
- 1linux服务器安装openvpn_easy-rsa下载
- 2马蹄集 oj赛(双周赛第二十二次)_oj赛双周赛第22次
- 3IDEA中配置Git_idea配置git
- 4每日一题(leetcode31):下一个排列-思维
- 5标准库unsafe:带你突破golang中的类型限制_golang unsafe
- 6【Axure视频教程】在指定位置添加行_axure新增行
- 7【论文阅读笔记】Customized Segment Anything Model for Medical Image Segmentation
- 8webrtc-streamer下载编译
- 9Vscode搭建TS环境_vscode 如何默认用tsconfig
- 10基于javaweb的宠物医院预约挂号系统(java+JSP+Spring+SpringBoot+MyBatis+html+layui+maven+Mysql)_javaweb(springboot+mybatis)宠物医院预约管理系统设计
YOLOv2目标检测算法——通俗易懂的解析
赞
踩
YOLOv2目标检测算法
前沿
前面我们讲过了YOLOv1目标检测算法,不了解的小伙伴可以参考一下博文:
这篇文章我们仍然通俗的介绍下YOLOv2,YOLOv2又叫做YOLO9000,顾名思义,就是能够检测出9000种类别(有点夸张了,实际上根本做不到,不过作者提到的思路倒是很值得借鉴)。
YOLOv2对YOLOv1做了很多的改进,如加了BN,anchor,多尺度训练等tricks。YOLOv2是YOLO系列承上启下的算法,可以说YOLO算法真正的开始算是从YOLOv2开始的,当然这也不是说YOLOv1你不用了解了,了解YOLOv1对学习后面的YOLO系列具有很大的帮助。
YOLOv1属于YOLO系类的最初版本,存在着很多的问题,如recall比较低、准确度差、定位能力差、检测小目标和密集型目标性能很差等问题。我们看一下YOLOv1跟他那个时代已经存在的目标检测模型进行比较。

上面讲了YOLOv1存在四个问题,recall比较低、准确度差、定位能力差、检测小目标和密集型目标性能很差,于是YOLOv2就尝试着对YOLOv1进行改进,尝试解决这些问题。下面我们正式进入YOLOv2的讲解。
一.YOLOv2的改进
YOLOv2采取了各种各样的手段对YOLOv1做改进:
- BN
- High Resolution Classifier(高分辨率的分类器)
- Anchor(通过聚类得到)
- Dimension Cluster
- Direct location prediction
- Fine-Grained Feature
- Multi-Scale Training
下面我们一个一个的来看上面的tricks分别都做了什么事情
1.1.BN
BN就是Batch Normalization,批标准化,BN做了什么事情呢?实际上他就是对神经元的输出进行一个归一化的操作,把每个神经元的输出减去均值再除以标准差变成一个以0为均值,1为标准差的一个分布的过程。为什么要进行这个BN操作呢,不做行不行呢? 我们知道很多激活函数如:sigmoid,tanh激活函数,他们在0附近是非饱和区(关于什么是饱和区什么是非饱和区请参考:激活函数中的硬饱和,软饱和,左饱和和右饱和)。如果神经元的输出太大或者太小的话就会陷入激活函数的饱和区,饱和区就意味着梯度消失(导数为0),导致模型难以训练,所以我们通过BN 强行的把神经元的输出集中到0附近。BN 是包含测试阶段和训练阶段的,尤其要注意测试阶段是怎么处理的,用不好反而适得其反,具体可以参考:Batch Normalization详解以及pytorch实验以及我的一篇博文关于BN和LN的简单介绍:Batchnorm和Layernorm的区别。通过上面的对BN层的介绍,我们不难得出BN层一般放在输出特征层的后面,激活函数的前面。总结一下BN层有哪些好处:
- 加快模型训练的收敛速度
- 改善梯度,远离饱和区
- 可以使用大的学习率,使得模型对初始化不敏感(如果没有使用
BN层就有可能导致神经元的输出都在非饱和区,所以经过BN之后对初始化的敏感度就降低了。)- 起到正则化的作用,防止过拟合甚至可以起到
dropout层。 这里留一个问题:BN和dropout都可以防止过拟合,为什么他们两个一块用不行?
具体可参考:BN和Dropout同时使用的问题

