
- 1ESP32网络开发实例-Web服务器发送事件_利用esp32搭建web向客户端发送数据
- 22023 数字IC设计秋招复盘——数十家公司笔试题、面试实录_芯动科技 数字ic设计工程师 比试
- 3kafka 的零拷贝原理
- 4动态分析 Android 程序—动态分析框架/工具_adb forward tcp:8008 tcp:8008
- 5【STM32】使用CubeMX快速创建FreeRTOS的基础工程,基于正点原子_stm32cubemx freertos
- 6【网络安全技术】IPsec——AH和ESP
- 7SQL加减乘除_sql语句计算加减乘除
- 8Py之matplotlib.pyplot:matplotlib.pyplot的plt.legend函数的简介、使用方法之详细攻略_plt.legend()函数
- 9常见的Java报错和原因_java常见错误以及可能原因集锦
- 10计算机毕业设计springboot华南地区走失人员信息管理系统9k7b39【附源码+数据库+部署+LW】_预防老人走失系统设计数据库怎么做
NLP 快速上手_huggingface configure_http_backend
赞
踩
前言
学习NLP,解决两个问题:
- 如何使用别人训练好的模型?
- 如何基于别人的模型,加入自己的数据,训练得到自己的模型?
答案是使用预训练模型。预训练模型(pre-training model)是先通过一批语料进行训练模型,然后在这个初步训练好的模型基础上,再继续训练或者另作他用。这样的理解基本上是对的,预训练模型的训练和使用分别对应两个阶段:预训练阶段(pre-training)和 微调(fune-tuning)阶段。
NLP 历史回顾
文法规则->统计语言学->神经网络方法
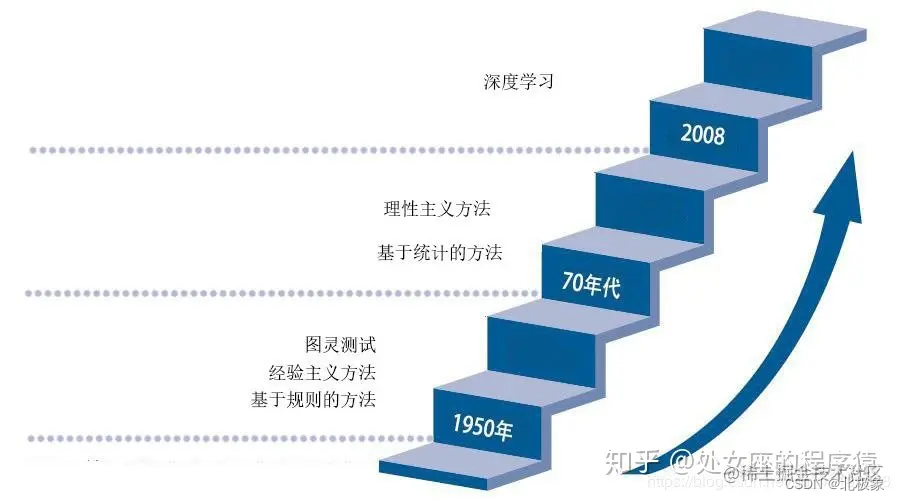
2017年谷歌提出了Transformer架构模型,2018年底,基于Transformer架构,谷歌推出了bert模型,bert模型一诞生,便在各大11项NLP基础任务中展现出了卓越的性能(一个排名榜单),现在很多模型都是基于或参考Bert模型进行改造。
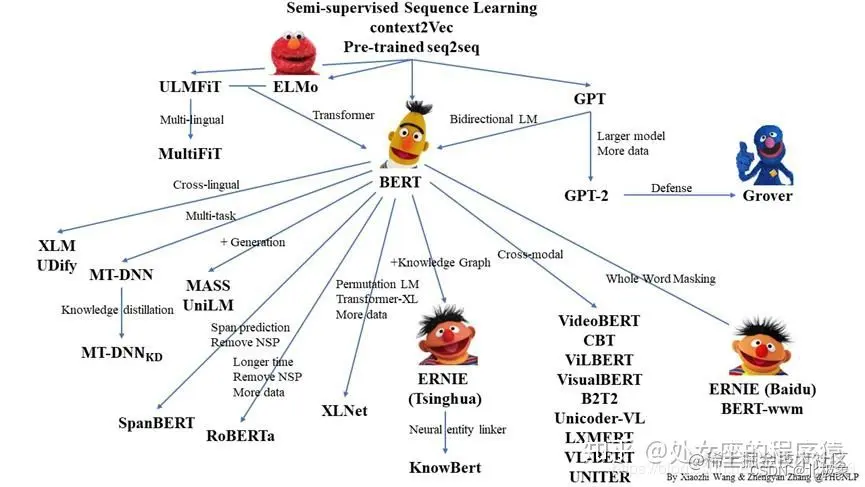
Transformer 架构是自然语言处理领域最近几乎所有主要发展的核心。这种 Transformer 架构的性能优于 RNN 和 CNN(卷积神经网络)。而且训练模型所需的计算资源也大为减少。
BERT (Bidirectional Encoder Representations)双向编码器表示是第一个无监督、深度双向的自然语言处理模型预训练系统。它只使用纯文本语料库进行训练。
NLP任务
目前NLP可以处理的任务主要包含以下几个大类:问答系统,文档摘要,机器翻译,语音识别,文档分类等。
基本概念
TF-IDF词袋模型
TF-IDF(Term Frequency-inverse Document Frequency)是一种针对关键词的统计分析方法,用于评估一个词对一个文件集或者一个语料库的重要程度。一个词的重要程度跟它在文章中出现的次数成正比,跟它在语料库出现的次数成反比。这种计算方式能有效避免常用词对关键词的影响,提高了关键词与文章之间的相关性。
其中TF指的是某词在文章中出现的总次数,该指标通常会被归一化定义为TF=(某词在文档中出现的次数/文档的总词量),这样可以防止结果偏向过长的文档(同一个词语在长文档里通常会具有比短文档更高的词频)。IDF逆向文档频率,包含某词语的文档越少,IDF值越大,说明该词语具有很强的区分能力,IDF=loge(语料库中文档总数/包含该词的文档数+1),+1的原因是避免分母为0。TFIDF=TFxIDF,TFIDF值越大表示该特征词对这个文本的重要性越大。
Word2Vec
Word2Vec是google在2013年推出的一个NLP工具,它的特点是能够将单词转化为向量来表示。基本出发点和Distributed representation类似:上下文相似的两个词,它们的词向量也应该相似。 word2vec在 2018 年之前非常流行,但是随着 BERT、GPT2.0 等方法的出现,这种方式已经不算效果最好的方法了。
word2vec主要包含两个模型:
- 连续词袋模型(CBOW,continuous bag of words):
通过上下文来预测当前值。相当于一句话中扣掉一个词,让你猜这个词是什么。在CBOW模型中包含三层,即输入层,映射层和输出层。输入层是当前词周围每个词对应的词向量,在映射层将这些词的词向量相加求平均,在输出层求出为当前词的概率。
如何根据一个词的one-hot编码,得到它对应的词向量,可以看下图所示:

