
- 1windows下启动rabbitmq_windows启动rabbitmq
- 2使用GitHub制作一个高逼格的在线简历_在线简历word模板 github
- 3C++(运算符重载+赋值拷贝函数+日期类的书写)
- 4如何在Linux环境下安装Jenkins_linux安装jenkins
- 5mysql复制sql语句_MySQL复制表结构 表数据sql语句总结
- 6Milvus入门手册1.0_milvus中文文档
- 7Android11 open failed: EACCES (Permission denied)的解决方法_android open failed: eacces (permission denied)
- 8图论的基本知识
- 9数据结构之二叉搜索树底层实现洞若观火!
- 10GPT-4 API平替?性能媲美同时成本降低98%,斯坦福提出FrugalGPT,研究却惹争议
从规则到神经网络:机器翻译技术的演化之路
赞
踩
在本文中,我们深入探讨了机器翻译的历史、核心技术、特别是神经机器翻译(NMT)的发展,分析了模型的优化、挑战及其在不同领域的应用案例。同时,我们还提出了对未来机器翻译技术发展的展望和潜在的社会影响。

一、概述
机器翻译(Machine Translation, MT)是人工智能领域的一项关键技术,旨在实现不同语言之间的自动翻译。自从20世纪中叶首次提出以来,机器翻译已从简单的字面翻译演变为今天高度复杂和精准的语义翻译。这项技术的发展不仅彻底改变了全球信息交流的方式,而且对于经济、政治和文化交流产生了深远影响。
1. 机器翻译的历史与发展
机器翻译的概念最早出现在20世纪40年代,初期以规则为基础,依赖于详尽的词典和语法规则。然而,这种方法局限于规则的严格性和语言的复杂性。随着20世纪90年代统计机器翻译(Statistical Machine Translation, SMT)的兴起,机器翻译开始依赖大量双语语料库来“学习”翻译。比如,使用欧洲议会会议记录这种双语语料,机器学习不同语言间的转换规律。
2. 神经机器翻译的兴起
21世纪初,随着深度学习和神经网络的发展,机器翻译进入了一个新时代:神经机器翻译(Neural Machine Translation, NMT)。与基于规则或统计的方法不同,NMT使用深度神经网络,特别是RNN(循环神经网络)和后来的Transformer模型,以端到端的方式学习语言转换。例如,谷歌翻译在2016年引入了基于NMT的系统,显著提高了翻译质量。
3. 技术对现代社会的影响
机器翻译技术的进步对于打破语言障碍、促进全球化意义重大。它不仅为个人用户提供了方便,例如通过智能手机应用实时翻译外语,还对企业和政府进行跨国沟通提供了强大支持。机器翻译的发展还促进了其他技术的进步,如语音识别和自然语言处理,这些技术现在被广泛应用于各种智能助手和在线服务中。
总体而言,机器翻译不仅是技术上的一个重大突破,它还在文化、社会和经济等多个领域产生了深远的影响。通过不断的技术创新,机器翻译正在逐渐成为人类语言交流的一个不可或缺的部分。
二、机器翻译的核心技术

机器翻译的核心技术经历了几个重要的发展阶段,从最初的规则基础的方法到现代的基于深度学习的神经机器翻译。每种技术都有其特点和应用领域,对机器翻译的进步起到了关键作用。
1. 规则基础的机器翻译(Rule-Based Machine Translation, RBMT)
RBMT是最早的机器翻译方法,依赖于详细的语法规则和词汇数据库。它通过分析源语言的语法结构,然后根据预设规则转换为目标语言。例如,早期的机器翻译系统SYSTRAN就是基于这种技术。它在冷战时期被用于翻译俄语和英语之间的文件,虽然结果不够流畅,但在当时已经是一项重大突破。
2. 统计机器翻译(Statistical Machine Translation, SMT)
随着大数据时代的来临,统计机器翻译开始崭露头角。SMT不再依赖于硬编码的语言规则,而是通过分析大量双语文本数据,学习语言间的统计关系。例如,IBM的Candide系统是早期的SMT研究项目之一,它通过分析法语和英语的大量平行语料,开创了基于数据的机器翻译新时代。SMT的一个典型特点是“短语表”,它将文本分解为短语单位,并学习这些短语如何在不同语言间转换。
3. 神经机器翻译(Neural Machine Translation, NMT)
神经机器翻译代表了机器翻译技术的最新发展方向。NMT使用深度学习中的神经网络,特别是循环神经网络(RNN)和后来的Transformer模型,实现更加流畅和准确的翻译。以谷歌翻译为例,其采用的Transformer模型能够更好地处理长距离依赖和复杂的语言结构,显著提高了翻译的准确性和自然性。神经机器翻译在处理诸如词序、句法结构和语义理解方面展现出了显著的优势,成为当前机器翻译领域的主流技术。
4. 综合考量
每种机器翻译技术都有其优势和局限。规则基础的方法在处理特定、固定的语言结构时表现良好,但缺乏灵活性。统计机器翻译虽然能处理更多样化的文本,但在处理复杂句子和罕见词汇时存在挑战。神经机器翻译则在多方面展现了优越性,但它对训练数据的质量和量有较高要求。这些技术的发展不仅体现了人工智能领域的进步,也反映了计算能力和数据处理能力的增强。通过综合运用这些技术,机器翻译正在不断向更高的准确性和自然性迈进。
