
- 1计算机专业转教育技术,转现代教育技术试题.doc
- 2Android平台架构和Android Framework的区别
- 3ESXI 7.0 安装 MacOS_esxi装苹果
- 4已知深度图,获得某个像素点的三维坐标_像素坐标 根据深度信息 得到 3维点
- 5CrossOver 22中文版本更新上线功能介绍_crossover arm
- 6c语言中如何将以IEEE754标准显示的int型变量转换float型变量_flutter int32 转ieee754
- 7push发出去php,unipush 服务端PHP不能离线发送
- 8鸿蒙系统基于安卓是什么意思,华为鸿蒙系统基于安卓还是Linux呢?
- 9PyQt5 实战记录1 如何进行资源打包_pyqt5 打包 图片
- 10mips汇编基础与解析_汇编jarl
今日arXiv最热NLP论文:Meta重磅,为训练数据打上烙印,以判断是否被大模型所用
赞
踩
为了将LLMs打造成人类想要的样子,通常需要收集大量数据微调模型。在LLMs时代之前,众包是获取标注数据的主要方式。
自从LLMs出来后,研究者们探索出可以从强大的模型如Bard、ChatGPT或Claude中生成合成数据微调自己的模型,相比众包更加省时省力省钱。
但这一过程涉及到了使用其他模型生成的数据,可能会引发版权和知识产权的问题。例如,如果一个模型被用来生成训练数据,而这些数据又被用来训练另一个模型,那么后者是否是对前者的派生作品?
为了追根溯源,可以像图片版权保护一样为LLM的输出打上水印(watermarking),以此来检测合成数据,极大的促进了大模型的安全防护。
最近关于LLM水印技术的文章很多,今天介绍的这篇文章来自Meta,它并没有探讨如何在保障输出质量的情况下为LLM打水印,而是另辟蹊径,研究水印文本的“放射性”——即水印文本被用作微调数据时会发生什么呢?对模型的潜在“污染”能力有多大?
论文标题:
Watermarking Makes Language Models Radioactive
前置知识
考虑到有些童鞋对水印技术不太了解,这里做一些简单的介绍。
LLM的解码过程很简单,以上下文作为输入,其中是模型的词汇表,然后输出一个logits向量,。该向量将被转换为,也就是下一个token的概率分布。再使用top-k采样、nucleus采样等方法选择下一个token。
水印嵌入:就是改变logits向量或采样过程。通常,使用秘密密钥加密函数的输出对先前的k个token进行哈希处理,它用作初始化随机数生成器的种子,从而影响下一个记号的选择。
水印检测:对待审查的文本tokenizes处理,重复秘密种子生成并对每个token打分。因此,为当前token 的函数可以写成,该函数将token作为相对于种子和标记序列的分数的输入:
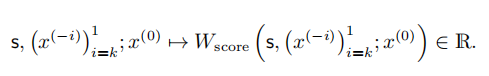
再基于累积分数和token的数量的统计检验确定文本是否含有数字水印。
符号和问题陈述
假设Alice拥用语言模型A。Bob拥有另一个语言模型B。Bob使用从语言模型A中获取的少量文本对B进行微调。用D表示用于微调B的数据集,其中由A生成的文本表示为。定义ρA生成的数据占整个微调数据的比例:
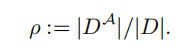
另外本文定义了四种情景:监督/无监督,开源/闭源,并基于此做交叉搭配测试,如下图所示:

