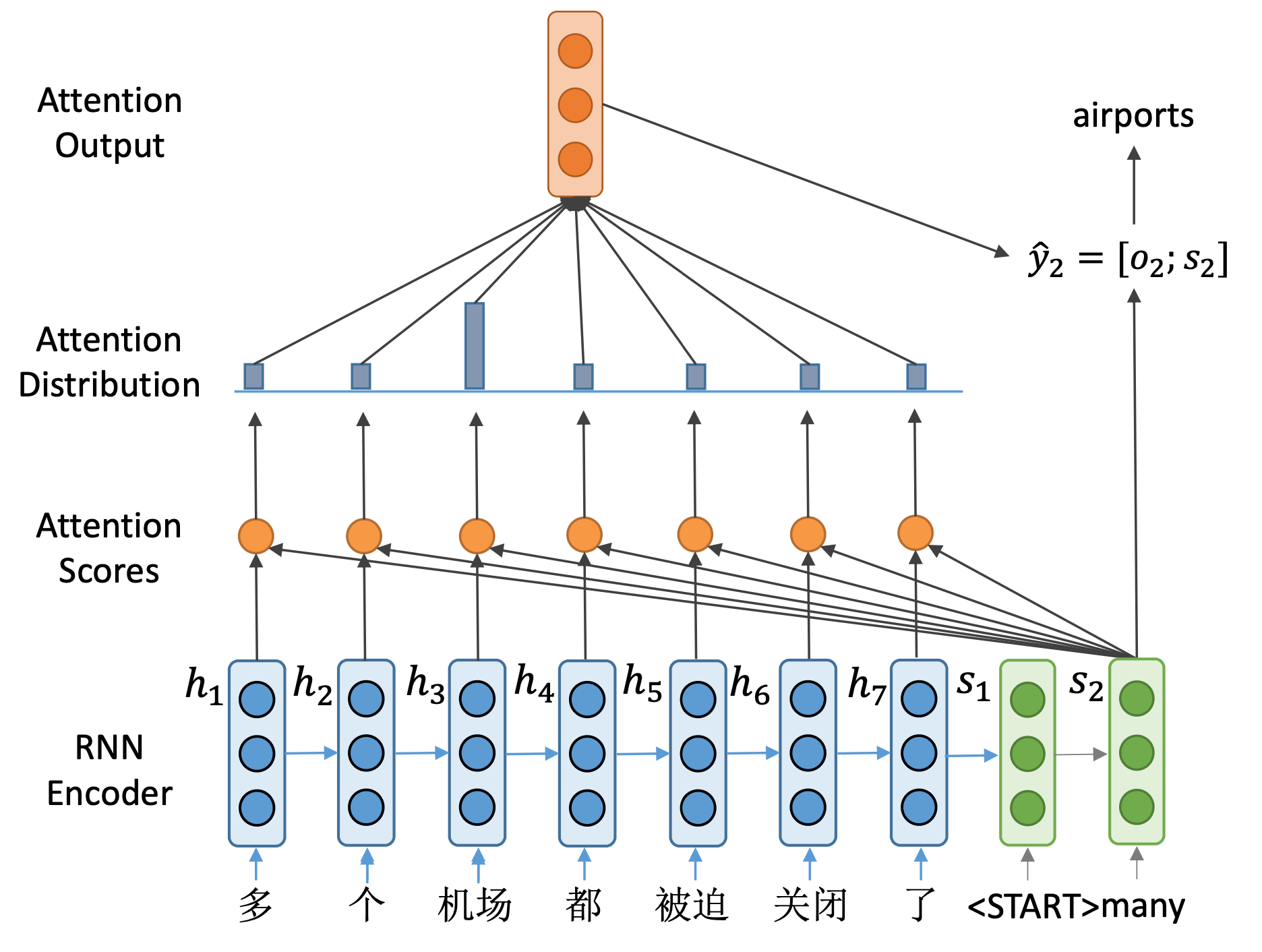
随后,将many输入到解码器,得到下一个隐藏状态 s 2 s_2 s2,通过同样的步骤,计算出 y ^ 2 \hat y_2
y^2,进行预测得到输出单词airports。
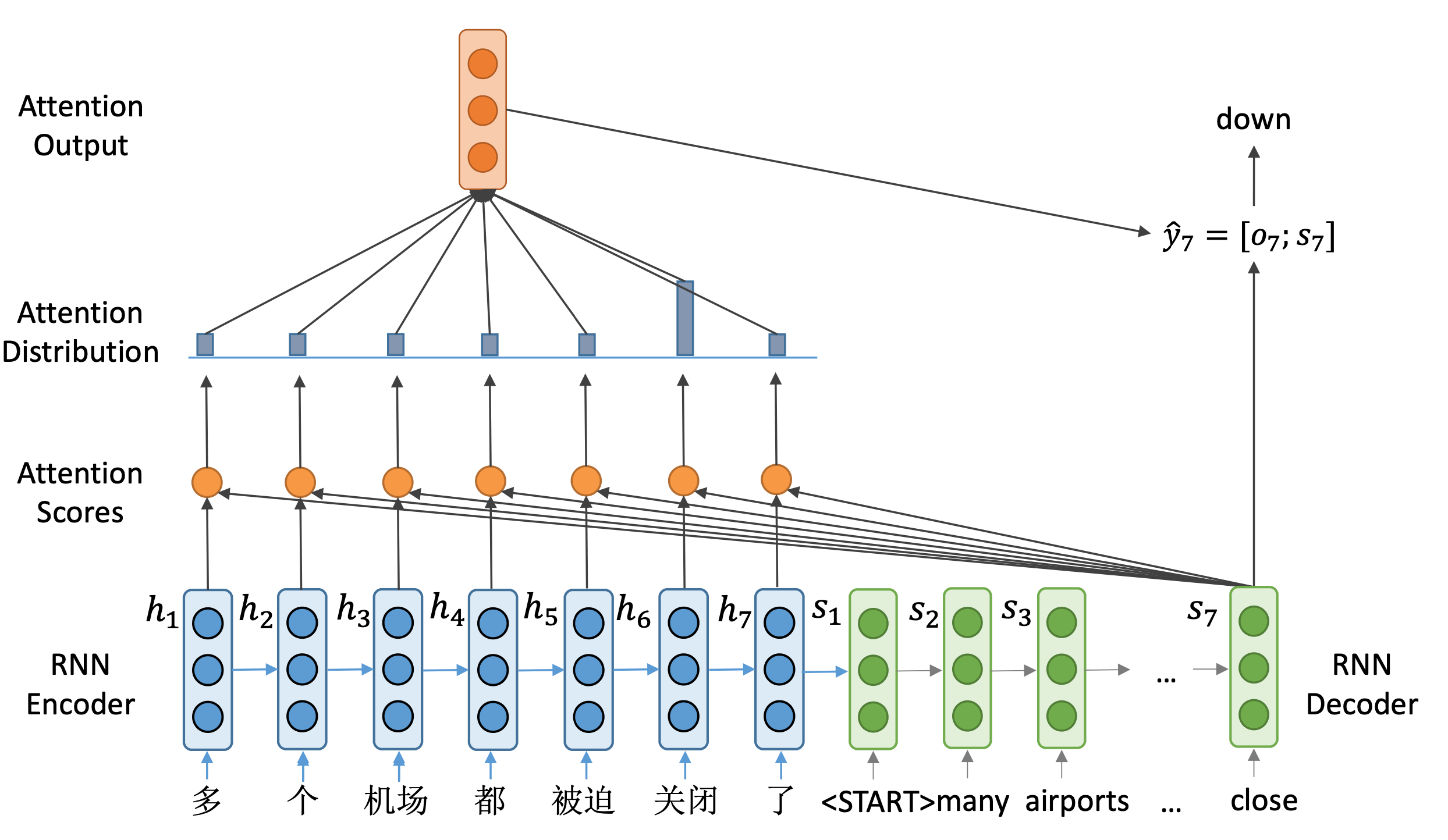
重复此过程,直到完成整个句子的翻译。
下面我们对前面提到的过程进行总结:
- 计算编码器隐藏状态 h 1 , h 2 , ⋯ , h N ∈ R h h_1,h_2,\cdots,h_N \in \Bbb R^h h1,h2,⋯,hN∈Rh
- 计算解码器每步的隐藏状态 s t ∈ R h s_t \in \Bbb R^h st∈Rh
- 计算每步的注意力分数 e t = [ s t T h 1 , ⋯ , s t T h N ] ∈ R N e^t =[sT_th_1,\cdots,s_tTh_N] \in \Bbb R^N et=[stTh1,⋯,stThN]∈RN
- 利用softmax得到注意力分布 α t = softmax ( e t ) ∈ R N \alpha^t = \text{softmax}(e^t) \in \Bbb R^N αt=softmax(et)∈RN
- 使用该注意力分布对编码器隐藏状态计算加权和作为注意力输出 o t = ∑ i = 1 N α i t h i ∈ R h o_t = \sum_{i=1}^N \alpha_i^t h_i \in \Bbb R^h ot=∑i=1Nαithi∈Rh
- 拼接注意力输出和解码器隐藏状态 [ o t ; s t ] ∈ R 2 h [o_t;s_t] \in \Bbb R^{2h} [ot;st]∈R2h来进行预测
我们可以对前面计算注意力的过程给出一个更加抽象的定义。
给定一个query向量和一系列的value向量,分别对应解码器端的隐向量和编码器端的隐向量,那么注意力机制就是根据query向量对value向量进行加权和。
因此,我们可以发现——注意力机制的本质就是value向量的加权和。同时,value向量长度是非固定的。最终我们可以通过注意力机制获取综合了所有value向量的定长的向量表示。
变体
注意力机制的计算有几种常见的变体。基本的就是上面介绍的点积
e i = s T h i ∈ R e_i = s^Th_i \in \Bbb R ei=sThi∈R
这是基于编码器和解码器隐藏状态向量的维度是一致的情况。我们分别用 d 1 d_1 d1和 d 2 d_2 d2表示。
如果这两个向量维度不一致,那么就需要在中间加上一个权重矩阵。
e i = s T W h i ∈ R , W ∈ R d 2 × d 1 e_i = s^TWh_i \in \Bbb R,\quad W \in
\Bbb R^{d_2 \times d_1} ei=sTWhi∈R,W∈Rd2×d1
第二种变体比较复杂,它使用了单层的神经网络将两个向量变成一个标量。
e i = v T tanh ( W 1 h i + W 2 s ) ∈ R e_i = v^T \tanh (W_1 h_i + W_2 s)
\in \Bbb R ei=vTtanh(W1hi+W2s)∈R
其中 W 1 ∈ R d 3 × d 1 , W 2 ∈ R d 3 × d 2 W_1 \in \Bbb R^{d_3 \times d_1}, W_2
\in \Bbb R^{d_3 \times d_2} W1∈Rd3×d1,W2∈Rd3×d2是权重矩阵,还有一个 v ∈ R d 3 v
\in \Bbb R^{d_3} v∈Rd3是一个权重向量。
特点
我们来看下注意力机制给这样的seq2seq模型带来了什么变化。
首先,解码器在每步都可以看到编码器端所有位置的信息,解决了信息瓶颈问题。
其次,通过在编码器和解码器之间提供了一种直接连接的方式,防止了梯度在RNN中传播过长导致的梯度消失问题。
