
- 1【DataHub】 现代数据栈的元数据平台--如何与spark集成,自动产生spark作业的数据血缘关系?
- 2【代码复现】SCI论文特征重要性条形图代码复现_随机森林重要性排名的误差棒
- 32022最新软件测试八股文,已经帮助3000+测试员入职大厂....
- 4STM32+ENC28J60+UIP协议栈实现WEB服务器示例_enc28j60 stm32
- 5【梦马】程序员必备的九种算法(C语言实现)_c语言实现工程算法
- 6TLS1.3中文版上(RFC8446)(注:本文有错误但无法修改,正确的见后来文章)_tls协议 文档
- 7Flutter应用中显示iOS/Android原生视图_flutter中展示原生页面
- 8HCIP H12-223 题库_在排除 vrrp 备份组双故障时。在配置 vrrp 备份组两端的 vlanif 接口上执行 disp
- 9写给我自己的2022_我的2022自设
- 10常用9款在线作图工具,总有一款适合你!_画图软件在线使用
StarRocks实战——表设计规范与监控体系_starrocks主键表
赞
踩
目录
1.4.2 案例一:Update内存超了,导致主键表导入失败
前言
StarRocks 是一款高性能分析型数据仓库,使用向量化、MPP 架构、CBO、智能物化视图、可实时更新的列式存储引擎等技术实现多维,实时,高并发的数据分析。StarRocks 既支持从各类实时和离线的数据源高效导入数据,也支持直接分析数据湖上各种格式的数据。StarRocks兼容 MySQL 协议,可使用 MySQL 客户端和常用 BI 工具对接。同时StarRocks具备水平扩展,高可用、高可靠、易运维等特性,StarRocks 广泛应用于实时数仓、OLAP 报表、数据湖分析等场景。
一、StarRocks表设计
现有的场景中,主要使用比较多的两种表模型是更新模型和主键模型。二者在同维度列相同的 数据处理上是一致的,不同的是相对于更新模型,主键模型在查询时不需要执行聚合操作,并且支持谓词下推和索引使用,能够在支持实时和频繁更新等场景的同时,提供高效查询。
下面内容主要是对更新模型与主键模型都适用的分区分桶规范,以及主键模型需要而外注意一些场景。
1.1 字段类型
定义恰当数据字段类型对StarRocks查询的优化是非常重要的,从查询效率的角度考虑,我们可以遵循两条原则:
- 如果数据没有Null,可以指定Not Null属性;
- 尽量使用数字列代替字符串列。
1.2 分区分桶
StarRocks采用Range分区,Hash分桶的组合数据分布方式。
Table (逻辑描述) -- > Partition(分区:管理单元) --> Bucket(分桶:每个分桶就是一个数据分片:Tablet,数据划分的最小逻辑单元)
