- 1linux环境下安装gitlab_linux gitlab 中文版 安装
- 2通过威纶通触摸屏的穿透功能实现对FX3U系列PLC程序的上传下载和监控的具体方法_威纶通穿透连接三菱plc
- 3大数据队列Kafka
- 4扩散模型(Diffusion Model)最新综述!
- 5SENet解析
- 6Android更换默认主题_theme.materialcomponents.daynight.darkactionbar
- 7深入Vue响应式
- 8一文看尽 CVPR 2022 最新 20 篇 Oral 论文
- 9我的第一个Android应用小程序_android小程序
- 10浙大版《C语言程序设计实验与习题指导(第3版)》题目集 实验11-1-9 藏尾诗 (20分)_7-13 藏尾诗 分数 20 作者 c课程组 单位 浙江大学 本题要求编写一个解密藏尾诗的
Pandas处理Excel文件的操作_pd.read_excel
赞
踩
关于Pandas的基本介绍
Series
Pandas Series 类似表格中的一个列(column),类似于一维数组,可以保存任何数据类型。
Series 由索引(index)和列组成,函数如下:
pandas.Series( data, index, dtype, name, copy)
参数说明:
-
data:一组数据(ndarray 类型)。
-
index:数据索引标签,如果不指定,默认从 0 开始。
-
dtype:数据类型,默认会自己判断。
-
name:设置名称。
-
copy:拷贝数据,默认为 False。
创建一个简单的Series实例:
- import pandas as pd
-
-
- a = [1, 2, 3]
- myvar = pd.Series(a)
-
-
- print(myvar)
输出结果如下

如果不指定索引就从0开始
关于series仅作一个概念介绍,详细可自行了解
DataFrame
DataFrame 是一个表格型的数据结构,它含有一组有序的列,每列可以是不同的值类型(数值、字符串、布尔型值)。DataFrame 既有行索引也有列索引,它可以被看做由 Series 组成的字典(共同用一个索引)。


DataFrame 构造方法如下:
pandas.DataFrame( data, index, columns, dtype, copy)
参数说明
-
data:一组数据(ndarray、series, map, lists, dict 等类型)。
-
index:索引值,或者可以称为行标签。
-
columns:列标签,默认为 RangeIndex (0, 1, 2, …, n) 。
-
dtype:数据类型。
-
copy:拷贝数据,默认为 False。
Pandas DataFrame 是一个二维的数组结构,类似二维数组。
创建DataFrame
使用列表创建
- import pandas as pd
-
-
- data = [['Google',10],['Runoob',12],['Wiki',13]]
-
-
- df = pd.DataFrame(data,columns=['Site','Age'],dtype=float)
-
-
- print(df)
输出结果:

使用 ndarrays 创建
- import pandas as pd
-
-
- data = {'Site':['Google', 'Runoob', 'Wiki'], 'Age':[10, 12, 13]}
-
-
- df = pd.DataFrame(data)
-
-
- print (df)
输出结果:

使用字典创建
其中字典的 key 为列名:
- import pandas as pd
-
-
- data = [{'a': 1, 'b': 2},{'a': 5, 'b': 10, 'c': 20}]
-
-
- df = pd.DataFrame(data)
-
-
- print (df)
输出结果:
- a b c
- 0 1 2 NaN
- 1 5 10 20.0
没有对应的部分数据为 NaN
具体用法
首先需要安装pandas并导入pandas库
pip install pandasimport pandas as pd
读取excel
想要运用好pandas需要先了解有哪些参数
参数
read_excel函数能够读取的格式包含:xls, xlsx, xlsm, xlsb, odf, ods 和 odt 文件扩展名。支持读取单一sheet或几个sheet。
官方文档中提供的全部参数信息:
-
io:文件路径,支持 str, bytes, ExcelFile, xlrd.Book, path object, or file-like object。默认读取第一个sheet的内容。案例:"/desktop/student.xlsx"
-
sheet_name:sheet表名,支持 str, int, list, or None;默认是0,索引号从0开始,表示第一个sheet。案例:sheet_name=1, sheet_name="sheet1",sheet_name=[1,2,"sheet3"]。None 表示引用所有sheet
-
header:表示用第几行作为表头,支持 int, list of int;默认是0,第一行的数据当做表头。header=None表示不使用数据源中的表头,Pandas自动使用0,1,2,3…的自然数作为索引。
-
names:表示自定义表头的名称,此时需要传递数组参数。在header=None的前提下,补充列名
-
index_col:指定列属性为行索引列,支持 int, list of int, 默认是None,也就是索引为0,1,2,3等自然数的列用作DataFrame的行标签。如果传入的是列表形式,则行索引会是多层索引
