
- 1java8新特性_18_新时期与日期API_本地时间和时间戳_18may20java
- 2【Pytorch】torchtext终极安装方法及常见问题_torchtext安装
- 3rasa.core.agent - Could not load model due to No NLU or Core data for unpacked model at: '/tmp/tmpc...
- 4光标 与 输入法 之 android:imeOptions属性_代码设置 android:imeoptions="actionsearch
- 5鸿蒙开发学习教程大全:从入门到精通的全攻略_鸿蒙开发教程
- 6Linux 搭建 JumpServer 堡垒机_linux搭建jumpserver
- 7AI > 语音识别开源项目列举_ai语音识别开发
- 8数据结构——双向循环链表
- 9LTP4.2.0 哈工大分词 库python使用踩坑_安装ltp哈工大
- 10【开题报告】基于SpringBoot的社区老人健康跟踪管理系统设计与实现_基于springboot的养老服务平台的设计与实现的开题报告在,写
悟道·天鹰 Aquila + 天秤 FlagEval,打造大模型能力与评测标准双标杆_悟道·天鹰aquila语言大模型 源码
赞
踩
为推动大模型在产业落地和技术创新,智源研究院发布“开源商用许可语言大模型系列+开放评测平台” 2 大重磅成果,打造“大模型进化流水线”,持续迭代、持续开源开放。
开源商用许可语言大模型系列
悟道·天鹰(Aquila) 语言大模型是首个具备中英双语知识、支持商用许可协议、国内数据合规需求的开源语言大模型。
