
- 1 业务与技术的关系: 找到结合点才能创造价值_业务决定变现,技术决定供求
- 2make menuconfig错误Unable to find the ncurses libraries_unable to find the ncurses libraries or the
- 3修改 jupyter notebook的默认打开的文件夹位置——亲测有用
- 4HarmonyOS将程序下载并运行到真机上 (华为手机为例)_harmony能先安装在自己手机
- 5《安富莱嵌入式周报》第305期:超级震撼数码管瀑布,使用OpenAI生成单片机游戏代码的可玩性,120通道逻辑分析仪,复古电子设计,各种运动轨迹函数源码实现
- 6基于Java+Springboot+Vue的校园爱心捐赠互助管理系统设计和实现_基于springboot的公益捐助管理系统的设计与实现文献
- 7JAVA中webSocket应用_websocket jar包
- 8通俗易懂了解Vue组件的生命周期
- 9App自动化测试通过USB连接和无线连接Android终端设备的方法(adb远程连接)_app自动化测试如何连接手机
- 10计算机网络(谢希仁)— 第三章-数据链路层(一)_字节填充法
图像处理——主成分分析PCA、奇异值分解SVD_图像pca分析
赞
踩
感谢以下2位的渊博知识:
(1)李春春:http://blog.csdn.net/zhongkelee/article/details/44064401
(2)沈春旭: https://blog.csdn.net/shenziheng1/article/details/52916278
一、PCA简介
1. 相关背景
上完陈恩红老师的《机器学习与知识发现》和季海波老师的《矩阵代数》两门课之后,颇有体会。最近在做主成分分析和奇异值分解方面的项目,所以记录一下心得体会。
在许多领域的研究与应用中,往往需要对反映事物的多个变量进行大量的观测,收集大量数据以便进行分析寻找规律。多变量大样本无疑会为研究和应用提供了丰富的信息,但也在一定程度上增加了数据采集的工作量,更重要的是在多数情况下,许多变量之间可能存在相关性,从而增加了问题分析的复杂性,同时对分析带来不便。如果分别对每个指标进行分析,分析往往是孤立的,而不是综合的。盲目减少指标会损失很多信息,容易产生错误的结论。
因此需要找到一个合理的方法,在减少需要分析的指标同时,尽量减少原指标包含信息的损失,以达到对所收集数据进行全面分析的目的。由于各变量间存在一定的相关关系,因此有可能用较少的综合指标分别综合存在于各变量中的各类信息。主成分分析与因子分析就属于这类降维的方法。
2. 问题描述
下表1是某些学生的语文、数学、物理、化学成绩统计:
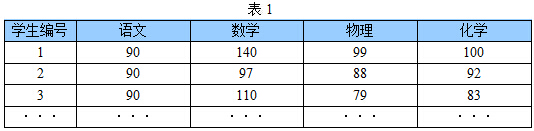