1.2.High Resolution Classifier
一般模型的训练都是以
224
×
224
224\times224
224×224尺寸大小在ImageNet上进行训练的,而我们的YOLOv1模型最后的输入图像时
448
×
448
448\times448
448×448,如果一个模型原来是在小尺寸上进行训练的现在又在大尺寸上进行训练,那么网络就要学会切换这两种分辨率会带来模型性能的下降。YOLOv2怎么解决这个问题呢?作者用了最简单粗暴方法,直接在分类图像数据集上以
448
×
448
448\times448
448×448的尺寸进行骨干网络的训练,让网络适应大分辨率。实际上作者训练的时候是只在分类图像训练骨干网络的最后10个eopchs切换到
448
×
448
448\times448
448×448,节省训练时间。通过使用High Resolution Classifier,模型提高了3.5%mAP。
1.3.anchor

anchor是YOLOv2的核心。YOLOv3,YOLOv4,YOLOv5也是用anchor机制,近期的一些目标检测算法开始使用anchor free机制。下面我们来讲下什么是anchor机制。我们在YOLOv1里面没有使用anchor机制,直接使用两个bounding box,谁跟ground truth的
I
o
U
IoU
IoU大,谁负责去拟合这个ground truth。这个时候可能会遇到一个问题,这两个bounding box是不受任何约束的,想怎么变怎么变,想多大就多大,想多宽就多宽,不受约束,你觉得让这样的完全不受限制的框去拟合ground truth好吗,他能够很准确的预测出待检测物体吗?我们不能说他不好,显然很难训练,没有给他一个限定范围,完全让他俩任意生长,这样做显然是不好的。于是在YOLOv2里面就引入了anchor机制,我们不让这两个bounding box随机生长了,给他们一个限制,加个紧箍咒,给他们一个参考,这个参考就是anchor,又叫做先验框。如上图所示以两个anchor为例,一个瘦高,一个矮胖分别负责预测不同形状的物体。这样的话bounding box就不会随机生长了,就会有了自己的使命了,知道自己应该预测什么样的物体了。所以这个时候每个预测框只需要预测出它相较于这个anchor的偏移量就行了。
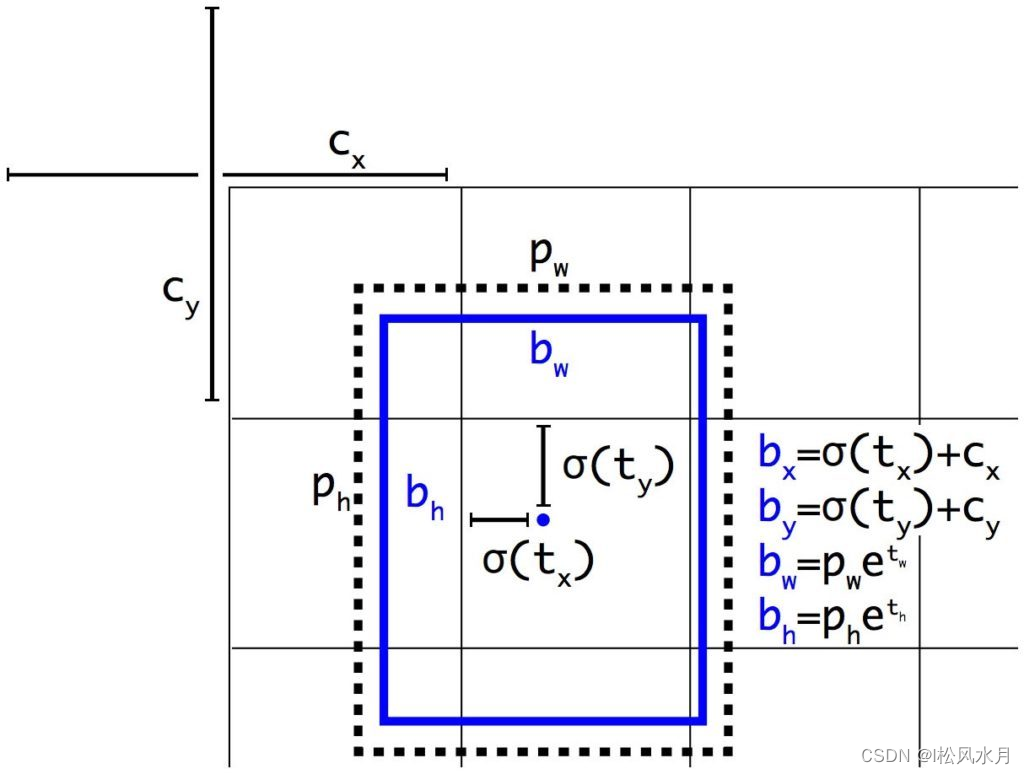
这个时候你又该问了,偏移量又是个什么鬼?不急,带我娓娓道来,上面我们知道了什么是anchor,所谓的anchor就是预先设置好的一个限制框,预测框只能根据这个限制框进行预测。下面我们讲下偏移量。上图就是YOLOv2给出的改进,通过预测偏移量代替直接预测bounding box,你看到这可能一脸懵逼,这么多符号都是啥意思?我来解释下其中的含义:
- b x , b y , b w , b h b_{x},b_{y},b_{w},b_{h} bx,by,bw,bh:模型最终得到的检测结果。
- t x , t y , t w , t h t_{x},t_{y},t_{w},t_{h} tx,ty,tw,th:模型要预测的结果。
- c x , c y c_{x},c_{y} cx,cy:
grid的左上角坐标。- p w , p h p_{w},p_{h} pw,ph:
anchor的宽和高,因为anchor是人为设定的,所以这两个值是固定的。
有没有发现上面少了一项,置信度。置信度的标签是
P
r
(
o
b
j
e
c
t
)
∗
I
o
U
(
b
,
o
b
j
e
c
t
)
=
σ
(
t
o
)
Pr(object)*IoU(b,object)=\sigma(t_{o})
Pr(object)∗IoU(b,object)=σ(to),这地方和YOLOv1是一样的,只不过这地方的置信度经过了一个归一化操作。
通过上面anchor机制,我们从直接预测bounding box改为预测一个偏移量,这个偏移量是什么呢,他是不是就是一个基于anchor框的宽和高和grid的先验位置的偏移量,得到最终目标的位置,这种方法也叫作location prediction。注意,因为物体的宽高可能很大,所以并没有对
t
w
,
t
h
t_{w},t_{h}
tw,th进行限制。只是把
t
x
,
t
y
t_{x},t_{y}
tx,ty中心坐标限制在了grid里面了(这里有个小小的bug,我们先不讲,可以自己先想一下,YOLOv4会改进)。刚才我们说了
t
x
,
t
y
,
t
w
,
t
h
t_{x},t_{y},t_{w},t_{h}
tx,ty,tw,th是模型要预测的值,那么这几个值应该怎么计算呢?