悟道·天鹰(Aquila)语言大模型在中英文高质量语料基础上从 0 开始训练,通过数据质量的控制、多种训练的优化方法,实现在更小的数据集、更短的训练时间,获得比其它开源模型更优的性能。系列模型包括 Aquila基础模型(7B、33B),AquilaChat对话模型(7B、33B)以及 AquilaCode-7B “文本-代码”生成模型,后续将持续更新迭代并开源更新版本。
开源地址:
https://github.com/FlagAI-Open/FlagAI/tree/master/examples/Aquila
Aquila基础模型(7B、33B)在技术上继承了 GPT-3、LLaMA 等的架构设计优点,替换了一批更高效的底层算子实现、重新设计实现了中英双语的 tokenizer,升级了 BMTrain 并行训练方法,实现了比 Magtron+DeepSpeed ZeRO-2 将近8倍的训练效率。
AquilaChat 对话模型(7B、33B)支持流畅的文本对话及多种语言类生成任务,通过定义可扩展的特殊指令规范,实现 AquilaChat对其它模型和工具的调用,且易于扩展。例如,调用智源开源的 AltDiffusion 多语言文图生成模型,实现了流畅的文图生成能力。配合智源 InstructFace 多步可控文生图模型,轻松实现对人脸图像的多步可控编辑。
AquilaChat 训练过程中,实现了模型能力与指令微调数据的循环迭代,包括数据集的高效筛选与优化,充分挖掘基础模型的潜力。

AquilaChat 支持可扩展的特殊指令规范,令用户可在AquilaChat中轻松实现多任务、工具的嵌入,如文图生成,下图示例为在对话中调用智源开源的多语言文图生成模型 AltDiffusion。
