
- 1DataLoader详解_dataloader函数
- 2北京/上海内推 | 字节跳动AI Lab招聘NLP算法模型优化方向实习生
- 3【工具】1664- Codeium:强大且免费的AI智能编程助手
- 4.net core使用filter过滤器处理拦截webapi接口_asp.net core 过滤器 拦截所有接口
- 5网络端口及对应服务_常用端口号与对应的服务
- 6Bag of Tricks for Efficient Text Classification (fastText) 学习笔记_fasttext model 镜像网站
- 7Android手机 通过NFC读取二代证信息_安卓 解析 nfc 身份证
- 8ubuntu查看内存cpu占用情况_ubuntu查看cpu占用率
- 9Bugku之Flask_FileUpload
- 10YOLOv8及其改进(三) 本文(5000字) | 解读modules.py划分成子文件 | 标签透明化与文字大小调节 | 框粗细调节 |
视觉Mamba模型的Swin时刻,中国科学院、华为等推出VMamba
赞
踩

©作者 | 机器之心编辑部
来源 | 机器之心
Transformer 在大模型领域的地位可谓是难以撼动。不过,这个AI 大模型的主流架构在模型规模的扩展和需要处理的序列变长后,局限性也愈发凸显了。Mamba的出现,正在强力改变着这一切。它优秀的性能立刻引爆了AI圈。
上周四, Vision Mamba(Vim)的提出已经展现了它成为视觉基础模型的下一代骨干的巨大潜力。仅隔一天,中国科学院、华为、鹏城实验室的研究人员提出了 VMamba:一种具有全局感受野、线性复杂度的视觉 Mamba 模型。这项工作标志着视觉 Mamba 模型 Swin 时刻的来临。

论文标题:
VMamba: Visual State Space Model
论文链接:
https://arxiv.org/abs/2401.10166
代码链接:
https://github.com/MzeroMiko/VMamba
CNN 和视觉 Transformer(ViT)是当前最主流的两类基础视觉模型。尽管 CNN 具有线性复杂度,ViT 具有更为强大的数据拟合能力,然而代价是计算复杂较高。研究者认为 ViT 之所以拟合能力强,是因为其具有全局感受野和动态权重。受 Mamba 模型的启发,研究者设计出一种在线性复杂度下同时具有这两种优秀性质的模型,即 Visual State Space Model(VMamba)。
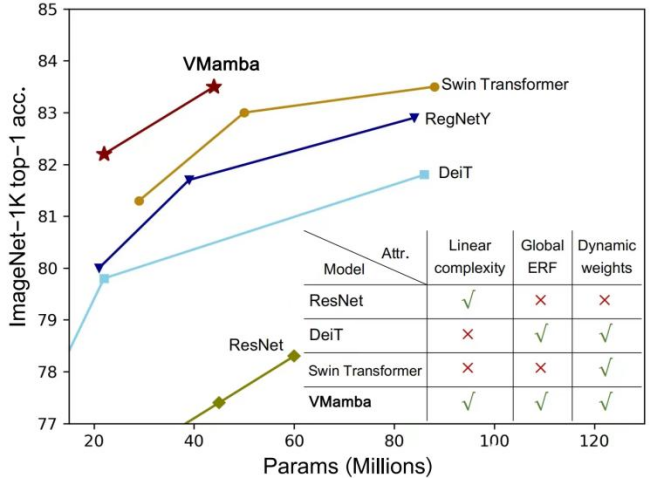
大量的实验证明,VMamba 在各种视觉任务中表现卓越。如下图所示,VMamba-S 在 ImageNet-1K 上达到 83.5% 的正确率,比 Vim-S 高 3.2%,比 Swin-S 高 0.5%。