三、神经机器翻译的深入探讨
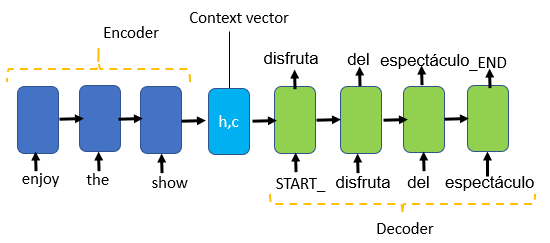
神经机器翻译(Neural Machine Translation, NMT)是利用深度学习技术进行语言翻译的前沿方法。NMT的核心在于使用神经网络,特别是循环神经网络(RNN)和Transformer模型,以端到端的方式学习和预测语言。
1. 神经网络架构
循环神经网络(RNN)
RNN是早期NMT系统的基石,特别擅长处理序列数据。例如,RNN在处理一个句子时,会逐个单词地读取并记忆上下文信息。RNN的问题在于难以处理长距离依赖,即在长句子中,前面的信息难以影响到句子后面的处理。
Transformer模型
为了克服RNN的限制,Transformer模型被引入。它通过自注意力机制(Self-Attention)来处理序列中的每个元素,从而有效地处理长距离依赖问题。Transformer模型的关键创新在于其能够同时关注输入序列中的所有部分,从而更好地理解上下文。
2. 训练数据与预处理
训练神经机器翻译模型需要大量的双语语料库。这些数据首先需要经过预处理,包括分词、归一化、去除噪声等步骤。预处理的目的是准备干净、一致的数据,以便于网络学习。
3. 训练过程详解
示例代码
以下是一个简化的NMT模型训练过程,使用PyTorch框架:
- import torch
- import torch.nn as nn
- import torch.optim as optim
-
- class NMTModel(nn.Module):
- def __init__(self, input_dim, output_dim, emb_dim, hid_dim, n_layers):
- super().__init__()
- self.embedding = nn.Embedding(input_dim, emb_dim)
- self.rnn = nn.LSTM(emb_dim, hid_dim, n_layers)
- self.fc_out = nn.Linear(hid_dim, output_dim)
-
- def forward(self, src):
- embedded = self.embedding(src)
- outputs, (hidden, cell) = self.rnn(embedded)
- predictions = self.fc_out(outputs)
- return predictions
-
- # 示例模型参数
- INPUT_DIM = 10000 # 输入语言的词汇量
- OUTPUT_DIM = 10000 # 输出语言的词汇量
- EMB_DIM = 256 # 嵌入层维度
- HID_DIM = 512 # 隐藏层维度
- N_LAYERS = 2 # RNN层数
-
- # 初始化模型
- model = NMTModel(INPUT_DIM, OUTPUT_DIM, EMB_DIM, HID_DIM, N_LAYERS)
-
- # 定义优化器和损失函数
- optimizer = optim.Adam(model.parameters())
- criterion = nn.CrossEntropyLoss()
-
- # 训练模型(示例,非完整代码)
- def train(model, iterator, optimizer, criterion):
- model.train()
- for i, batch in enumerate(iterator):
- src = batch.src
- trg = batch.trg
- optimizer.zero_grad()
- output = model(src)
- loss = criterion(output, trg)
- loss.backward()
- optimizer.step()

此代码展示了一个简化的NMT模型结构和训练循环。实际应用中,模型会更加复杂,且需要更多的调优和评估。
四、模型优化与挑战
神经机器翻译(NMT)模型虽然在多个方面取得了显著进展,但仍然面临着诸多挑战。优化这些模型并解决这些挑战是当前研究的重点。
1. 优化技术
正则化
为防止模型过拟合,正则化技术是关键。例如,使用Dropout可以在训练过程中随机“关闭”神经元,减少模型对特定训练样本的依赖。
注意力机制
注意力机制(Attention Mechanism)是提高NMT性能的关键。通过赋予模型在翻译时对源文本的不同部分进行“关注”的能力,可以显著提高翻译的准确性和自然性。例如,Transformer模型中的自注意力机制可以帮助模型更好地理解长句子中的语境。
示例代码:实现Dropout
以下是在PyTorch中实现Dropout的示例:
- import torch.nn as nn
