
- 1Python 实现学生成绩管理系统_python用字典创建一个学生成绩管理系统
- 2嵌入式Linux系统:应用开发基础_fork函数基础_嵌入式fork
- 3maven中spring-boot-maven-plugin插件的作用_spring-boot-maven-plugin作用
- 4【微信小程序】 自定义导航栏(navigationStyle=custom)
- 5数据科学家技能路径图【中文修改版】
- 6ROS由于python版本而运行出错_ros python 失败
- 7re:Invent 云端历程:2023 亚马逊云科技 re:Invent 大会之初识Amazon Q
- 8成为Linux内核高手的四个方法_linux容纳内核技术
- 9CCF-CSP【202303-3 LDAP】C++_ldap ccf
- 10linux有名管道主动清空,linux-有名管道
ToolLearning Eval:CodeFuse发布首个中文Function Call的大语言模型评测基准!_function call dataset 大语言模型
赞
踩

1. 背景
随着ChatGPT等通用大模型的出现,它们可以生成令人惊叹的自然语言,使得机器能够更好地理解和回应人类的需求,但在特定领域的任务上仅靠通用问答是无法满足日常工作需要。随着OpenAI推出了Function Call功能,工具学习能力越来越作为开源模型的标配,目前业界较有影响力的是ToolBench的英文数据集。但是中文数据集的稀缺,使得我们很难判断各个模型在中文型工具上Function Call的能力差异。
为弥补这一不足,CodeFuse发布了首个面向ToolLearning领域的中文评测基准ToolLearning-Eval,以帮助开发者跟踪ToolLearning领域大模型的进展,并了解各个ToolLearning领域大模型的优势与不足。ToolLearning-Eval按照Function Call流程进行划分,包含工具选择、工具调用、工具执行结果总结这三个过程,方便通用模型可以对各个过程进行评测分析。
目前,我们已发布了第一期的评测榜单,首批评测大模型包含CodeFuse、Qwen、Baichuan、Internlm、CodeLLaMa等开源大语言模型;我们欢迎相关从业者一起来共建ToolLearning Eval项目,持续丰富ToolLearning领域评测题目或大模型,我们也会定期更新评测集和评测榜单。
ModelScope 地址:devopseval-exam
2. 评测数据
2.1. 数据来源
ToolLearning-Eval最终生成的样本格式都为Function Call标准格式,采用此类格式的原因是与业界数据统一,不但能够提高样本收集效率,也方便进行其它自动化评测。经过统计,该项目的数据来源可以分为3类:
- 开源数据:对开源的ToolBench原始英文数据进行清洗;
- 英译中:选取高质量的ToolBench数据,并翻译为中文;
- 大模型生成:采用Self-Instruct方法构建了中文 Function Call 训练数据&评测集;
我们希望越来越多的团队能参与到中文的functioncall数据构建,共同优化模型调用工具的能力。我们也会不断地强化这部分开源的数据集。
2.2. 数据类别
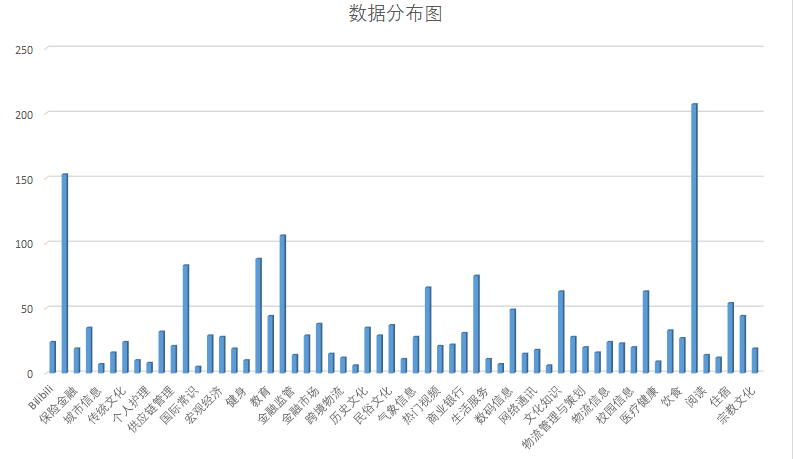
ToolLearning-Eval里面包含了两份评测集,fcdata-zh-luban和fcdata-zh-codefuse。里面总共包含 239 种工具类别,涵盖了59个领域,包含了1509 条评测数据。ToolLearning-Eval的具体数据分布可见下图
2.3. 数据样例
在数据上我们完全兼容了 OpenAI Function Calling,具体格式如下:
Function Call的数据格式
| Input Key | Input Type | Input Description |
| functions | List[Swagger] | 工具集合 |
| chatrounds | List[chatround] | 多轮对话数据 |
chatrounds的数据格式
| Input Key | Input Type | Input Description |
| role | string | 角色名称,包含三种类别,user、assistant、function |
| name | string | 若role为function,则存在name字段,为function的名称 |
| content | string | role的返回内容 |
| function_call | dict | 工具调用 |
- {
- "functions":
- [
- {
- "name": "get_fudan_university_scoreline",
- "description": "查询复旦大学往年分数线,例如:查询2020年复旦大学的分数线",
- "parameters":
- {
- "type": "object",
- "properties":
- {
- "year":
- {
- "type": "string",
- "description": "年份,例如:2020,2019,2018"
- }
- },
- "required":
- [
- "year"
- ]
- }
- }
- ],
- "chatrounds":
- [
- {
- "role": "system",
- "content": "CodeFuse是一个面向研发领域的智能助手,旨在中立的、无害的帮助用户解决开发相关的问题,所有的回答均使用Markdown格式返回。\n你能利用许多工具和功能来完成给定的任务,在每一步中,你需要分析当前状态,并通过执行函数调用来确定下一步的行动方向。你可以进行多次尝试。如果你计划连续尝试不同的条件,请每次尝试一种条件。若给定了Finish函数,则以Finish调用结束,若没提供Finish函数,则以不带function_call的对话结束。"
- },
- {
- "role": "user",
- "content": "查询2020年复旦大学的分数线"
- },
- {
- "role": "assistant",
- "content": null,
- "function_call":
- {
- "name": "get_fudan_university_scoreline",
- "arguments": "{\n \"year\": \"2020\"\n}"
- }
- },
- {
- "role": "function",
- "name": "get_fudan_university_scoreline",
- "content": "{\n \"scoreline\":{\n \"文科一批\": 630, \n \"文科二批\": 610, \n \"理科一批\": 650, \n \"理科二批\": 630 \n }\n}"
- },
- {
- "role": "assistant",
- "content": "2020年复旦大学的分数线如下:\n\n- 文科一批:630分\n- 文科二批:610分\n- 理科一批:650分\n- 理科二批:630分"
- }
- ]
- }

