
热门标签
热门文章
- 1【粉丝福利社】《AIGC重塑金融:AI大模型驱动的金融变革与实践》(文末送书-进行中)
- 2头歌(Linux之进程管理一):第2关:进程创建操作-fork_头歌实践教学平台linux进程管理
- 3《向量数据库指南》——腾讯云向量数据库Tencent Cloud VectorDB产品特性,架构和应用场景
- 4antd Upload组件设置fileList后onChange只执行一次的解决办法_antd upload onchange
- 5Elasticsearch api查询多行空格分隔数据java解析_elasticsearch用,分隔
- 6鸿蒙listContainer 监听点击_鸿蒙点击按钮之后监听的程序
- 7利用dwebsocket在Django中使用Websocket
- 8Centos7#Linux基础富文本笔记_ftp://192.168.10.11/zabbix/repodata/repomd.xml: [e
- 9hci_uart 分析_hci_uart_rx
- 10R中读取文件,找不到路径问题 No such file or directory_error in file(file, "rt") : 无法打开链结 此外: warning mes
当前位置: article > 正文
Sora技术分解(dw00)
作者:小蓝xlanll | 2024-04-05 19:04:32
赞
踩
Sora技术分解(dw00)
Sora原理与技术实战
日程安排
名词解释
u-Net结构:encode,decode,先卷积收缩,再扩散上卷积,u形,concat方式叠加,concat方式使深层与浅层融合更充分,所以更优于FCN方式
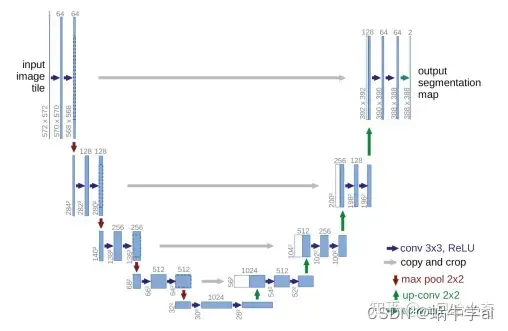
FCN结构:add方式叠加


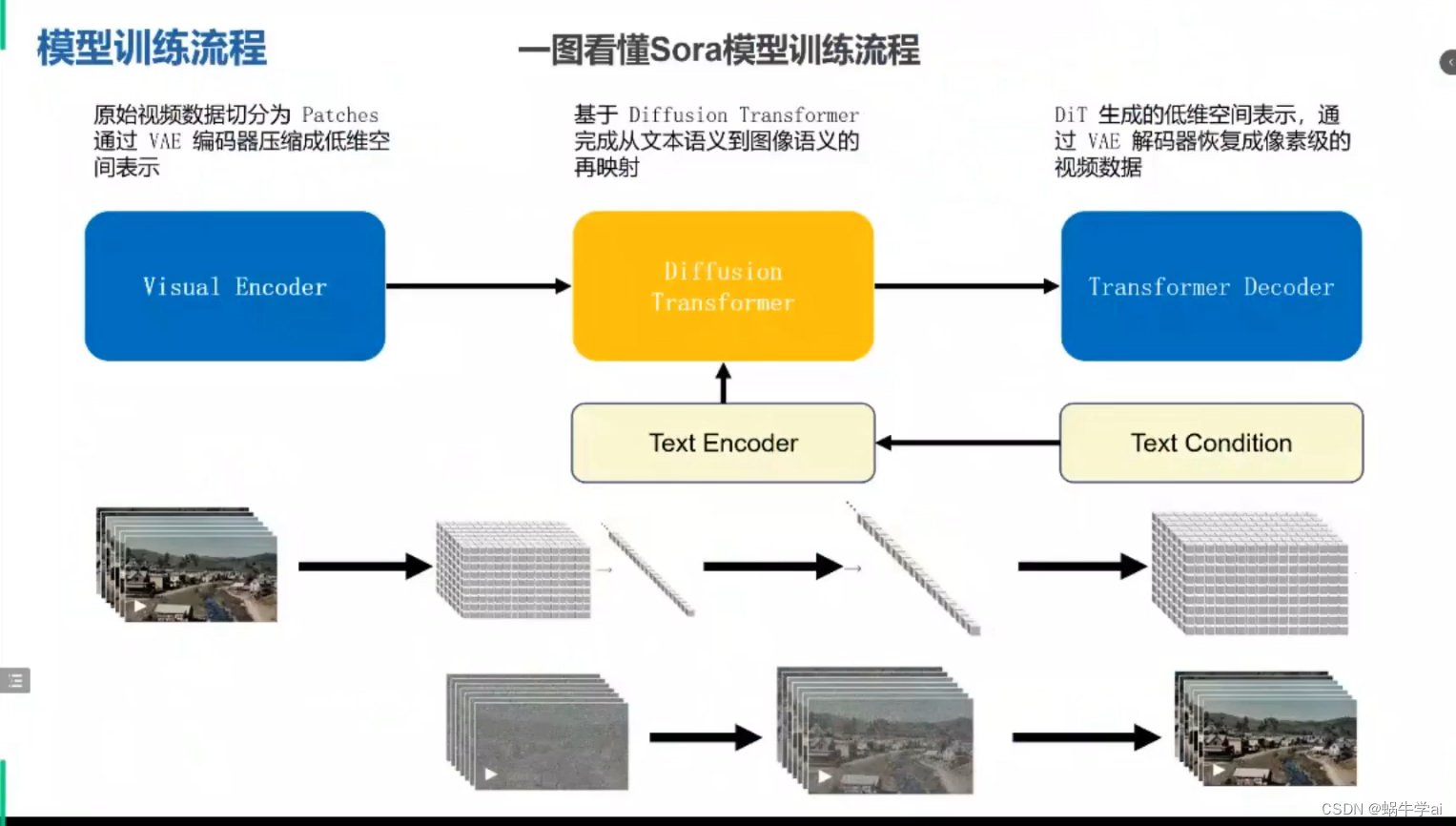
