
- 1C++中map、hash_map、unordered_map、unordered_set通俗辨析
- 2大数据开发面试中常见sql题选辑_大数据 sql题
- 3图片放大后画质变模糊?教你一招无损放大图片_怎么把图片放大并保持清晰
- 4想让你的公众号拥有AI对话能力吗?那你一定不要错过这篇文章,手把手教你将Kimi大模型接入微信公众号,完全免费,只需要三分钟即可_公众号接入大模型
- 5国内外顶尖AI绘画软件大盘点-附详细教程_国内最强绘图ai
- 6用 Python 如何爬取股票信息
- 7微服务应用性能如何?APM监控工具来告诉你!
- 8BurpSuite v2024最新版本_burpsuite2024中文版下载
- 9推荐3个完美替代 Navicat 的工具_navicat替代软件mac
- 101.机顶盒晶晨s905l3b芯片--armbian安装Homeassistant之系统优化篇_armbian home
scrapy爬虫框架学习入门教程及实例_scrapy 爬取 接口
赞
踩
Scrapy是一个基于Twisted,纯Python实现的爬虫框架,用户只需要定制开发几个模块就可以轻松的实现一个爬虫,用来抓取网页内容以及各种图片,非常之方便~
Scrapy 使用 Twisted这个异步网络库来处理网络通讯,架构清晰,并且包含了各种中间件接口,可以灵活的完成各种需求。整体架构如下图所示:
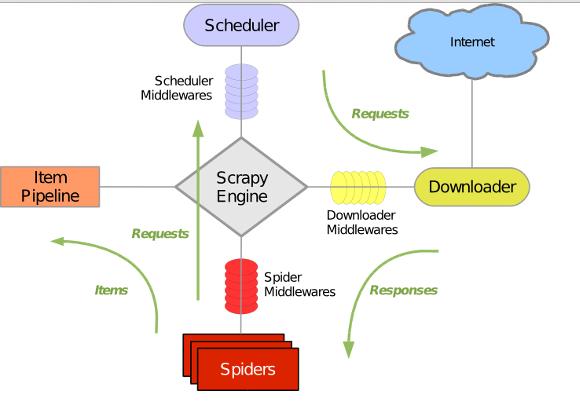
绿线是数据流向,首先从初始URL 开始,Scheduler 会将其交给 Downloader 进行下载,下载之后会交给 Spider 进行分析,Spider分析出来的结果有两种:一种是需要进一步抓取的链接,例如之前分析的“下一页”的链接,这些东西会被传回 Scheduler ;另一种是需要保存的数据,它们则被送到Item Pipeline 那里,那是对数据进行后期处理(详细分析、过滤、存储等)的地方。另外,在数据流动的通道里还可以安装各种中间件,进行必要的处理。
在本文中,我们将学会如何使用Scrapy建立一个爬虫程序,并爬取指定网站上的内容
1. 创建一个新的Scrapy Project
2. 定义你需要从网页中提取的元素Item
3.实现一个Spider类,通过接口完成爬取URL和提取Item的功能
4. 实现一个Item PipeLine类,完成Item的存储功能
爬取网址: 盗墓笔记小说 http://www.daomubiji.com/
爬取盗墓笔记小说 书的大标题 小标题 章节名称 第几章 章节网址
Step1: 新建scrapy工程
打开命令行 scrapy startproject 工程名称
建好工程,有以下几个文件
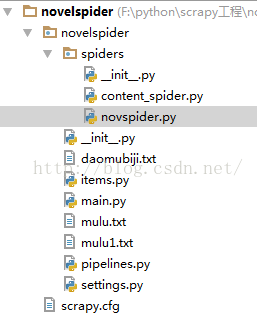
必有的文件 settings.py items.py pipelines.py __init__.py scrapy.cfg 及spider文件夹下 __init__.py 其它一些是自己后来添加的
scrapy.cfg: 项目配置文件
items.py: 需要提取的数据结构定义文件
pipelines.py:管道定义,用来对items里面提取的数据做进一步处理,如保存等
settings.py: 爬虫配置文件
spiders: 放置spider的目录
BOT_NAME = 'novelspider'
SPIDER_MODULES = ['n