word2vec训练的目的就是得到这个隐藏层参数矩阵。

- 跳字模型(skip-gram):
用当前词来预测上下文。相当于给你一个词,让你猜前面和后面可能出现什么词。输入层是当前词对应的词向量,映射层什么也不做,在输出层求出当前词上下文窗口中词的概率。

word2vec使用示例
from gensim.models import word2vec import jieba def train(): with open('/pub/NLP/天龙八部.txt', errors='ignore', encoding='utf-8') as fp: lines = fp.readlines() for line in lines: seg_list = jieba.cut(line) with open('/pub/NLP/分词后的天龙八部.txt', 'a', encoding='utf-8') as ff: ff.write(' '.join(seg_list)) # 词汇用空格分开 # 加载语料 sentences = word2vec.Text8Corpus('/pub/NLP/分词后的天龙八部.txt') # 训练模型 model = word2vec.Word2Vec(sentences) # 保存模型 model.save('/pub/NLP/天龙八部.model') def test_word2vec_model(): # 加载模型 model = word2vec.Word2Vec.load('/pub/NLP/天龙八部.model') # 选出最相似的10个词 for e in model.wv.most_similar(positive=['段誉'], topn=10): print(e[0], e[1])

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
输出结果:
乔峰 0.9072518348693848
游坦之 0.9017099738121033
木婉清 0.8961336016654968
虚竹 0.8942322731018066
阿紫 0.8807579874992371
王语嫣 0.8777897953987122
慕容复 0.87125563621521
萧峰 0.8666722178459167
乌老大 0.8532173037528992
段正淳 0.8409541249275208
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
BERT的语言模型
Bert最关键两点,一点是特征抽取器采用Transformer;第二点是预训练的时候采用双向语言模型。使用Bert得到的embedding可以为下游任务提供高质量的特征。即使没有关键字重叠,还是可以找出比较相似的句子。
BERT是 word2vec的高级进化版,进化的后果【用进废退】就是:BERT广泛成长,word2vec逐渐废弃。
Bert 与 word2vec 的区别是:word2vec中每个单词都有一个固定的表示,而与单词出现的上下文无关;bert生成的单词表示是由单词周围的单词动态形成的。
Bert 有自己的word to vector方法,可以将其看做是embedding生成机制中的一种,但Bert得到embedding是动态的,即使同一个单词得到的embedding可能都不是一样的(因为其上下文可能不同)。但有个问题是:BERT 是由12层 Transformer 构成,每个层得到的输出embedding各不相同,所以就需要我们自己考虑取哪些层的输出。通常情况下,取最后一层的embedding就OK了。
Bert 可以得到word的embedding,句子的embedding,句子的embedding是通过[CLS]获取的。
Attention 是一种算法,可以将其看成是平级于 RNN,LSTM 的一种方法。这种方法的特别之处在于它对一个句子不同的词赋以不同的优先级。transformer 是一种架构,它基于Attention 机制实现。所谓的transformer也就是数个ecoder layer叠加得到的块。【同时需要注意,我们平常也会使用一个包叫做Transformer,这个包实现了诸如BERT,GPT这种常用且著名的算法,这个包由著名的hugging face团队开发】。BERT是一种集合transfomer+双向检索思想得到的算法,它可以很好的提取出文本中的信息。
Bert做embedding的示例代码