首先,假设这些科目成绩不相关,也就是说某一科目考多少分与其他科目没有关系。那么一眼就能看出来,数学、物理、化学这三门课的成绩构成了这组数据的主成分(很显然,数学作为第一主成分,因为数学成绩拉的最开)。为什么一眼能看出来?因为坐标轴选对了!下面再看一组学生的数学、物理、化学、语文、历史、英语成绩统计,见表2,还能不能一眼看出来:
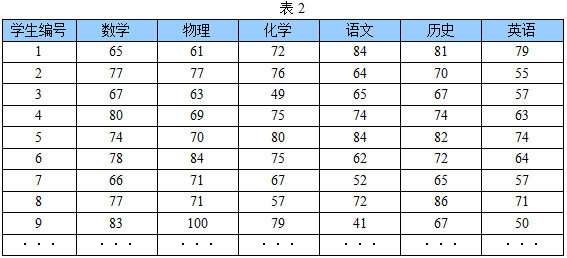
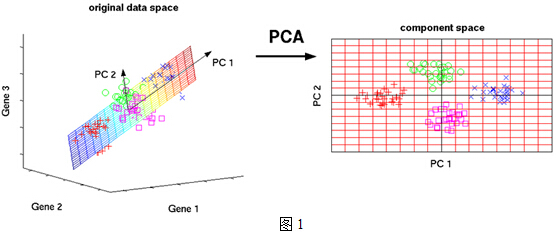
数据太多了,以至于看起来有些凌乱!也就是说,无法直接看出这组数据的主成分,因为在坐标系下这组数据分布的很散乱。究其原因,是因为无法拨开遮住肉眼的迷雾~如果把这些数据在相应的空间中表示出来,也许你就能换一个观察角度找出主成分。如下图1所示:
但是,对于更高维的数据,能想象其分布吗?就算能描述分布,如何精确地找到这些主成分的轴?如何衡量你提取的主成分到底占了整个数据的多少信息?所以,我们就要用到主成分分析的处理方法。
3. 数据降维
为了说明什么是数据的主成分,先从数据降维说起。数据降维是怎么回事儿?假设三维空间中有一系列点,这些点分布在一个过原点的斜面上,如果你用自然坐标系x,y,z这三个轴来表示这组数据的话,需要使用三个维度,而事实上,这些点的分布仅仅是在一个二维的平面上,那么,问题出在哪里?如果你再仔细想想,能不能把x,y,z坐标系旋转一下,使数据所在平面与x,y平面重合?这就对了!如果把旋转后的坐标系记为x',y',z',那么这组数据的表示只用x'和y'两个维度表示即可!当然了,如果想恢复原来的表示方式,那就得把这两个坐标之间的变换矩阵存下来。这样就能把数据维度降下来了!但是,我们要看到这个过程的本质,如果把这些数据按行或者按列排成一个矩阵,那么这个矩阵的秩就是2!这些数据之间是有相关性的,这些数据构成的过原点的向量的最大线性无关组包含2个向量,这就是为什么一开始就假设平面过原点的原因!那么如果平面不过原点呢?这就是数据中心化的缘故!将坐标原点平移到数据中心,这样原本不相关的数据在这个新坐标系中就有相关性了!有趣的是,三点一定共面,也就是说三维空间中任意三点中心化后都是线性相关的,一般来讲n维空间中的n个点一定能在一个n-1维子空间中分析!
上一段文字中,认为把数据降维后并没有丢弃任何东西,因为这些数据在平面以外的第三个维度的分量都为0。现在,假设这些数据在z'轴有一个很小的抖动,那么我们仍然用上述的二维表示这些数据,理由是我们可以认为这两个轴的信息是数据的主成分,而这些信息对于我们的分析已经足够了,z'轴上的抖动很有可能是噪声,也就是说本来这组数据是有相关性的,噪声的引入,导致了数据不完全相关,但是,这些数据在z'轴上的分布与原点构成的夹角非常小,也就是说在z'轴上有很大的相关性,综合这些考虑,就可以认为数据在x',y' 轴上的投影构成了数据的主成分!
