
热门标签
热门文章
- 1深圳Uniop触摸屏维修ETOP06-0050工业电脑人机界面显示屏维修
- 2关于VS2019安装失败,由于某文件损坏解决方法_incredibuild9.3.7 安装vs2019失败
- 3什么是软件设计中的上游和下游?_系统架构上游下游怎么区分
- 4android开发:无序广播和有序广播区别_android有序广播和无序广播的区别
- 5200基于matlab的利用神经网络算法训练图片
- 6文心一言、讯飞星火、GPT、通义千问等线上API调用示例
- 7Wireshark命令行工具tshark使用小记_tshark查看长度
- 8软件项目投标技术标书模板_软件技术 投标
- 9编织数据经纬,洞见业务全景:Elasticsearch、Logstash与Kibana的铁三角关系深度解析
- 10使用 RxJava 进行响应式编程_响应式编程rxjava
当前位置: article > 正文
LLM推理参数(top_k,top_p, temperature, num_beams)
作者:小蓝xlanll | 2024-04-07 01:43:14
赞
踩
LLM推理参数(top_k,top_p, temperature, num_beams)
正常LLM做 next token predicate 时,对输出的 logits 做 softmax,选择概率最大的token。
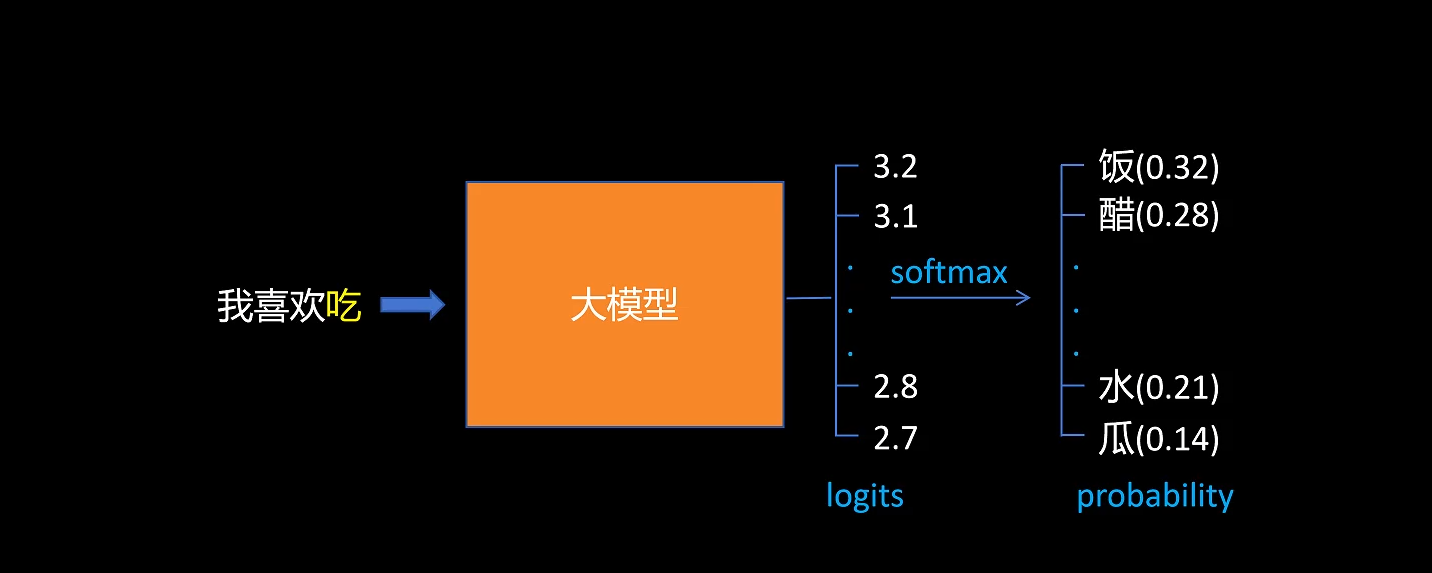
-