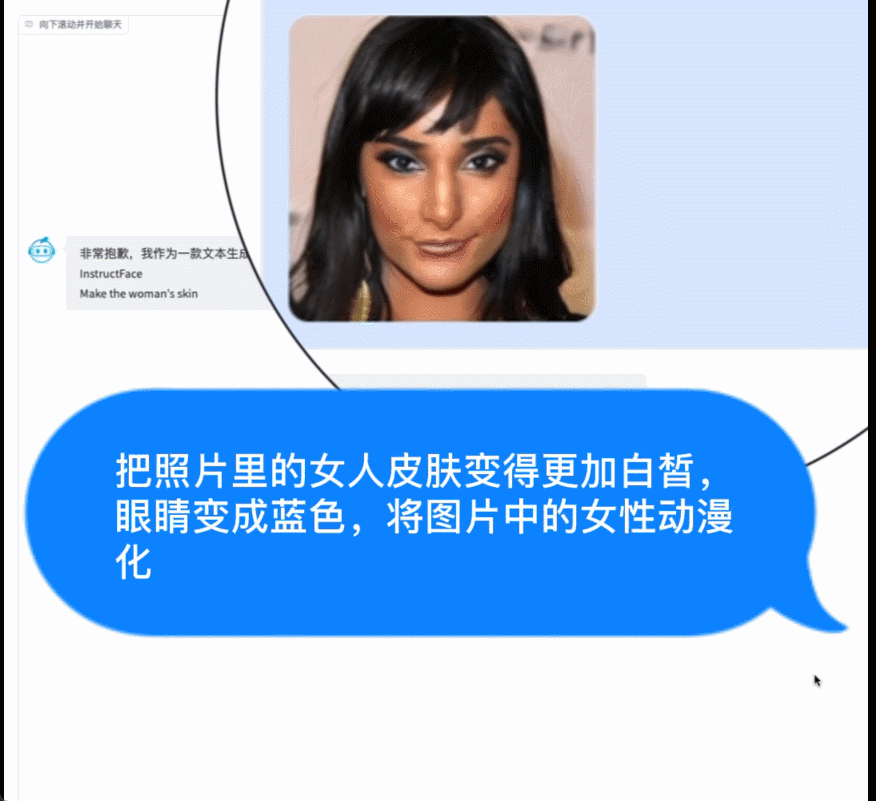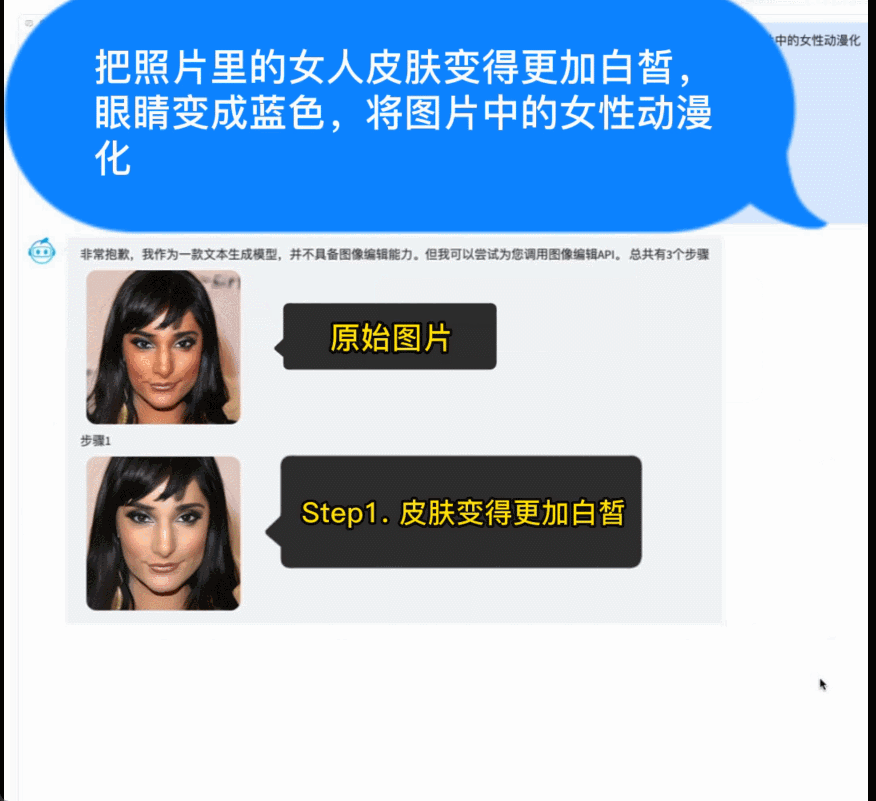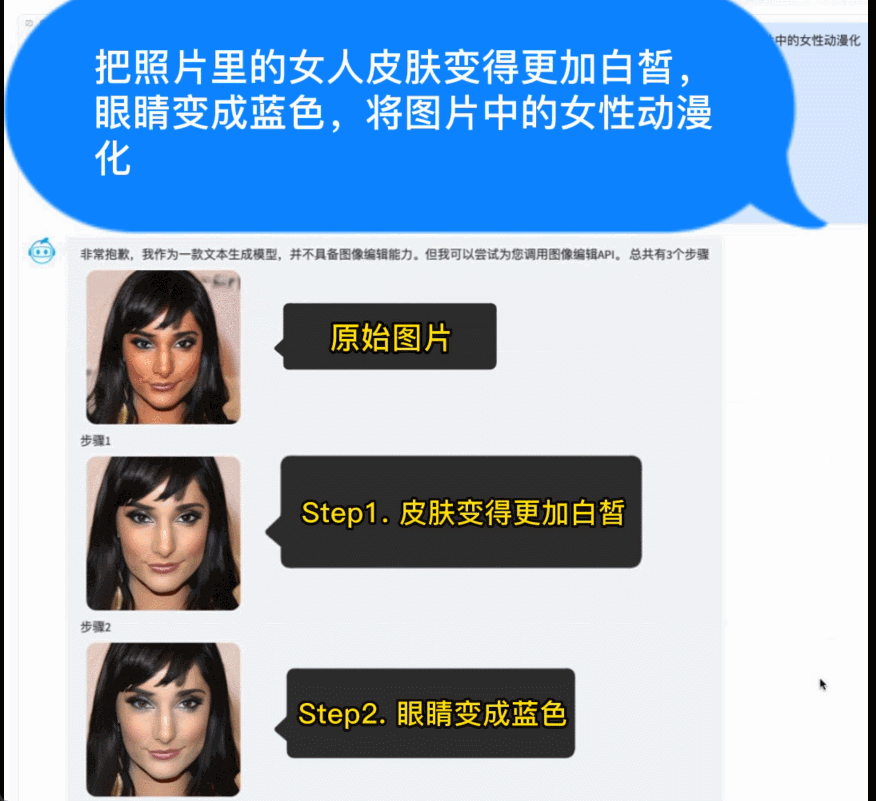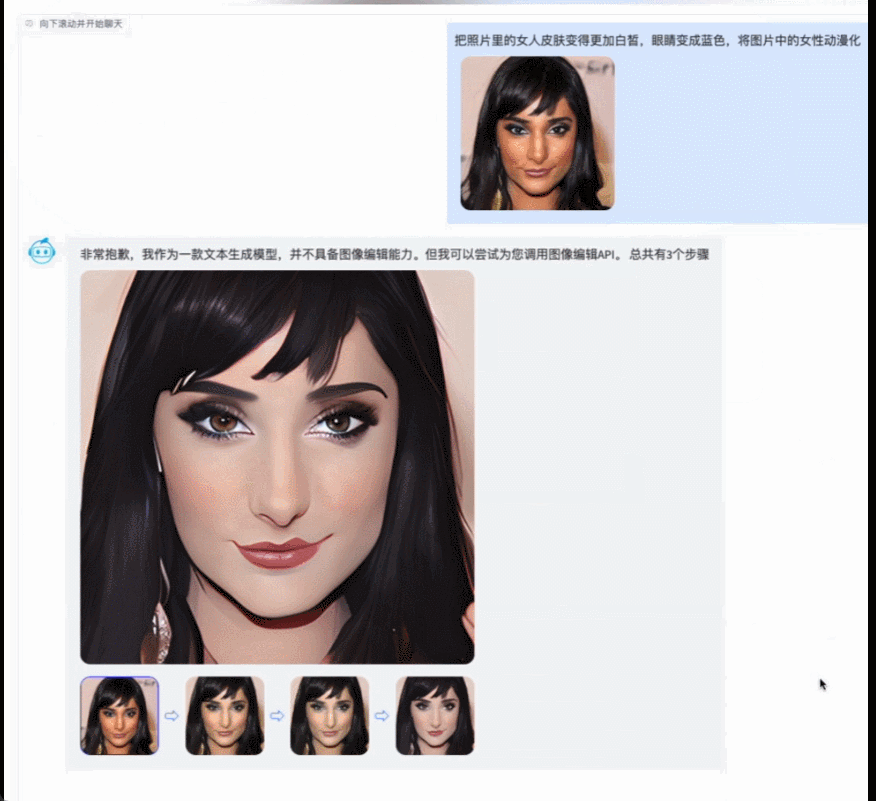
AquilaChat 具备强大的指令分解能力,配合智源InstructFace多步可控文生图模型,轻松实现对图片的多步可控编辑。
AquilaCode-7B “文本-代码”生成模型,基于 Aquila-7B 强大的基础模型能力,以小数据集、小参数量,实现高性能,是目前支持中英双语的、性能最好的开源代码模型,经过了高质量过滤、使用有合规开源许可的训练代码数据进行训练。
此外,AquilaCode-7B 分别在英伟达和国产芯片上完成了代码模型的训练,并通过对多种架构的代码+模型开源,推动芯片创新和百花齐放。
大模型评测体系及开放平台
天秤(FlagEval)大模型评测体系及开放平台,旨在建立科学、公正、开放的评测基准、方法、工具集,协助研究人员全方位评估基础模型及训练算法的性能,同时探索利用AI方法实现对主观评测的辅助,大幅提升评测的效率和客观性。目前已推出语言大模型评测、多国语言文图大模型评测及文图生成评测等工具,并对各种语言基础模型、跨模态基础模型实现评测。后续将全面覆盖基础模型、预训练算法、微调算法等三大评测对象,包括自然语言处理(NLP)、计算机视觉(CV)、语音(Audio)及多模态(Multimodal)等四大评测场景和丰富的下游任务。