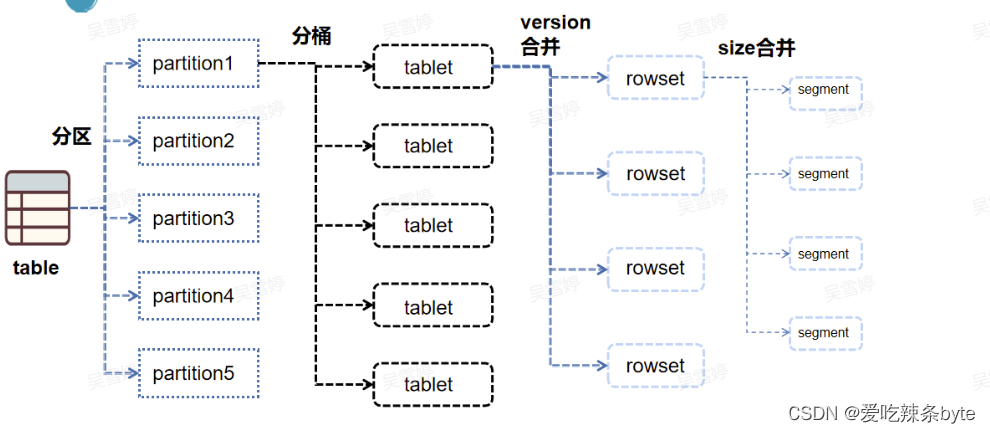
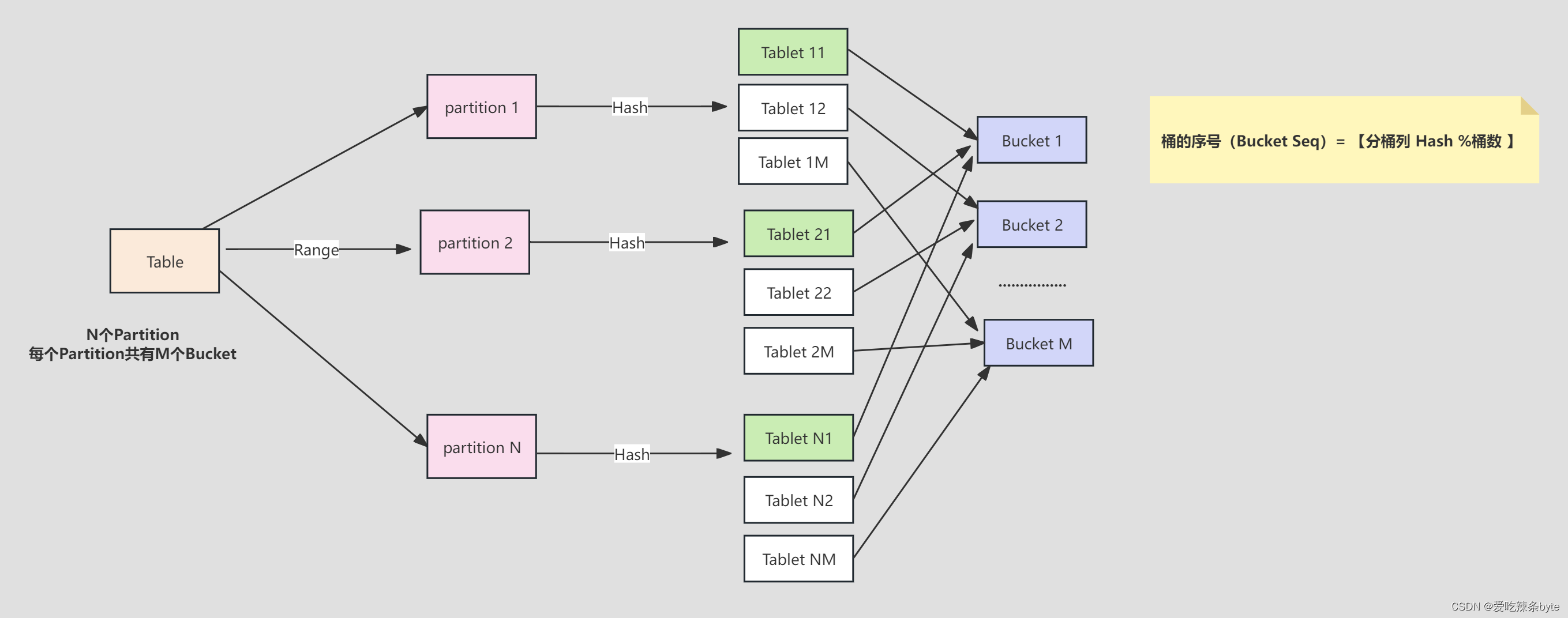
1.2.1 分区规范
- 分区键选择:当前分区键仅支持日期类型和整数类型,表中数据可以根据分区列(通常是时间和日期)分成一个个更小的数据管理单元。查询时,通过分区裁剪,可以减少扫描的数据量,显著优化查询性能。
- 分区粒度选择:StarRocks 的分区粒度需要综合考虑数据量、查询特点、数据粒度等因素。单个分区原始数据量建议维持在100G以内。
1.2.2 分桶规范
- 分桶键选择:
- 如果查询比较复杂,则建议选择高基数的列为分桶键,保证数据在各个分桶中尽量均衡,提高集群资源利用率。
- 如果查询比较简单,则建议选择经常作为查询条件的列为分桶键,提高查询效率。
- 如果数据倾斜情况严重,可以使用多个列作为数据的分桶键,但是建议不超过 3 个列
- 分桶数:分桶数的设置需要适中,如果分桶过少,查询时查询并行度上不来(CPU多核优势体现不出来)。而如果分桶过多,会导致元数据压力比较大,数据导入导出时也会受到一些影响。
ps: 从经验来看,每个分桶的原始数据建议不要超过5个G,考虑到压缩比,即每个分桶的大小建议在100M-1G之间。
1.3 主键表
该模型适合需要对数据进行实时更新的场景,特别适合 MySQL 或其他数据库同步到StarRocks 的场景。虽然原有的Unique更新模型也可以实现对数据的更新,但Merge-on-Read 的策略大大限制了查询性能。Primary主键模型更好地解决了行级别的更新操作,配合 Flink-connector-StarRocks 可以完成 MySQL 数据库的同步。
由于StarRocks存储引擎会为主键建立索引,而在导入数据时会把主键索引加载在内存中,所以主键模型对内存的要求比较高,还不适合主键特别多的场景。目前比较适合的两个场景是:
1.3.1 数据有冷热特征
数据有冷热特征,即最近几天的热数据才经常被修改,老的冷数据很少被修改。典型的例子如 MySQL 订单表实时同步到 StarRocks 中提供分析查询。其中,数据按天分区,对订单的修改集中在最近几天新创建的订单,老的订单完成后就不再更新,因此导入时其主键索引就不会加载,也就不会占用内存,内存中仅会加载最近几天的索引。

1.3.2 大宽表
大宽表(数百到数千列),主键只占整个数据的很小一部分,其内存开销比较低。比如用户状态和画像表,虽然列非常多,但总的用户数不大(千万至亿级别),主键索引内存占用相对可控。如下图所示,大宽表中排序键只占一小部分,且数据行数不多。

1.4 实际案例
1.4.1 案例一:主键表内存优化
- 治理前现状
