
- 1《关于我摸鱼一天后搞定PyCharm这档事》Python环境配置_pycharm摸鱼插件
- 2三维模型设计新纪元:3D开发工具HOOPS在机械加工行业的应用与优势
- 3python中requests如何使用代理_requests.get proxy
- 4Java开发Twitter爬虫抓取图片和视频并保存到本地_java 获取 twitter视频
- 5创建好的提示词来让 Stable Diffusion 生成 AI 艺术作品图像_stable diffusion 提示词生成
- 6程序猿面试时的65个技巧性回答_程序员面试技巧:如何讲解自己做过的项目
- 7学习记录:Ubuntu系统安装远程控制软件teamviewer_teamviewer ubuntu安装
- 8Linux系统编程中O_APPEND和O_TRUNC标志的使用方法。_o_append flag
- 9Linux-CentOS/统信UOS(v20-1060a/e)安装.net core 6.0运行环境_统信uos 1060a是基于centos8吗
- 10GPT2 & GPT3
纯干货全面解读AI框架RAG_rag ai
赞
踩

什么是RAG
RAG定义
RAG,即检索增强生成,英文Retrieval-Augmented Generation的缩写。
RAG可以通过将检索模型和生成模型结合在一起,从而提高了生成内容的相关性和质量。
通俗一点讲就是大模型LLM如何很好的与外部知识源结合在一起, 使其生成的内容质量更高,缓解大模型LLM生成内容「幻觉」的问题。
检索模型
检索模型旨在从一组给定的文档或知识库中检索相关信息。
检索模型的工作就像是在一个巨大的图书馆中寻找信息。设想你有成千上万本书籍和文章,当你提出一个问题时,检索模型就像一个聪明的图书管理员,能迅速理解你的问题并找到与之最相关的最佳信息。
检索的核心分为如下两部分:
- 索引:嵌入(Embeddings),将知识库转换为可搜索/查询的内容。
- 查询:从搜索内容中提取最相关的、最佳知识片段。
生成模型
生成模型指的是大型语言模型LLM,例如chatGPT。生成模型是实现高质量、高相关性内容生成的关键。它不仅利用自身的强大语言生成能力,还结合检索模型提供的确切信息,以生成更准确、更丰富的内容。
简单来说,检索模型擅长"找"信息,生成模型擅长"创造"内容。
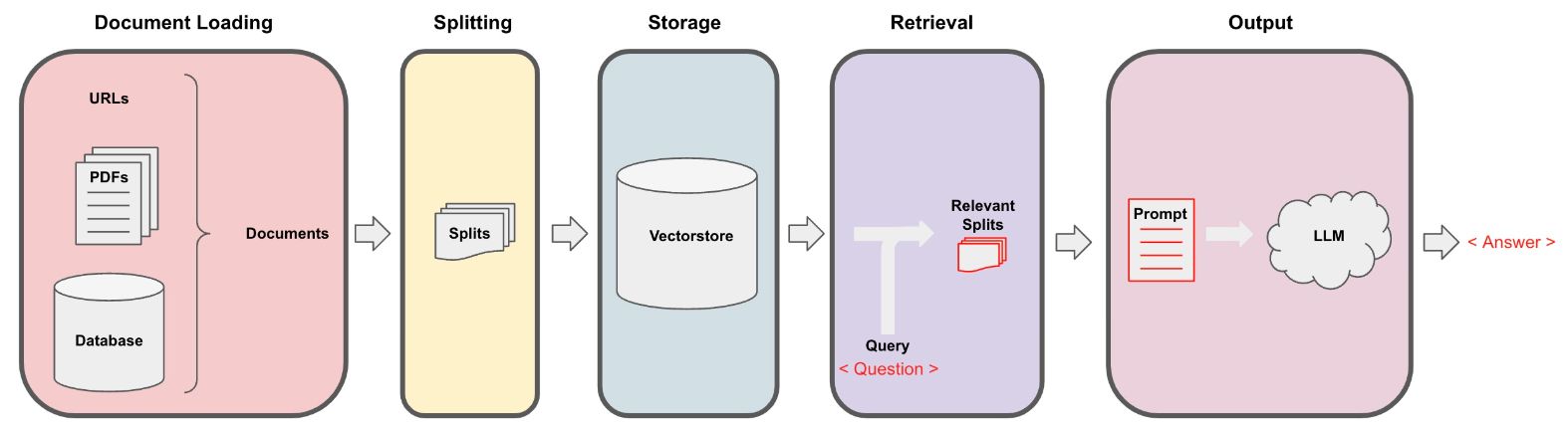
执行流程
执行流程图
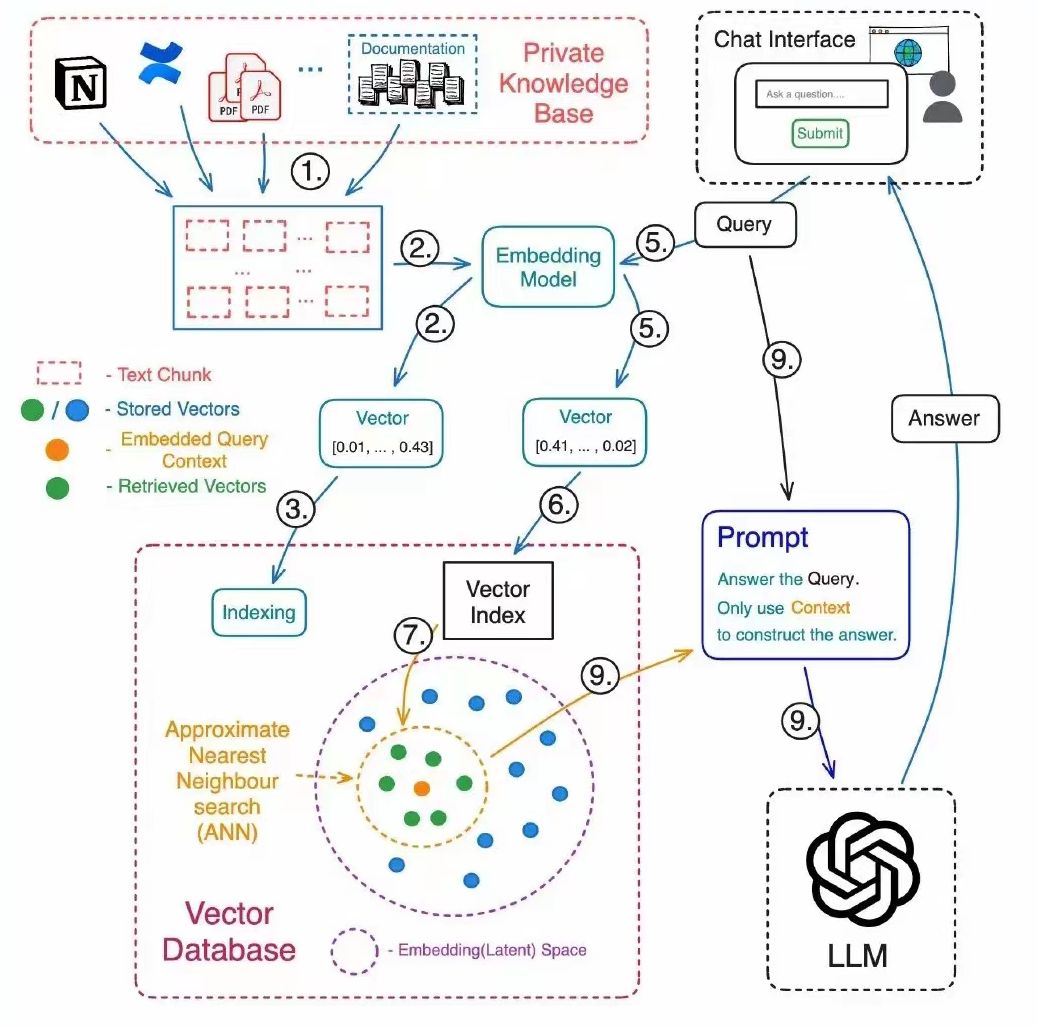