""" 实现bert做embedding """ import torch from transformers import BertTokenizer, BertModel # 导入transformer 的包 #torch.set_printoptions(profile="full") # 输出tensor的整个部分 """ 1.from_pretrained()方法是类PreTrainedModel的一个方法 2.这里的如果加上 output_hidden_states=True,那么就会把所有的hidden_states 给输出 如果没有加,那么就只能得到最后一个隐层的输出。 """ model = BertModel.from_pretrained("bert-base-uncased", output_hidden_states = True) tokenizer = BertTokenizer.from_pretrained('bert-base-uncased') inputs = tokenizer("hello,my dog",return_tensors='pt') # 执行model[BertModel实例]的forward()方法,但是在执行之前,仍然做了很多其他的事情 with torch.no_grad(): outputs = model(**inputs) hiddden_states = outputs[2] # get the hidden states # The last hidden-state is the first element of the output tuple last_hidden_states = outputs[0] print(last_hidden_states) """ 1.如果我的句子是 "hello,my dog is cute",那么得到last_hidden_state 的size 就是torch.Size([1, 8, 768]);如果我的句子是"hello,my dog",那么得到的last_hidden_state 的 就是 torch.size([1,6,768])。也就是中间那个维度的大小是跟句子长度有关系 """ print(last_hidden_states.size()) # """ inputs 是个字典,的内容如下: {'input_ids': tensor([[ 101, 7592, 1010, 2026, 3899, 2003, 10140, 102]]), 'token_type_ids': tensor([[0, 0, 0, 0, 0, 0, 0, 0]]), 'attention_mask': tensor([[1, 1, 1, 1, 1, 1, 1, 1]]) } """
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
语料的标注
标注工具的选择,市面上有多种标注工具可供选择,例如MAE, Callisto,Brandeis Annotation Tool,Prodigy(收费)等。
AI语料标注师岗位职责
1.负责语料库的收集、整理和分类工作
2.根据需求完成数据预处理任务
3.使用自然语言处理技术对语料进行解析和分析,并产生文本数据
4.通过分析数据和算法实现自动化文本分类模型训练
5.持续优化模型性能和精度,提升效果
6.编写相关文档资料等,协助其他人员使用语料库
7.维护语料库并进行定期更新和维护
模型
Transformer
自从 BERT 和 GPT 模型取得重大成功之后, Transformer 结构已经替代了循环神经网络 (RNN) 和卷积神经网络 (CNN),成为了当前 NLP 模型的标配。两个著名 Transformer 模型: GPT和BERT。
Transformers 是由 Hugging Face 开发的一个 NLP 包,支持加载目前绝大部分的预训练模型。随着 BERT、GPT 等大规模语言模型的兴起,越来越多的公司和研究者采用 Transformers 库来构建 NLP 应用。

BERT
2018 年底随着 BERT 的提出,这一阶段神经语言模型的发展终于出现了一位集大成者,它在 11 个 NLP 任务上都达到了最好性能。
BERT 在模型大框架上采用和 GPT 完全相同的两阶段模型,首先是语言模型预训练,然后使用微调模式解决下游任务。BERT 不仅像 GPT 模型一样采用 Transformer 作为编码器,而且在预训练阶段采用了类似 ELMO 的双向语言模型。

因此 BERT 不仅编码能力强大,而且对各种下游任务,Bert 都可以简单地通过改造输入输出部分来完成。但是 BERT 的优点同样也是它的缺陷,由于 BERT 构建的是双向语言模型,因而无法直接用于文本生成任务。
Hugging Face
Hugging Face Transformers 是自然语言处理领域的重要开源项目,提供了基于通用架构(如 BERT,GPT-2,RoBERTa)的数千个预训练模型,并提供了 PyTorch 和 TensorFlow 的良好互操作性。
Hugging face 起初是一家总部位于纽约的聊天机器人初创服务商,他们本来打算创业做聊天机器人,然后在github上开源了一个Transformers库,虽然聊天机器人业务没搞起来,但是他们的这个库在机器学习社区迅速大火起来。目前已经共享了超100,000个预训练模型,10,000个数据集,变成了机器学习界的github。
Hugging Face Hub 平台为自然语言处理社区提供了一个中心化的地方,使人们可以共享和发现各种自然语言处理模型和数据集。该公司主要是提供nlp服务,同时它提供了一个很
Copyright © 2003-2013 www.wpsshop.cn 版权所有,并保留所有权利。