数据团队集群总共有主键表50张左右,集群8台BE节点,平均每台BE大概有7.5G内存被主键长期消耗(常驻),当前集群机器分配给 BE 服务也就只有50G,严重影响了离线写入与查询的性能。
- 治理方式
不需要实时更新的主键模型都改用更新模型。
检查所有主键表的数据生命周期,删除多余数据。
写入有冷热概念的表,全部增加分区键。
- 治理结果
主键表优化,BE 内存释放大概48G(常驻),优化后BE有更多内存用于写入和查询。
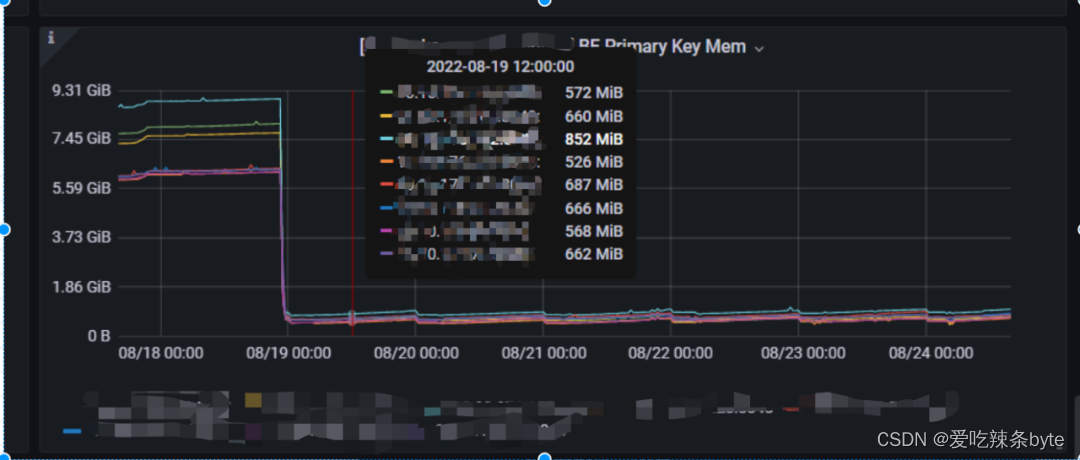
ps:相较于更新模型,主键模型(Primary Key)可以更好的支持实时/频繁更新的场景。如果表写入是离线任务,或者更新频率很低则不需要使用主键模型,因为主键模型相对于更新模型有更大的内存消耗。
1.4.2 案例一:Update内存超了,导致主键表导入失败
- 1.背景
收到研发反馈,说有多个主键表导入报错,任务返回如下:
- Caused by: java.io.IOException: com.starrocks.connector.flink.manager.StarRocksStreamLoadFailedException: Failed to flush data to StarRocks, Error response:
-
- {"Status":"Fail","BeginTxnTimeMs":0,"Message":"close index channel failed, load_id=bc4eb485-f99b-1f20-ffd9-e7e7e22925ab","NumberUnselectedRows":0,"CommitAndPublishTimeMs":0,"Label":"2434c3d7-9cef-45b0-b057-482b9a0032cd","LoadBytes":1056,"StreamLoadPutTimeMs":1,"NumberTotalRows":0,"WriteDataTimeMs":14,"TxnId":1355616,"LoadTimeMs":15,"ReadDataTimeMs":0,"NumberLoadedRows":0,"NumberFilteredRows":0}
- 2.报错
通过 Label ID去BE日志里面过滤,找到相关的报错:
ps:每一个事务可以设置一个label,StarRocks FE会检查本次begin transaction 请求的label是否已经存在,如果label在系统中不存在,则会为当前label开启一个新的事务。

- 3.相关监控

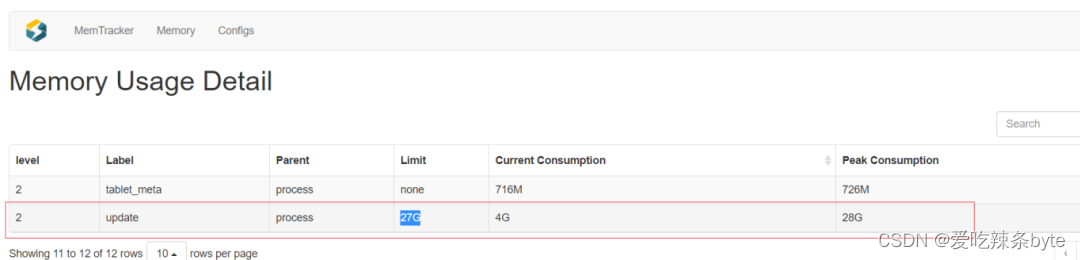
- 4.原因
默认BE的Update内存设置是27G,实际使用中发现这部分内存使用超了,导致任务报错。该值已经很大了,排查后发现有几张表设计的不合理。