方法介绍

VMamba 成功的关键在于采用了 Selective Scan Space State Sequential Model(S6 模型)。该模型设计之初是用于解决自然语言处理(NLP)任务。与 ViT 中注意力机制不同,S6 将 1D 向量中的每个元素(例如文本序列)与在此之前扫描过的信息进行交互,从而有效地将二次复杂度降低到线性。
然而,由于视觉信号(如图像)不像文本序列那样具有天然的有序性,因此无法在视觉信号上简单地对 S6 中的数据扫描方法进行直接应用。为此研究者设计了 Cross-Scan 扫描机制。Cross-Scan 模块(CSM)采用四向扫描策略,即从特征图的四个角同时扫描(见上图)。该策略确保特征中的每个元素都以不同方向从所有其他位置整合信息,从而形成全局感受野,又不增加线性计算复杂度。
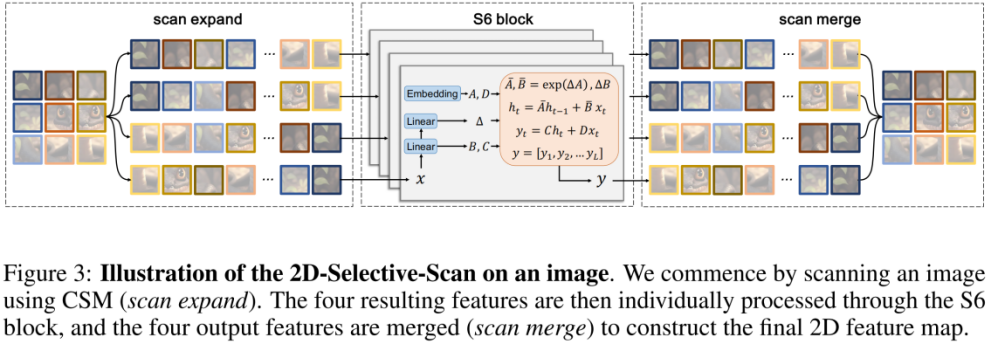
在 CSM 的基础上,作者设计了 2D-selective-scan(SS2D)模块。如上图所示,SS2D 包含了三个步骤:
scan expand 将一个 2D 特征沿 4 个不同方向(左上、右下、左下、右上)展平为 1D 向量。
S6 block 独立地将上步得到的 4 个 1D 向量送入 S6 操作。
scan merge 将得到的 4 个 1D 向量融合为一个 2D 特征输出。
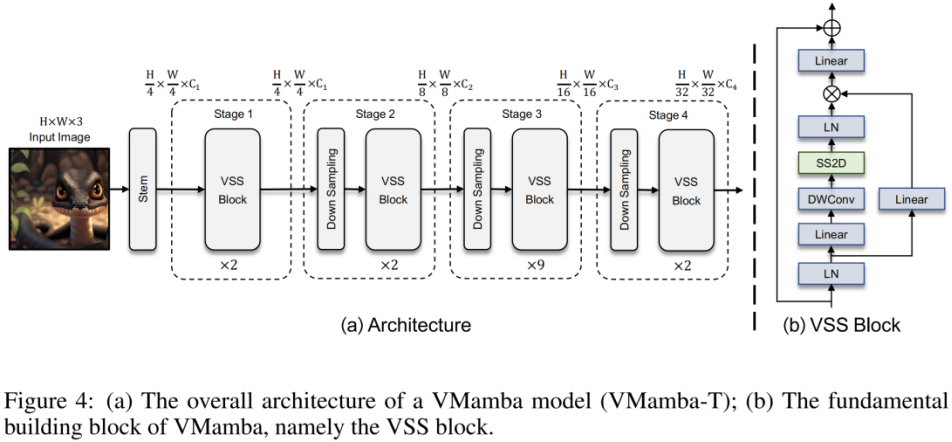
上图为本文提出的 VMamba 结构图。VMamba 的整体框架与主流的视觉模型类似,其主要区别在于基本模块(VSS block)中采用的算子不同。VSS block 采用了上述介绍的 2D-selective-scan 操作,即 SS2D。SS2D 保证了 VMamba 在线性复杂度的代价下实现全局感受野。

