
- 1CREO:CREO软件之工程图界面的【创建】、【布局】、【表】、【注释】的简介(图文教程)之详细攻略_creo的工程图绘制图元如何恢复成布局视图
- 2解决:宿主机无法访问linux下docker容器中的服务_linux 服务器存在监听 docker 不能访问
- 3实力见证!黑马2023年度就业报告新鲜出炉,这份成绩单,漂亮!_黑马java学科2023年就业报告
- 4tensorflow笔记-文本情感分类_tensorflow文本情感分类
- 5空指针在java中的环境配置,轻松搞定项目中的空指针异常Caused by: java.lang.NullPointerException: null...
- 6jvm的垃圾回收策略
- 7Android MediaCodec播放h.264文件dequeueOutputBuffer一直返回-1
- 8ffmpeg添加MP4的pcm音频支持_ffmpeg mp4 alac
- 9Linux文件搜索工具(gnome-search-tool)
- 10在M1芯片的MacBookPro上编译并运行 Verilog 代码_mac用什么编写verilog
[转]深度学习 Transformer架构解析_transformer架构拆解
赞
踩
原文链接:https://blog.csdn.net/mengxianglong123/article/details/126261479
1.1 Transformer的诞生
2018年10月,Google发出一篇论文《BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding》, BERT模型横空出世, 并横扫NLP领域11项任务的最佳成绩!
论文地址: https://arxiv.org/pdf/1810.04805.pdf
而在BERT中发挥重要作用的结构就是Transformer, 之后又相继出现XLNET,roBERT等模型击败了BERT,但是他们的核心没有变,仍然是:Transformer.
1.2 Transformer的优势
相比之前占领市场的LSTM和GRU模型,Transformer有两个显著的优势:
Transformer能够利用分布式GPU进行并行训练,提升模型训练效率.
在分析预测更长的文本时, 捕捉间隔较长的语义关联效果更好.
下面是一张在测评比较图:
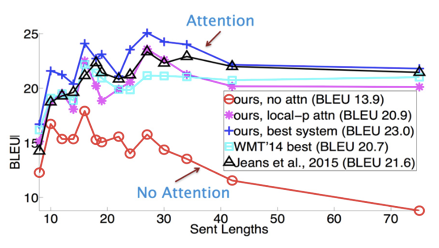
1.3 Transformer的市场
在著名的SOTA机器翻译榜单上, 几乎所有排名靠前的模型都使用Transformer,
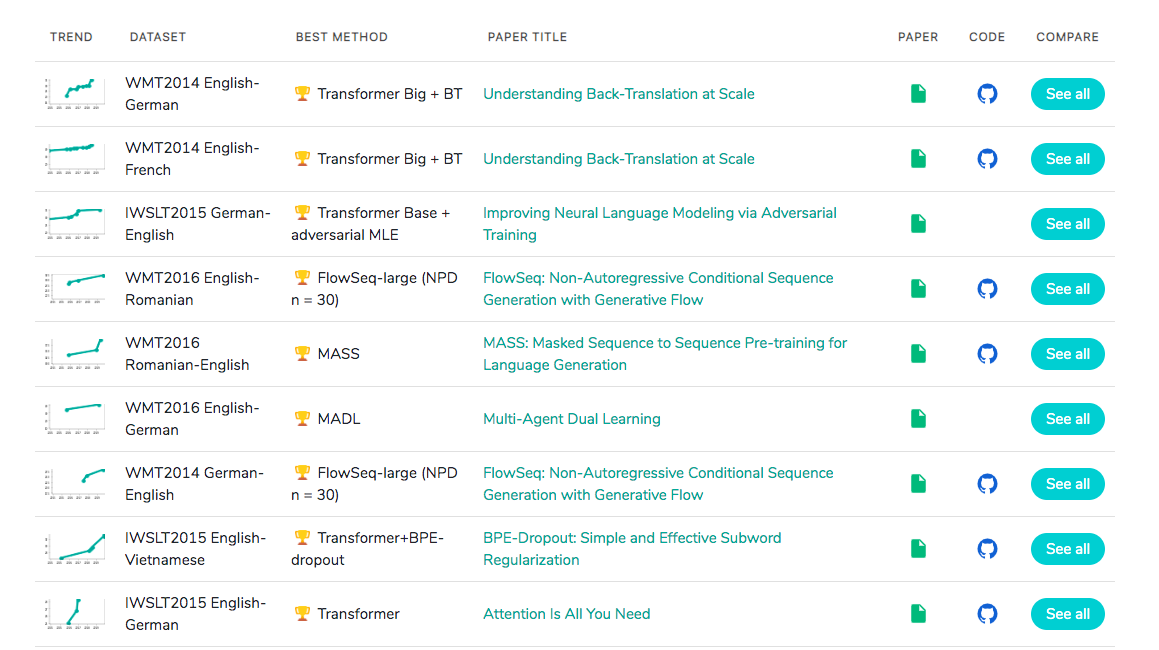
其基本上可以看作是工业界的风向标, 市场空间自然不必多说!
二、Transformer架构解析
2.1 认识Transformer架构
2.1.1 Transformer模型的作用
基于seq2seq架构的transformer模型可以完成NLP领域研究的典型任务, 如机器翻译, 文本生成等. 同时又可以构建预训练语言模型,用于不同任务的迁移学习.
声明:
在接下来的架构分析中, 我们将假设使用Transformer模型架构处理从一种语言文本到另一种语言文本的翻译工作, 因此很多命名方式遵循NLP中的规则. 比如: Embeddding层将称作文本嵌入层, Embedding层产生的张量称为词嵌入张量, 它的最后一维将称作词向量等.
2.1.2 Transformer总体架构图
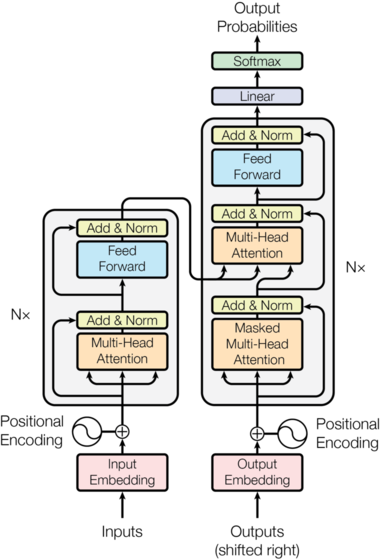
Transformer总体架构可分为四个部分:
输入部分
输出部分
编码器部分
解码器部分