sora模型训练流程
统一不同分辨率、不同宽高比、不同格式的视频数据patchs化
diffusion model(扩散模型)
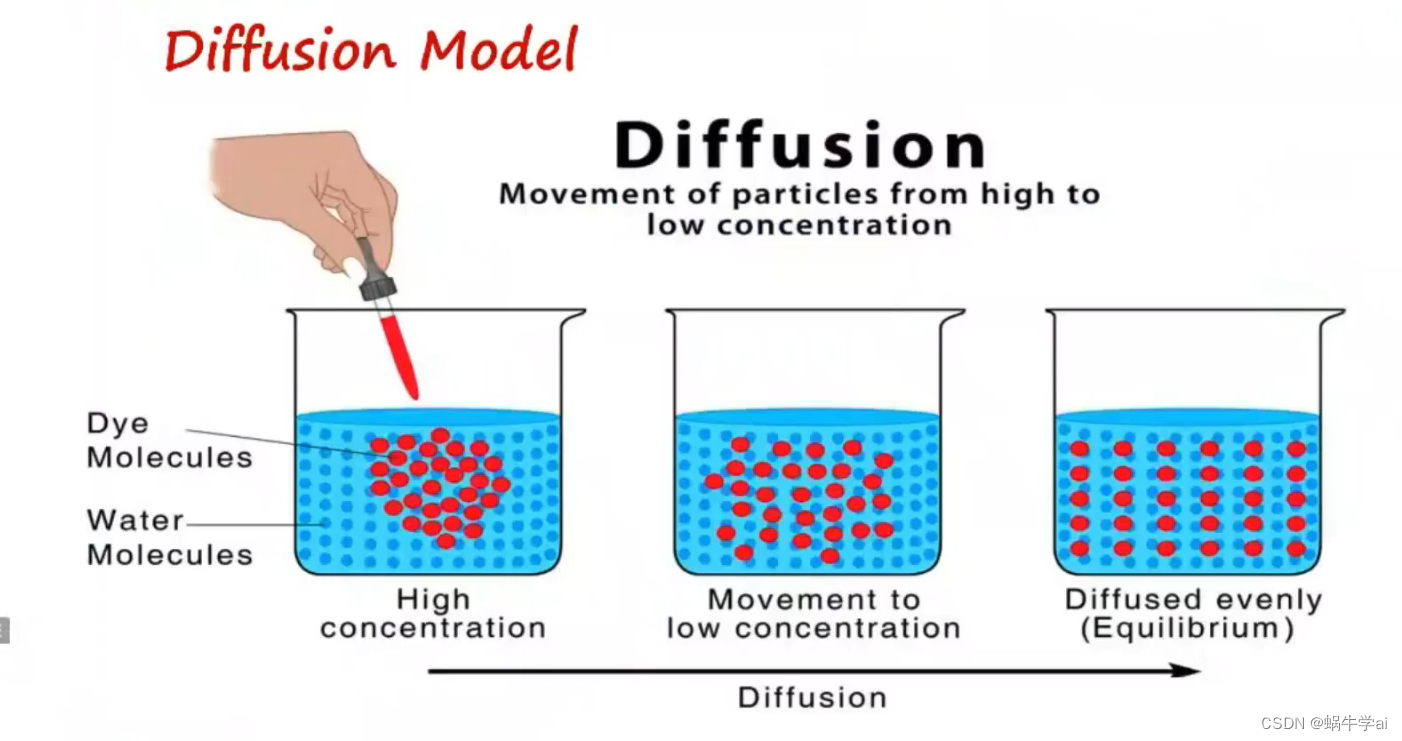
DDPM(Doiseing Diffusion Probabilistic model,改善的扩散模型)

encoder后的数据加入噪声,再去噪,decoder
基于扩散模型的主干u-net:可以限定模型规模
SD

vivit
理解时空编码:spacetime latent patches
- 摊大饼法:将每帧平铺,每帧都分patch