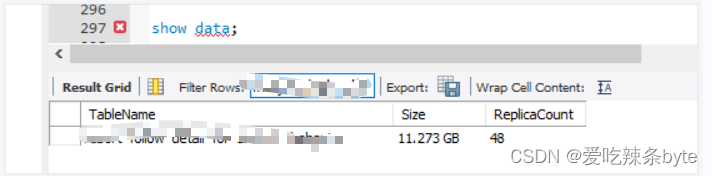
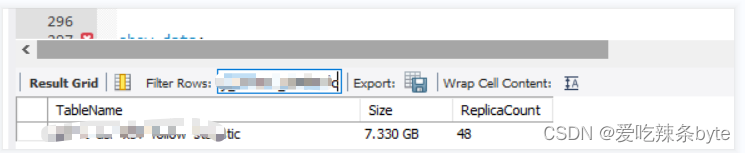
该主键表没有分区,在写入的时候会把整张表都加载到内存中,导致BE内存暴涨,超出Update 限制。
- 5.处理
表优化:发现该业务其实并不需要用主键模型只需要更新模型就能满足需求。于是把主键模型改为了更新模型。
- 6.补充与总结
- 1.相较更新模型,主键模型(Primary Key)可以更好地支持实时/频繁更新的功能。如果表写入的是离线任务,或者更新频率很低则不需要使用主键模型,因为主键模型相对于更新模型有更大的内存消耗。
- 2.主键表把主键加载到内存中的最小维度是分区,所以主键表如果有冷热数据的概念,可以根据时间增加分区键,减小写入时主键部分消耗的内存。(默认主键表在写入的时候,会将主键加载到内存中,如10分钟没有写入需求才会把这部分内存释放)
1.4.3 案例三:tablet 数量治理
- 治理前现状
数据团队集群的数据分片Tablet数120w,整个集群的数据量才3T,平均每个Tablet大小才2.6M,远低于官方推荐的100M-1G,有大量的tablet大小只有几KB,而Tablet 过多导致元数据过大,FE内存紧张。(show data)
- 治理方式
以单个分区Partition大小在100G以内,单个Tablet 数据分配在100M-1G为标准,对表的分区分桶做重新设计,具体方式是:
a. 把天级别分区改为月级别分区
b. 对于分桶过多,数据量不大的表,减少分桶数量
- 治理结果
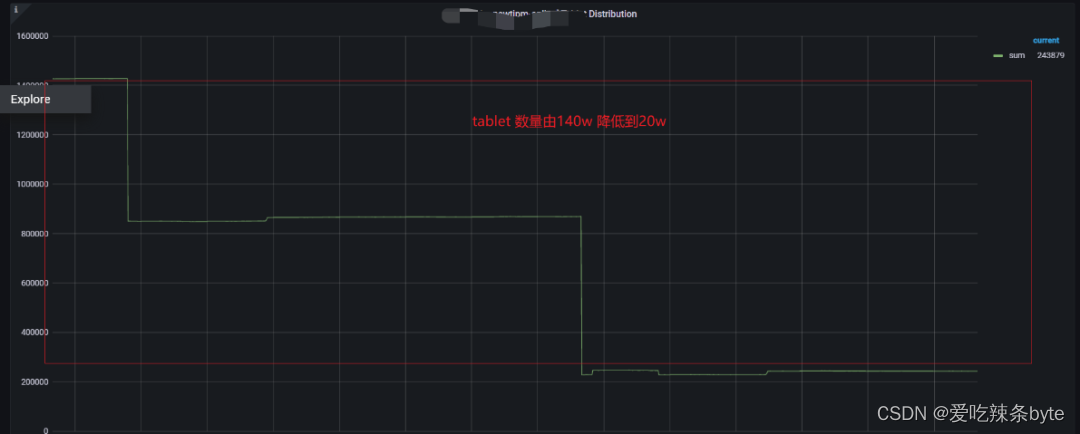
治理后,Tablet 数量由140W 降低到13W,FE 内存峰值由 18.6G 下降为 4.5G,减少了FE内存的浪费。
1.5 建表案例
(1)业务背景:需要新建一张订单表,表信息如下:
- #=====1.字段
- bos_id bigint(20) NOT NULL COMMENT "组织架构树id",
- vid bigint(20) NOT NULL COMMENT "节点id",
- path varchar(65533) NULL COMMENT "父节点路径",
- prod_id bigint(20) NOT NULL COMMENT "产品id",
- prod_inst_id bigint(20) NOT NULL COMMENT "产品实例id",
- st tinyint(4) NOT NULL COMMENT "数据统计类型0:全部, 1:自身, 2:全部子节点",
- consign_type tinyint(4) NOT NULL COMMENT "交付单状态0:待发单;1:发单;2确认收货",