最后,提供了一点的可解释性,我们可以看到每个时间步解码器注意了哪些输入,同时允许学习到语义上的对齐关系。
Transformer
概述
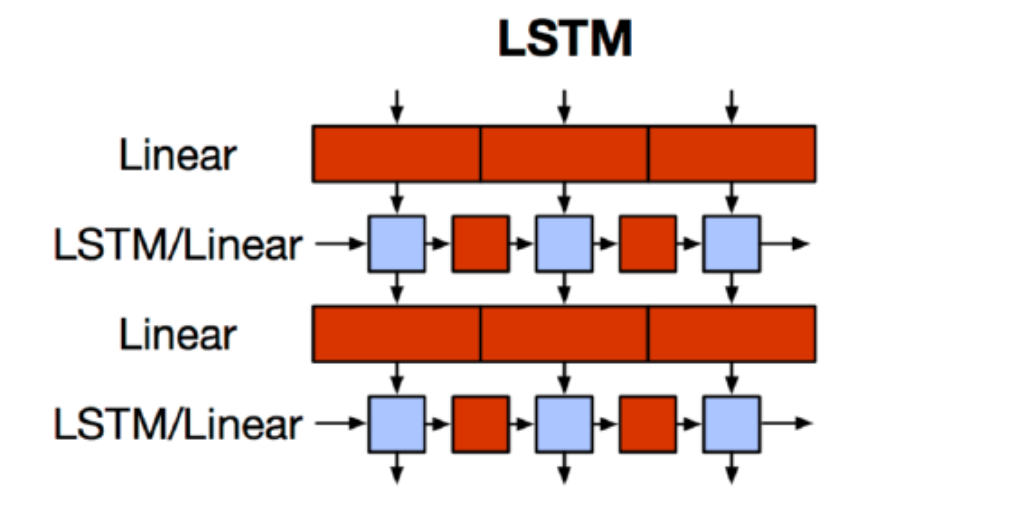
这是一个典型的双层LSTM模型,它最大的缺点是必须要顺序地执行,即不能并行化。
基于这个缺点,我们是否可以完全抛弃RNN结构来完成文本的一些任务。答案是肯定的,Attention is all you need。
答案就是Transformer。
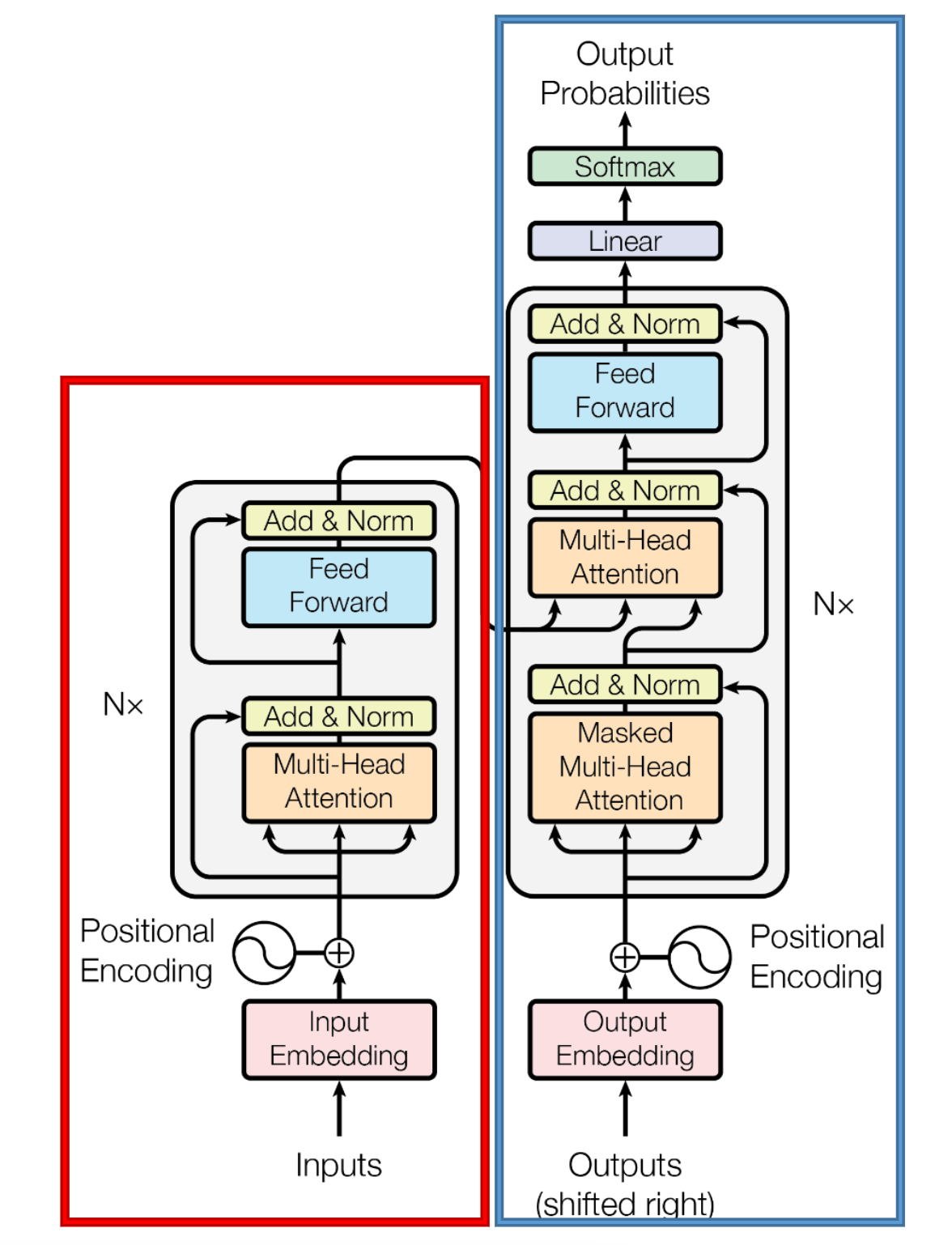
可以看到它也是一种编码器-解码器架构,上图红色框框出了编码器,蓝色框出了解码器。
我们来简单看下其中所有的构件。
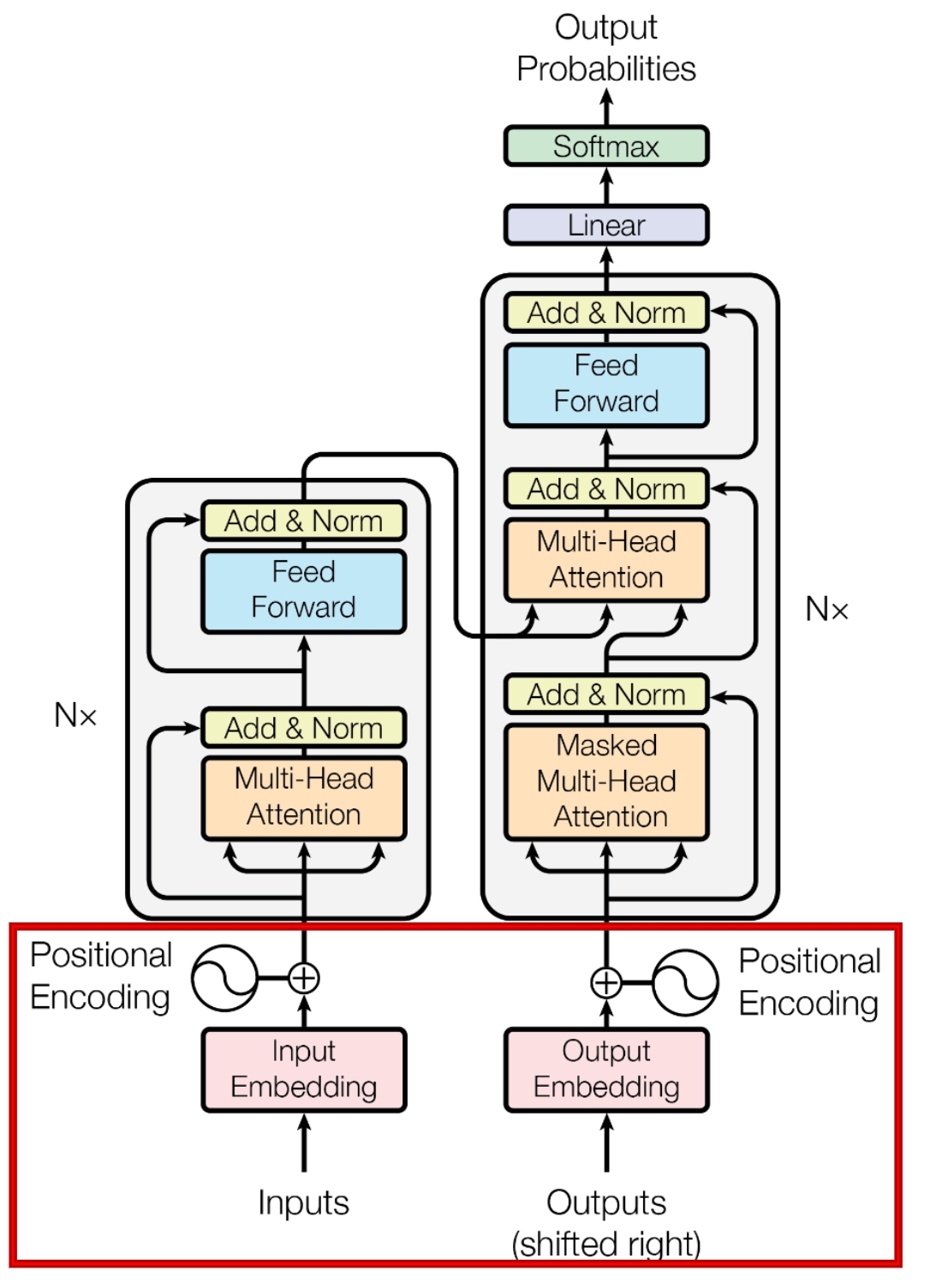
首先是输入层(Input Layer),和RNN中一样,我们需要将文本序列进行词元化(分词)为不同的token,然后通过Input
Embedding得到词向量表示。同时加上了位置编码来表示位置信息。
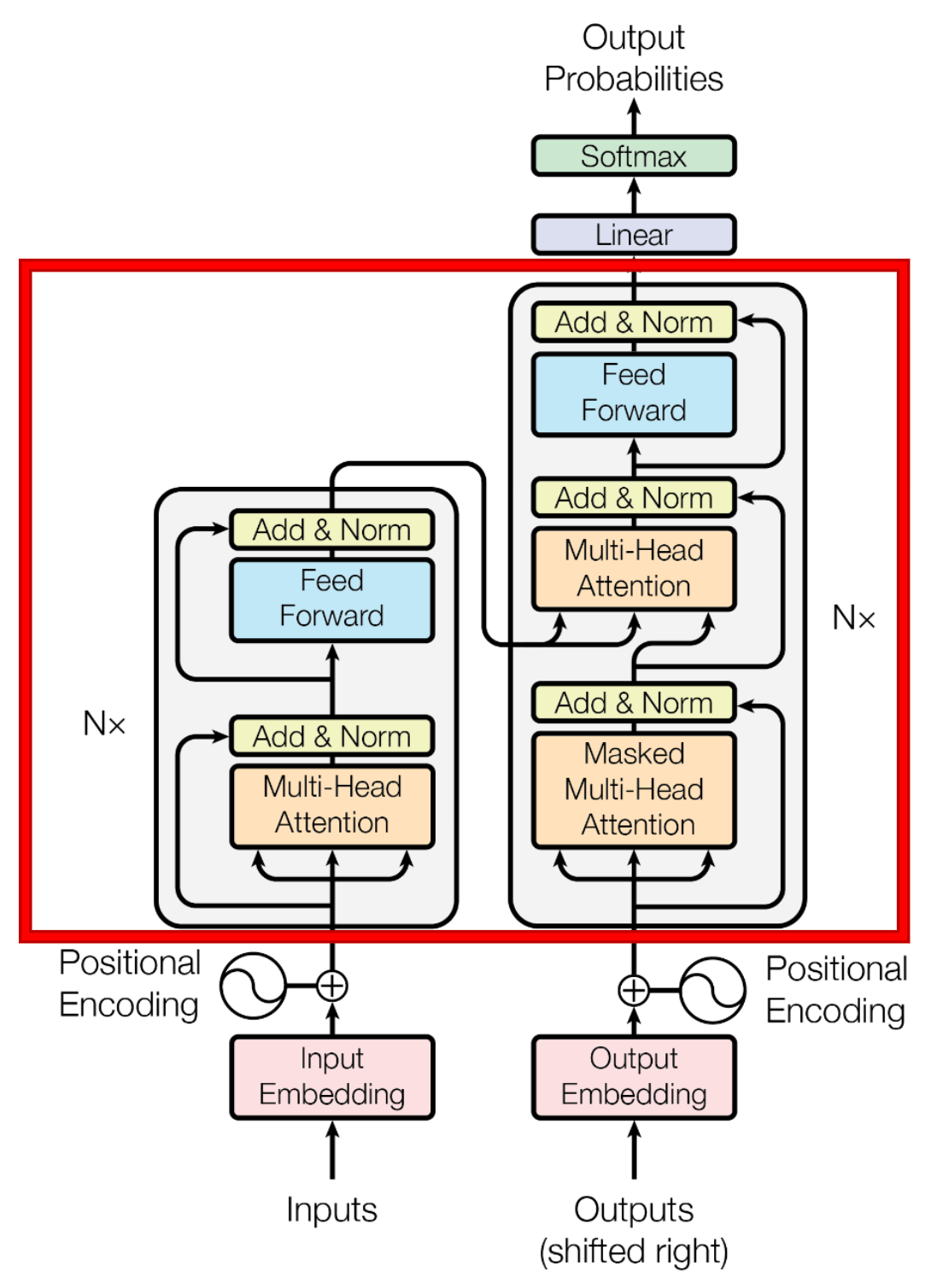
接下来就是Transformer的核心部分,它是由多个Encoder/Decoder block堆叠而成,
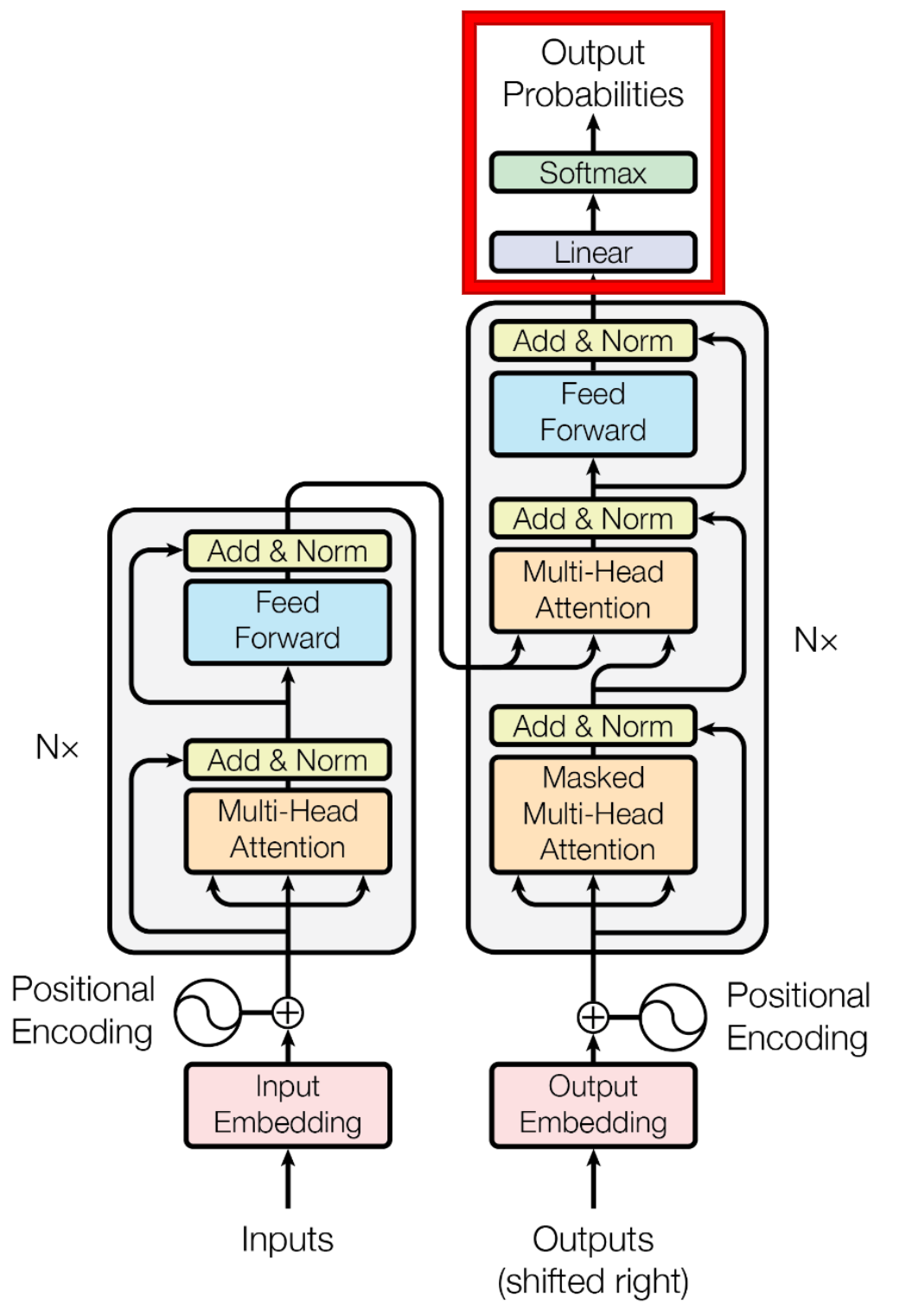
最后介绍的输出层,就是一个线性变换和一个Softmax转换为概率分布。
下面来详细介绍。
BPE
在输入层中进行分词时使用的技术是BPE(字节对编码)。
BPE是一种分词算法,对于英文来说,它首先将语料库中所有的单词按字母切分,随后它统计语料库这些字母组成的bi-gram出现的数量,然后逐步把频度最高的bi-
gram抽象为一个词加入词表中。
举个例子,假设在文本中单词和对应出现的次数:
- low : 5
- lower : 2
- newest : 6
- wildest : 3
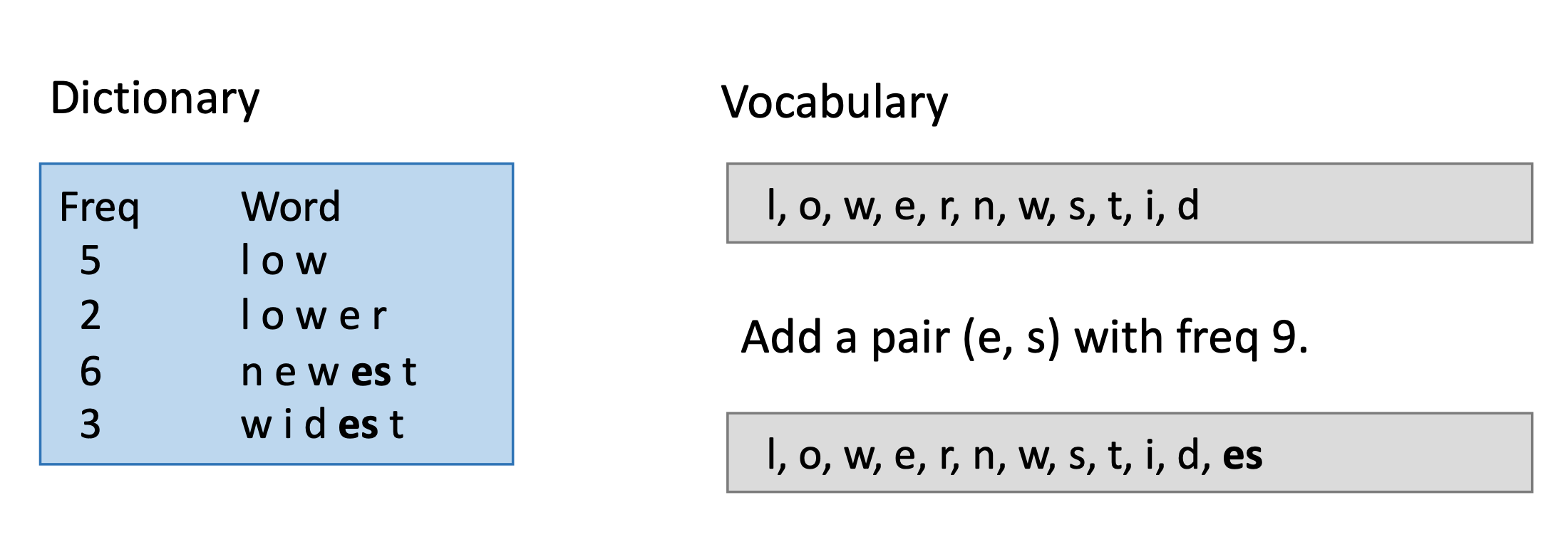
最开始的词表为这4个单词所有的字母组成。
然后统计所有单词内字母bi-
gram组合出现的次数。这样我们可以计算出现频率最高的是es这样的组合。分别为6次出现在newest中,3次出现在widest中。
这样,我们把es拼接为新的单词加入到词表中,同时标记它的频次为9。因为s不再单独出现,所以我们也将其从词表中去除。
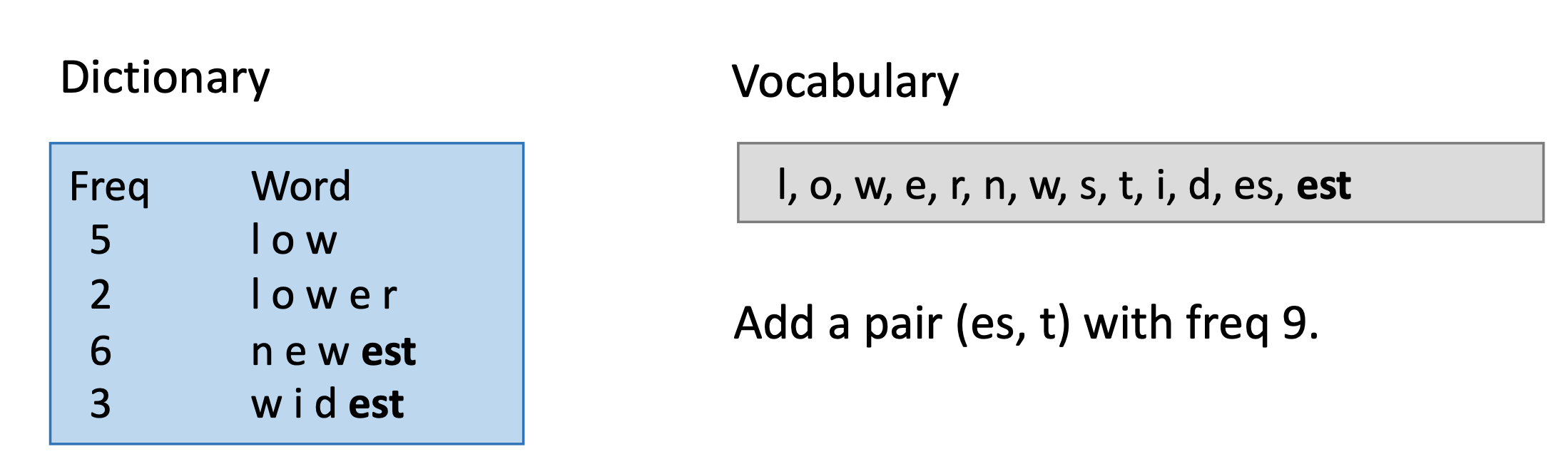
随后,按照新的词表再次组合bi-gram,统计出现频次最高的组合为est。
将est加入到词表中,同时es不再单独出现,也将它从词表中去除。
不断重复此过程,直到词表中单词数量达到预设的值。
BPE主要用来解决未登陆词问题(Out of vocabulary,OOV)。它通过将文本序列变成一个个子词(sub word)的更小的单元。
比如在上面的例子中,如果出现了新的单词lowest,那么就可以被切分为low和est两个子词。
而在传统的基于空格分词技术中,若该单词没有出现在词表中,那么会被替换为<UNK>,从而失去了意义。
位置编码
由于Transformer没有使用类似RNN那种顺序地读取输入的方式,而是一次并行处理所有的输入,因此它没有位置信息。为了增加位置信息到输入中,我们需要利用位置编码。
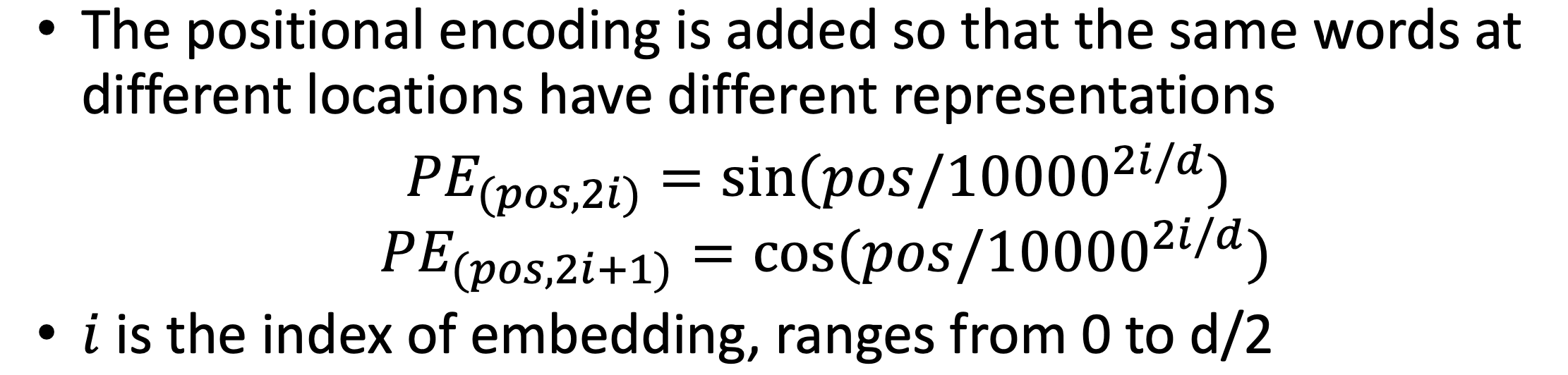
其实就是为原来的token编码加上位置向量,使其具有位置信息。而这里的位置向量,是基于正选加余弦来实现的。
Transformer Block
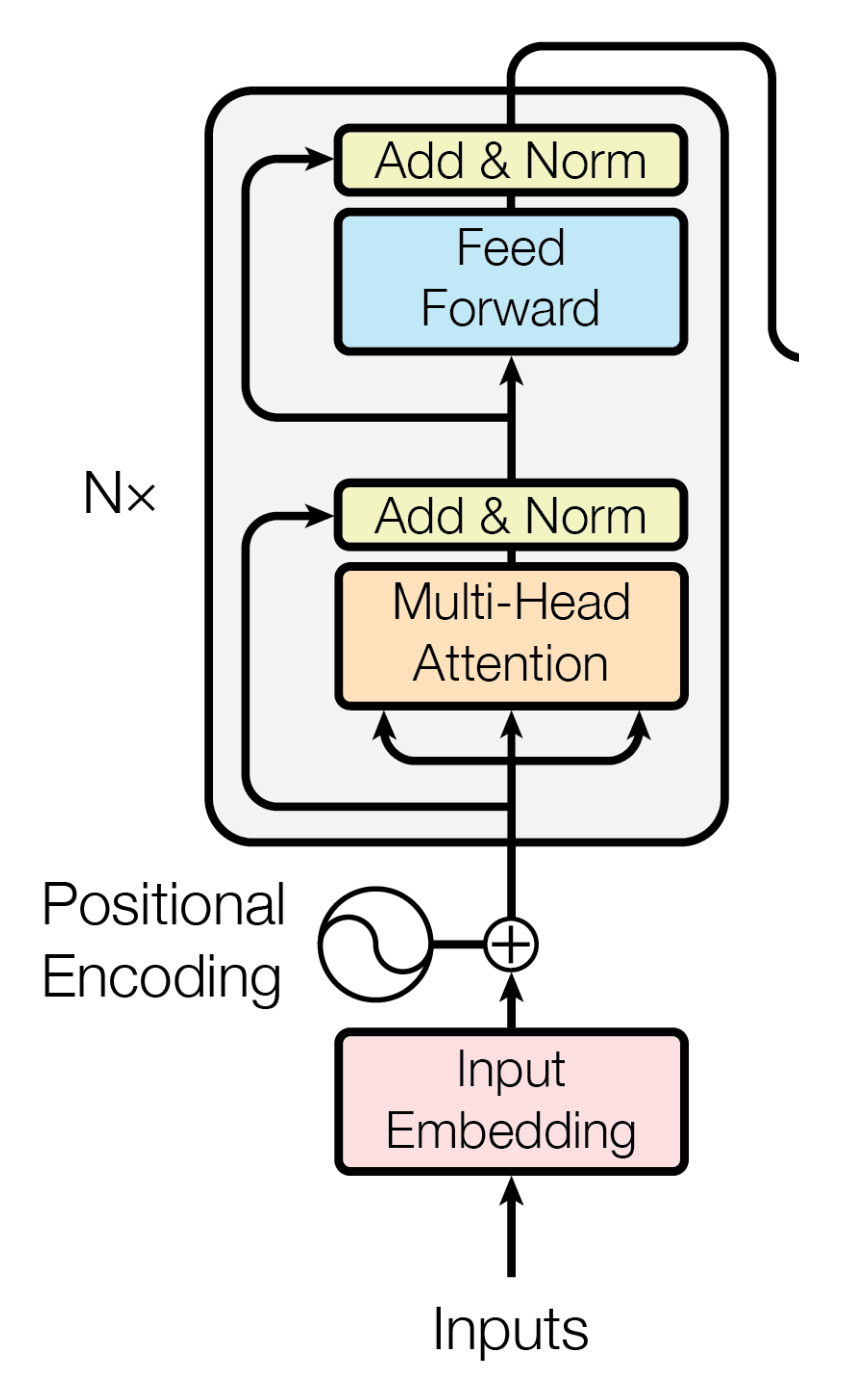
下面我们来了解Transformer Block,可以看到,它主要由两个子层组成:
- 多头注意力层
- 前馈网络
但这两个子层不是直接连接的,它们有一些小技巧:
- 残差连接
- 层归一化
在这些子层中假如残差连接,防止模型过深带来梯度消失问题。
而层归一化将输入的向量变成均值为0方差为1的分布。
在Transformer中使用的注意力也是基于点积来实现的。
-
输入
- 一个query q向量和一系列key-value向量对(k,v)
- query向量和key向量的维度为 d k d_k dk
- value向量的维度为 d v d_v dv
-
输出
-
value向量的加权和
-
其权重时基于query和相应的key进行点积来计算的
A ( q , K , V ) = ∑ i e q ⋅ k i ∑ j e q ⋅ k j v i A(q,K,V) = \sum_i
\frac{e^{q\cdot k_i}}{\sum_j e^{q \cdot k_j} } v_i
A(q,K,V)=i∑∑jeq⋅kjeq⋅kivi -
我们可以堆叠多个query到矩阵Q从而只需一次计算
A ( Q , K , V ) = softmax ( Q K T ) V A(Q,K,V) = \text{softmax}(QK^T)V
A(Q,K,V)=softmax(QKT)V
-
下面用一个图示来解释该过程。
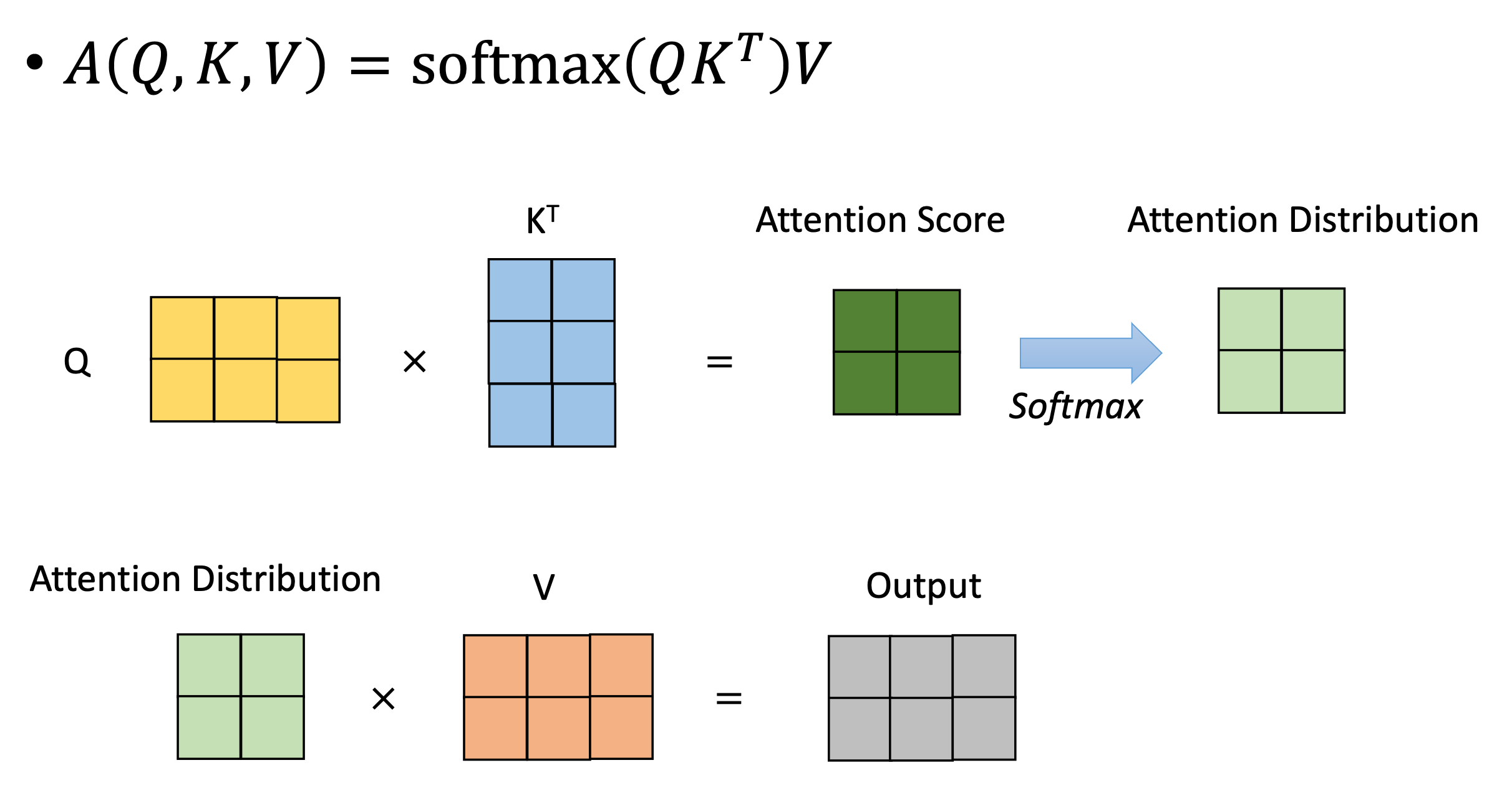
首先有三个矩阵, Q , K , V Q,K,V Q,K,V。然后计算 Q K T QK^T
QKT得到一个注意力分数,再经过Softmax得到注意力分布。再乘上 V V V矩阵就得到输出。
在前面Attention的基础上,我们进一步假如一个缩放系数。就得到了Transformer中使用的缩放点积注意力。
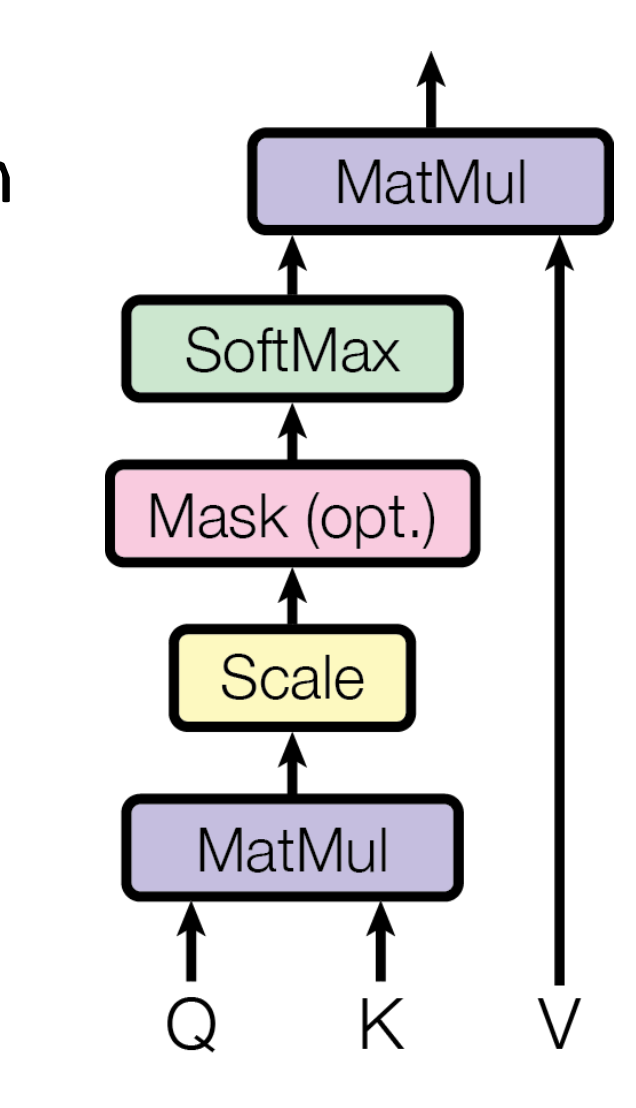
变成了
A ( Q , K , V ) = softmax ( Q K T d k ) V A(Q,K,V) = \text{softmax} \left (
\frac{QK^T}{\sqrt{d_k}} \right)V A(Q,K,V)=softmax(dk QKT)V
为什么要加这个缩放系数呢?因为注意力是通过q和k的点积实现的,如果没有这个缩放系数,那么q和k的点积得到的标量的方差会随着 d k d_k
dk的增加而变大,这样得到的概率分布会非常尖锐,从而使得梯度变得很小,不好训练。
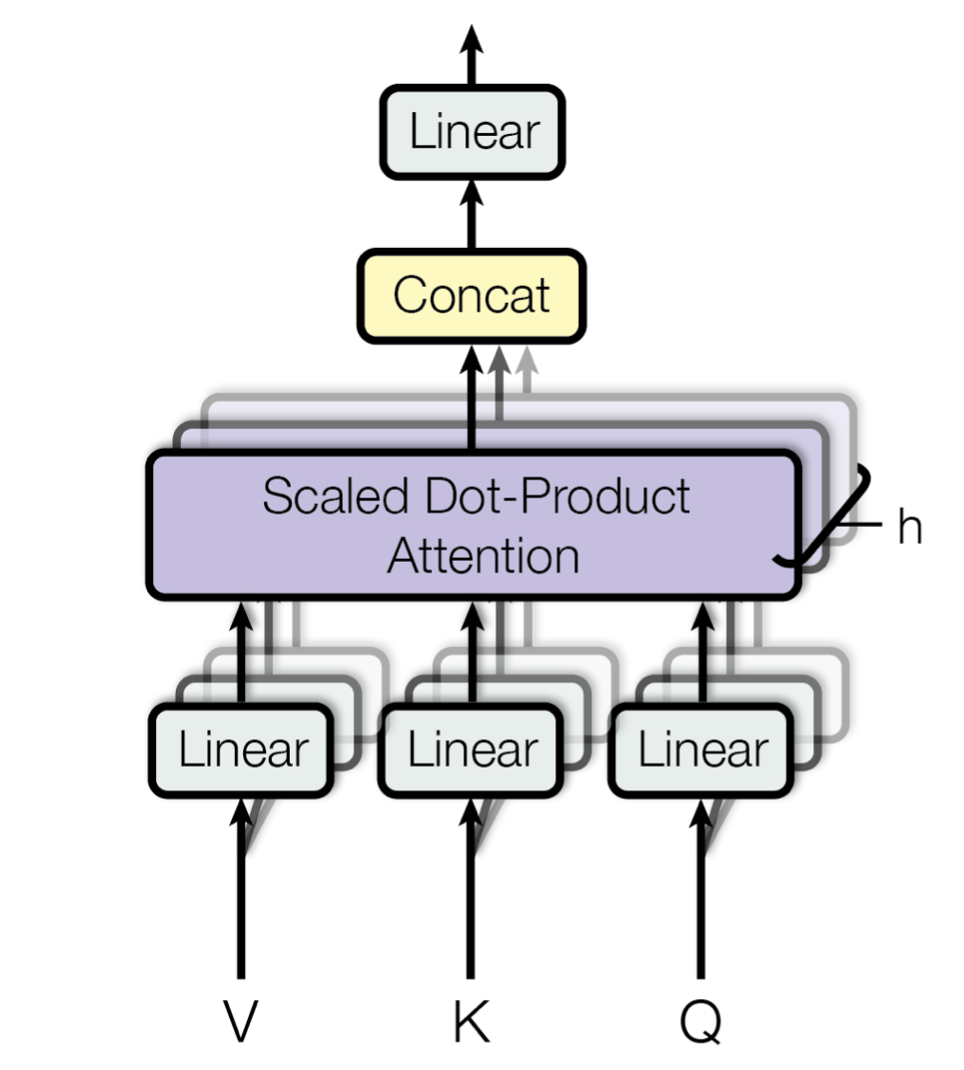
由于我们的这个Attention是一种自注意力机制,我们希望模型能够让每个token可以自主地选择应该关注输入中的哪些token,并进行信息的整合。
所以对应到QKV三个矩阵,它们其实都是从文本的表示向量乘上变换矩阵(Linear)得到的。
对于非第一层的Transformer block来说,文本的表示向量就是前一层的输出。而对于第一层来说,就是词向量和对应位置编码的求和。
在上述单个Attention的基础上,Transformer为了增强模型的表示能力,采用了多个结构相同但参数不同的一个注意力模块,组成了一个对头的注意力机制。其中每个头的注意力计算方式和上面介绍的无二。
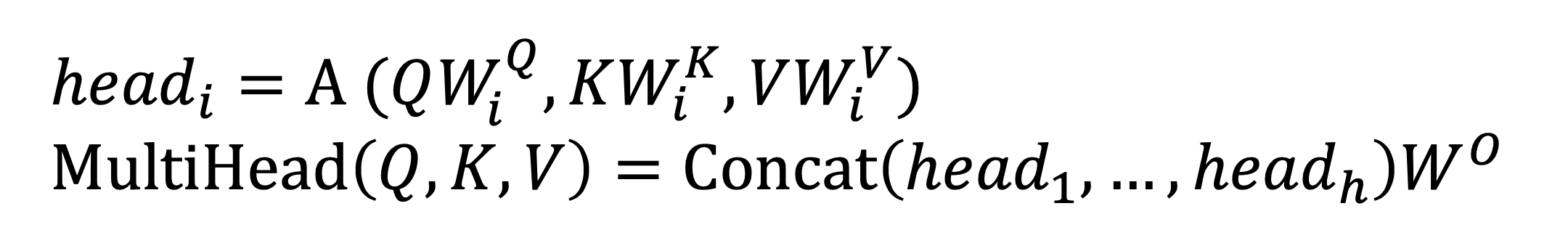
只不过每个头都会有一个自己对应的权重矩阵。
每个注意力头在得到自己的输出之后,我们将这些输出在维度层面进行拼接,然后通过一个线性层整合,就得到了多头注意力的输出。
上面是编码器端Block的结构,下面我们来看对于解码器来说会有什么不同。
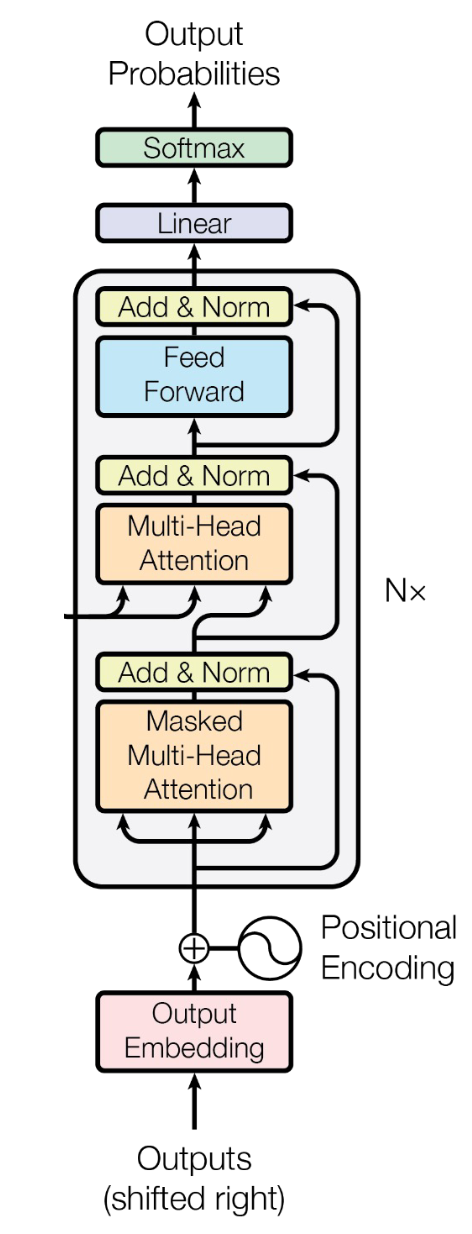
第一个不同在于输入经过的不是编码器那样的多头注意力,而是增加了掩码。
为什么需要这个掩码呢?因为在预测任务时,我们只能让解码器看到它已经输出的单词,而不能看到后面未输出的单词。
第二个不同是接着加入了编码器和解码器端之间的注意力,上图中的Multi-Head
