
热门标签
热门文章
- 1开源的分布式版本控制系统git的相关使用_开源 git 仓库系统
- 2PHP tp5微信扫码登陆_php对接微信公众号扫码登录开发
- 3【分享】我正在啃的一本书
- 4AI芯片技术架构有哪些?FPGA芯片定义及结构分析
- 5项目中,如何写 readme.md 文件 | 写项目总结
- 6【AI绘画+本地部署】基于krita的AI绘画(含windows一键整合包)_kritaai
- 7「时事点评」我有一个预感,保时捷女车主丈夫要残了!
- 8【git】LF will be replaced by CRLF the next time Git touches it 或 warning: LF will be replaced by CRLF
- 9mysql sql语句大全
- 10C++数据结构与算法:布隆过滤器(Bloom Filter)原理与实现_c++murmurhash
当前位置: article > 正文
Python学习从0到1 day23 第二阶段 面向对象 ⑥ 综合案例
作者:小蓝xlanll | 2024-04-11 15:29:45
赞
踩
Python学习从0到1 day23 第二阶段 面向对象 ⑥ 综合案例
先有自我,才无枷锁
—— 24.4.10
综合案例——数据分析
知识简介
1.使用面向对象思想完成数据读取和处理
2.基于面向对象思想重新认知第三方库的使用(PyEcharts)
数据分析案例
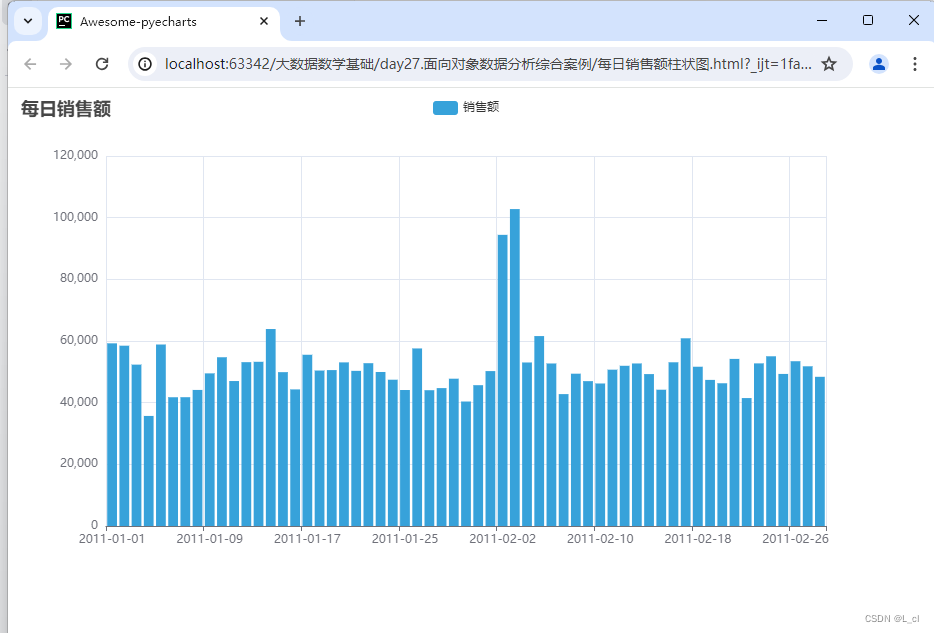
某公司,有2份数据文件,现需要对其进行分析处理,计算每日的销售额并以柱状图表的形式进行展示
1月份数据是普通文本,使用逗号分割数据记录,从前到后依次是(日期、订单ID、销售额、销售省份)
2月份数据是JSON数据,同样包含(日期,订单ID,销售额,销售省份)
需求分析
① 读取数据 设计FileReader类
② 封装数据对象 设计数据封装类
③ 计算数据对象 对对象进行逻辑计算
④ pyecharts绘图 以面向对象思想重新认知pyecharts
实现步骤: 1. 设计一个类,可以完成数据的封装 2. 设计一个抽象类,定义文件读取的相关功能,并使用子类实现具体功能 3. 读取文件,生成数据对象 4. 进行数据需求的逻辑运算(计算每一天的销售额) 5. 通过PyEcharts进行图形绘制1.data_define
设计一个类可以完成数据的封装
tips:
① 在设计类的时候使用构造方法定义成员变量,构造类对象的时候可以直接赋值
② 定义一个魔术方法,规定返回的数据类型
2.file_define
设计一个抽象类定义文件读取的相关功能,并使用子类实现具体功能
tips:
① 抽象类用来做顶层设计,确定类中有哪些功能需要实现
② 文本数据的文件读取器,继承抽象类
③ JSON文件读取器2,同样继承于FileReader
④ 魔术方法,在当前类中进行测试
⑤ 读取结果
3.数据分析及可视化
tips:
① 读取数据,将读取到的数据保存在变量中
② 数据计算
③ 可视化图表开发
可视化图表


声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/小蓝xlanll/article/detail/405805
推荐阅读
相关标签