课堂上老师谈到的特征选择的问题,其实就是要剔除的特征主要是和类标签无关的特征。而这里的特征很多是和类标签有关的,但里面存在噪声或者冗余。在这种情况下,需要一种特征降维的方法来减少特征数,减少噪音和冗余,减少过度拟合的可能性。
PCA的思想是将n维特征映射到k维上(k<n),这k维是全新的正交特征。这k维特征称为主成分,是重新构造出来的k维特征,而不是简单地从n维特征中去除其余n-k维特征。
二、PCA实例
现在假设有一组数据如下:
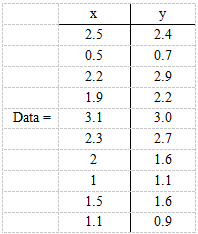
行代表了样例,列代表特征,这里有10个样例,每个样例两个特征。可以这样认为,有10篇文档,x是10篇文档中“learn”出现的TF-IDF,y是10篇文档中“study”出现的TF-IDF。
第一步,分别求x和y的平均值,然后对于所有的样例,都减去对应的均值。这里x的均值是1.81,y的均值是1.91,那么一个样例减去均值后即为(0.69,0.49),得到
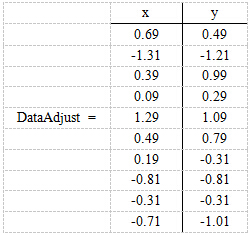
第二步,求特征协方差矩阵,如果数据是3维,那么协方差矩阵是
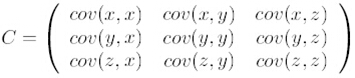
这里只有x和y,求解得
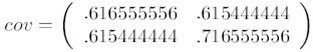
对角线上分别是x和y的方差,非对角线上是协方差。协方差是衡量两个变量同时变化的变化程度。协方差大于0表示x和y若一个增,另一个也增;小于0表示一个增,一个减。如果x和y是统计独立的,那么二者之间的协方差就是0;但是协方差是0,并不能说明x和y是独立的。协方差绝对值越大,两者对彼此的影响越大,反之越小。协方差是没有单位的量,因此,如果同样的两个变量所采用的量纲发生变化,它们的协方差也会产生树枝上的变化。
第三步,求协方差的特征值和特征向量,得到
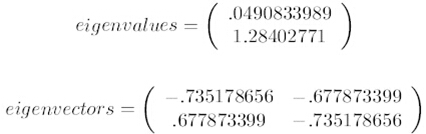
上面是两个特征值,下面是对应的特征向量,特征值0.0490833989对应特征向量为,这里的特征向量都归一化为单位向量。
第四步,将特征值按照从大到小的顺序排序,选择其中最大的k个,然后将其对应的k个特征向量分别作为列向量组成特征向量矩阵。
这里特征值只有两个,我们选择其中最大的那个,这里是1.28402771,对应的特征向量是(-0.677873399, -0.735178656)T。
第五步,将样本点投影到选取的特征向量上。假设样例数为m,特征数为n,减去均值后的样本矩阵为DataAdjust(m*n),协方差矩阵是n*n,选取的k个特征向量组成的矩阵为EigenVectors(n*k)。那么投影后的数据FinalData为
FinalData(10*1) = DataAdjust(10*2矩阵) x 特征向量(-0.677873399, -0.735178656)T
得到的结果是
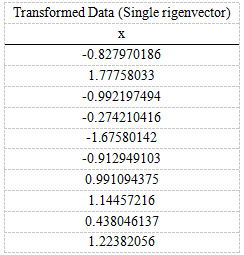
这样,就将原始样例的n维特征变成了k维,这k维就是原始特征在k维上的投影。
上面的数据可以认为是learn和study特征融合为一个新的特征叫做LS特征,该特征基本上代表了这两个特征。上述过程如下图2描述:
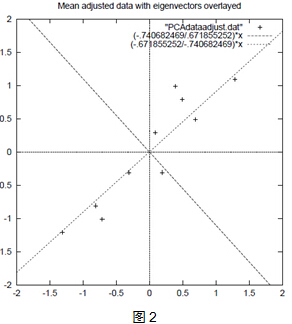
正号表示预处理后的样本点,斜着的两条线就分别是正交的特征向量(由于协方差矩阵是对称的,因此其特征向量正交),最后一步的矩阵乘法就是将原始样本点分别往特征向量对应的轴上做投影。
整个PCA过程貌似及其简单,就是求协方差的特征值和特征向量,然后做数据转换。但是有没有觉得很神奇,为什么求协方差的特征向量就是最理想的k维向量?其背后隐藏的意义是什么?整个PCA的意义是什么?