索引生成部分
文档处理:将私有知识库中的文档转换成可以处理的文本块。
嵌入模型:使用嵌入模型(如BERT、GPT等)将文本块转换成向量。
索引:创建文本块向量的索引,以便能够快速检索。
数据库:嵌入向量被存储在一个向量数据库中,通常使用近似最近邻(ANN)搜索来优化检索速度。
用户问答部分
查询:用户在聊天界面输入查询。
查询嵌入:查询也被转换成向量,以便与文档的嵌入向量进行比较。
检索向量:查询的向量在向量索引中被用来找出最相近的文本块向量,最相近的文本块向量代表了与用户查询最相关的知识片段。
提示和回答:生成模型(LLM)接收到用户的查询和检索到的知识片段,然后生成回答。这个回答既包含了用户查询的上下文,也融合了从知识库中检索到的信息。
RAG的作用
保持知识更新
将大型语言模型(LLM)如ChatGPT配备能够随时查阅最新资讯的能力,就好比为它安装了一对能够观察现实世界的“眼睛”。这种能力的增加不仅极大地扩展了模型的知识范围,还提高了其与现实世界同步的能力,让它能够更有效地参与到关于时事的对话中。
提供专业知识
如果你的问题涉及特定的专业领域,RAG就像一个熟练的图书管理员,它不仅掌握着大量的专业书籍,还能够迅速而准确地从这些书籍中找到与你的问题最相关的答案。这样的能力使得RAG在处理复杂和专业性问题时表现出色。
私有知识的安全
随着人工智能的发展,数据安全成为了企业关注的重点。对于企业而言,将长期累积的独有的知识库、敏感的经营数据、合同文件等机密信息上传到互联网上的大型模型可能会带来安全风险。在这种背景下,RAG技术提供了一种有效的解决方案。
增加可信度
RAG赋予机器人在回答问题时提供信息来源的能力,这是一个重要的特性。当你向机器人提问时,它不仅能给出答案,还能明确告诉你这些答案是基于哪些资料或数据得出的。这种透明度极大地增加了机器人提供的信息的可信度,并帮助用户区分信息的真实性和准确性。
减少大模型LLM的“幻觉”
大型语言模型(如GPT系列)在生成文本时偶尔出现的“幻觉”(hallucination)现象,是由于模型在处理特定查询时,可能会生成不准确、不相关或虚构的信息。这种现象往往发生在模型对于回答问题所需的知识不了解或不熟悉的情况下。RAG的出现,通过利用外部知识源,可以有效地弥补这一缺陷。
面临的挑战
RAG在实施过程中确实面临着多项挑战,其中包括嵌入质量、性能优化和上下文理解。这些难点不仅关系到RAG系统的效率,还直接影响到最终生成文本的准确性和可用性。
提升嵌入的质量