对grid cell进行归一化:

观察上面的图,我们可以计算出:
t
x
=
l
o
g
[
0.07
1
−
0.07
]
=
−
1.12
t
y
=
l
o
g
[
0.116
1
−
0.116
]
=
−
0.882
t
w
=
l
o
g
(
240
280
)
=
−
0.067
t
h
=
l
o
g
(
380
230
)
=
0.218
t_{x}=log[\frac{0.07}{1-0.07}]=-1.12\\ t_{y}=log[\frac{0.116}{1-0.116}]=-0.882\\ t_{w}=log(\frac{240}{280})=-0.067\\ t_{h}=log(\frac{380}{230})=0.218
tx=log[1−0.070.07]=−1.12ty=log[1−0.1160.116]=−0.882tw=log(280240)=−0.067th=log(230380)=0.218
关于上面的0.07,0.116这些值是怎么来的,我知道你肯定有疑问。下面我们来看下。
首先要明确一下,我们要对每个grid cell都进行归一化操作,也就是每个计算都是针对每个grid cell来的。我们知道
b
x
=
s
i
g
m
o
i
d
(
t
x
)
+
c
x
b_{x}=sigmoid(t_{x})+c_{x}
bx=sigmoid(tx)+cx,又因为
s
i
g
m
o
i
d
(
t
x
)
=
1
1
+
e
−
t
x
sigmoid(t_{x})=\frac{1}{1+e^{-t_{x}}}
sigmoid(tx)=1+e−tx1,从而可以推出
t
x
=
l
o
g
(
b
x
−
c
x
1
−
(
b
x
−
c
x
)
)
t_{x}=log(\frac{b_{x}-c_{x}}{1-(b_{x}-c_{x})})
tx=log(1−(bx−cx)bx−cx),其他坐标同理,代入anchor框的宽高、grid的坐标和预测框的宽高即可计算出
t
x
,
t
y
,
t
w
,
t
h
t_{x},t_{y},t_{w},t_{h}
tx,ty,tw,th四个值。
通过上面计算之后,要预测的值就变成了
t
x
,
t
y
,
t
w
,
t
h
=
−
1.12
,
−
0.882
,
−
0.063
,
0.132
t_{x},t_{y},t_{w},t_{h}=-1.12,-0.882,-0.063,0.132
tx,ty,tw,th=−1.12,−0.882,−0.063,0.132这是一个偏移量,这个时候再预测是不是比之前直接预测bounding box容易多了。
理解这个anchor的核心就是,先验框是事先设定好的,但是呢,我只需要设定的anchor的宽高信息,中心点坐标我自己来预测,因为这个中心点坐标已经被限制在了这个anchor所在的grid cell中了,再怎么预测都不会逃出这个anchor所在的grid cell。
通过上面的讲解,我相信你对anchor和偏移量已经有了了解了,下面我们回归正题,继续回到YOLOv2。在实际训练和预测的时候,YOLOv2是把整个图像给划分成
13
×
13
13\times13
13×13个grid,每个grid有5个anchor,就是事先指定了5种大小不同的先验框,每个anchor都对应一个预测框,而这个预测框只需要去负责预测输出他相对于他所在的anchor偏移量就行了。如下图所示,如果要预测小女孩,人工标注框的中心点落在哪个grid里面就应该由哪个grid产生的五个anchor中与ground truth的
I
o
U
IoU
IoU最大的那个anchor去负责拟合ground truth。而这个anchor对应的预测框只需要预测他相较于这个anchor的偏移量就行了,意思就是在这个anchor的基础上进行预测。