-
监督设置:Bob使用一个可识别的帐户查询A。Alice保留了A为Bob生成的所有内容。因此,Alice知道。将监督程度定义为:
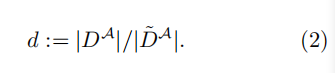
-
无监督设置:Bob不使用任何可识别的账户或隐藏在他人背后查询模型A,此时d = 0。这是最现实的情形。
当B没有从A那里看到任何输出时,ρ和d并不代表相同的概念,但ρ = d = 0。
-
开放模型:模型B是开源的或者Alice通过合法途径获取了B的访问权限,Alice可以观察B输出的logits。
-
闭源模型:Alice只能通过API来查询B,不能输出概率向量或logits,Alice只能观察生成的文本。大多数聊天机器人都是这种情况。
放射性定义
这里探索LLM水印技术的潜在“放射性”,是由 [1]创造的术语,指的是水印文本在被用作微调数据时污染模型的能力。
1. 文本放射性
给定一个统计检验 ,使得“ 在 上没有训练” ,如果 能够在显著水平(p 值)小于 的情况下拒绝 ,称文本语料库 对于 是α。
2. 模型放射性
给定一个统计检验 ,使得“ 在 的输出上没有训练” ,如果 能够在显著水平(p 值)小于 的情况下拒绝 ,称模型 对于 是 α。
因此, 量化了数据集或模型的放射性。 越低(例如,)代表放射性越强,因为检测测试具有较高的置信度,而 表示低放射性(检测是一个随机测试)。
放射性检测
接下来,作者提出了在语言模型中检测非水印文本和水印文本的放射性的方法。
这里先介绍一下另一项技术Membership inference attacks(MIAs)成员推理攻击,作为一种攻击方法,其目标是分辨一条数据是否属于模型的训练集,如果属于训练集,则为成员,否则为非成员。这与本文的目的检测模型A生成的文本是否用于模型B训练不谋而合。因此,作者后续思路受MIAs启发。
无水印检测
在开源模型/监督学习的情况下,MIA通过观察B在精心选择的输入集上的损失(或困惑度)来评估一个样本/句子的放射性。期望在训练期间看到的样本上的困惑度越小越好(有时被称为损失攻击)。
本文将这个思想扩展到没有水印的文本语料库的基准放射性检测测试中。将文本语料库划分为句子(每个句子256个token),并计算B在每个句子上的损失。使用zlib熵进行校准,校准的目的是考虑每个样本的复杂性并将其与B的过度自信分离开来。
K-S检验
测试零假设:“在上的困惑度与生成的新文本的困惑度具有相同的分布”。实际上,如果B没有在的部分上进行微调,那么必然成立。
为了比较经验分布,使用双样本Kolmogorov-Smirnov检验。给定损失值上的两个累积分布和,计算距离为:
如果这个距离高于一个阈值,即确定检验的p值,则拒绝,并得出结论:对于B具有放射性。
带水印的检测
考虑使用方法和秘密密钥为的输出带上水印的情况。在这种情况下,在开源/闭源,监督/无监督几种设置下都存在一个检测测试,如下表所示:

的评分函数取决于观察到的tokens和;的水印检测测试取决于评分和token数量。T测试零假设:“文本不是按照加密方法和秘密密钥生成的”
1. 简单方法
通过对B生成的大量文本进行水印检测,可以检测到放射性。事实上,如果B从未见过水印,W和s之后的文本就不能生成,所以如果“B没有使用A的输出”,那么H0为真。
然而,在中只有中的k-gram才能找到水印的痕迹。即使假设这些k-gram被强烈地水印化,并且B已经记住了它们,它们仍然只构成了可以进行测试的个k-gram中的一小部分,使得测试结果不够理想。
B中的水印检测
为了弥补简单方法中的缺陷,本文针对B的访问引入两种方法:
-
闭源模型:用B来提示和生成新的文本。在监督设置中,只用来自的(带水印的)文本来提示B。在无监督的情况下,用来自同一分布的新文本来提示被怀疑接受过训练的文本。
-
开源模型:不使用B生成新的文本,而是直接通过B来传递句子。设为一个token序列,为根据B的解码得出的最可能的下一个token。使用对 进行评分,具体算法如下图所示:

基于得分的k-gram筛选
为了改进检测,还引入了一个筛选器ϕ,这是一个可能经过训练的k-gram集合。仅当它们前面的k-gram窗口——用于散列的水印上下文窗口——是ϕ的一部分时,才会对标记进行评分。这将使得评分计算集中在可能已经学习水印的k-grams上。
在完全的监督设置中,确切地知道B的训练数据,因此ϕ由训练时使用的k-grams组成。
在无监督设置中,关注‘可能’受到污染的token集合,例如,在由A生成的带水印文本中频繁出现的k-grams。筛选器ϕ仅在封闭模型设置中使用。
令牌评分和去重
由于在实践中发现水印必须在数量级更多的tokens中被观察到,而传统的水印会受到token分布偏差影响。因此仅在先前的k-gram还没有在检测中被看到时,才对一个token进行评分。这样即使对许多token进行分析,也能提供可靠的值。
指令数据集中的放射性
假设预训练的LLM B是根据模型a生成的指令/答案对进行指令微调的。作者通过一些实验证明加了水印的合成指令具有放射性,并将其放射性水平与未加水印的指令进行比较。
实验设置
指令数据生成
模型A使用Llama-2-chat-7B,采用Self-instruct的方法以一条指令为开头,后跟三个指令/回答配对的示例,并要求模型生成接下来的20个指令/回答配对。
从LLM的logits中进行采样时,选择不进行水印处理,或者使用[2]的水印处理方法,最终得到了一个包含100k个指令/回答配对的数据集。
最后,创建了6个混合数据集,带水印的数据比例为ρ,其余的数据集用未带水印的指令填充。
微调
使用这六个合成数据集进行训练,遵循Alpaca的方法,对模型B=Llama-1-7B进行微调,该模型在训练时使用了与A=Llama-2不同的数据集,以避免在微调过程中出现使用相同基础模型的偏差。
指令调优的质量检查
下图使用六个合成数据集微调Bob模型后生成的答案示例:

另外,本文通过几个常规的问答数据集Natural Questions、TriviaQA等在0-shot下的得分,定性地检查了微调后的模型B的输出质量。
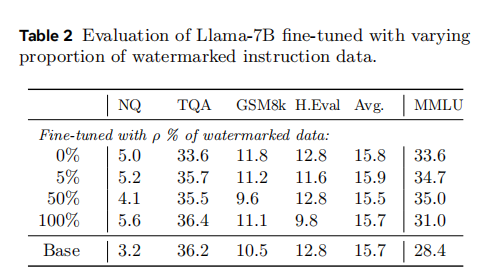
正如预期的那样,指令微调对大多数基准测试结果没有影响,但对MMLU的结果产生了改进。这证实了对指令进行水印处理不会对微调产生显著影响。
MIA基线设置
在没有水印的情况下,设置如下:Alice对B具有开放模型访问权限,并且知道为Bob生成的所有数据(监督设置)。Bob在微调B时使用了一部分数据,其程度由监督度d确定。在实验中,使用K-S检验来区分B在以下数据集上的校准困惑度:包含了5k个指令/回答(截断至256个tokens),这些数据不属于B的微调数据集;而包含了(1/d)×5k个指令/回答。数据集模拟了当Bob生成了大量数据,但只对其中一小部分进行微调时的情况。
下图比较了d = 0和d > 0时的分布。随着d的减小,检测变得更具挑战性:数据中包含了越来越多Bob没有进行微调的文本,因此两个困惑度分布之间的差异越来越小。
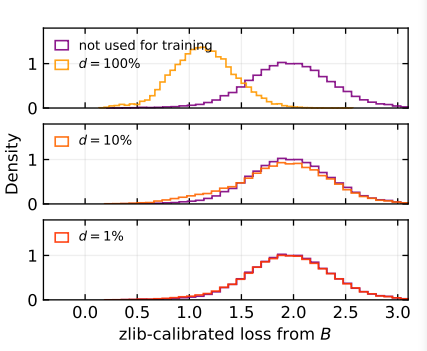
下表呈现了从放射性检验中获得的p值。当d > 2%时,该检验以较高的显著性水平拒绝了零假设:意味着当检测到放射性污染时,误报的概率为。