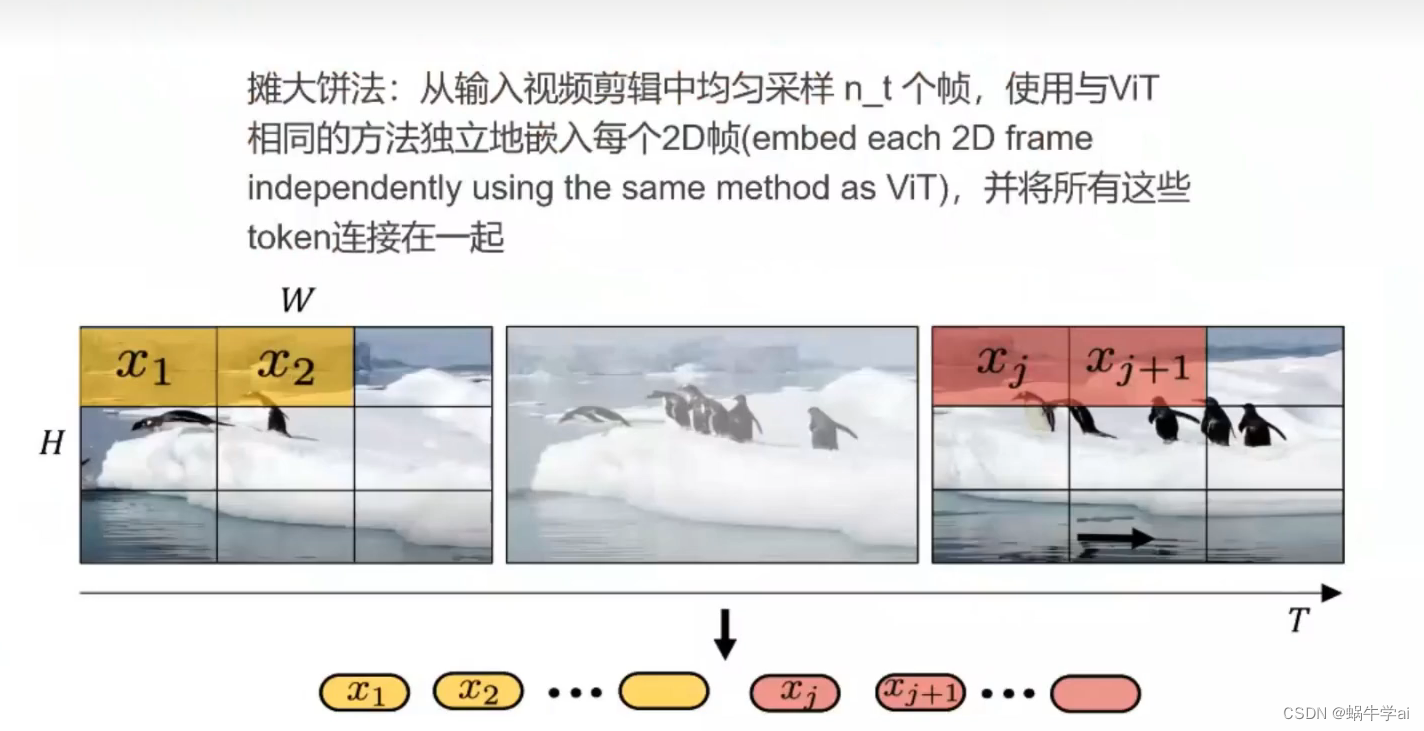
- 切块法

sora 支持不同长度、不同分辨率的输出
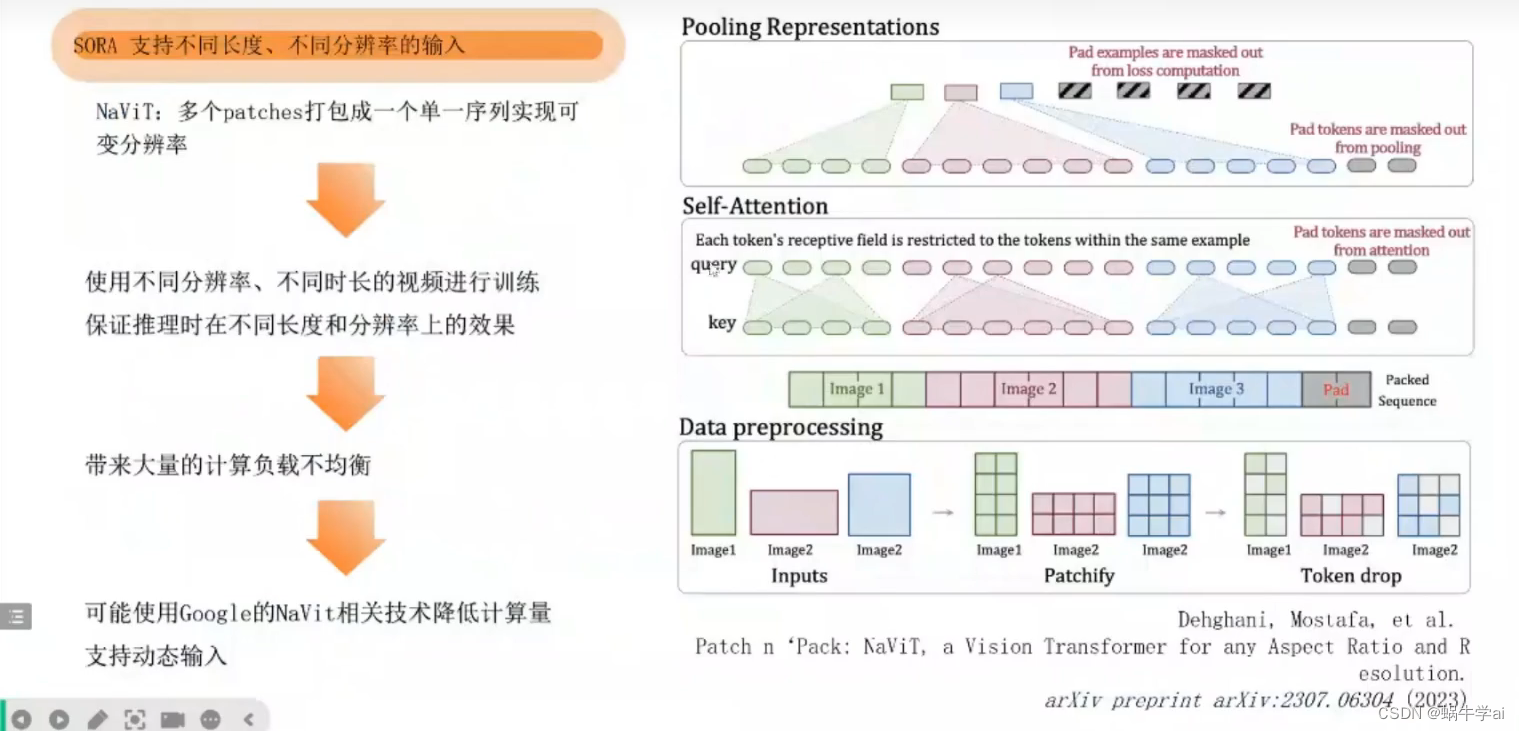
NaVit:google论文:将多个patch打包成单一的序列,就可以投喂不同分辨率,不同时长的视频,能保证输出不同分辨率,不同时长的输出;同时可以去重,如果两个patch变化率很小,可以过滤,不重复计算,减少计算量,但会造成负载不均衡,Patchify方法可以解决这个问题
scale up后视频生成质量有所提升