我们知道每个grid 都有5个anchor,ground truth落在哪个grid就由哪个grid产生的五个anchor中的一个来负责预测预测这个ground truth,总共5个anchor,那么由哪一个anchor去负责预测呢?由与anchor的
I
o
U
IoU
IoU最大的那个去负责预测。 这个anchor对应的预测框只需要输出它相比于它所在的anchor的偏移量就行了。
我们上面有讲到YOLOv2最后输出的网格大小是
13
×
13
13\times13
13×13,这个网格的长宽都是奇数,是为了便于预测物体的只有一个中心的grid,如果是偶数的话就会有好几个。
通过上面的介绍可以知道YOLOv2模型输出的结构也改了,如下图所示,在YOLOv1里面没有用anchor,而是直接划分成
7
×
7
7\times7
7×7个grid,每个grid输出两个bounding box,每个bounding box有两个未知参数和一个置信度,以及每个grid还预测出了20个类别的条件类别概率。在YOLOv2里面模型就变得稍微复杂一些,YOLOv1里面的类别是由grid负责,在YOLOv2里面类别变成由anchor负责了,每个grid产生5个anchor,每个anchor除了产生4个定位参数和一个置信度参数之外还有20个类别的条件类别概率,所以在YOLOv2里面每个anchor都会产生25个数,总共输出
5
×
25
=
125
5\times25=125
5×25=125个数。即YOLOv2总共输出
13
×
13
×
125
=
21125
13\times13\times125=21125
13×13×125=21125个数。最终的目标检测结果就是从这21125个数里面提取出来的。

下图可视化了YOLOv2的anchor的产生过程。

上面每个grid将产生5个anchor,你有没有疑问,为什么一定是5个,我产生10个不行吗?当然可以,只不过没必要,太浪费,导致网络参数太多。作者通过聚类的方法对PASCAL VOC和COCO数据集的长宽比进行了聚类操作,黑色框表示VOC数据集,紫色框表示COCO数据集。通过观察左图可以发现,聚类的长宽比种类越多,所覆盖的
I
o
U
IoU
IoU也越大,但是模型也会变的更复杂,作者在此取了个折中,直接取值为5,兼顾了准确度效率。长宽度如下图的有图所示。通过聚类的方法确定anchor数目。比双阶段的目标检测,如Faster RCNN手动去选择anchor要科学很多,聚类产生anchor一直到YOLOV5还在用,后面就开始使用anchor free了。

1.4.Fine-Grained Features(细粒度特征)
总结一句话就是长宽变为原来的一半,通道数变为原来的4倍。如下图的展示了一个可视化,就是网络中的Pass Throuth层。

1.5.Multi-Scale Training
在模型训练期把不同的图像大小输入到模型,这个地方你还不会有疑问,输入图像大小变了,我的网络模型不用调整吗?作者肯定考虑了这个问题,他用了一个全局平均池化层,对每个通道求平均来替换全连接层。如下图所示,速度跟图像尺寸成反比,精度跟输入图像尺寸成正比。

最后我们再来看张图,作者加了这些tricks到底有没有用。

上面我们讲的都是针对YOLOv2为什么会更好,下面我们再来介绍下YOLOv2为什么会更快。作者换了骨干网络,我们知道YOLOv1作者使用的是VGG骨干网络,很臃肿,在YOLOv2里面换成了作者自己设计Darknet19。