实验结果
ImageNet 分类
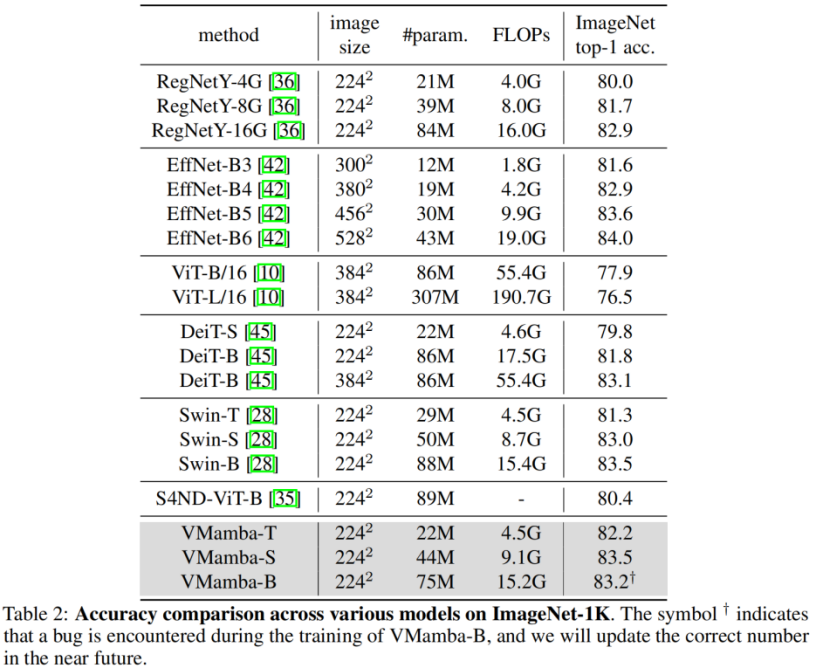
通过对比实验结果不难看出,在相似的参数量和 FLOPs 下:
VMamba-T 取得了 82.2% 的性能,超过 RegNetY-4G 达 2.2%、DeiT-S 达 2.4%、Swin-T 达 0.9%。
VMamba-S 取得了 83.5% 的性能,超过 RegNetY-8G 达 1.8%,Swin-S 达 0.5%。
VMamba-B 取得了 83.2% 的性能(有 bug,正确结果将尽快在 Github 页面更新),比 RegNetY 高 0.3%。
这些结果远高于 Vision Mamba (Vim) 模型,充分验证了 VMamba 的潜力。
COCO 目标检测
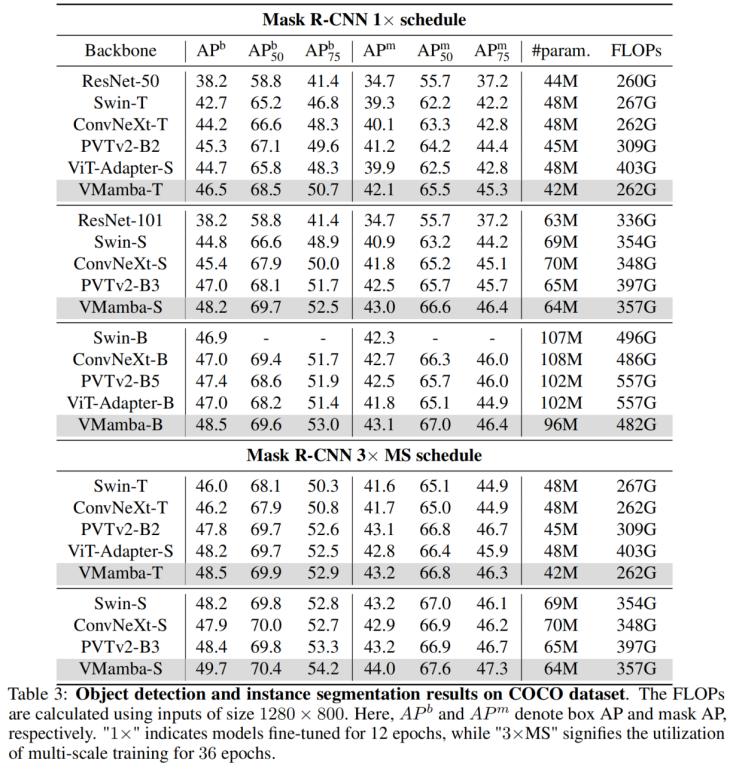
在 COOCO 数据集上,VMamba 也保持卓越性能:在 fine-tune 12 epochs 的情况下,VMamba-T/S/B 分别达到 46.5%/48.2%/48.5% mAP,超过了 Swin-T/S/B 达 3.8%/3.6%/1.6% mAP,超过 ConvNeXt-T/S/B 达 2.3%/2.8%/1.5% mAP。这些结果验证了 VMamba 在视觉下游实验中完全 work,展示出了能平替主流基础视觉模型的潜力。
ADE20K 语义分割
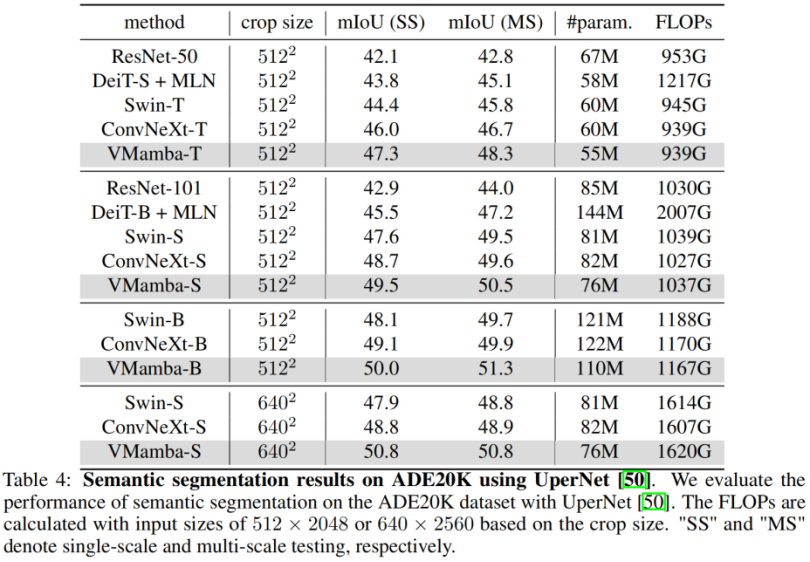
在 ADE20K 上,VMamba 也表现出卓越性能。VMamba-T 模型在 512 × 512 分辨率下实现 47.3% 的 mIoU,这个分数超越了所有竞争对手,包括 ResNet,DeiT,Swin 和 ConvNeXt。这种优势在 VMamba-S/B 模型下依然能够保持。