- order_no bigint(20) NOT NULL COMMENT "订单号",
- dd date NOT NULL COMMENT "日期",
- merchant_id bigint(20) NOT NULL COMMENT "商户id",
- vid_type bigint(20) NOT NULL COMMENT "节点类型",
- consign_vid bigint(20) NULL COMMENT "处理vid",
- create_time datetime NOT NULL COMMENT "创建时间"
-
- #=====2.数据量:年数据量预估在20亿左右。
- #=====3.SIZE:年数据量是10G左右,23年之前有存量数据1G。
- #=====4.常用过滤条件:dd,bos_id,path,prod_id。
- #=====5.QPS:10

(2)建表分析
- 1、 2023年之前存量数据较少,使用频率低,可以建为一个分区。
- 2、 增量数据稳定10G每年,并有时间维度做分区,采用月分区,平均分区大小在0.83G。(每分区=10G/12)
- 3、 在保证每个Tablet数据量在100M-1G之间的同时,增加读写的并发,将分桶设置为6,平均Tablet大小是138M(每桶=0.83G / 6)。
- #======建表,更新模型
- CREATE TABLE table1 (
- dd date NOT NULL COMMENT "日期",
- bos_id bigint(20) NOT NULL COMMENT "组织架构树id",
- vid bigint(20) NOT NULL COMMENT "节点id",
- path varchar(65533) NULL COMMENT "父节点路径",
- prod_id bigint(20) NOT NULL COMMENT "产品id",
- prod_inst_id bigint(20) NOT NULL COMMENT "产品实例id",
- st tinyint(4) NOT NULL COMMENT "数据统计类型0:全部, 1:自身, 2:全部子节点",
- consign_type tinyint(4) NOT NULL COMMENT "交付单状态0:待发单;1:发单;2确认收货",
- order_no bigint(20) NOT NULL COMMENT "订单号",
- merchant_id bigint(20) NOT NULL COMMENT "商户id",
- vid_type bigint(20) NOT NULL COMMENT "节点类型",
- consign_vid bigint(20) NULL COMMENT "处理vid",