二.损失函数
下面我们讲一下YOLOv2的损失函数。

在YOLOv2论文里面并没有提到上面的损失函数,网上大神根据YOLOv2的代码整理出来的。
首先,我们看下损失函数的最外层,总共有三次求和,分别是遍历所有的宽,高和anchor的个数。然后是这个求和符号后面总共有三项,每项前面还有一个条件系数,这个系数非0即1。系数后面又有个
λ
\lambda
λ,表示权重:
- 第一项(第一行)是预测框或者说
anchor与ground truth的 I o U IoU IoU是否小于0.6,代码中给的阈值Thresh为0.6,他们是被抛弃的框,并不负责预测物体,他们的置信度越为0越好,括号里面为什么会有个负号?他表示是 ( 0 − b i j k o ) 2 (0-b_{ijk}^o)^2 (0−bijko)2,0就是那些被抛弃的框的标签, b i j k o b_{ijk}^o bijko表示预测框置信度。怎么计算 I o U IoU IoU? 可以参考我的另一篇博文, I o U IoU IoU的进化之路。IoU、GIoU、DIoU、CIoU四种损失函数总结。 - 第二项(第二行)是否是前12800次迭代,即是否是模型训练的早期。在模型训练的早期遍历四个定位参数,要让anchor的四个参数与预测框的四个参数尽可能的重合。就是让模型在训练的早期让五个
anchor能够各司其职,尽快找到自己负责的物体,让模型能够更加的稳定。 - 第三项(第三行及后面的)是这个
anchor负责检测物体,一个grid产生5个anchor,这个负责检测物体的anchor就是5个anchor里面与ground truth最大的那个anchor,也就是一个ground truth只分配给一个anchor。这个地方你会不会有疑问,负责预测物体的grid的里面的不是与 I o U IoU IoU最大但是又与ground truth的 I o U IoU IoU大于0.6的那些anchor怎么处理。或者你也可以这样理解,总共三类anchor,第一类是与gouund truth的 I o U IoU IoU最大的anchor,用来负责预测物体,第二类是与gouund truth的 I o U IoU IoU小于0.6的,也就是损失函数第一项,第三类是与gouund truth的 I o U IoU IoU大于0.6但又不是与ground truth的 I o U IoU IoU最大的那些anchor怎么处理?作者怎么处理的呢?他是直接把第三类的给抛弃了。对于负责预测物体的这个anchor总共要计算三项,分别是定位误差、置信度误差、分类误差。定位误差就是计算ground truth的位置和预测框的位置的误差。置信度误差就是计算anchor与标注框ground truth的 I o U IoU IoU与预测框置信度得误差,这里anchor与 I o U IoU IoU的标签是置信度标签,YOLOv1也是这样设计的。而分类误差就是计算标注框类别和预测框类别的误差,并且遍历所有类别。
也就是总共计算了两类损失+anchor位置调整损失:
- 最大的iou的anchor的位置损失,置信度损失,类别损失
- iou小于0.6的anchor的置信度损失,越小越好
- 前12800次让anchor接近目标尺寸
三.检测更多类别
损失函数我们讲过了,下面我们来继续接着讲作者是怎么加测更多类别的。
不是重点,简单了解即可,我们知道COCO也不过就80个类别,作者是怎么做到能够检测出9000各类别的,是在夸大其词还是真的能够做到检测9000个类别?
YOLOv2作者是这样做的,他把COCO数据集和ImageNet数据集进行联合训练,我们知道ImageNet数据集有两万多个类别,但是呢ImageNet又没有定位标签,只有分类标签,并且ImageNet的分类细粒度还很高,比如狗这个类别,他是什么狗,是阿拉斯加还是二哈,还是金毛,拉布拉多等。于是作者把他两个联合起来训练让模型能够学习到更多细粒度的特征。主要就是让目标检测数据集学定位,分类数据集学识别。这个地方简单了解即可,这里不做过多介绍。
至此,我们的YOLOv2模型理论部分也基本上介绍完了,YOLOv3的理论部分我们下篇文章再讲,在此,附一个YOLO系列的文章链接:
YOLOv1目标检测算法——通俗易懂的解析
YOLOv3目标检测算法——通俗易懂的解析
YOLOv4目标检测算法——通俗易懂的解析
YOLOv5目标检测算法——通俗易懂的解析
欢迎各位大佬批评指正。