随着d的减小,该检验的功效减弱。在边缘情况d = 0中,即Alice对Bob使用的数据缺乏了解的无监督设置中,检验是随机的。相反,接下来的章节将展示在带有水印的数据上进行放射性检测可以在该设置下成功。
带水印的放射性检测:开源模型情况下
讨论在开放模型设置下的放射性检测,其中ρ表示A的带水印数据在B的微调数据集中的比例。同样分为监督设置(d = 1)和无监督设置(d = 0)。结果如下图所示:
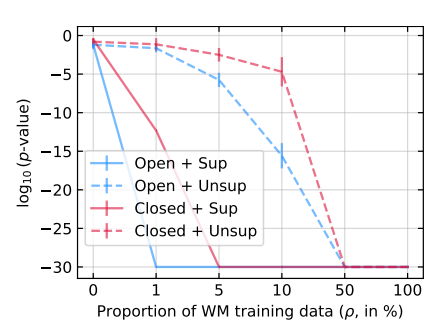
类似于MIA方法,监督设置是直接的,即使只有1%的Bob微调数据来自A,放射性检测的p值也小于,也就是说可以轻松检测出来。
相反,当d = 0时,MIA不再适用,**但本文提出的的开放模型放射性检测测试仍然可以再当用于微调B的指令不超过5%来自A时使得**。此时,检测是在一个不包含Bob使用的样本的文本语料库上进行的。然而,它确实包含k-grams,可能与Bob训练的中的k-grams重叠,并且可能检测到放射性。
带水印的放射性检测:闭源模型情况下
在封闭模型设置中,Bob的模型B只能通过API访问,该API可以根据提示生成答案。下图比较了在封闭模型和监督设置(d = 1)下,微调数据中带有1%水印时的检测结果,其中考虑了是否使用过滤器。
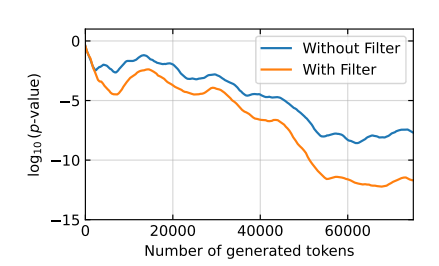
如预期的那样,检测测试的置信度随着标记数量的增加而增加。此外,使用过滤器始终显示出改进效果。
实验结果小结
在Alice确切知道哪些数据被用于训练Bob的模型,并且可以自由访问该模型的情况下,membership inference attacks非常有效。在这种情况下,她可以非常有信心地证明Bob使用了Alice的模型生成的数据。然而,该方法的适用范围较小。
而本文提出的基于水印的检测方法可以在各种设置下识别B是否具有放射性。例如,即使没有对Bob的训练样例的监督(最现实的场景),当B只能通过API访问时,只要至少10%的数据有水印的,这种检测方法也有效。
当模型B是开放模型时,测试更加强大。它可以在文本中有10%带水印的情况下,检测到的放射性。
微调、水印算法和数据分布对放射性的影响
1. 微调
下表显示了学习率、微调算法、训练周期、模型大小对放射性的影响,从结果可以看出模型与微调数据拟合得越好,其辐射活性就越容易被检测到。比如将学习率乘以10后几乎是放射性测试的平均的两倍。

2. 水印方法
下表设置了不同的水印窗口大小,结果表明当固定训练文本的水印检测的p值时,随着窗口大小k的增大,放射性检测的置信度降低。作者认为主要有两点原因:首先,对于较低的k, k-gram在训练数据中重复的机会更高,这增加了它在模型中的记忆。其次,k-gram的数量为,随着k的增加而增加,而水印标记的数量是固定的m。因此,在检测时,随着k的增加,放射性k-grams的数量减少,这降低了测试的能力。

3. 数据分布
假设Alice对的分布没有先验知识,比如Alice不知道的语言是意大利语、法语、英语、西班牙语还是德语。
如下表所示,使用相应语言的维基百科文章开头提示B,并对生成的下一个token进行检测。结果显示,即使Alice不知道Bob可能用来训练B的特定数据分布,她可能仍然会在不同的分布中测试放射性,并表现出显著性水平。
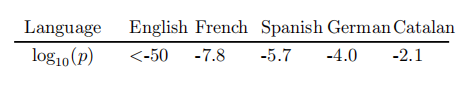
结论
这篇文章对语言模型中的"放射性"概念进行了详细说明。它介绍了一种方法来检测水印生成文本在被用作微调数据时在模型中留下的痕迹。并根据对微调模型的访问权限(开放或封闭)以及训练数据的类型(监督或无监督),提出了四种新的方法来检测放射性。这些方法相比基线方法有显著的改进。
研究结果表明,对于没有水印的文本来说,检测放射性是困难的。然而,带有水印的文本在微调过程中对模型造成了污染,所以展现出明显的放射性迹象。这意味着我们可以非常自信地判断训练数据是不是由带水印的模型合成的。


参考资料
[1]Alexandre Sablayrolles, Matthijs Douze, Cordelia Schmid,and Hervé Jégou. Radioactive data: tracing through training. In International Conference on Machine Learning, pages 8326–8335. PMLR, 2020.
[2]John Kirchenbauer, Jonas Geiping, Yuxin Wen, Jonathan Katz, Ian Miers, and Tom Goldstein. A water mark for large language models. arXiv preprint arXiv:2301.10226, 2023a.