DiT(Diffusion Transformer) = VAEencoder+Vit+DDPM+VAE
DiT利用transformer 结构探索新的扩散模型,成功用tranformer替换U-Net主干
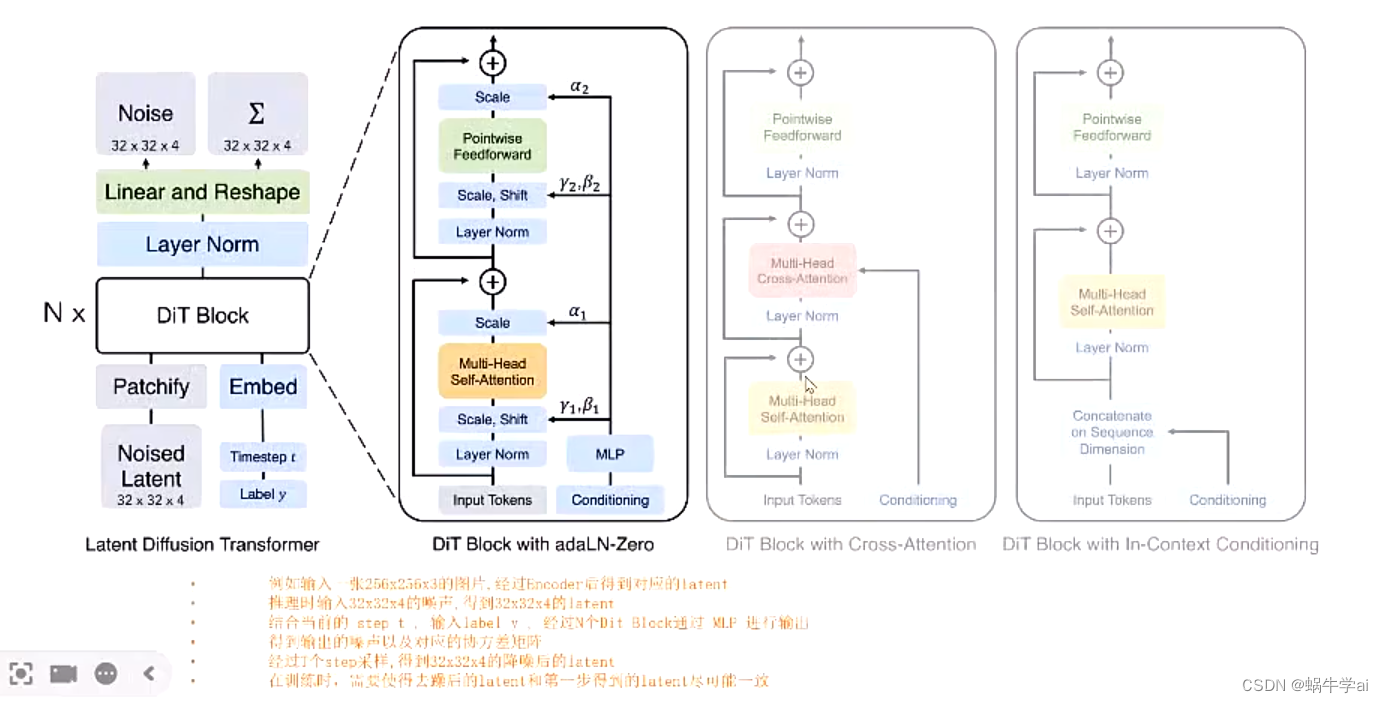
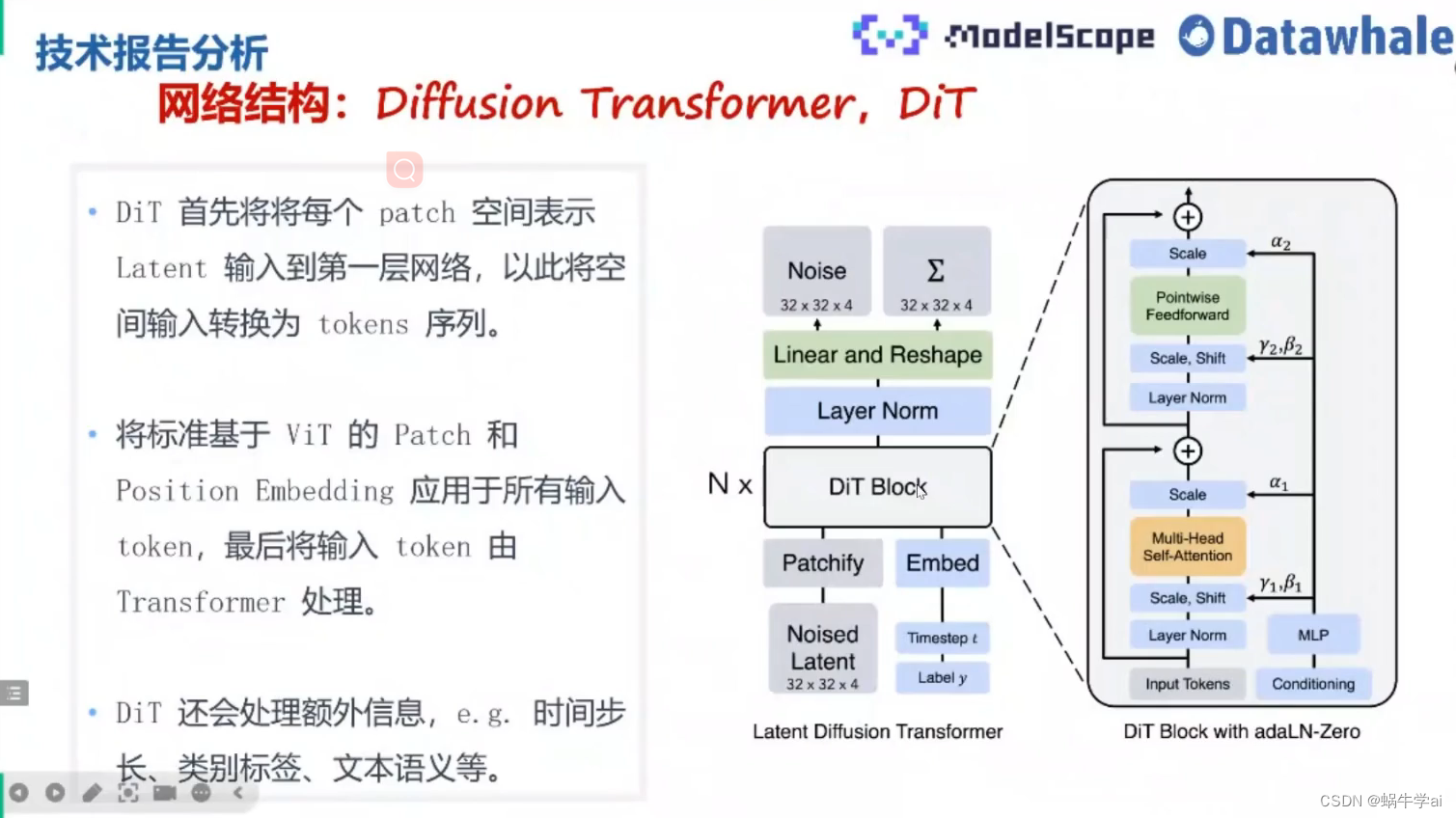
DALLE2

以上都是推理可能使用到的技术
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/小蓝xlanll/article/detail/367470
推荐阅读
相关标签