- create_time datetime NOT NULL COMMENT "创建时间"
- ) ENGINE=OLAP
- UNIQUE KEY(dd, bos_id, vid, path, prod_id, prod_inst_id, st, consign_type, order_no)
- COMMENT "履约分析_待发货待发单待备货"
- PARTITION BY RANGE(dd)
- (PARTITION p2022 VALUES [('1970-01-01'), ('2023-01-01')),
- PARTITION p2023 VALUES [('2023-01-01'), ('2024-02-01')),
- PARTITION p202401 VALUES [('2023-02-01'), ('2024-03-01')))
- DISTRIBUTED BY HASH(bos_id, order_no) BUCKETS 6
- PROPERTIES (
- "replication_num" = "3",
- "dynamic_partition.enable" = "true",
- "dynamic_partition.time_unit" = "MONTH",
- "dynamic_partition.time_zone" = "Asia/Shanghai",
- "dynamic_partition.start" = "-2147483648",
- "dynamic_partition.end" = "1",
- "dynamic_partition.prefix" = "p",
- "dynamic_partition.buckets" = "6",
- "dynamic_partition.start_day_of_month" = "1",
- "in_memory" = "false",
- "storage_format" = "DEFAULT"
- );
二、StarRocks监控
本模块包含监控架构、监控页面使用、监控项的解释以及对应值的合理范围(其中部分性能指标有原理及排查思路的扩展)。
2.1 监控架构
StarRocks 支持基于Prometheus 和 Grafana实现可视化监控,便于监控和故障排除。StarRocks 提供了兼容Prometheus的信息采集接口,Prometheus通过 Pull 方式访问 FE 或 BE 的 Metric 接口,然后将监控数据存入时序数据库。Grafana 则可以将 Prometheus 作为数据源将指标信息可视化。搭配 StarRocks 提供的Dashboard模板,可以便捷的实现StarRocks集群监控指标的统计展示和阈值报警。