Attention。这和解码器的多头注意力完全相同,不同之处在于,它的query向量来自解码器中掩码多头注意力的输出,而key和value向量来自于编码器最后一层的输出。
和带注意力机制的seq2seq类似,为了帮助解码器端每一步生成都可以关注和整合编码器端每个位置信息而设计的。
我们也用一个图示来看下一带掩码的注意力过程。
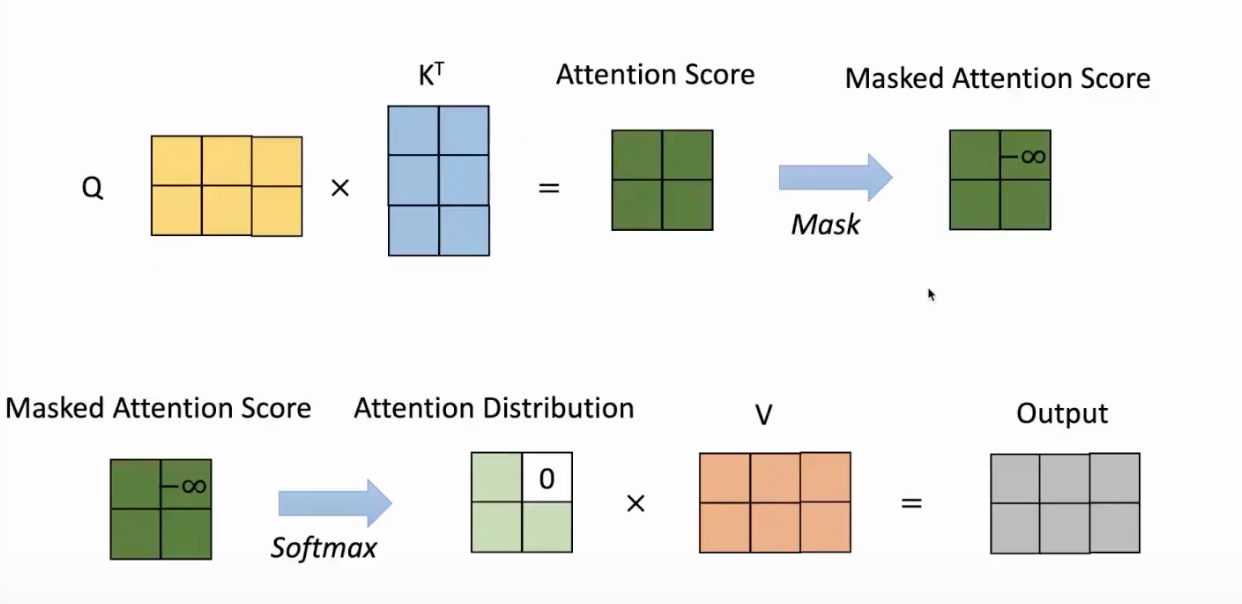
在通过 Q Q Q和 K K
K矩阵计算出注意力分数后,接着就是掩码部分,即将矩阵左对角线的上三角部分(右上角)的值变为负无穷大。这样在经过Softmax后,右上角的值会变为零。这样保证了解码器端在文本生成的时候,它是顺序生成的,不会出现在生成第
i i i个位置的时候,参考了 i + 1 i+1 i+1等后面位置的信息。
优化技巧
Transformer在训练和生成的过程中采用了很多小技巧:
- ADAM优化器
- 在残差连接之前加上Dropout
- 输出层加入了Label smoothing
- 在解码器生成了过程中采用了更加复杂的生成策略
优缺点
- 优点
- 是一个很强的模型,在很多NLP任务中得到了证明
- 适用于并行化
- 给后续的预训练语言模型比如BERT和GPT等带来了很多启发
- 缺点
- 模型本身对于参数敏感,优化过程非常困难
- 处理文本的复杂度是文本长度的平方 O ( n 2 ) O(n^2) O(n2),这样无法处理特别长的文本
预训练语言模型
语言建模
语言建模的任务是预测下一个单词。
途径就是计算下一个单词 w n w_n wn的条件概率:
P ( w n ∣ w 1 , w 2 , ⋯ , w n − 1 ) P(w_n|w_1,w_2,\cdots,w_{n-1})
P(wn∣w1,w2,⋯,wn−1)
语言模型重要的是可以迁移到其他NLP任务中。比较有代表性的三种模型是:
- word2vec
- 预训练RNN
- GPT&BERT
预训练语言模型
预训练语言模型(PLM)的好处是,在语言模型预训练后学到的知识可以非常容易地迁移到各种下游任务。
word2vec是第一个预训练语言模型。
现在大多数预训练语言模型都是基于Transformer(e.g. BERT)。
预训练语言模型可以分成两种范式
- 特征提取器
- 最代表性的是word2vec
- 使用PLM的输出作为下游任务的输入
- 模型参数微调
- 最代表性的是BERT
- 语言模型也会作为下游模型进行参数更新(主流)
微调
有两种具有代表性的微调模型,首先我们来介绍GPT。
GPT
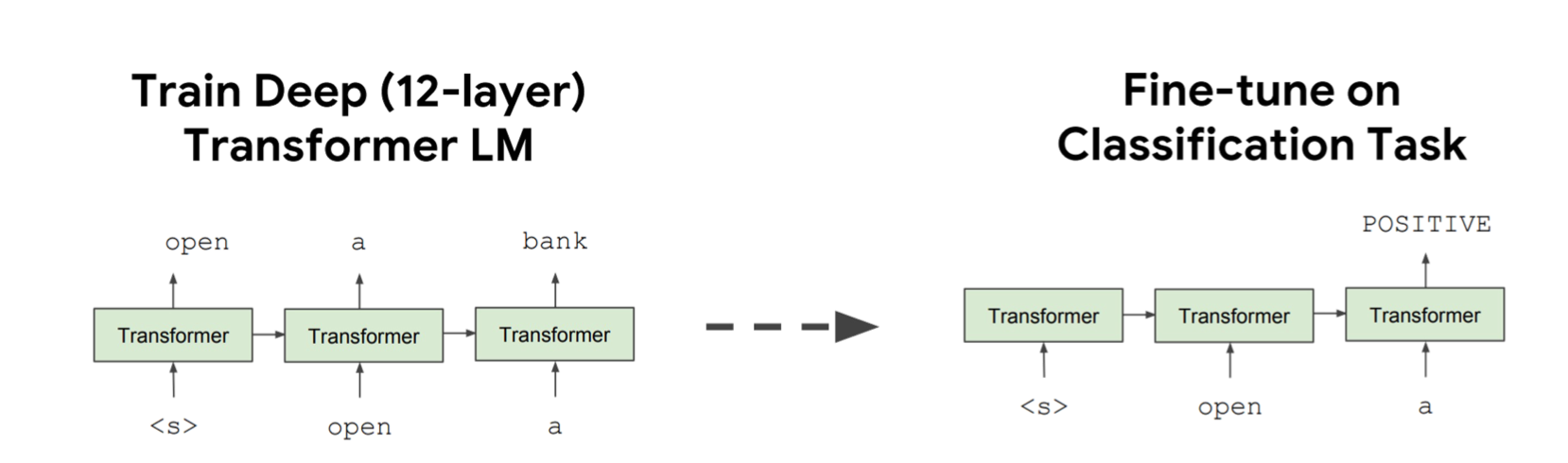
受到了Transformer的启发,GPT是第一个在Transformer上预训练PLM工作的。
它拿到了Transformer的Decoder,用自回归的方式去训练一个语言模型。
具体地,使用了12层的Transformer的decoder来自回归地在无监督文本语料上训练一个语言模型,在下游任务可以通过这种方式对整体的文本内容进行编码。
下一步,作者们又提出了GPT-2。主要不同是提升了模型的参数量,训练了不同的模型大小。
并且使用了更大规模的语料(40GB)进行预训练。
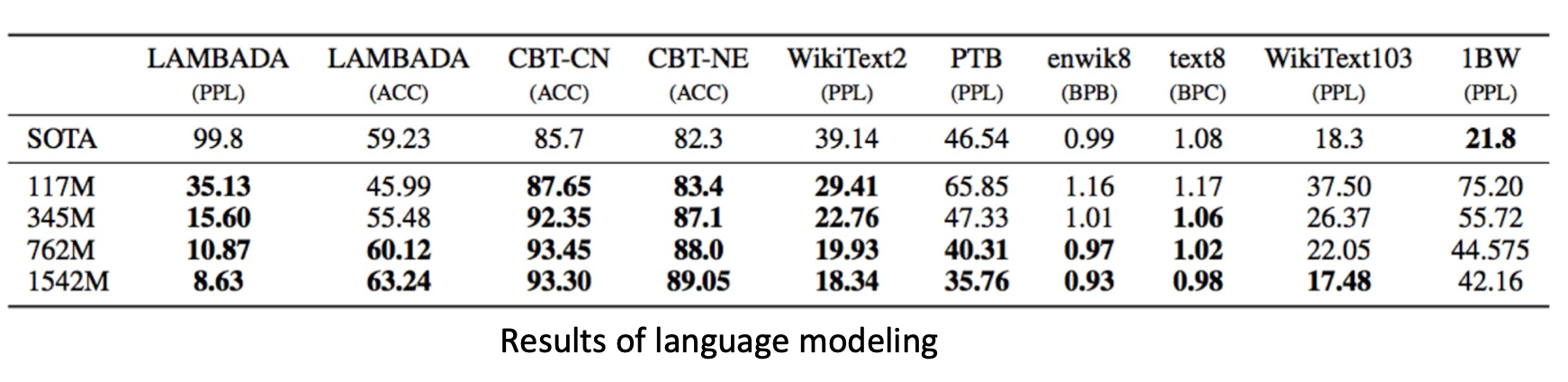
GPT还具有非常好的一个zero-shot能力。我们可以实现很多种任务使用语言模型形式把它统一起来。可以在没有任何标注数据的情况下来完成任务。

比如做与阅读理解,给定一个上下文以及一个问题,它就可以通过语言模型的形式去自回归地生成答案。
另一个具有代表性的模型是BERT。
BERT
BERT是现在最受欢迎的预训练语言模型。它改变了NLP研究的范式。
在BERT之前最成功的预训练语言模型是GPT,它通过自左到右自回归的去做预训练。但是在语言理方面,我们直观的认为它是一个双向的过程。即当前内容左边和右边的信息对于理解当前内容都是很有帮助的。
为什么之前的GPT是单向的呢?