首期推出的 FlagEval 大语言模型评测体系,创新构建了“能力-任务-指标”三维评测框架,细粒度刻画基础模型的认知能力边界,可视化呈现评测结果,总计 600+ 评测维度,任务维度包括 22 个主观&客观评测数据集。除了知名的公开数据集 HellaSwag、MMLU、C-Eval等,FlagEval 还集成了包括智源自建的主观评测数据集 Chinese Linguistics & Cognition Challenge (CLCC) ,北京大学与闽江学院共建的语义关系判断、多义词理解、修辞手法判断评测数据集。更多维度的评测数据集也在陆续集成中。
FlagEval 评测榜单目前涵盖了前面谈到的22 个主观和客观评测集,84433 道题目,细粒度刻画大模型的认知能力。基于“悟道 · 天鹰”Aquila 基础模型(7B)打造的 AquilaChat 对话模型,在 FlagEval 大语言模型评测榜单上,目前暂时在“主观+客观”的评测上领先其他同参数量级别的开源对话模型。
在我们当前的最新评测结果中,AquilaChat 以大约相当于其他模型 50% 的训练数据量(SFT 数据+预训练数据分别统计)达到了最优性能。但由于当前的英文数据仅训练了相当于Alpaca的40%,所以在英文的客观评测上还暂时落后于基于 LLaMA 进行指令微调的Alpaca。随着后续训练的进行,我们相信很快可以超越。
悟道·天鹰(Aquila)模型还在迭代进步的过程中,天秤(FlagEval)评测能力也在不断的扩充中, 因而此评测结果只是暂时的,新的评测结果还会不断更新。此外,FlagEval的评测体系方法及相关研究还需要继续深入,当前对模型能力的覆盖程度仍有很大的进步空间,智源也期待与多方合作,共同打造全面、科学的评测方法体系。