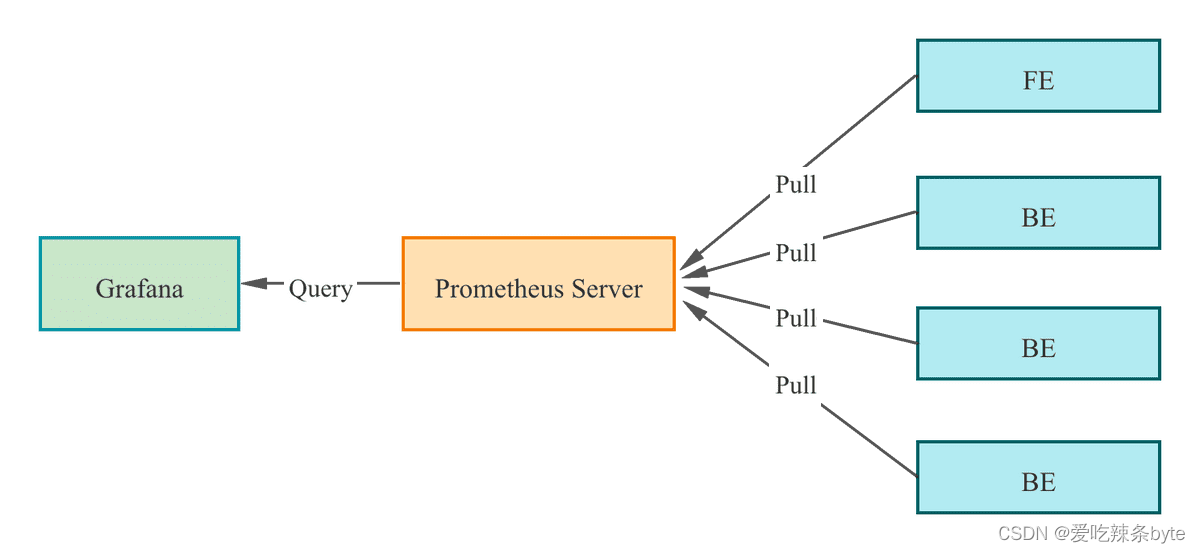
监控告警选择上,基于官方推荐的 Prometheus+Grafana 的方案, 公司内部接入 AlertManager+ 自定义的 API 做告警。
Prometheus 通过Pull 方式访问 FE 或 BE 的 Metric 接口,然后将监控数据存入时序数据库。监控展示选取的是通过 Grafana 配置 Prometheus 为数据源。

针对集群的审计SQL进行采集分析,通过ELK将各个FE节点的审计日志采集后写入到ES中,通过配置规则,筛选出其中的慢sql,推送到告警系统中,以提醒相应的同事关注及优化。
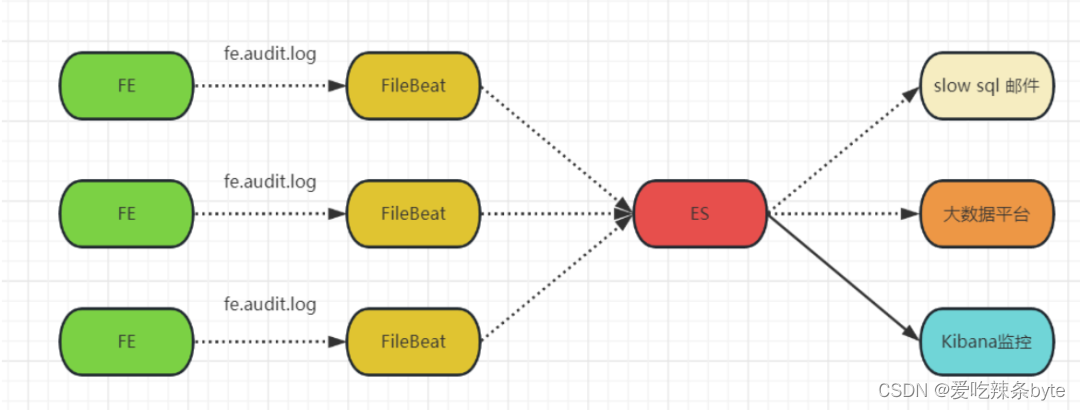
2.2 监控页面使用
根据需求,选择需要查看的集群,FE,BE节点。

2.2 监控分类
对于关键指标会标记。
2.2.1 Overview
主要是用来同时展示所有StarRocks 集群的运行状态,一般作为StarRocks日常巡检的一部分。
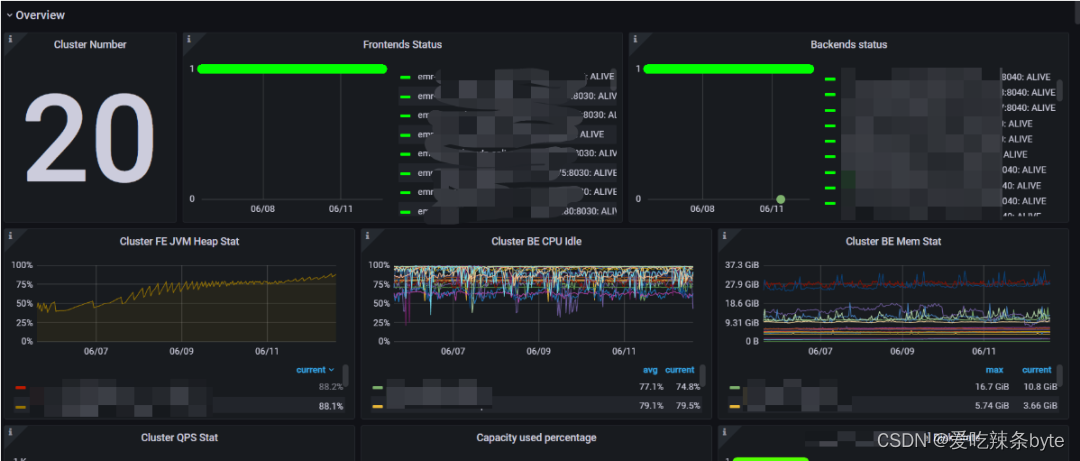
监控项解释:
1、Cluster Number:starrocks 集群总数
2、Frontends Status:fe节点状态(1为alive,0为dead)
3、Backends status:be节点状态(1为alive,0为dead)
4、Cluster FE JVM Heap Stat:fe内存使用情况(所有fe节点的平均值)
5、Cluster BE CPU Idle:be节点cpu使用情况(所有be节点的平均值)
6、Cluster BE Mem Stat:be节点内存使用情况(所有be节点的平均值)
7、Cluster QPS Stat:集群qps
8、Capacity used percentage:集群存储使用百分百
9、Disk State:be节点磁盘的状态(1为正常,0为异常)
2.2.2 Cluster Overview
主要是所选择集群的基础指标,观察所选集群的基础状态。

1、FE Node:FE节点的总数
2、FE Alive:alive状态 FE节点数
3、BE Node:BE节点的总数
4、BE Alive:alive状态 BE节点数
5、Total Capacity:集群整体的存储
6、Used Capacity:已使用的存储
7、Max Replayed journal id:当前最新的journal id
8、Scheduling Tablets:集群中正在调度(被复制)的tablet数量(tablet缺失,不一致,unhealthy,balance 都会触发tablet 的复制),一般情况下,该值超过50需要检查一下集群的负载。