将外部知识源转换为向量时,需要保证嵌入(embedding)的高质量至关重要,这一过程对于提高查询与知识库信息匹配的准确性至关重要。技术上,这要求嵌入能够捕获和保留文本的深层语义特征,包括上下文关系和词汇间的微妙联系。
此外,为了避免训练过程中的数据偏见,需要用到平衡和多样化的数据集。只有这样,通过嵌入生成的向量才能真正代表原始文本的意图和内容,从而在查询时提供更准确、更相关的结果。
查找精确知识的挑战
从外部知识源中准确地查找与当前问题最匹配的知识是一个复杂的挑战。这要求大模型LLM能够深入理解用户查询的真实意图,同时利用高效的检索算法在庞大的数据集中快速定位相关信息。此外,确保检索结果的相关性和质量,以及处理大量数据的能力,也是这一挑战的关键部分。同时,系统还需要适应模糊或复杂的查询,并保持知识库的时效性和准确性。
上下文内容的理解
上下文理解是一个核心挑战,要求生成模型不仅深入理解检索到的上下文信息,包括其隐含含义和语境;
在理解检索到的内容后,挑战在于如何将这些信息与原始查询请求以及模型已有的知识库相结合。这要求模型能够在回答生成过程中,不仅准确地引用检索信息,还要保证信息的连贯性和逻辑性。
上下文理解的挑战要求RAG在处理和生成回答时,能够展现出高度的理解能力和灵活的信息整合能力。这对于提升回答的质量和用户满意度至关重要。
应用场景
RAG在未来的应用前景非常广阔,几乎覆盖了所有企业和行业。这是因为RAG能够结合大型语言模型的强大处理能力和企业或行业自身独有的知识体系,从而制定出行业或企业专属的AI解决方案。无论是金融、医疗、法律、教育,还是零售、制造、娱乐等行业,企业都可以利用RAG技术构建专门的小型模型,以满足特定的业务需求。
医疗行业
在医疗领域,RAG可以被用作临床决策支持工具。通过结合医学数据库和研究论文,RAG能够帮助医生快速获得关于疾病诊断、治疗方案和药物信息的最新研究。例如,对于罕见病的诊断,RAG可以通过检索最新的医学文献和病例报告,提供可能的诊断建议和治疗方法。
法律行业
在法律行业,RAG可以辅助律师进行案例研究和提供法律咨询。通过访问法律数据库和历史案例,RAG能够帮助律师找到相关的法律先例和法规,从而提高案件分析的效率和准确性。这对于处理复杂的法律问题,如知识产权纠纷或国际法案,尤为有用。
教育领域
在教育领域,RAG可以作为学习资源和研究辅助工具。教师和学生可以利用RAG快速访问大量的教育资料、学术论文和案例研究,从而丰富教学内容和加深学习理解。例如,学生在准备论文时,可以用RAG来查找相关的研究工作和理论框架。
- 1.写wxml页面:
[详细] -->赞
踩

