
- 1pandas中的滚动窗口rolling函数和扩展窗口expanding函数_pandas rolling()的参数
- 2Python3对一个class类型的list按class中某一属性排序_python如何按照class的某个值排序
- 3TransReID: Transformer-based Object Re-Identification 介绍
- 4php如何实现在线直播系统,设计方案以及简单实现(此方案 app与pc端一致)---》第一篇
- 5PyTorch 最新安装教程_pytorch最新版本安装
- 6【软件安装】CUDA的卸载_cuda卸载
- 7新东方人工智能中台建设和AI部门管理经验分享_新东方数据中台
- 8迭代器详解
- 9假如C++是一只箭,你会用它来射哪只雕?| 就业岗位分享
- 10SqlSugar ORM 入门(简介和增删查改)
Elasticsearch与Postgresql大数据检索性能对比与融合_progresssql vs es
赞
踩
Elasticsearch与Postgresql大数据检索性能对比与融合
一般来说,影响数据库最大的性能问题有两个,一个是对数据库的读写操作,一个是数据库中的数据太大导致操作慢,对于前者我们可以适当借助缓存来减少一部分读操作,而针对一些复杂的报表分析和搜索可以交给hadoop和elasticsearch,对于写并发大,读也并发大,我们可以考虑分库分表,主从读写分离或者两者结合等方式来提高并发性和时效性,例如PG大并发写,大数据查看可以用elasticsearch与PG数据同步来读,可以启到很好的效果。
ElasticSearch做为搜索服务器,在性能上确实优势突出,是当前流行的企业级搜索引擎。它提供了一个分布式多用户能力的全文搜索引擎,基于RESTful web接口。主要用于实时搜索和分析引擎,,支持对结构化数据和非结构数据处理检索。
例如,我们使用的数据库时Postgres数据库,主从配置,从库主要用于数据分析检索为主,如果使用postgres进行多表多维度全量方式检索分析用户行为等挖掘有价值的数据,这样性能上无法及时满足客户时时性要求,因此我们可以使用Elasticsearch数据库代替PG从库做为挖掘分析数据库,使用过程中发现两者表与数据的兼容性都还不错,而且展现数据的性能确实快,
如下图是同一张表数据在postgres数据库中对应的表,在Elasticsearch数据库中对应,说明数据是兼容的。
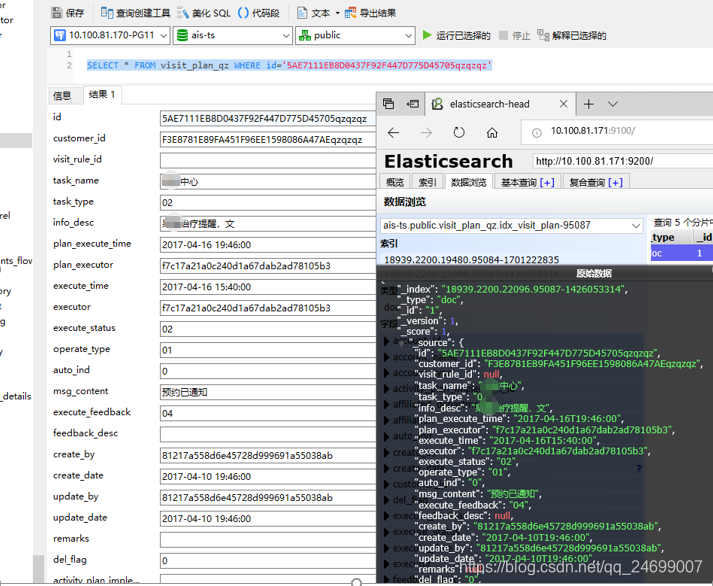
而在postgres数据库中针对visit_plan_qz 表3073920笔数据进行全量查询,耗时大于5分钟都无法正常展现出来,

如果使用Elasticsearch进程全量查询仅使用0.0005秒就可以展现出数据,当然Elasticsearch会自动对该表划分为5个分片来展现数据。

工作原理:
PG关系数据库 ⇒ 数据库 ⇒ 表 ⇒ 行 ⇒ 列(Columns)
Elasticsearch ⇒ 索引(Index) ⇒ 类型(type) ⇒ 文档(Docments) ⇒ 字段(Fields)
可以看出Elasticsearch性能上的优势在索引,它提供强大的索引能力,Elasticsearch 是通过 Lucene 的倒排索引技术实现比关系型数据库更快的过滤
Elasticsearch的索引思路:将磁盘里的东西尽量搬进内存,减少磁盘随机读取次数(同时也利用磁盘顺序读特性),结合各种算法,用及其苛刻的态度使用内存。