三、PCA推导
先看下面这幅图:
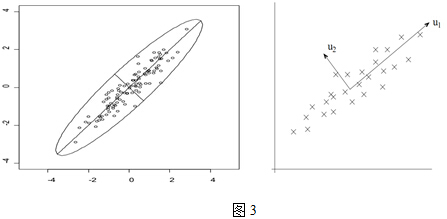
在第一部分中,我们举了一个学生成绩的例子,里面的数据点是六维的,即每个观测值是6维空间中的一个点。我们希望将6维空间用低维空间表示。
先假定只有二维,即只有两个变量,它们由横坐标和纵坐标所代表;因此每个观测值都有相应于这两个坐标轴的两个坐标值;如果这些数据形成一个椭圆形状的点阵,那么这个椭圆有一个长轴和一个短轴。在短轴方向上,数据变化很少;在极端的情况,短轴如果退化成一点,那只有在长轴的方向才能够解释这些点的变化了;这样,由二维到一维的降维就自然完成了。
上图中,u1就是主成分方向,然后在二维空间中取和u1方向正交的方向,就是u2的方向。则n个数据在u1轴的离散程度最大(方差最大),数据在u1上的投影代表了原始数据的绝大部分信息,即使不考虑u2,信息损失也不多。而且,u1、u2不相关。只考虑u1时,二维降为一维。
椭圆的长短轴相差得越大,降维也越有道理。
1. 最大方差理论
在信号处理中认为信号具有较大的方差,噪声有较小的方差,信噪比就是信号与噪声的方差比,越大越好。如前面的图,样本在u1上的投影方差较大,在u2上的投影方差较小,那么可认为u2上的投影是由噪声引起的。
因此我们认为,最好的k维特征是将n维样本点转换为k维后,每一维上的样本方差都很大。
比如我们将下图中的5个点投影到某一维上,这里用一条过原点的直线表示(数据已经中心化):
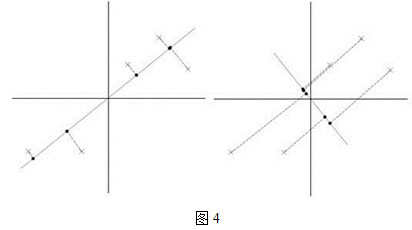
假设我们选择两条不同的直线做投影,那么左右两条中哪个好呢?根据我们之前的方差最大化理论,左边的好,因为投影后的样本点之间方差最大(也可以说是投影的绝对值之和最大)。
计算投影的方法见下图5:

图中,红色点表示样例,蓝色点表示在u上的投影,u是直线的斜率也是直线的方向向量,而且是单位向量。蓝色点是在u上的投影点,离原点的距离是<x,u>(即xTu或者uTx)。
2. 最小二乘法
我们使用最小二乘法来确定各个主轴(主成分)的方向。
对给定的一组数据(下面的阐述中,向量一般均指列向量):
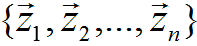
其数据中心位于:
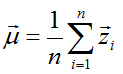
数据中心化(将坐标原点移到样本点的中心点):
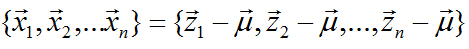
中心化后的数据在第一主轴u1方向上分布散的最开,也就是说在u1方向上的投影的绝对值之和最大(也可以说方差最大),计算投影的方法上面已经阐述,就是将x与u1做内积,由于只需要求u1的方向,所以设u1也是单位向量。
在这里,也就是最大化下式:
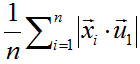
由矩阵代数相关知识可知,可以对绝对值符号项进行平方处理,比较方便。所以进而就是最大化下式:
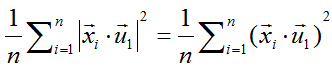
两个向量做内积,可以转化成矩阵乘法:
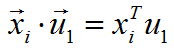
所以目标函数可以表示为:
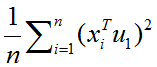
括号里面就是矩阵乘法表示向量内积,由于列向量转置以后是行向量,行向量乘以列向量得到一个数,一个数的转置还是其本身,所以又可以将目标函数化为:
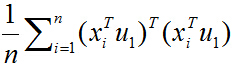
去括号:
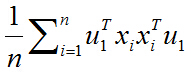
又由于u1和i无关,可以拿到求和符外面,上式化简为:
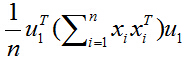
学过矩阵代数的同学可能已经发现了,上式括号里面求和后的结果,就相当于一个大矩阵乘以自身的转置,其中,这个大矩阵的形式如下:
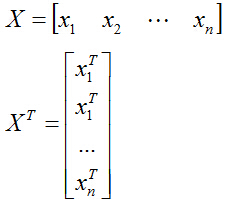
X矩阵的第i列就是xi
于是有:
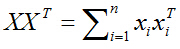
所以目标函数最终化为:
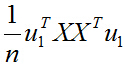
其中的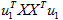
我们假设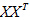
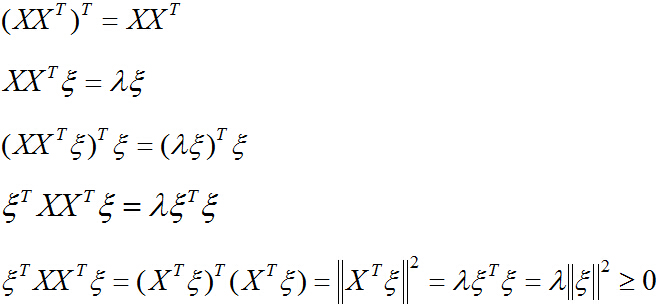
所以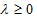
下面我们求解最大值、取得最大值时u1的方向这两个问题。
先解决第一个问题,对于向量x的二范数平方为:
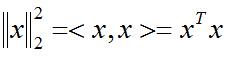
同样,目标函数也可以表示成映射后的向量的二范数平方:
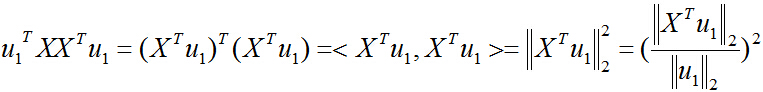
把二次型化成一个范数的形式,由于u1取单位向量,最大化目标函数的基本问题也就转化为:对一个矩阵,它对一个向量做变换,变换前后的向量的模长伸缩尺度如何才能最大?我们有矩阵代数中的定理知,向量经矩阵映射前后的向量长度之比的最大值就是这个矩阵的最大奇异值,即:
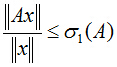
式中,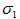
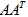
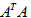
针对本问题来说,
再解决第二个问题,对一般情况,设对称阵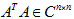
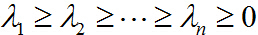
相应的单位特征向量为:
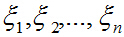
任取一个向量x,用特征向量构成的空间中的这组基表示为:
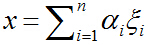
则:
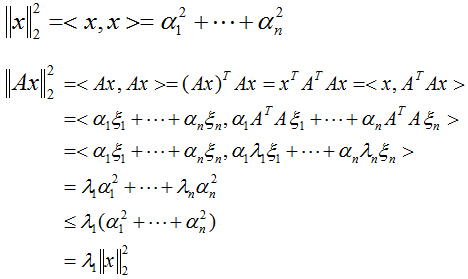
所以:
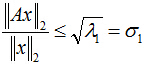
针对第二个问题,我们取上式中的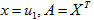
的最大特征值时,对应的特征向量的方向,就是第一主成分u1的方向!(第二主成分的方向为
证明完毕。
主成分所占整个信息的百分比可用下式计算:
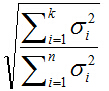
式中分母为
有些研究工作表明,所选的主轴总长度占所有主轴长度之和的大约85% 即可,其实,这只是一个大体的说法,具体选多少个,要看实际情况而定。
3.意义
PCA将n个特征降维到k个,可以用来进行数据压缩,例如100维的向量最后可以用10维来表示,那么压缩率为90%。同样图像处理领域的KL变换使用PCA做图像压缩,人脸检测和匹配。比如如下摘自另一篇博客上的Matlab实验结果:



可见测试样本为人脸的样本的重建误差显然小于非人脸的重建误差。
SVD