-
usecols:待解析的列,支持 int, str, list-like, or callable ,默认是 None,表示解析全部的列。
-
dtype:指定列属性的字段类型。案例:{‘a’: np.float64, ‘b’: np.int32};默认为None,也就是不改变数据类型。
-
engine:解析引擎;可以接受的参数有"xlrd"、"openpyxl"、"odf"、"pyxlsb",用于使用第三方的库去解析excel文件
-
“xlrd”支持旧式 Excel 文件 (.xls)
-
“openpyxl”支持更新的 Excel 文件格式
-
“odf”支持 OpenDocument 文件格式(.odf、.ods、.odt)
-
“pyxlsb”支持二进制 Excel 文件
-
converters:对指定列进行指定函数的处理,传入参数为列名与函数组成的字典,和usecols参数连用。key 可以是列名或者列的序号,values是函数,可以自定义的函数或者Python的匿名lambda函数
-
skiprows:跳过指定的行(可选参数),类型为:list-like, int, or callable
-
nrows:指定读取的行数,通常用于较大的数据文件中。类型int, 默认是None,读取全部数据
-
na_values:指定列的某些特定值为NaN
-
keep_default_na:是否导入空值,默认是导入,识别为NaN
本篇仅介绍部分常用的参数
运用参数
默认情况
此时文件刚好在当前目录下,读取的时候指定文件名即可,读取的是第一个sheet
df = pd.read_excel("name.xlsx")或者可以加入dataframe使用
df = pd.DataFrame(pd.read_excel('name.xlsx'))
文件路径 参数io
填写完整的文件路径作为io的取值。也可以使用相对路径
pd.read_excel(r"/Users/peter/Desktop/pandas/Pandas-Excel.xls")
选择子表 参数sheet_name
- # pd.read_excel("Pandas-Excel.xls", sheet_name=0) # 效果同上
-
-
- # 直接指定sheet的名字
- pd.read_excel("Pandas-Excel.xls", sheet_name="Sheet1") # 效果同上
值为数字:读取第x个sheet 值为字符串(表名):读取指定名称的sheet
选择索引 参数header 参数index_col
header=None表示不使用数据源中的表头,Pandas自动使用0,1,2,3…的自然数作为索引。
- df = pd.read_excel('./data/sample.xlsx', header=None)
- print(df)
- # 0 1 2 3
- # 0 NaN A B C
- # 1 one 11 12 13
- # 2 two 21 22 23
- # 3 three 31 32 33
-
-
- print(df.columns)
- # Int64Index([0, 1, 2, 3], dtype='int64')
- print(df.index)
- # RangeIndex(start=0, stop=4, step=1)
默认为 header = 0(= 第一行是列名),设置为整数 i 则表示设置i行为列标签,i行之前的数据会被舍弃。

比如这种有标题的表格,如果不设置header(即header=0)则读出来的表格为
- title Unnamed: 1 Unnamed: 2
- 0 id value1 value2
- 1 1900-01-01 00:00:00 23 56
- 2 1900-01-02 00:00:00 33 45
- 3 1900-01-03 00:00:00 43 34
- 4 1900-01-04 00:00:00 53 23
如果要舍弃第一行标题,设置为header=1即可
- id value1 value2
- 0 1900-01-01 23 56
- 1 1900-01-02 33 45
- 2 1900-01-03 43 34
- 3 1900-01-04 53 23
index_col = None(= 没有指定列作为索引)。
- df_default = pd.read_excel('./data/sample.xlsx')
- print(df_default)
- # Unnamed: 0 A B C
- # 0 one 11 12 13
- # 1 two 21 22 23
- # 2 three 31 32 33
-
-
- print(df_default.columns)
- # Index(['Unnamed: 0', 'A', 'B', 'C'], dtype='object')
-
-
- print(df_default.index)
- # RangeIndex(start=0, stop=3, step=1)
如果要将第一列设置为索引,可以显式设置 index_col = 0
指定列名 参数names
在header=None的前提下,补充指定列名
pd.read_excel("Pandas-Excel.xls", names=["a","b","c","d","e"])
读取部分列 参数usecols
用于读取指定的列,默认为None表示读取全部列,读取第2-4列usecols = [1,2,3],也可以直接指定名称
表df=pd.read_excel(io='./data.xls',index_col=[0])
- name count socre sum