- 需要一个方向去自然地把长文本拆解成一些小部分
- 双向模型如果能看到所有内容,会发生信息泄露。
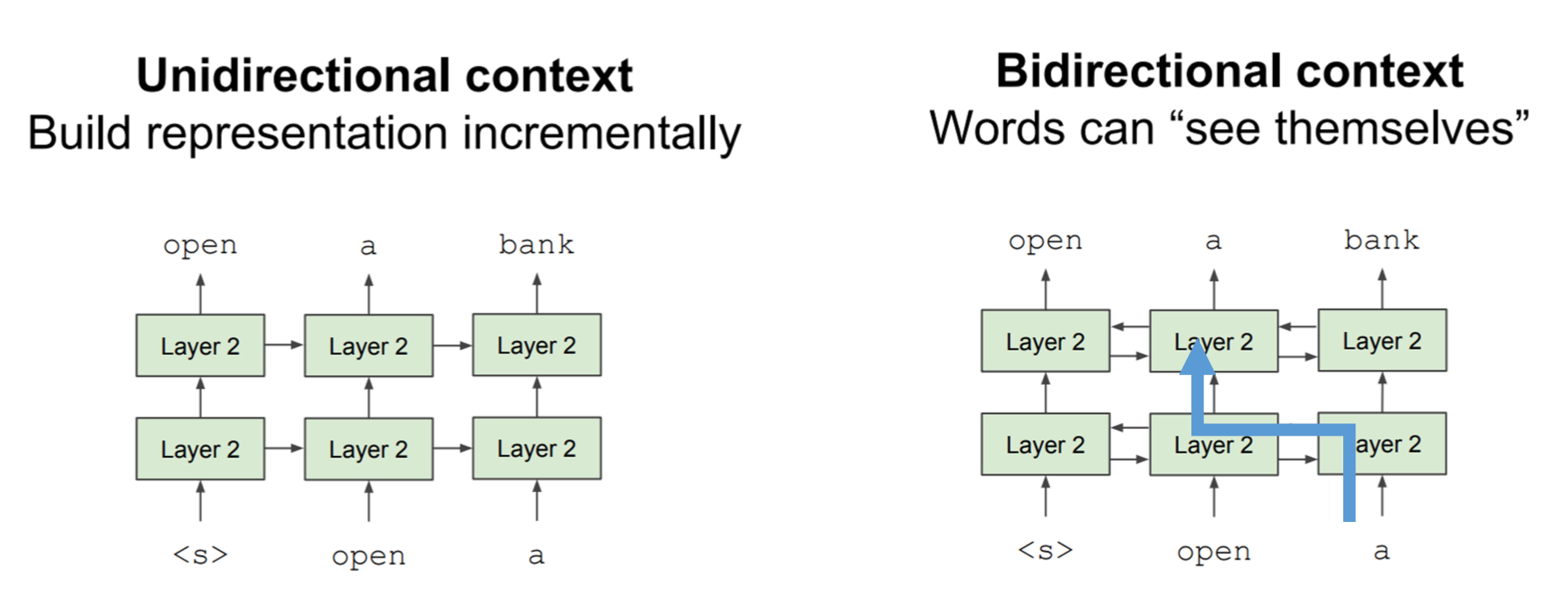
单向的GPT在语言生成方面很有优势,但是在语言理解上就有不足。
如果在双向的环节中,把整个序列输入进去,那么模型能看到当前单词的下一个单词,它只需要学会简单地复制即可。比如上图右边输入"open"时它能看到下一个单词是"a"。
BERT作为一个双向的语言模型,它是如何解决信息泄露问题的呢?
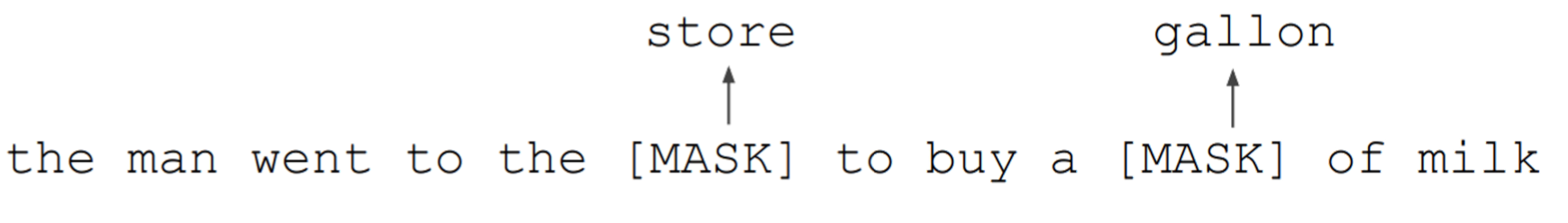
它的解决方案是通过遮盖(Mask)的方式,这是受到完形填空启发。
比如上面的例子中,将store和gallon遮盖住,然后让BERT去预测这两个单词。
BERT采用了随机Mask掉15%单词的策略。
虽然这样可以解决信息泄露的问题,但是也会带来一个新的问题。就是Mask
token在下游任务微调时是不会出现的,比如在做下游的与阅读理解的时候,它不会有mask这样一个token。
这样会造成预训练和微调非常大的差异,这样的差异会导致模型的效果变差。因为模型可能会只关注mask的表示,因为其他正常的token模型认为都是作为一些上下文出现的。它任务只要把mask预测好就完事了,这样模型可能会具有偏差。
针对此问题,BERT也提出了解决方法。在做15%Mask的时候,也细分成几种方式:

即80%的概率替换为Mask;10%的概率替换为随机单词;10%的概率不替换。
这样来要求模型去关注那些看起来不是mask的单词,去维持一个比较好的表示。但这样其实也会带来问题。最后10%的概率保持不变(即上图store预测出store)是为了防止模型认为现实中出现的词都是错的。
通过这三种策略的叠加来解决Mask带来的预训练和微调阶段的差异。
BERT除了Mask语言模型这样一个最核心的预训练任务,还有另外一个预训练任务——下一句预测(NSP)。来更好地利用大规模无监督语料库中句子间的信息。
如果Mask作为词和词之间的条件概率,那么NSP就是句子间的条件概率。

做法也很简单,如果是两个相邻的句子,那么标签就是True;如果是随机的两个句子,那么标签就是False。
下面来看一下BERT是如何表示输入的。
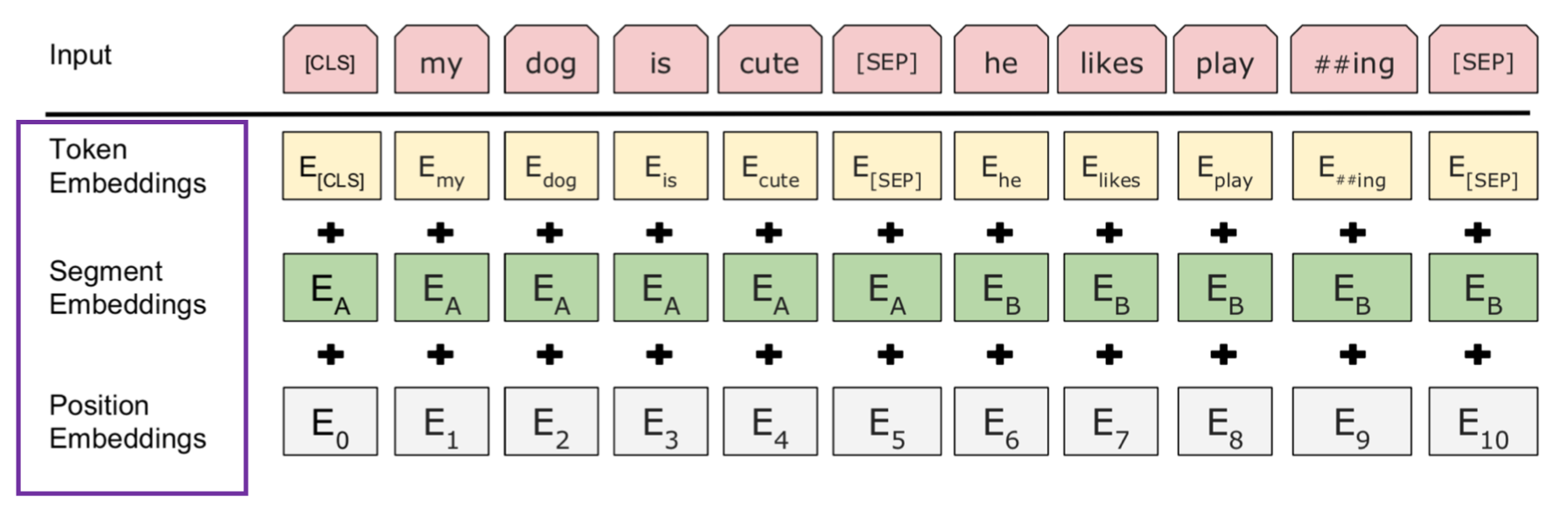
BERT整体上是基于Transformer的encoder, BERT在输入方面做了微小地调整。
首先的第一个输入单词是[CLS],定位是汇聚所有的输入信息,来支持下游的句子分类这样的任务。通常会接收几段的输入,中间通过[SEP]单词来进行分隔。最后也通过[SEP]表示整个输入的结束。
这里输入的token会分为三部分相加。
第一部分是词嵌入,采用的是word piece这种分词方式。
第二部分是片段嵌入,表示文本属于哪个文本段。
第三部分是位置编码,BERT中采用了更加简单地方式,预定义了512个这样的位置token,是随机初始化可学习的。
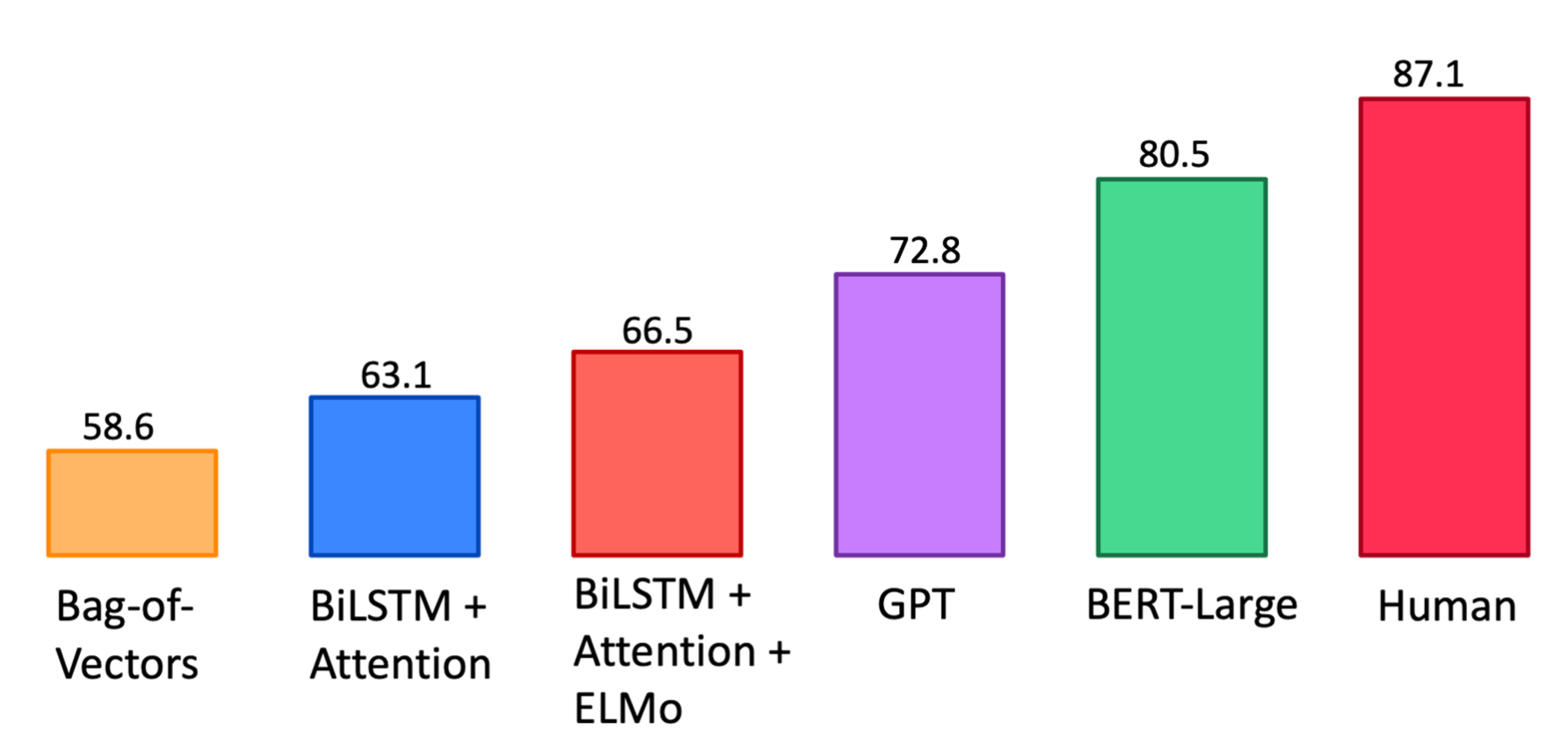
BERT作为一个双向的Encoder来预训练,可以看到它在GLUE上的表现比之前的GPT也有一个提示,达到了SOTA结果。
下面我们来看一下BERT这两种预训练任务的作用。
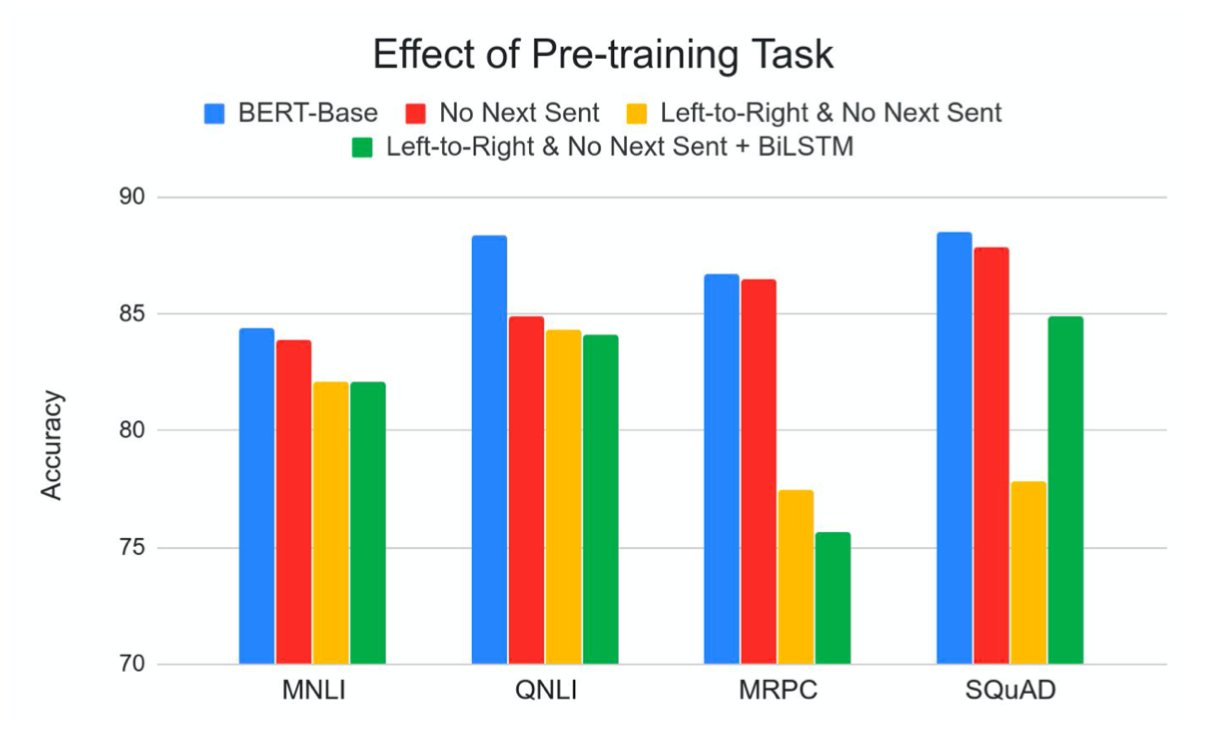
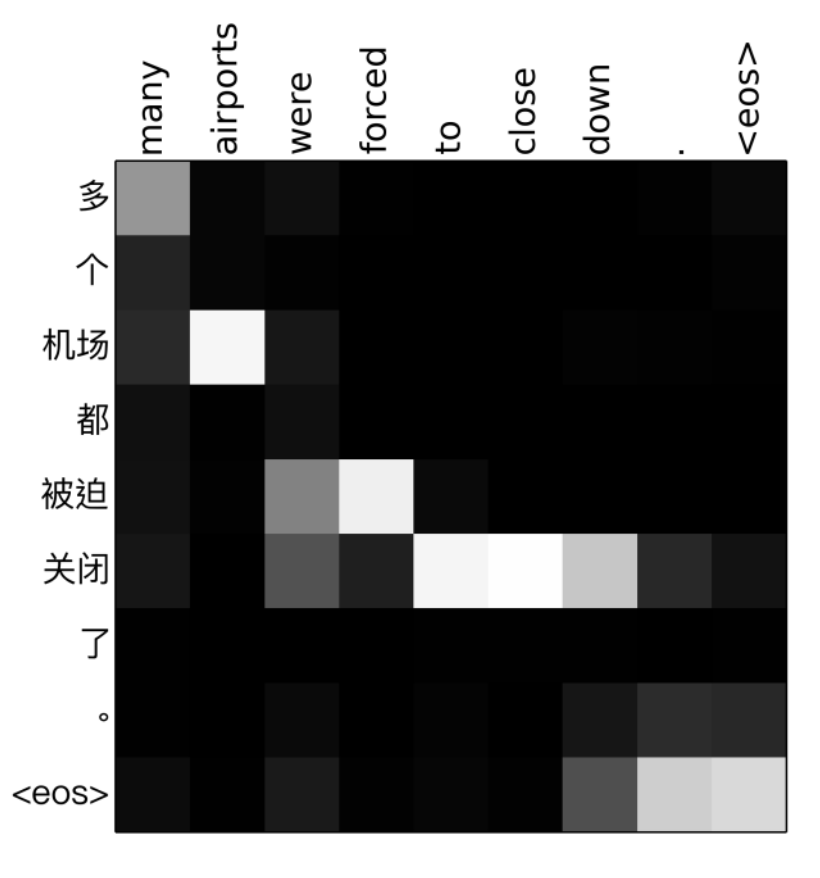
上图是蓝线条是BERT的结果;黄线条是GPT自回归从左到右的方式;
对于Mask LM任务,可以看到在非常多的任务上可以看BERT和GPT的区别,这就是在理解中考虑双向上下文的好处。
而对于NSP,可以看到在这些任务上基本做不做NSP训练,结果没有特别的差异,除了QNLI任务上差别较大。
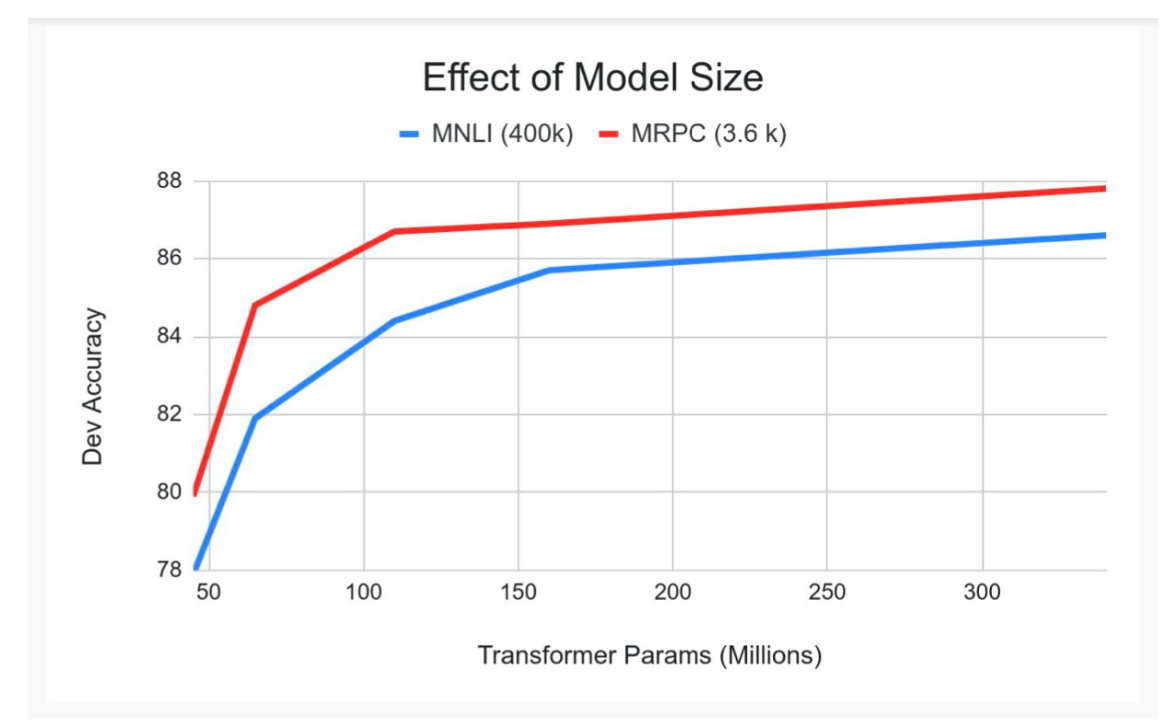
我们在BERT中也可以看到随着模型参数量的增大,效果会稳定提升,这启发了后面的模型越来越大,同时也更烧钱。
总结
- 特征提取方式的模型给下游任务提供单词嵌入,会固定输入的特征,效果非常有限。
- 基于微调的方式可以根据下游任务更新整个模型参数,取得了非常好的效果。
BERT之后的预训练语言模型
我们来看一下在BERT之后有哪些工作可以改进BERT。
BERT虽然带来了很大的提升,但也存在很多问题。
第一个就是我们上面提到的预训练和微调之间的差异(gap)。BERT通过混合不同的Mask策略来解决。但仍然没有从根本上解决这个问题,因为Mask在预训练中起到了非常重要的做法,但在下游任务中不会出现。
第二个是预训练的效率非常地,每次只能预测15%的单词,只有这些单词受到了有效的监督,其他的词不会受到监督的上下文进行编码。
下面简单介绍几个有代表性的改进。
RoBERTa
RoBERTa发现BERT没有完全被训练好,它探索了很多细节的改进。比如:
- 动态Mask
- NSP是否有必要存在
- 训练更大的批次
- 文本编码
基于这些改动,RoBERTa做了很多实验来证明改进效果。
ELECTRA
它主要解决的问题是预训练的效率不高(15%),基于传统的语言模型其实所有的词都会受到监督,它提出了替换标记检测(Replaced Token
Detection)任务。
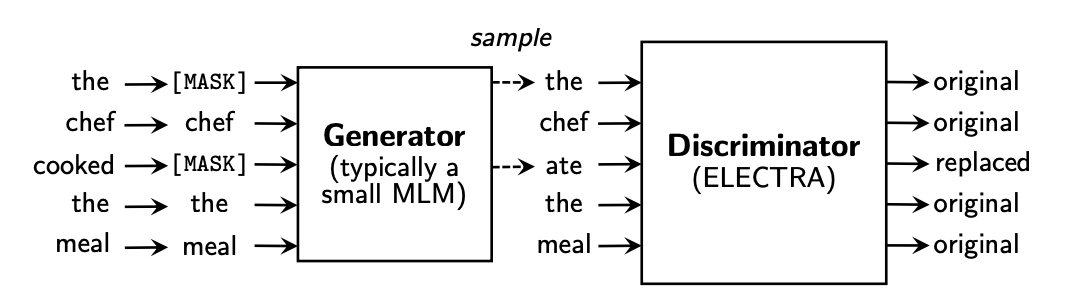
它首先也会对原始的输入做随机的Mask,然后用一个小的语言模型(预训练之后会丢弃掉)来尝试还原mask的结果,这里强调的是一个小的模型,所以该小模型还原出来的应该是大致合理但不是非常好的结果,比如这里把"cooked"还原成了"ate"。
接下来使用一个比较大的判别模型,这里就是ELECTRA来判断每一个单词是否发生了替换。这种方式同时解决了上述两个问题,首先它所有的单词都受到了有效监督,同时真正会用到的模型(ELECTRA)没有受到Mask单词的影响。
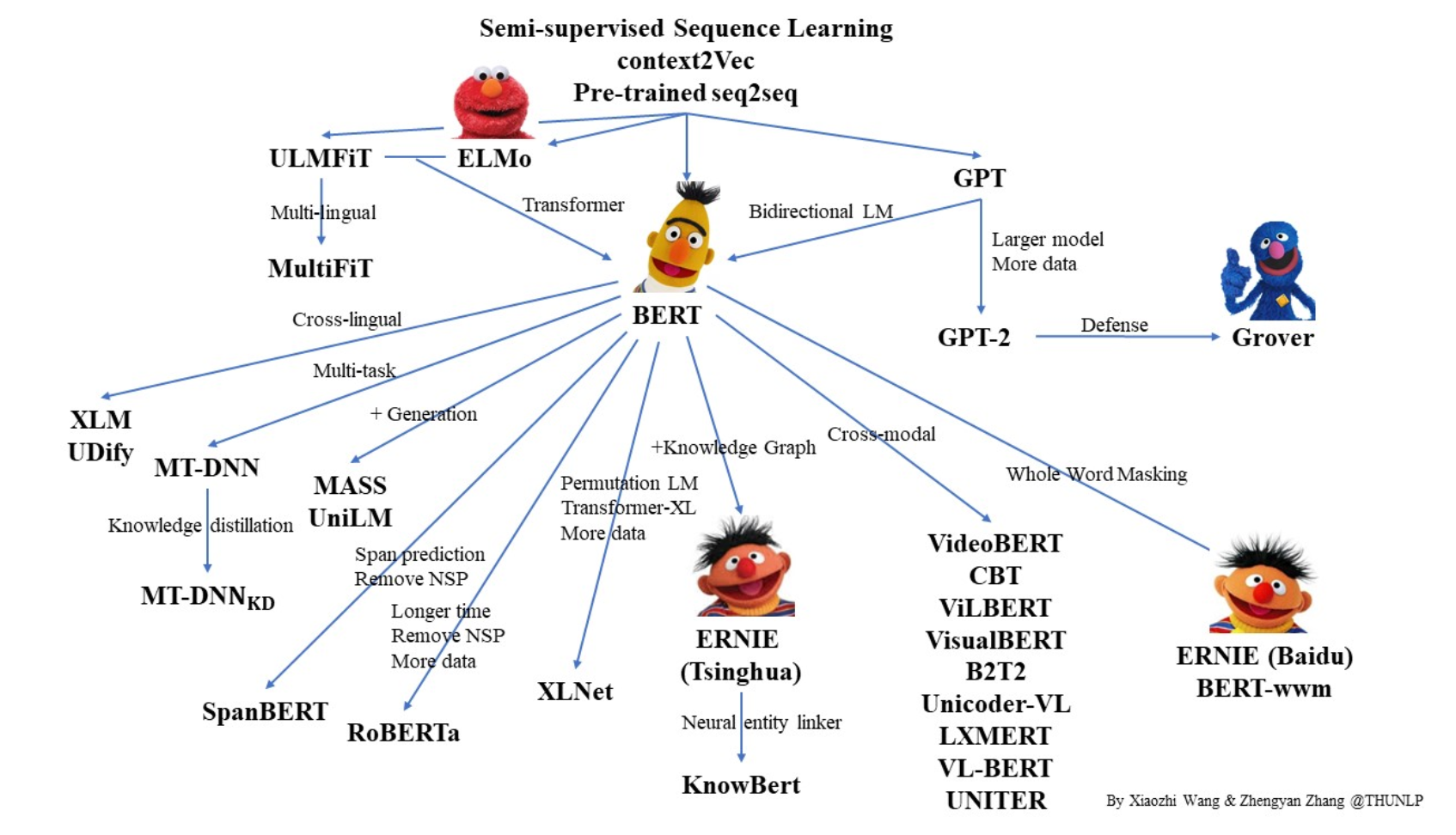
这里主要介绍了两个改进模型,其实还有非常多的模型尝试进行了改进,上图中有所体现。
Mask语言模型应用
基本思想:利用双向信息去预测目标token
除了基于单语言token建模之外,还可以通过mask获取多模态和多语言信息
比如跨语言应用,在本应用中的挑战是如何把不同的语言的词和句法结构建立关联。Masked
LM可以提供非常好的工具,比如在英法翻译中,我们Mask掉一个英文单词,模型可以注意到该英语单词的上下文来还原该单词,同样也可以注意到在它的翻译中,法语,应该也会大概对应一个法语词,鼓励模型对应英法与法语表征。
在跨模态模型中也有对齐问题,比如视频和文本,需要把文本的token和视觉区域做关联。
可以看到,Masked LM作为无监督数据中数据关联的一种方式,除了在文本之外,在很多其他的领域也可以有所应用。