分析实验
有效感受野
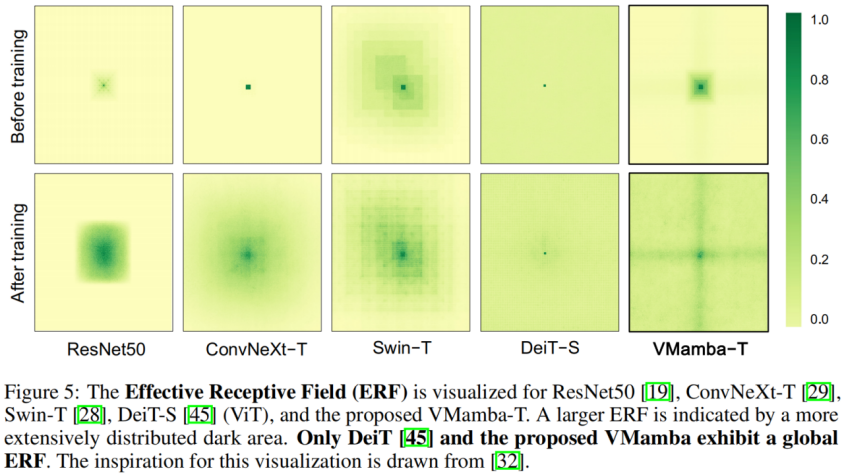
VMamba 具有全局的有效感受野,其他模型中只有 DeiT 具有这个特性。但是值得注意的是,DeiT 的代价是平方级的复杂度,而 VMamaba 是线性复杂度。
输入尺度缩放
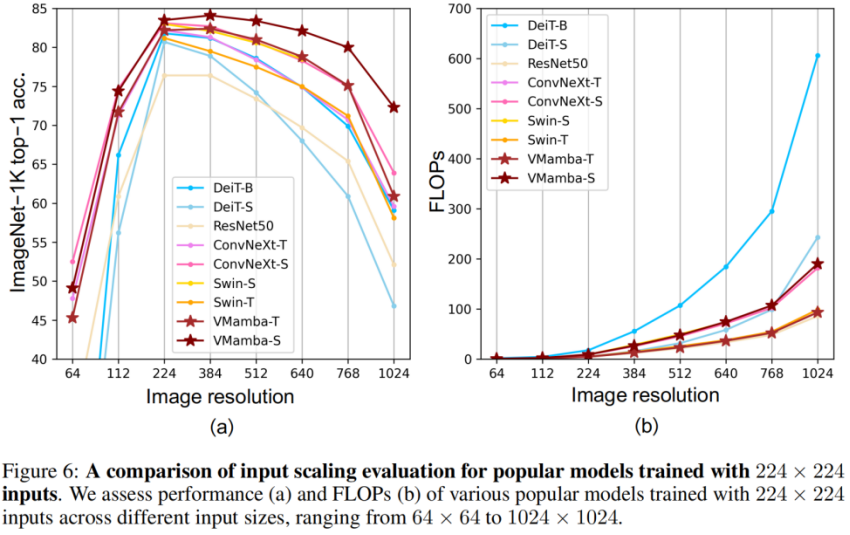
上图(a)显示,VMamba 在不同输入图像尺寸下展现出最稳定的性能(不微调)。有意思的是,随着输入尺寸从 224 × 224 增加到 384 × 384,只有 VMamba 表现出性能明显上升的趋势(VMamba-S 从 83.5% 上升到 84.0%),突显了其对输入图像大小变化的稳健性。
上图(b)显示,VMamba 系列模型随着输入变大,复杂性呈线性增长,这与 CNN 模型是一致的。
最后,让我们期待更多基于 Mamba 的视觉模型被提出,并列于 CNNs 和 ViTs,为基础视觉模型提供第三种选择。
更多阅读




#投 稿 通 道#
让你的文字被更多人看到
如何才能让更多的优质内容以更短路径到达读者群体,缩短读者寻找优质内容的成本呢?答案就是:你不认识的人。
总有一些你不认识的人,知道你想知道的东西。PaperWeekly 或许可以成为一座桥梁,促使不同背景、不同方向的学者和学术灵感相互碰撞,迸发出更多的可能性。
PaperWeekly 鼓励高校实验室或个人,在我们的平台上分享各类优质内容,可以是最新论文解读,也可以是学术热点剖析、科研心得或竞赛经验讲解等。我们的目的只有一个,让知识真正流动起来。
Copyright © 2003-2013 www.wpsshop.cn 版权所有,并保留所有权利。