- date
- 2017-01-01 mpg 15 1.506 1.330
- 2017-01-02 asd 18 1.533 1.359
- 2017-01-03 puck 20 1.537 1.365
- 2017-01-04 #N 24 1.507 1.334
- 2017-01-05 NaN 27 1.498 1.325
- 2017-01-06 some 30 1.506 1.329
字符串"A,C:D":表示选择excel字母列的A列,和C到D列;
- # 选择部分列读取(字符串形式)
- pd.read_excel(io='./data.xlsx',usecols="A,C:D")
-
-
- date count socre
- 0 2017_1_1 15 1.506
- 1 2017_1_2 18 1.533
- 2 2017_1_3 20 1.537
- 3 2017_1_4 24 1.507
- 4 2017_1_5 27 1.498
- 5 2017_1_6 30 1.506
字符列表["date","name"]:表示选择数据的date列和name列;
- # 选择部分列读取(字符列表形式)
- pd.read_excel(io='./data.xlsx',usecols=['date','name'])
-
-
- date name
- 0 2017_1_1 mpg
- 1 2017_1_2 asd
- 2 2017_1_3 puck
- 3 2017_1_4 #N
- 4 2017_1_5 NaN
- 5 2017_1_6 some
整数列表[0,2]:表示选择数据的0列和2列;
- # 选择部分列读取(整数列表形式)
- pd.read_excel(io='./data.xlsx',usecols=[0,2])
-
-
- date count
- 0 2017_1_1 15
- 1 2017_1_2 18
- 2 2017_1_3 20
- 3 2017_1_4 24
- 4 2017_1_5 27
- 5 2017_1_6 30
函数lambda x:x.endswith("e"):表示选择以字母e结尾的所有列
- # 选择部分列读取(函数形式)
- pd.read_excel(io='./data.xlsx',usecols=lambda x:x.endswith("e"))
-
-
- date name socre
- 0 2017_1_1 mpg 1.506
- 1 2017_1_2 asd 1.533
- 2 2017_1_3 puck 1.537
- 3 2017_1_4 #N 1.507
- 4 2017_1_5 NaN 1.498
- 5 2017_1_6 some 1.506
或者usecols=lambda x: "a" in x:表示选择字段中包含a的列
读取部分行 参数nrows 参数skiprows
设置参数nrows=n,可以读取数据的前n行。nrows默认None,表示读取全部行。
- # 选择前3行读取
- pd.read_excel(io='./data.xlsx',nrows=4)
-
-
- date name count socre sum
- 0 2017_1_1 mpg 15 1.506 1.330
- 1 2017_1_2 asd 18 1.533 1.359
- 2 2017_1_3 puck 20 1.537 1.365
- 3 2017_1_4 #N 24 1.507 1.334
-
-
设置skiprows参数,可以跳过部分行不读取。skiprows默认None,表示不跳过。
- # 跳过1,3行不读取
- pd.read_excel(io='./data.xlsx',skiprows=[1,3])
-
-
- date name count socre sum
- 0 2017_1_2 asd 18 1.533 1.359
- 1 2017_1_4 #N 24 1.507 1.334
- 2 2017_1_5 NaN 27 1.498 1.325
- 3 2017_1_6 some 30 1.506 1.329
可以设置skiprows参数为匿名函数,更加灵活的跳过部分行不读取。
- # 跳过部分行不读取(行索引包含[4,5])
- pd.read_excel(io='./data.xlsx',skiprows=lambda x:x in [4,5])
-
-
- date name count socre sum
- 0 2017_1_1 mpg 15 1.506 1.330
- 1 2017_1_2 asd 18 1.533 1.359
- 2 2017_1_3 puck 20 1.537 1.365
- 3 2017_1_6 some 30 1.506 1.329
处理excel表中数据
Dataframe提取数据的方法:excel转字典
to_dict() 函数基本语法
DataFrame.to_dict (self, orient='dict' , into= )
函数种只需要填写一个参数:orient 即可 ,但对于写入orient的不同,字典的构造方式也不同,官网一共给出了6种,并且其中一种是列表类型:
-
orient ='dict',是函数默认的,转化后的字典形式:{column(列名) : {index(行名) : value(值) )}};
-
orient ='list' ,转化后的字典形式:{column(列名) :{[ values ](值)}};
-
orient ='series' ,转化后的字典形式:{column(列名) : Series (values) (值)};
-
orient ='split' ,转化后的字典形式:{'index' : [index],‘columns' :[columns],’data‘ : [values]};