PCA的实现一般有两种,一种是用特征值分解去实现的,一种是用奇异值分解去实现的。特征值和奇异值在大部分人的印象中,往往是停留在纯粹的数学计算中。而且线性代数或者矩阵论里面,也很少讲任何跟特征值与奇异值有关的应用背景。奇异值分解是一个有着很明显的物理意义的一种方法,它可以将一个比较复杂的矩阵用更小更简单的几个子矩阵的相乘来表示,这些小矩阵描述的是矩阵的重要的特性。就像是描述一个人一样,给别人描述说这个人长得浓眉大眼,方脸,络腮胡,而且带个黑框的眼镜,这样寥寥的几个特征,就让别人脑海里面就有一个较为清楚的认识,实际上,人脸上的特征是有着无数种的,之所以能这么描述,是因为人天生就有着非常好的抽取重要特征的能力,让机器学会抽取重要的特征,SVD是也一个重要的方法。在机器学习领域,有相当多的应用与奇异值都可以扯上关系,比如做feature reduction的PCA,做数据压缩(以图像压缩为代表)的算法,还有做搜索引擎语义层次检索的LSI(Latent Semantic Indexing)。
本文主要关注奇异值的一些特性,还会稍稍提及奇异值的计算。另外,本文里面有部分不算太深的线性代数的知识,如果完全忘记了线性代数,看文可能会有些困难。
2.奇异值分解详解
特征值分解和奇异值分解两者有着很紧密的关系,特征值分解和奇异值分解的目的都是一样,就是提取出一个矩阵最重要的特征。先谈谈特征值分解吧:
1 特征值:
如果说一个向量v是方阵A的特征向量,将一定可以表示成下面的形式:
这时候λ就被称为特征向量v对应的特征值,一个矩阵的一组特征向量是一组正交向量。特征值分解是将一个矩阵分解成下面的形式:
其中Q是这个矩阵A的特征向量组成的矩阵,Σ是一个对角阵,每一个对角线上的元素就是一个特征值。首先,要明确的是,一个矩阵其实就是一个线性变换,因为一个矩阵乘以一个向量后得到的向量,其实就相当于将这个向量进行了线性变换。比如说下面的一个矩阵:
它其实对应的线性变换是下面的形式:
因为这个矩阵M乘以一个向量(x,y)的结果是:
上面的矩阵是对称的,所以这个变换是一个对x,y轴的方向一个拉伸变换(每一个对角线上的元素将会对一个维度进行拉伸变换,当值>1时拉长,当值<1时缩短),当矩阵不是对称的时候,假如说矩阵是下面的样子:
它所描述的变换是下面的样子:
这其实是在平面上对一个轴进行的拉伸变换(如蓝色的箭头所示),在图中,蓝色的箭头是一个最主要的变化方向(变化方向可能有不止一个),如果我们想要描述好一个变换,那我们就描述好这个变换主要的变化方向就好了。反过头来看看之前特征值分解的式子,分解得到的Σ矩阵是一个对角阵,里面的特征值是由大到小排列的,这些特征值所对应的特征向量就是描述这个矩阵变化方向(从主要的变化到次要的变化排列)
当矩阵是高维的情况下,那么这个矩阵就是高维空间下的一个线性变换,这个线性变化可能没法通过图片来表示,但是可以想象,这个变换也同样有很多的变换方向,我们通过特征值分解得到的前N个特征向量,那么就对应了这个矩阵最主要的N个变化方向。我们利用这前N个变化方向,就可以近似这个矩阵(变换)。也就是之前说的:提取这个矩阵最重要的特征。总结一下,特征值分解可以得到特征值与特征向量,特征值表示的是这个特征到底有多重要,而特征向量表示这个特征是什么,可以将每一个特征向量理解为一个线性的子空间,我们可以利用这些线性的子空间干很多的事情。不过,特征值分解也有很多的局限,比如说变换的矩阵必须是方阵。
2 奇异值:
下面重点谈谈奇异值分解。特征值分解是一个提取矩阵特征很不错的方法,但是它只是对方阵而言的,在现实的世界中,我们看到的大部分矩阵都不是方阵,比如说有N个学生,每个学生有M科成绩,这样形成的一个N * M的矩阵就不可能是方阵,我们怎样才能描述这样普通的矩阵呢的重要特征呢?奇异值分解可以用来干这个事情,奇异值分解是一个能适用于任意的矩阵的一种分解的方法:假设A是一个N * M的矩阵,那么得到的U是一个N * N的方阵(里面的向量是正交的,U里面的向量称为左奇异向量),Σ是一个N * M的矩阵(除了对角线的元素都是0,对角线上的元素称为奇异值),V’(V的转置)是一个N * N的矩阵,里面的向量也是正交的,V里面的向量称为右奇异向量),如下图所示: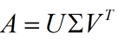