上述Function Call的数据样例为给定特定工具集后,用于回答用户查询某高校录取分数线的问题。此外限于篇幅,此处不再其它工具使用样例,具体可以查看HuggingFace数据集。
2.4. 数据下载
- 方法一: 直接下载(用浏览器打开下面的链接)
- 方法二:使用ModelScope datasets库函数
- from modelscope.msdatasets import MsDataset
- MsDataset.clone_meta(dataset_work_dir='./xxx', dataset_id='codefuse-ai/devopseval-exam')
- sample_data
- |- sampleData.json # 数据样例
- train_data
- |- fcdata_toolbenchG1.jsonl # 72783 toolbenchG1整理数据
- |- fcdata_toolbenchG2.jsonl # 29417 toolbenchG2整理数据
- |- fcdata_toolbenchG3.jsonl # 24286 toolbenchG3整理数据
- |- fcdata_toolbenchG1_zh.jsonl # 16335 toolbenchG1部分中文翻译数据
- |- fcdata_zh_train_v1.jsonl # 72032 自有采集生成的数据V1
- |- fcdata_zh_train_luban.jsonl # 10214 自有采集生成的数据luban
- test_data
- |- fcdata_zh_test_v1.jsonl # 1250 自有采集生成的测试数据V1
- |- fcdata_zh_test_luban.jsonl # 259 自有采集生成的测试数据luban
3. 评测设置
3.1. 评测模型
一期我们选取了比较热门的不同参数大小、不同机构发布的通用大模型和CodeFuse大模型,具体细节如下表。后续我们也会评测更多其他的大模型。
| 模型名称 | 参数量 |
| Qwen-7B-Chat | 7B |
| Qwen-14B-Chat | 14B |
| Baichuan2-7B-Chat | 7B |
| Internlm-7B-Chat | 7B |
| CodeLLaMA | 7B |
| CodeFuse-4k | 7B |
| CodeFuse-16k | 7B |
3.2. 评测指标
由于一般通用模型无法具备工具调用的能力,因此在进行Tool Learn-Eval评测之前需要对通用模型进行微调,先让模型学会工具使用的基本范式
下面,我们定义了几种评估工具使用的指标:

②③④⑤的和为1,代表工具调用失败的总数,⑤工具幻觉是工具名识别失败的一种特殊情况
在此基础上,我们提供了一个相应的评测脚本,具体评测过程欢迎到Github项目中进一步了解。