-
orient ='records' ,转化后是 list形式:[{column(列名) : value(值)}......{column:value}];
-
orient ='index' ,转化后的字典形式:{index(值) : {column(列名) : value(值)}};
备注:上面中 value 代表数据表中的值,column表示列名,index 表示行名,如下图所示:
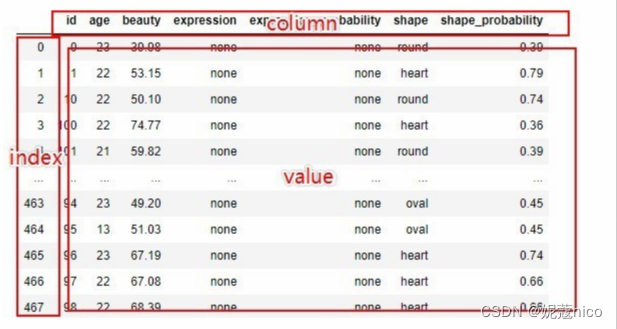
to_dict()函数的代码实例
实际上述六种构造方式所处理 DataFrame 数据是统一的,如下:
(意思就是数据源统一,创建的DataFrame是一样的)
- df =pd.DataFrame({'col_1':[1,2],'col_2':[0.5,0.75]},index =['row1','row2'])
-
-
- col_1 col_2
- row1 1 0.50
- row2 2 0.75
1.orient ='dict' — {column(列名) : {index(行名) : value(值) )}}
orient = 'list' 时,可以很方面得到 在某一列 各值所生成的列表集合,例如我想得到col_2 对应值得列表
- >>> df.to_dict('dict')
- {'col_1': {'row1': 1, 'row2': 2}, 'col_2': {'row1': 0.5, 'row2': 0.75}}
-
-
- #orient = 'dict' 可以很方便得到 在某一列对应的行名与各值之间的字典数据类型,例如在源数据上面我想得到在col_1这一列行名与各值之间的字典,直接在生成字典查询列名为col_1
- >>> df.to_dict('dict')['col_1']
- {'row1': 1, 'row2': 2}
2.orient ='list' — {column(列名) :{[ values ](值)}};
生成字典中 key为各列名,value为各列对应值的列表
- >>> df.to_dict('list')
- {'col_1': [1, 2], 'col_2': [0.5, 0.75]}
3.orient ='series' — {column(列名) : Series (values) (值)};
orient ='series' 与 orient = 'list' 唯一区别就是,这里的 value 是 Series数据类型,而前者为列表类型
- >>> df.to_dict('series')
- {'col_1': row1 1
- row2 2
- Name: col_1, dtype: int64, 'col_2': row1 0.50
- row2 0.75
- Name: col_2, dtype: float64}
4.orient ='split' — {'index' : [index],‘columns' :[columns],’data‘ : [values]};
orient ='split' 得到三个键值对,列名、行名、值各一个,value统一都是列表形式;
- >>> df.to_dict('split')
- {'index': ['row1', 'row2'], 'columns': ['col_1', 'col_2'], 'data': [[1, 0.5], [2, 0.75]]}
orient = 'split' 可以很方便得到DataFrame数据表中全部列名或者行名的列表形式,例如我想得到全部列名:
- >>> df.to_dict('split')['columns']
- ['col_1', 'col_2']
5.orient ='records' — [{column:value(值)},{column:value}....{column:value}];
注意的是,orient ='records' 返回的数据类型不是 dict ; 而是list 列表形式,由全部列名与每一行的值形成一一对应的映射关系:
- >>> df.to_dict('records')
- [{'col_1': 1, 'col_2': 0.5}, {'col_1': 2, 'col_2': 0.75}]
6.orient ='index' — {index:{culumn:value}};
orient ='index'与2.1用法刚好相反,求某一行中列名与值之间一一对应关系(查询效果与2.5相似):
- >>> df.to_dict('index')
- {'row1': {'col_1': 1, 'col_2': 0.5}, 'row2': {'col_1': 2, 'col_2': 0.75}}
-
- #查询行名为 row2 列名与值一一对应字典数据类型
- >>> df.to_dict('index')['row2']
- {'col_1': 2, 'col_2': 0.75}
输出到excel文件
此部分用到dataframe
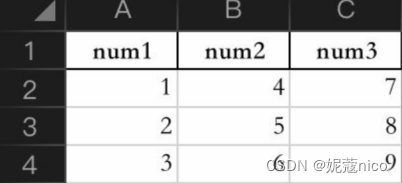
简单模拟一份数据
- df2 = pd.DataFrame({"num1":[1,2,3],
- "num2":[4,5,6],
- "num3":[7,8,9]})
- print(df2)
-
- num1 num2 num3
- 0 1 4 7
- 1 2 5 8
- 2 3 6 9
输出到excel
df2.to_excel("newdata_1.xlsx")
效果如下:

如果不想要索引号:
df2.to_excel("newdata_2.xlsx",index=False)