那么奇异值和特征值是怎么对应起来的呢?首先,我们将一个矩阵A的转置 * A,将会得到一个方阵,我们用这个方阵求特征值可以得到:这里得到的v,就是我们上面的右奇异向量。此外我们还可以得到: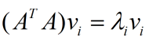
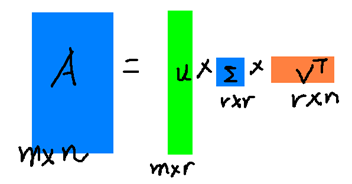
这里的σ就是上面说的奇异值,u就是上面说的左奇异向量。奇异值σ跟特征值类似,在矩阵Σ中也是从大到小排列,而且σ的减少特别的快,在很多情况下,前10%甚至1%的奇异值的和就占了全部的奇异值之和的99%以上了。也就是说,我们也可以用前r大的奇异值来近似描述矩阵,这里定义一下部分奇异值分解:
r是一个远小于m、n的数,这样矩阵的乘法看起来像是下面的样子:
右边的三个矩阵相乘的结果将会是一个接近于A的矩阵,在这儿,r越接近于n,则相乘的结果越接近于A。而这三个矩阵的面积之和(在存储观点来说,矩阵面积越小,存储量就越小)要远远小于原始的矩阵A,我们如果想要压缩空间来表示原矩阵A,我们存下这里的三个矩阵:U、Σ、V就好了。
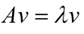
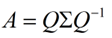
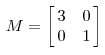
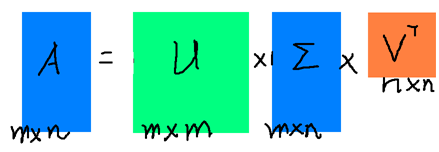
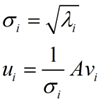

3.如何计算奇异值
奇异值的计算是一个难题,是一个O(N^3)的算法。在单机的情况下当然是没问题的,matlab在一秒钟内就可以算出1000 * 1000的矩阵的所有奇异值,但是当矩阵的规模增长的时候,计算的复杂度呈3次方增长,就需要并行计算参与了。
其实SVD还是可以用并行的方式去实现的,在解大规模的矩阵的时候,一般使用迭代的方法,当矩阵的规模很大(比如说上亿)的时候,迭代的次数也可能会上亿次,如果使用Map-Reduce框架去解,则每次Map-Reduce完成的时候,都会涉及到写文件、读文件的操作。个人猜测Google云计算体系中除了Map-Reduce以外应该还有类似于MPI的计算模型,也就是节点之间是保持通信,数据是常驻在内存中的,这种计算模型比Map-Reduce在解决迭代次数非常多的时候,要快了很多倍。
Lanczos迭代就是一种解对称方阵部分特征值的方法(之前谈到了,解A’* A得到的对称方阵的特征值就是解A的右奇异向量),是将一个对称的方程化为一个三对角矩阵再进行求解。
由于奇异值的计算是一个很枯燥,纯数学的过程,而且前人的研究成果(论文中)几乎已经把整个程序的流程图给出来了。更多的关于奇异值计算的部分,将在后面的参考文献中给出,这里不再深入,我还是focus在奇异值的应用中去。
4.奇异值分解应用
奇异值与主成分分析(PCA)
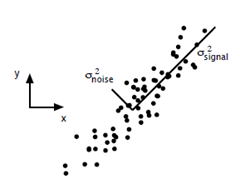
这里主要谈谈如何用SVD去解PCA的问题。PCA的问题其实是一个基的变换,使得变换后的数据有着最大的方差。方差的大小描述的是一个变量的信息量,我们在讲一个东西的稳定性的时候,往往说要减小方差,如果一个模型的方差很大,那就说明模型不稳定了。但是对于我们用于机器学习的数据(主要是训练数据),方差大才有意义,不然输入的数据都是同一个点,那方差就为0了,这样输入的多个数据就等同于一个数据了。以下面这张图为例子:
这个假设是一个摄像机采集一个物体运动得到的图片,上面的点表示物体运动的位置,假如我们想要用一条直线去拟合这些点,那我们会选择什么方向的线呢?当然是图上标有signal的那条线。如果我们把这些点单纯的投影到x轴或者y轴上,最后在x轴与y轴上得到的方差是相似的(因为这些点的趋势是在45度左右的方向,所以投影到x轴或者y轴上都是类似的),如果我们使用原来的xy坐标系去看这些点,容易看不出来这些点真正的方向是什么。但是如果我们进行坐标系的变化,横轴变成了signal的方向,纵轴变成了noise的方向,则就很容易发现什么方向的方差大,什么方向的方差小了。
一般来说,方差大的方向是信号的方向,方差小的方向是噪声的方向,我们在数据挖掘中或者数字信号处理中,往往要提高信号与噪声的比例,也就是信噪比。对上图来说,如果我们只保留signal方向的数据,也可以对原数据进行不错的近似了。
PCA的全部工作简单点说,就是对原始的空间中顺序地找一组相互正交的坐标轴,第一个轴是使得方差最大的,第二个轴是在与第一个轴正交的平面中使得方差最大的,第三个轴是在与第1、2个轴正交的平面中方差最大的,这样假设在N维空间中,我们可以找到N个这样的坐标轴,我们取前r个去近似这个空间,这样就从一个N维的空间压缩到r维的空间了,但是我们选择的r个坐标轴能够使得空间的压缩使得数据的损失最小。
还是假设我们矩阵每一行表示一个样本,每一列表示一个feature,用矩阵的语言来表示,将一个m * n的矩阵A的进行坐标轴的变化,P就是一个变换的矩阵从一个N维的空间变换到另一个N维的空间,在空间中就会进行一些类似于旋转、拉伸的变化。
而将一个m * n的矩阵A变换成一个m * r的矩阵,这样就会使得本来有n个feature的,变成了有r个feature了(r < n),这r个其实就是对n个feature的一种提炼,我们就把这个称为feature的压缩。用数学语言表示就是:
但是这个怎么和SVD扯上关系呢?之前谈到,SVD得出的奇异向量也是从奇异值由大到小排列的,按PCA的观点来看,就是方差最大的坐标轴就是第一个奇异向量,方差次大的坐标轴就是第二个奇异向量…我们回忆一下之前得到的SVD式子:
在矩阵的两边同时乘上一个矩阵V,由于V是一个正交的矩阵,所以V转置乘以V得到单位阵I,所以可以化成后面的式子:
将后面的式子与A * P那个m * n的矩阵变换为m * r的矩阵的式子对照看看,在这里,其实V就是P,也就是一个变化的向量。这里是将一个m * n 的矩阵压缩到一个m * r的矩阵,也就是对列进行压缩,如果我们想对行进行压缩(在PCA的观点下,对行进行压缩可以理解为,将一些相似的sample合并在一起,或者将一些没有太大价值的sample去掉)怎么办呢?同样我们写出一个通用的行压缩例子:
这样就从一个m行的矩阵压缩到一个r行的矩阵了,对SVD来说也是一样的,我们对SVD分解的式子两边乘以U的转置U':
这样我们就得到了对行进行压缩的式子。可以看出,其实PCA几乎可以说是对SVD的一个包装,如果我们实现了SVD,那也就实现了PCA了,而且更好的地方是,有了SVD,我们就可以得到两个方向的PCA,如果我们对A’A进行特征值的分解,只能得到一个方向的PCA。
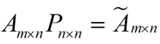

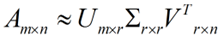
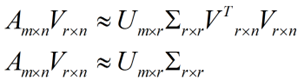
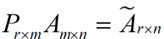
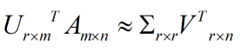


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}