预训练语言模型前沿发展
GPT-3
首先不得不提的就是GPT-3,前面介绍的GPT的第三代,一个超大的模型。
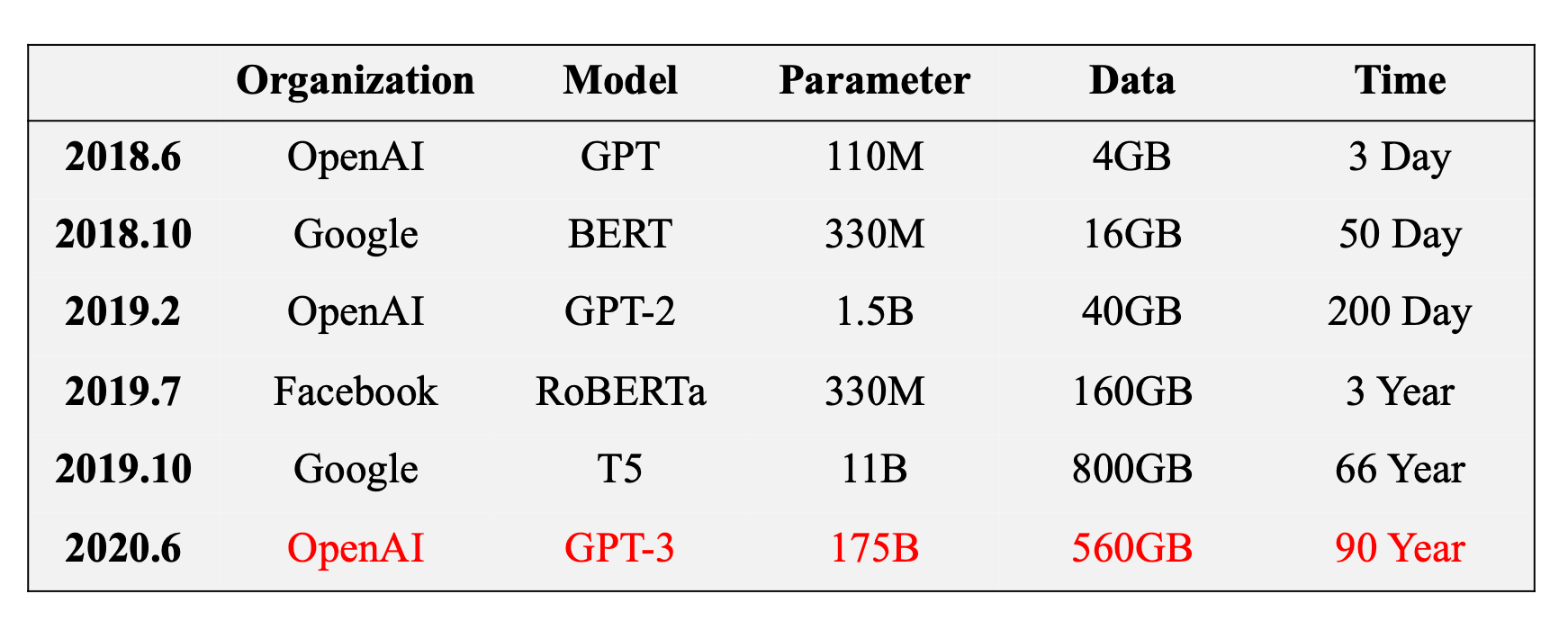
在它的模型规模和预训练数据增大了之后,我们会观察到一些神奇的现象。

它的Zero-shot/One-shot效果非常好。
zero-shot就是可以不给模型任何训练数据,只给它一个整体的任务描述,模型就可以完成任务,如上图所示。
而one-shot就是在zero-shot的基础上,我们可以只提供一个样例,让模型来完成任务。
它其实都是以in-context learning的形式完成的,所谓in-context
learning指它没有针对下游任务做任何参数的更新,只是在上下文中给了这个任务的描述以及样例,通过语言模型自回归地生成来完成这个任务。
但GPT有一个非常明显的问题是它不知道何时说"我不知道"。

即它不知道这个问题可能本身是不合理的,或者它自己并不知道答案。
比如问“我的脚有几只眼睛?”,它会回答“你的脚有两只眼睛。”
T-5
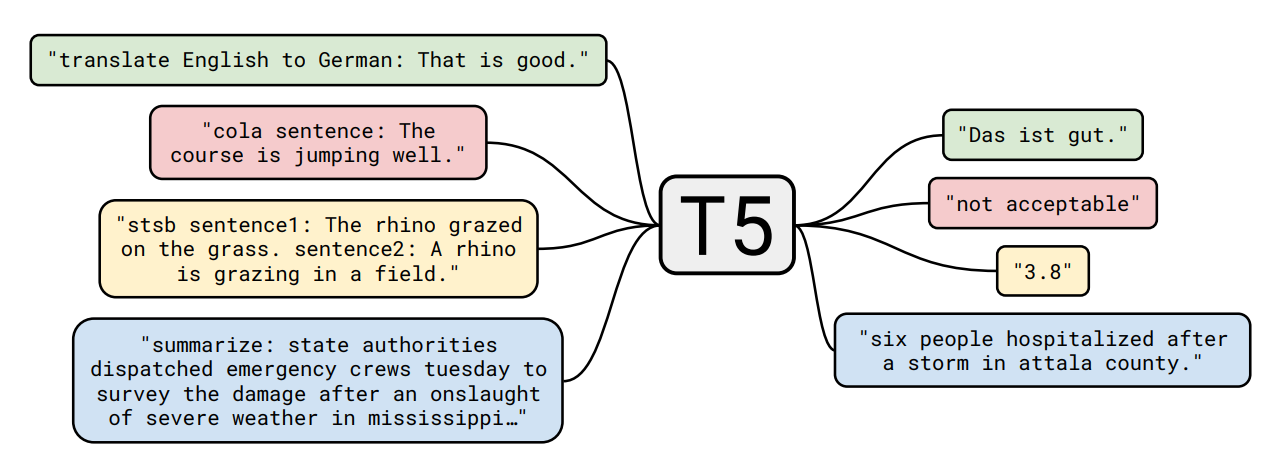
在GPT之后的这个T5也是非常重要的一种预训练语言模型。它的创新在于将所有的NLP任务统一成一个text-to-
text的形式,输入都是任务的描述加上任务的内容,T5基于encoder-decoder的一个架构,利用seq2seq的方式去生成答案。
T5也是非常通用的一个框架,在语言理解以及生成上面都取得了非常好的效果。
MoE
在发现预训练模型规模越大,效果越好之后,大家进行了各种尝试来训练更大的模型,但后面研究者发现,在模型越来越大之后,它的优化上会出现各种问题。
为了解决这些问题,研究者提出了基于Mixture of Experts(MoE)的方式去增大模型的参数,以训练更大规模的预训练语言模型。
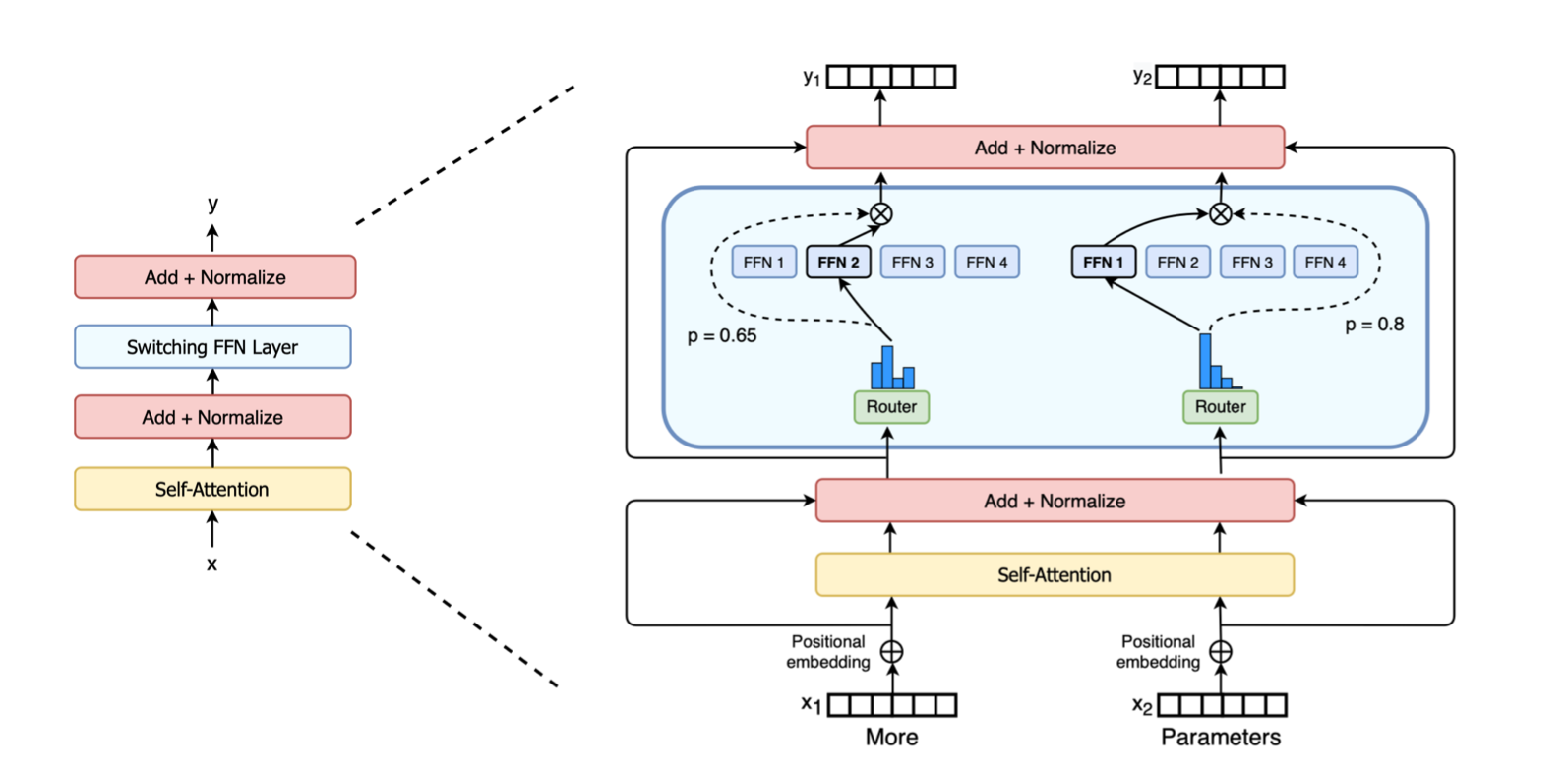
主要的思想是把模型的参数分成一块块的子模块,每次模型的输入只调用其中部分的子模块来参与计算。将每个子模块看成是一个专家(expert),而整体的模型是不同export组合的结果。
HuggingFace Transformers教程
本节来介绍流行的Transformer库的使用。
简介

我们知道,预训练语言模型在BERT之后,就像雨后春笋一样大量地涌现了。虽然这是好事,但作为工程师,我们想要实现每一个模型的时候,都要保证模型中的每一处细节和原论文一样,这其实是非常困难的。并且要实现各种模型不太现实,如果每一次都需要从头实现模型,对于使用预训练模型的人来说是一个非常繁重的工作。
我们就会希望有一个第三方的库能帮助我们:
- 轻松地复现各种预训练语言模型论文的结果
- 快速部署模型
- 自由地自定义模型
而HuggingFace就提供了这样一个库,叫transformers。
安装也非常简单pip install transformers。

使用Pipeline
这个库有一个非常重要的工具叫pipeline,它主要的使用场景是你希望使用现成的预训练好的模型来完成你的任务。

比如你希望有一个微调好的预训练模型来完成情感分析任务,那么只要输入任务名(sentiment-
analysis)到pipeline中,那么它会根据任务名为你提供一个微调好的模型。

再比如一个问答任务,只要输入问题和上下文。
Tokenization
如果不想直接用微调好的模型,而是想在自己的数据上去微调,那么第一个要做的事情就是分词。
我们知道,不同的模型可能包含不同的分词技术。

但有了transformers之后,我们不需要担心这些具体的不同。

只需要引入AutoTokenizer,它会帮你根据不同的模型自动选择对应的分词器。
然后直接传入要分词的文本即可。
常用API介绍
除了分词之外,要微调自己的数据或模型,你还需要了解一些API。
比如加载一个预训练的模型。
from transformers import AutoTokenizer, AutoModelForSequenceClassification
# 加载分词器
tokenizer = AutoTokenizer.from_pretrained('bert-base-uncased')
# 加载预训练的模型
model = AutoModelForSequenceClassification.from_pretrained('bert-base-uncased')
- 1
- 2
- 3
- 4
- 5
然后对输入进行分词:
inputs = tokenizer("Hello World!", return_tensors='pt')
- 1
接着将输入喂给模型:
outputs = model(**inputs)
- 1
最后可能需要保存微调好的模型:
model.save_pretrained('path_to_save_model')
- 1
实际上在训练时也有封装好的API:
trainer = Trainer(
model, # 模型
args, # 优化相关的参数
train_dataset=encoded_dataset["train"], # 训练数据集
eval_dataset=encoded_dataset["validation"], # 验证集
tokenizer=tokenizer, # 分词器
compute_metrics=compute_metrics # 评估指标
)
trainer.train() # 开始训练
trainer.evaluate() # 开始评估
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
实战
Pipeline虽然好用,但是不支持微调。如果想加载预训练模型,并自己微调的话,我们需要额外写一些加载模型、数据处理的代码。
以BERT在GLUE的SST-2数据集进行情感分析为例,展示如何使用微调。
首选我们需要加载要微调的数据集。
加载数据集
HuggingFace还提供了datasets库,包含了主流的数据集,通过一行命令(load_dataset)就可以完成数据集的下载与加载,且能够加载该数据集对应的指标(metric)以便计算(load_metric)。在这个例子中,我们需要加载GLUE中的SST-2任务。
我们使用Google的Colab来完成本次实战。
!pip install transformers datasets
- 1
首先我们要安装需要用到的这两个库。
然后加载GLUE中的SST-2任务。
from datasets import load_dataset, load_metric
dataset = load_dataset("glue", "sst2")
