
- 1Python爬虫解析器BeautifulSoup4_python beautifulsoup4
- 2如何训练一个高效的GPT模型
- 3VMware 16新建虚拟机CentOS 64 以及启动配置_vm16虚拟机
- 4电子课程设计 - 基于51单片机的停车场车位管理系统_基于单片机的停车场管理系统
- 5VS跨平台开发框架DevExtreme使用教程:在XAF应用中使用DevExtreme Widgets_devexpress exteme vs
- 6查看Anaconda版本、Anaconda和python版本对应关系和快速下载_anaconda版本推荐
- 7计算机科学的知识单元,计算机科学-的技术专业知识点体系-课程体系.ppt
- 8switch与if效率实例解析·5年以下编程经验必看【C#】_c#做一次if判断要多长时间
- 9python统计一组图片的均值与标准差_mean(axis=0,keepdims=true)
- 10比肩ChatGPT的国产AI:文心一言——有话说_ai有话说
python 实现基于用户的协同过滤算法_python协同过滤算法
赞
踩
一、算法思想
基于用户的协同过滤算法的思想是有相似兴趣的用户(user)可能会喜欢相同的物品(item)。因此,计算用户的相似度成为该算法的关键步骤。本文实现过程中使用的相似度公式如下:
ω
u
v
=
N
(
u
)
⋂
N
(
v
)
N
(
u
)
∗
N
(
v
)
\omega_{uv}=\frac{N(u)\bigcap N(v)}{\sqrt{N(u)*N(v)}}
ωuv=N(u)∗N(v)
N(u)⋂N(v)
其中 N(u) 表示用户 u 看过的电影个数。
二、实现思路
- 数据集
本实现使用的数据集为 MovieLens 提供的数据:

下载地址:MovieLens数据集
加载解压后为:

我们使用 ml-latest-small 文件夹下的 ratings.csv 文件:
该数据集中的数据格式为:
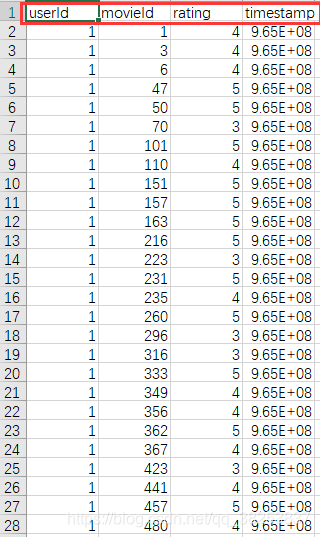
userId : 用户 ID
movieId : 用户看过的电影 ID
rating : 用户对所看电影的评分
timestap : 用户看电影的时间戳
- 定义变量
N : 记录用户看过的电影数量,如: N[“1”] = 10 表示用户 ID 为 “1” 的用户看过 10 部电影;
W : 相似矩阵,存储两个用户的相似度,如:W[“1”][“2”] = 0.66 表示用户 ID 为 “1” 的用户和用户 ID 为 “2” 的用户相似度为 0.66 ;
train : 用户记录数据集中的数据, 格式为: train= { user : [[item1, rating1], [item2, rating2], …], …… }
item_users : 将数据集中的数据转换为 物品_用户 的倒排表,这样做的原因是在计算用户相似度的时候,可以只计算看过相同电影的用户之间的相似度(没看过相同电影的用户相似度默认为 0 ),倒排表的形式为: item_users = { item : [user1, user2, …], ……}
k : 使用最相似的 k 个用户作推荐
n : 为用户推荐 n 部电影
- 加载数据
从数据集中读出数据,将数据以 { user : [[item1, rating1], [item2, rating2], …],……} 的形式存入 train 中,并整理成形如 { item : [user1, user2, …], ……} 的倒排表,存入 item_users 中。 - 计算相似度矩阵
遍历 item_users ,统计每个用户看过的电影 item 的次数,同时遍历 item_users 中的 users ,先计算用户 u 和用户 v 看过相同电影的个数存在 W 中, 然后遍历 W ,使用上述公式计算用户 u 和用户 v 的相似度。 - 推荐
最后为用户 u 推荐,首先从 item_users 中获得用户 u 已经看过的电影,然后将用户按相似度排序,并取前 k 个用户,对这 k 个用户看过但用户 u 没有看过的电影计算加权评分和,计算公式为:用户相似度 * 用户对电影的评分。
三、源代码
""" @description: a demo for user-based collaborative filtering @author: Chengcheng Zhao @date: 2020-11-15 15:21:13 """ import random import operator class UserBasedCF: def __init__(self): self.N = {} # number of items user interacted, N[u] = the number of items user u interacted self.W = {} # similarity of user u and user v self.train = {} # train = { user : [[item1, rating1], [item2, rating2], …], …… } self.item_users = {} # item_users = { item : [user1, user2, …], …… } # recommend n items from the k most similar users self.k = 30 self.n = 10 def get_data(self, file_path): """ @description: load data from dataset @file_path: path of dataset """ with open(file_path, 'r') as f: for i, line in enumerate(f, 0): if i != 0: # remove the title of the first line line = line.strip('\n') user, item, rating, timestamp = line.split(',') self.train.setdefault(user, []) self.train[user].append([item, rating]) self.item_users.setdefault(item, []) self.item_users[item].append(user) def similarity(self): """ @description: calculate similarity between user u and user v """ for item, users in self.item_users.items(): for u in users: self.N.setdefault(u, 0) self.N[u] += 1 for v in users: if u != v: self.W.setdefault(u, {}) self.W[u].setdefault(v, 0) self.W[u][v] += 1 # number of items which both user u and user v have interacted for u, user_cnts in self.W.items(): for v, cnt in user_cnts.items(): self.W[u][v] = self.W[u][v] / (self.N[u] * self.N[v]) ** 0.5 # similarity between user u and user v def recommendation(self, user): """ @description: recommend items for user @param user : the user who is recommended, we call this user u @return : items recommended for user u """ watched = [i[0] for i in self.train[user]] # items that user have interacted rank = {} for v, similar in sorted(self.W[user].items(), key=operator.itemgetter(1), reverse=True)[0:self.k]: # order user v by similarity between user v and user u for item_rating in self.train[v]: # items user v have interacted if item_rating[0] not in watched: # item user hvae not interacted rank.setdefault(item_rating[0], 0.) rank[item_rating[0]] += similar * float(item_rating[1]) return sorted(rank.items(), key=operator.itemgetter(1), reverse=True)[0:self.n] if __name__ == "__main__": file_path = "C:\\Users\\DELL\\Desktop\\code\\python\\dataset\\ml-latest-small\\ratings.csv" userBasedCF = UserBasedCF() userBasedCF.get_data(file_path) userBasedCF.similarity() user = random.sample(list(userBasedCF.train), 1) rec = userBasedCF.recommendation(user[0]) print(rec)

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
四、代码运行结果
程序随机选择一位用户,根据和他最相似的 30 个用户,为其推荐 10 部电影,打印出推荐电影的 ID 和加权评分 [[电影ID, 加权评分],[电影ID,加权评分],……]。

源代码地址:基于用户的协同过滤算法的 python 实现
参考资料:《推荐系统实践》——项亮