-
- class NMTModelWithDropout(nn.Module):
- def __init__(self, input_dim, output_dim, emb_dim, hid_dim, n_layers, dropout_rate):
- super().__init__()
- self.embedding = nn.Embedding(input_dim, emb_dim)
- self.rnn = nn.LSTM(emb_dim, hid_dim, n_layers, dropout=dropout_rate)
- self.fc_out = nn.Linear(hid_dim, output_dim)
- self.dropout = nn.Dropout(dropout_rate)
-
- def forward(self, src):
- embedded = self.dropout(self.embedding(src))
- outputs, (hidden, cell) = self.rnn(embedded)
- predictions = self.fc_out(self.dropout(outputs))
- return predictions
在这个模型中,Dropout被应用于嵌入层和RNN层之间以及RNN层和全连接层之间,有助于减少过拟合。
2. 挑战
长句子翻译
长句子的翻译是NMT模型面临的一大挑战。随着句子长度的增加,模型保持语境和语义的能力下降。虽然Transformer模型在处理长距离依赖方面取得了进展,但对于非常长的句子,翻译质量仍然是一个问题。
低资源语言翻译
对于那些可用训练数据较少的语言,NMT模型的表现通常不佳。这是因为深度学习模型通常需要大量数据来学习有效的特征和模式。为了解决这个问题,研究人员正在探索诸如迁移学习和多语言训练等方法。
评价标准
评价机器翻译的质量是一个复杂的任务。常用的评价标准如BLEU分数,主要基于翻译结果和参考翻译之间的重叠程度,但这不一定能完全反映翻译的自然性和准确性。因此,开发更全面的评价标准是当前研究的重点之一。
五、应用与案例分析
神经机器翻译(NMT)技术的进步已经使其在多个领域得到广泛应用。从商业到学术,从日常生活到专业领域,NMT正在逐步改变我们理解和使用语言的方式。
1. 实际应用
商业领域
在商业领域,NMT技术的应用主要集中在跨语言通信和全球化内容管理。例如,多国公司使用NMT系统来翻译和本地化产品说明、市场营销材料和客户支持文档。这不仅加快了信息传递速度,还降低了语言服务的成本。
学术领域
在学术研究中,NMT使研究人员能够访问和理解其他语言的文献,促进了跨文化和跨学科的学术交流。此外,NMT还被用于语言学研究,帮助学者更好地理解不同语言间的相似性和差异性。
2. 成功案例
Google翻译
Google翻译是NMT应用的典型例子。2016年,谷歌引入了基于NMT的系统,显著提高了翻译的准确性和流畅性。例如,对于英语和法语之间的翻译,NMT系统相比于之前的统计机器翻译方法,在保持语义准确性的同时,大大增加了句子的自然流畅性。
DeepL
DeepL翻译器是另一个在NMT领域取得显著成就的例子。它以高准确性和流畅的翻译结果闻名,在某些情况下甚至超过了Google翻译。DeepL利用先进的NMT技术,特别是在处理复杂句子和特定行业术语方面展现出卓越的性能。
3. 对社会的影响
NMT的广泛应用极大地促进了全球化进程,帮助人们跨越语言障碍,更容易地获取信息和沟通。它不仅使个人用户的生活变得更加便捷,而且对于企业的国际化战略和学术研究的国际合作都起到了关键作用。
六、总结
在探讨了机器翻译的历史、核心技术、神经机器翻译的深入分析、模型优化与挑战,以及实际应用与案例后,我们可以总结出一些独特的洞见,这些洞见不仅彰显了机器翻译技术的成就和潜力,也指出了未来的发展方向。
技术发展的深远影响
神经机器翻译(NMT)的发展不仅是人工智能领域的一个重要成果,更是信息时代的一个里程碑。NMT的进步大幅提升了翻译的准确性和流畅性,这不仅改善了人与人之间的交流,也促进了跨文化理解和合作。机器翻译的发展有助于打破语言障碍,为全球化的进程提供了强大动力。
技术融合的前景
NMT的成功归功于多个技术领域的融合,包括深度学习、自然语言处理、大数据等。这种跨学科的融合不仅为机器翻译带来了突破,也为其他技术领域提供了灵感。例如,NMT中的自注意力机制已经被广泛应用于语音识别、图像处理等其他人工智能应用中。
持续的挑战和机遇
虽然NMT取得了显著成就,但仍面临诸如处理低资源语言、提高长句子翻译质量等挑战。这些挑战不仅推动了技术的不断进步,也为研究人员提供了新的研究方向。同时,随着计算能力的提升和数据量的增加,我们可以预期机器翻译将实现更大的飞跃。
技术伦理与社会责任
随着机器翻译技术的深入应用,技术伦理和社会责任问题也日益凸显。例如,如何确保翻译结果的公正性和无偏见,以及如何处理隐私和版权等问题,都是必须认真考虑的问题。这不仅是技术挑战,也是社会和法律挑战。
文章转载自:techlead_krischang