metric = load_metric("glue", "sst2")
- 1
- 2
- 3
我们看一下这个dataset:
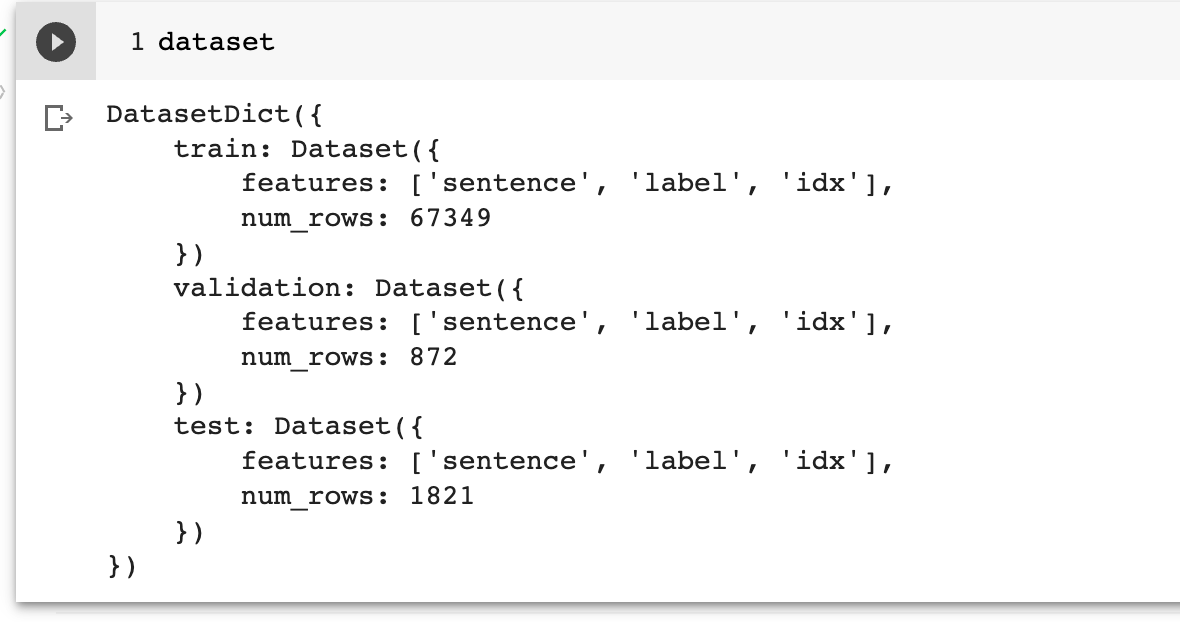
它已经将数据集进行了拆分,每个集合包含三个Key,对应文本,标签和编号。
我们也可以看第一条训练数据长啥样:

下面打印指标信息:
metric Metric(name: "glue", features: {'predictions': Value(dtype='int64', id=None), 'references': Value(dtype='int64', id=None)}, usage: """ Compute GLUE evaluation metric associated to each GLUE dataset. Args: predictions: list of predictions to score. Each translation should be tokenized into a list of tokens. references: list of lists of references for each translation. Each reference should be tokenized into a list of tokens. Returns: depending on the GLUE subset, one or several of: "accuracy": Accuracy "f1": F1 score "pearson": Pearson Correlation "spearmanr": Spearman Correlation "matthews_correlation": Matthew Correlation Examples: >>> glue_metric = datasets.load_metric('glue', 'sst2') # 'sst2' or any of ["mnli", "mnli_mismatched", "mnli_matched", "qnli", "rte", "wnli", "hans"] >>> references = [0, 1] >>> predictions = [0, 1] >>> results = glue_metric.compute(predictions=predictions, references=references) >>> print(results) {'accuracy': 1.0} >>> glue_metric = datasets.load_metric('glue', 'mrpc') # 'mrpc' or 'qqp' >>> references = [0, 1] >>> predictions = [0, 1] >>> results = glue_metric.compute(predictions=predictions, references=references) >>> print(results) {'accuracy': 1.0, 'f1': 1.0} >>> glue_metric = datasets.load_metric('glue', 'stsb') >>> references = [0., 1., 2., 3., 4., 5.] >>> predictions = [0., 1., 2., 3., 4., 5.] >>> results = glue_metric.compute(predictions=predictions, references=references) >>> print({"pearson": round(results["pearson"], 2), "spearmanr": round(results["spearmanr"], 2)}) {'pearson': 1.0, 'spearmanr': 1.0} >>> glue_metric = datasets.load_metric('glue', 'cola') >>> references = [0, 1] >>> predictions = [0, 1] >>> results = glue_metric.compute(predictions=predictions, references=references) >>> print(results) {'matthews_correlation': 1.0} """, stored examples: 0)

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
可以看到SST-2的指标为准确率。
在我们有了模型的预测结果以及正确结果之后,我们可以通过调用metric.compute来方便地计算模型的表现。我们先随机生成一些数据来展示使用方法。
import numpy as np
fake_preds = np.random.randint(0, 2, size=(64,)) # 随机生成一些预测结果
fake_labels = np.random.randint(0, 2, size=(64,)) # 随机生成一些标签
metric.compute(predictions=fake_preds, references=fake_labels) # 将二者输入metric.compute中
{'accuracy': 0.609375}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
这样,我们已经完成了数据集的下载、加载以及对应指标的准备。
分词
预训练模型并不直接接受文本作为输入,每个预训练模型都有自己的分词方式以及自己的词表,我们在使用某一模型时,需要:
- 使用该模型的分词方式对数据进行分词
- 使用该模型的词表,将分词之后的每个token转化成对应的id
除了token的id之外,预训练模型还需要其他的一些输入。例如BERT还需要token_type_ids、attention_mask等。
但这种繁琐的工作HuggingFace也为我们进行了简化,我们只需要加载想用的模型的分词器即可。
from transformers import AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained('bert-base-uncased')
- 1
- 2
下面就可以将文本直接传给分词器实例tokenzier就能得到模型的输入,例如:
tokenizer("Tsinghua University is located in Beijing.")