num_beams :当我们设置 num_beams=2 后,就使用了 beam search 的方法,每次不是只直接选择概率最大的 token,而是保留 num_beams 个概率最大的 token 选择,接着进行下一轮的 next token predicate,把两次预测的 token的 联合概率作为选择标准,选取联合概率最大的分支。
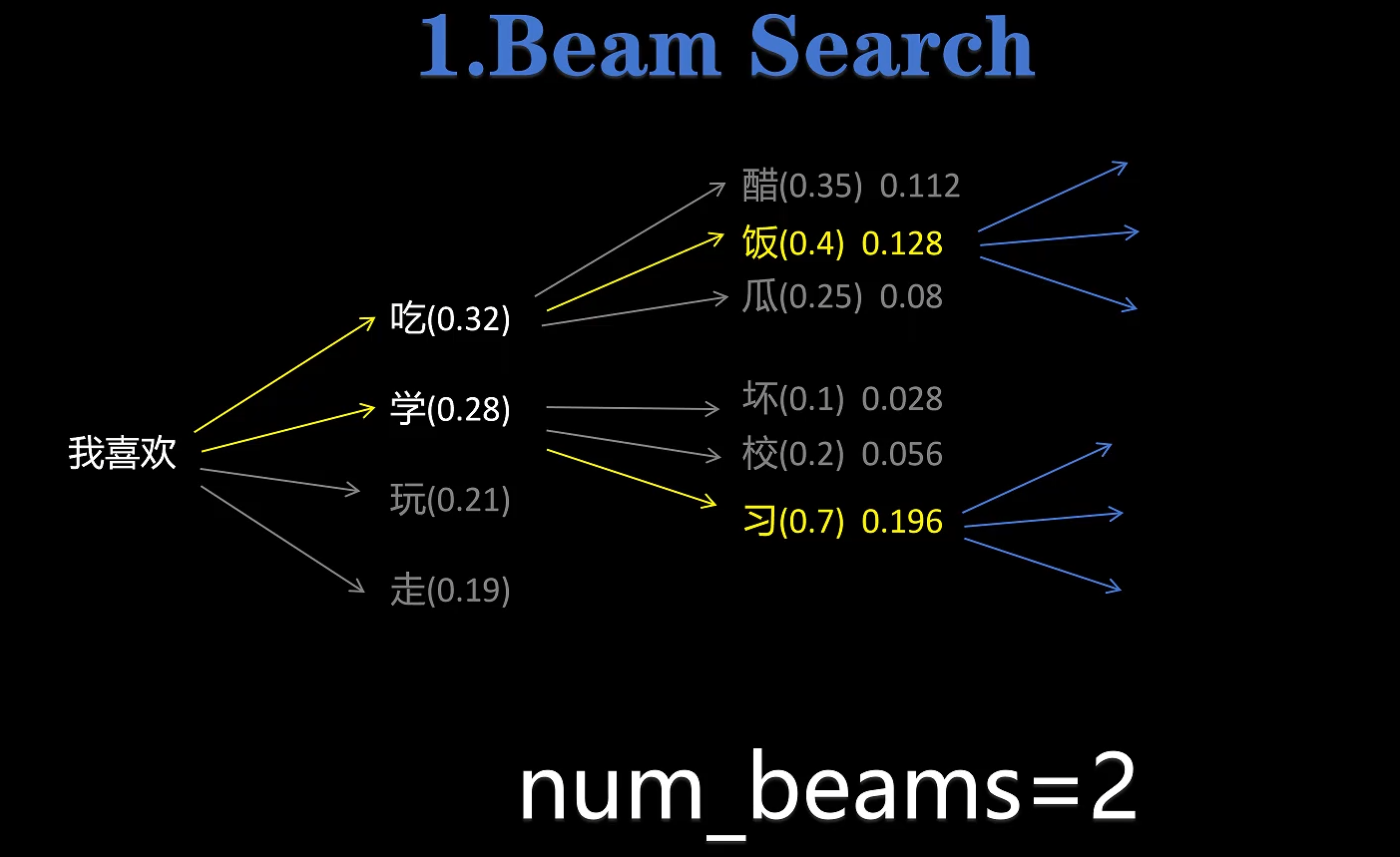
-
top_k:当我们设置top_k=2之后,会对LLM输出的 logits 保留 top_k 个最大的,然后其他 token 的 logits 设置为负无穷-inf,再对所有 logits 进行 softmax,那么-inf就会变成0,选概率最大的token即可。实现了在top_k个概率最大的 token 中选取。

-
top_p:当我们设置top_p=0.8之后,对每个token的softmax的概率累积求和,当概率达到top_p之后,后面概率更小的token概率设置为-inf,然后再经过一次softmax重新分配概率,取概率最大的token。

-
temperature:当我们设置temperature=[0,2]之后,就是对softmax进行调节。temperature越大,softmax得到的各个token概率越平均,生成的随机性越大。


声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/小蓝xlanll/article/detail/375598
推荐阅读
相关标签

