
热门标签
热门文章
- 1Android AAChartView饼图开发_android aachatcore
- 2为什么LLM都用的Decoder only结构?_encoder的模型是在训练的时候一直在做完形填空
- 3Pytorch实现RNN进行文本(情感)分类_torch rnn可以做文本分类吗
- 4Spring boot 结合Mockito、junit、MockMVC_springboot 集成mockito
- 5【CVPR红外小目标检测】红外小目标检测中的非对称上下文调制(ACM)_asymmetric contextual modulation for infrared smal
- 6RAG 全链路评测工具 —— Ragas_ragas算法
- 7【ChatGPT4】王老师零基础《NLP》(自然语言处理)第一课_nlp在chatgpt上的基础知识
- 8国内首场高规格AIGC峰会盛况出圈!万字干货热聊GPT-4时代,浓缩21位大牛演讲_nolibox 汽车 合作
- 9从零开始学数据分析之数据分析概述
- 10数字人添加背景(heygen+剪映)_heygen数字人
当前位置: article > 正文
一文读懂Llama 2(从原理到实战)_llama2 数据格式
作者:小蓝xlanll | 2024-04-07 02:07:34
赞
踩
llama2 数据格式
简介
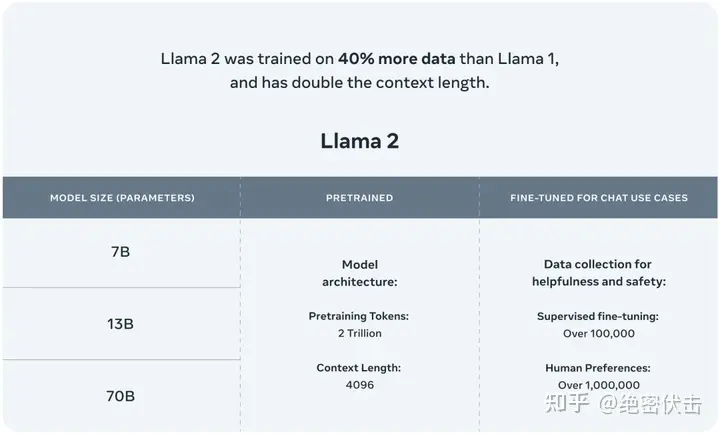
Llama 2,是Meta AI正式发布的最新一代开源大模型。
Llama 2训练所用的token翻了一倍至2万亿,同时对于使用大模型最重要的上下文长度限制,Llama 2也翻了一倍。Llama 2包含了70亿、130亿和700亿参数的模型。Meta宣布将与微软Azure进行合作,向其全球开发者提供基于Llama 2模型的云服务。同时Meta还将联手高通,让Llama 2能够在高通芯片上运行。
Llama 2是一系列预训练和微调的大型语言模型(LLMs),参数规模从70亿到700亿不等。Meta的微调LLMs,叫做Llama 2-Chat,是为对话场景而优化的。Llama 2模型在大多数基准上都比开源的对话模型表现得更好,并且根据人类评估的有用性和安全性,可能是闭源模型的合适替代品。Meta提供了他们对Llama 2-Chat进行微调和安全改进的方法的详细描述。


github地址:https://github.com/facebookresearch/llama-recipes
开源7B、13B、70B模型(7B模型约12.5GB,13B模型需要24.2GB)
实战:微调Llama 2
- 1.首先我们从github上下载Llama 2的微调代码:
git clone https://github.com/facebookresearch/llama-recipes .
- 1
- 2.下载完成之后,安装对应环境,执行命令:
pip install -r requirements.txt
- 1
- 3.接着我们从HuggingFace上下载模型,可以看到目前有多个版本可供选择,这里我们就选择Llama-2-7b-half:
import huggingface_hub
huggingface_hub.snapshot_download(
"meta-llama/Llama-2-7b-hf",
local_dir="./Llama-2-7b-hf",
token="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"
)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
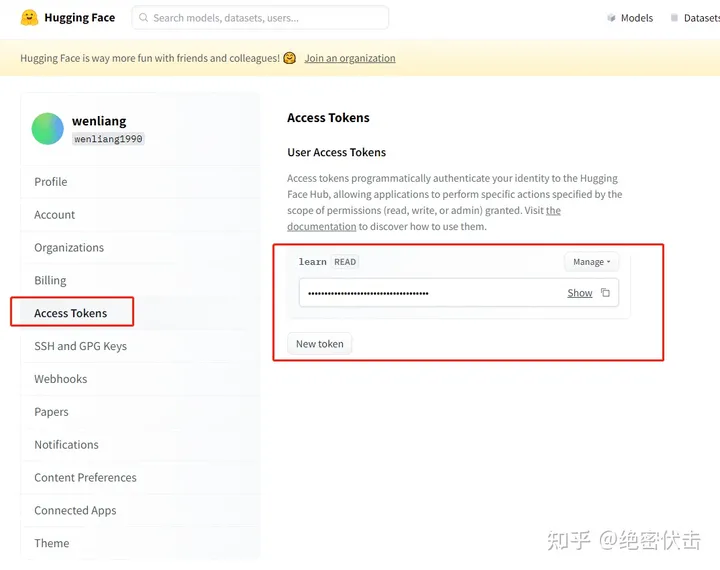
这里的token可以在HuggingFace中获取,如下图所示:
- 4.下载数据,这里选择GuanacoDataset数据集。数据格式如下:

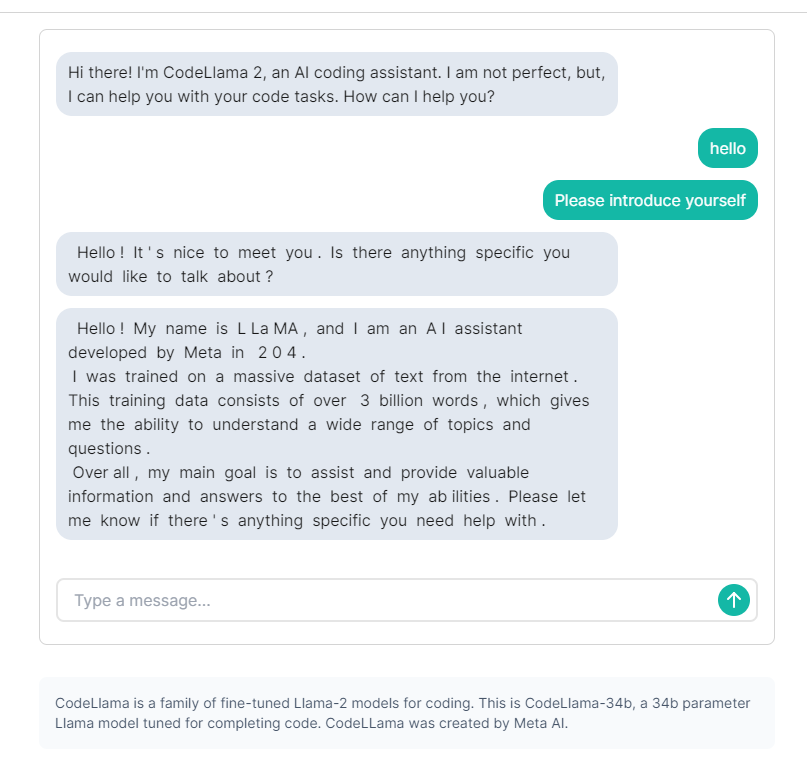
在线体验
参考
https://github.com/facebookresearch/llama-recipes
https://zhuanlan.zhihu.com/p/653303123
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/小蓝xlanll/article/detail/375731
推荐阅读
相关标签