{'input_ids': [101, 24529, 2075, 14691, 2118, 2003, 2284, 1999, 7211, 1012, 102], 'token_type_ids': [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0], 'attention_mask': [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1]}
- 1
- 2
- 3
- 4
- 5
下面我们就开始利用分词器来定义处理数据函数,由于BERT只能处理长度不超过512的序列,因此我们指定truncation=True来截断过长的序列。
def preprocess_function(examples):
return tokenizer(examples['sentence'], truncation=True, max_length=512)
- 1
- 2
我们可以使用数据集中的前5条数据来检验一下处理结果。
preprocess_function(dataset['train'][:5])
{'input_ids': [[101, 5342, 2047, 3595, 8496, 2013, 1996, 18643, 3197, 102], [101, 3397, 2053, 15966, 1010, 2069, 4450, 2098, 18201, 2015, 102], [101, 2008, 7459, 2049, 3494, 1998, 10639, 2015, 2242, 2738, 3376, 2055, 2529, 3267, 102], [101, 3464, 12580, 8510, 2000, 3961, 1996, 2168, 2802, 102], [101, 2006, 1996, 5409, 7195, 1011, 1997, 1011, 1996, 1011, 11265, 17811, 18856, 17322, 2015, 1996, 16587, 2071, 2852, 24225, 2039, 102]], 'token_type_ids': [[0, 0, 0, 0, 0, 0, 0, 0, 0, 0], [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0], [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0], [0, 0, 0, 0, 0, 0, 0, 0, 0, 0], [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]], 'attention_mask': [[1, 1, 1, 1, 1, 1, 1, 1, 1, 1], [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1], [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1], [1, 1, 1, 1, 1, 1, 1, 1, 1, 1], [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1]]}
- 1
- 2
- 3
- 4
- 5
可以看到处理结果为一个字典,包含input_ids,token_type_ids以及attention_mask。
那么我们现在就可以使用preprocess_function来处理整个数据集,这一过程可以借助dataset.map函数来实现,该函数能将我们自定义的处理函数用到数据集的所有数据上。此外,通过指定batched=True,可以实现多线程并行处理来加速。
encoded_dataset = dataset.map(preprocess_function, batched=True)
- 1
查看一下encoded_dataset,我们可以发现encoded_dataset在原先的dataset基础上,多出了三个feature,分别就是tokenizer输出的三个结果:
DatasetDict({
train: Dataset({
features: ['sentence', 'label', 'idx', 'input_ids', 'token_type_ids', 'attention_mask'],
num_rows: 67349
})
validation: Dataset({
features: ['sentence', 'label', 'idx', 'input_ids', 'token_type_ids', 'attention_mask'],
num_rows: 872
})
test: Dataset({
features: ['sentence', 'label', 'idx', 'input_ids', 'token_type_ids', 'attention_mask'],
num_rows: 1821
})
})
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
再次查看第一条训练数据:
encoded_dataset['train'][0]
{'sentence': 'hide new secretions from the parental units ',
'label': 0,
'idx': 0,
'input_ids': [101, 5342, 2047, 3595, 8496, 2013, 1996, 18643, 3197, 102],
'token_type_ids': [0, 0, 0, 0, 0, 0, 0, 0, 0, 0],
'attention_mask': [1, 1, 1, 1, 1, 1, 1, 1, 1, 1]}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
至此,我们将所有数据转化成了模型能接受的输入格式(input_ids, token_type_ids, attention_mask)。
微调模型
数据集已经准确完毕,我们可以开始微调模型了。
首先,我们需要利用transformers把预训练下载下来,同时由于SST-2的标签种类只有两种,因此我们指定num_labels=2。
from transformers import AutoModelForSequenceClassification
model = AutoModelForSequenceClassification.from_pretrained('bert-base-uncased', num_labels=2)
- 1
- 2
代码会输出一些像是报错的信息,不用担心。这是因为我们为了利用BERT来进行情感分类,舍弃了原先BERT用来做masked language
modeling和句子关系预测的参数,替换为了一个新的分类层来进行训练。
下面,我们使用Trainer类来进行模型的微调。这里,我们设置它的各种参数如下:
from transformers import TrainingArguments
batch_size=16
args = TrainingArguments(
"bert-base-uncased-finetuned-sst2", # 训练的名称
evaluation_strategy="epoch", # 在每个epoch结束的时候在validation集上测试模型效果
save_strategy="epoch", # 在每个epoch结束的时候保存一个checkpoint
learning_rate=2e-5, # 优化的学习率
per_device_train_batch_size=batch_size, # 训练时每个gpu上的batch_size
per_device_eval_batch_size=batch_size, # 测试时每个gpu上的batch_size
num_train_epochs=5, # 训练5个epoch
weight_decay=0.01, # 优化时采用的weight_decay
load_best_model_at_end=True, # 在训练结束后,加载训练过程中最好的参数
metric_for_best_model="accuracy" # 以准确率作为指标
)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
下面我们定义一个函数,告诉Trainer怎么计算指标:
def compute_metrics(eval_pred):
logits, labels = eval_pred # predictions: [batch_size,num_labels], labels:[batch_size,]
predictions = np.argmax(logits, axis=1) # 将概率最大的类别作为预测结果
return metric.compute(predictions=predictions, references=labels)
- 1
- 2
- 3
- 4
现在我们可以定义出该Trainer类了:
from transformers import Trainer
trainer = Trainer(
model,
args,
train_dataset=encoded_dataset["train"],
eval_dataset=encoded_dataset["validation"],
tokenizer=tokenizer,
compute_metrics=compute_metrics
)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
这里我们使用默认的选项,优化器是AdamW,scheduler是linear warmup。
接着,调用train方法就可以开始训练了。
trainer.train() The following columns in the training set don't have a corresponding argument in `BertForSequenceClassification.forward` and have been ignored: sentence, idx. If sentence, idx are not expected by `BertForSequenceClassification.forward`, you can safely ignore this message. /usr/local/lib/python3.7/dist-packages/transformers/optimization.py:310: FutureWarning: This implementation of AdamW is deprecated and will be removed in a future version. Use the PyTorch implementation torch.optim.AdamW instead, or set `no_deprecation_warning=True` to disable this warning FutureWarning, ***** Running training ***** Num examples = 67349 Num Epochs = 5 Instantaneous batch size per device = 16 Total train batch size (w. parallel, distributed & accumulation) = 16 Gradient Accumulation steps = 1 Total optimization steps = 21050 [21050/21050 48:49, Epoch 5/5] Epoch Training Loss Validation Loss Accuracy 1 0.177300 0.327943 0.916284 2 0.121800 0.339612 0.917431 3 0.089700 0.341416 0.918578 4 0.053900 0.441544 0.915138 5 0.030300 0.464400 0.910550 The following columns in the evaluation set don't have a corresponding argument in `BertForSequenceClassification.forward` and have been ignored: sentence, idx. If sentence, idx are not expected by `BertForSequenceClassification.forward`, you can safely ignore this message. ***** Running Evaluation ***** Num examples = 872 Batch size = 16 Saving model checkpoint to bert-base-uncased-finetuned-sst2/checkpoint-4210 Configuration saved in bert-base-uncased-finetuned-sst2/checkpoint-4210/config.json Model weights saved in bert-base-uncased-finetuned-sst2/checkpoint-4210/pytorch_model.bin tokenizer config file saved in bert-base-uncased-finetuned-sst2/checkpoint-4210/tokenizer_config.json Special tokens file saved in bert-base-uncased-finetuned-sst2/checkpoint-4210/special_tokens_map.json The following columns in the evaluation set don't have a corresponding argument in `BertForSequenceClassification.forward` and have been ignored: sentence, idx. If sentence, idx are not expected by `BertForSequenceClassification.forward`, you can safely ignore this message. ***** Running Evaluation ***** Num examples = 872 Batch size = 16 Saving model checkpoint to bert-base-uncased-finetuned-sst2/checkpoint-8420 Configuration saved in bert-base-uncased-finetuned-sst2/checkpoint-8420/config.json Model weights saved in bert-base-uncased-finetuned-sst2/checkpoint-8420/pytorch_model.bin tokenizer config file saved in bert-base-uncased-finetuned-sst2/checkpoint-8420/tokenizer_config.json Special tokens file saved in bert-base-uncased-finetuned-sst2/checkpoint-8420/special_tokens_map.json The following columns in the evaluation set don't have a corresponding argument in `BertForSequenceClassification.forward` and have been ignored: sentence, idx. If sentence, idx are not expected by `BertForSequenceClassification.forward`, you can safely ignore this message. ***** Running Evaluation ***** Num examples = 872 Batch size = 16 Saving model checkpoint to bert-base-uncased-finetuned-sst2/checkpoint-12630 Configuration saved in bert-base-uncased-finetuned-sst2/checkpoint-12630/config.json Model weights saved in bert-base-uncased-finetuned-sst2/checkpoint-12630/pytorch_model.bin tokenizer config file saved in bert-base-uncased-finetuned-sst2/checkpoint-12630/tokenizer_config.json Special tokens file saved in bert-base-uncased-finetuned-sst2/checkpoint-12630/special_tokens_map.json The following columns in the evaluation set don't have a corresponding argument in `BertForSequenceClassification.forward` and have been ignored: sentence, idx. If sentence, idx are not expected by `BertForSequenceClassification.forward`, you can safely ignore this message. ***** Running Evaluation ***** Num examples = 872 Batch size = 16 Saving model checkpoint to bert-base-uncased-finetuned-sst2/checkpoint-16840 Configuration saved in bert-base-uncased-finetuned-sst2/checkpoint-16840/config.json Model weights saved in bert-base-uncased-finetuned-sst2/checkpoint-16840/pytorch_model.bin tokenizer config file saved in bert-base-uncased-finetuned-sst2/checkpoint-16840/tokenizer_config.json Special tokens file saved in bert-base-uncased-finetuned-sst2/checkpoint-16840/special_tokens_map.json The following columns in the evaluation set don't have a corresponding argument in `BertForSequenceClassification.forward` and have been ignored: sentence, idx. If sentence, idx are not expected by `BertForSequenceClassification.forward`, you can safely ignore this message. ***** Running Evaluation ***** Num examples = 872 Batch size = 16 Saving model checkpoint to bert-base-uncased-finetuned-sst2/checkpoint-21050 Configuration saved in bert-base-uncased-finetuned-sst2/checkpoint-21050/config.json Model weights saved in bert-base-uncased-finetuned-sst2/checkpoint-21050/pytorch_model.bin tokenizer config file saved in bert-base-uncased-finetuned-sst2/checkpoint-21050/tokenizer_config.json Special tokens file saved in bert-base-uncased-finetuned-sst2/checkpoint-21050/special_tokens_map.json Training completed. Do not forget to share your model on huggingface.co/models =) Loading best model from bert-base-uncased-finetuned-sst2/checkpoint-12630 (score: 0.9185779816513762). TrainOutput(global_step=21050, training_loss=0.10431196976727375, metrics={'train_runtime': 2929.8649, 'train_samples_per_second': 114.935, 'train_steps_per_second': 7.185, 'total_flos': 6090242903971080.0, 'train_loss': 0.10431196976727375, 'epoch': 5.0})
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
如何学习大模型 AI ?
由于新岗位的生产效率,要优于被取代岗位的生产效率,所以实际上整个社会的生产效率是提升的。
但是具体到个人,只能说是:
“最先掌握AI的人,将会比较晚掌握AI的人有竞争优势”。
这句话,放在计算机、互联网、移动互联网的开局时期,都是一样的道理。
我在一线互联网企业工作十余年里,指导过不少同行后辈。帮助很多人得到了学习和成长。
我意识到有很多经验和知识值得分享给大家,也可以通过我们的能力和经验解答大家在人工智能学习中的很多困惑,所以在工作繁忙的情况下还是坚持各种整理和分享。但苦于知识传播途径有限,很多互联网行业朋友无法获得正确的资料得到学习提升,故此将并将重要的AI大模型资料包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】
因篇幅有限,仅展示部分资料,需要点击下方链接即可前往获取
2024最新版CSDN大礼包:《AGI大模型学习资源包》免费分享!


第一阶段(10天):初阶应用
该阶段让大家对大模型 AI有一个最前沿的认识,对大模型 AI 的理解超过 95% 的人,可以在相关讨论时发表高级、不跟风、又接地气的见解,别人只会和 AI 聊天,而你能调教 AI,并能用代码将大模型和业务衔接。
- 大模型 AI 能干什么?
- 大模型是怎样获得「智能」的?
- 用好 AI 的核心心法
- 大模型应用业务架构
- 大模型应用技术架构
- 代码示例:向 GPT-3.5 灌入新知识
- 提示工程的意义和核心思想
- Prompt 典型构成
- 指令调优方法论
- 思维链和思维树
- Prompt 攻击和防范
- …
第二阶段(30天):高阶应用
该阶段我们正式进入大模型 AI 进阶实战学习,学会构造私有知识库,扩展 AI 的能力。快速开发一个完整的基于 agent 对话机器人。掌握功能最强的大模型开发框架,抓住最新的技术进展,适合 Python 和 JavaScript 程序员。
- 为什么要做 RAG
- 搭建一个简单的 ChatPDF
- 检索的基础概念
- 什么是向量表示(Embeddings)
- 向量数据库与向量检索
- 基于向量检索的 RAG
- 搭建 RAG 系统的扩展知识
- 混合检索与 RAG-Fusion 简介
- 向量模型本地部署
- …
第三阶段(30天):模型训练
恭喜你,如果学到这里,你基本可以找到一份大模型 AI相关的工作,自己也能训练 GPT 了!通过微调,训练自己的垂直大模型,能独立训练开源多模态大模型,掌握更多技术方案。
到此为止,大概2个月的时间。你已经成为了一名“AI小子”。那么你还想往下探索吗?
- 为什么要做 RAG
- 什么是模型
- 什么是模型训练
- 求解器 & 损失函数简介
- 小实验2:手写一个简单的神经网络并训练它
- 什么是训练/预训练/微调/轻量化微调
- Transformer结构简介
- 轻量化微调
- 实验数据集的构建
- …
第四阶段(20天):商业闭环
对全球大模型从性能、吞吐量、成本等方面有一定的认知,可以在云端和本地等多种环境下部署大模型,找到适合自己的项目/创业方向,做一名被 AI 武装的产品经理。
- 硬件选型
- 带你了解全球大模型
- 使用国产大模型服务
- 搭建 OpenAI 代理
- 热身:基于阿里云 PAI 部署 Stable Diffusion
- 在本地计算机运行大模型
- 大模型的私有化部署
- 基于 vLLM 部署大模型
- 案例:如何优雅地在阿里云私有部署开源大模型
- 部署一套开源 LLM 项目
- 内容安全
- 互联网信息服务算法备案
- …
学习是一个过程,只要学习就会有挑战。天道酬勤,你越努力,就会成为越优秀的自己。
如果你能在15天内完成所有的任务,那你堪称天才。然而,如果你能完成 60-70% 的内容,你就已经开始具备成为一名大模型 AI 的正确特征了。
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】
因篇幅有限,仅展示部分资料,需要点击下方链接即可前往获取
2024最新版CSDN大礼包:《AGI大模型学习资源包》免费分享!