2.2.3 Query Statistic
集群查询相关的指标:
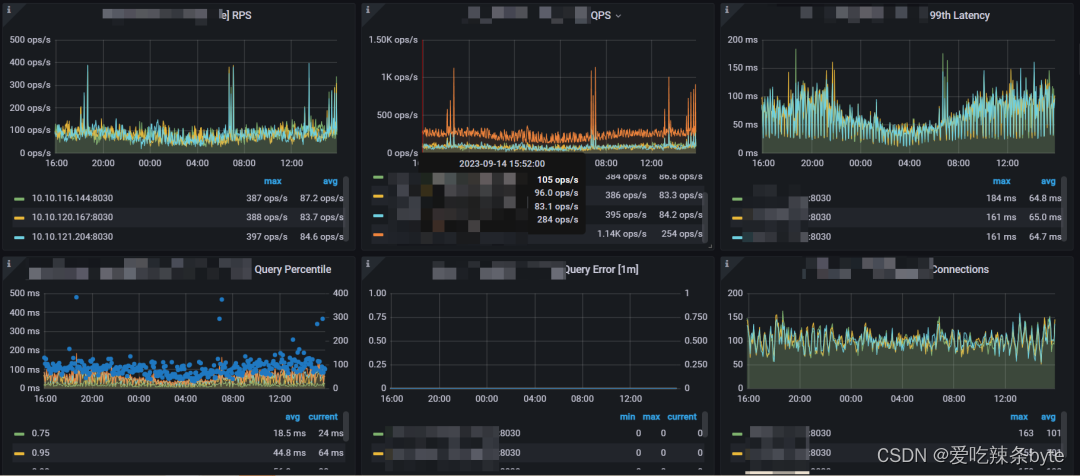
1、 RPS:每个FE的每秒请求数。请求包括发送到FE的所有请求。
2、 QPS:每个FE的每秒查询数。查询仅包括 Select 请求。
3、 99th Latency:每个FE 的 99th个查询延迟情况。
4、 Query Percentile:左 Y 轴表示每个FE的 95th 到 99th 查询延迟的情况。右侧 Y 轴表示每 1 分钟的查询率。
5、 Query Error:左 Y 轴表示累计错误查询次数。右侧 Y 轴表示每 1 分钟的错误查询率。通常,错误查询率应为 0。
6、 Connections:每个FE的连接数量
7、Slow Query:慢查询的数量(累计值)
2.2.4 Jobs
写入任务的相关指标:
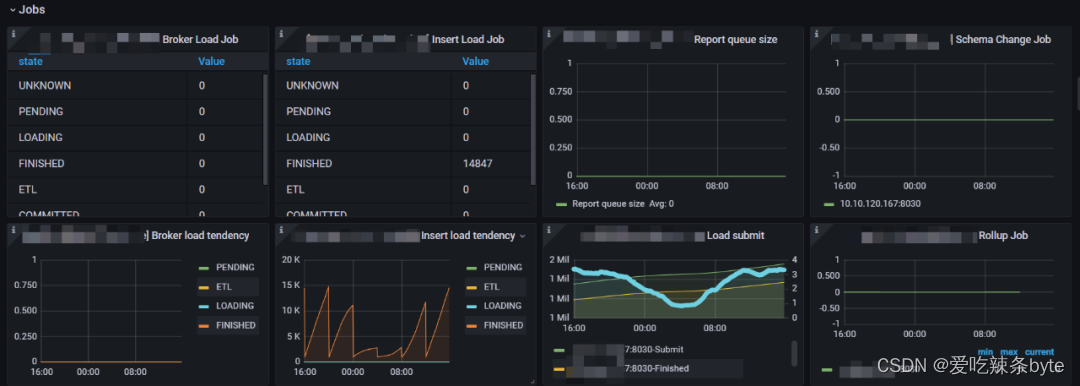
1、Broker Load Job:每个负载状态下的Broker Load 作业数量的统计。
2、Insert Load Job:由 Insert Stmt 生成的每个 Load State 中的负载作业数量的统计。
3、Report queue size:Master FE 中报告的队列大小
4、Schema Change Job:正在运行的Schema 更改作业的数量。
5、Broker load tendency:Broker Load 作业趋势报告
6、Insert Load tendency:Insert Stmt 生成的 Load 作业趋势报告
7、Load submit:显示已提交的 Load 作业和 Load 作业完成的计数器。
8、Rollup Job:正在运行Rollup 构建作业数量
2.2.5 Transaction
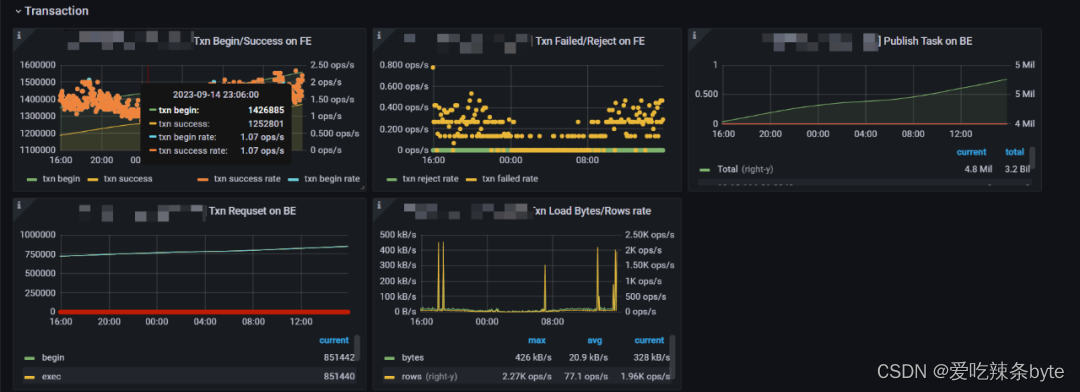
1、Txn Begin/Success on FE:事务开始/完成的数量,及速率,可以侧面衡量集群的写入频率
2、Txn Failed/Reject on FE:事务失败/拒绝的速率,可以侧面衡量集群写入失败的情况
3、Publish Task on BE:发布任务请求总数和错误率。(注意每个节点取得是错误的概率,集群正常情况下这个应该为0)
4、Txn Requset on BE:在 BE 上显示 txn 请求这里包括:begin,exec,commit,rollback四种请求的统计信息
5、Txn Load Bytes/Rows rate:事务写入速度,左 Y 轴表示 txn 的总接收字节数。右侧 Y 轴表示 txn 的Row 加载率。
2.2.6 FE JVM
FE服务的内存,线程相关指标:
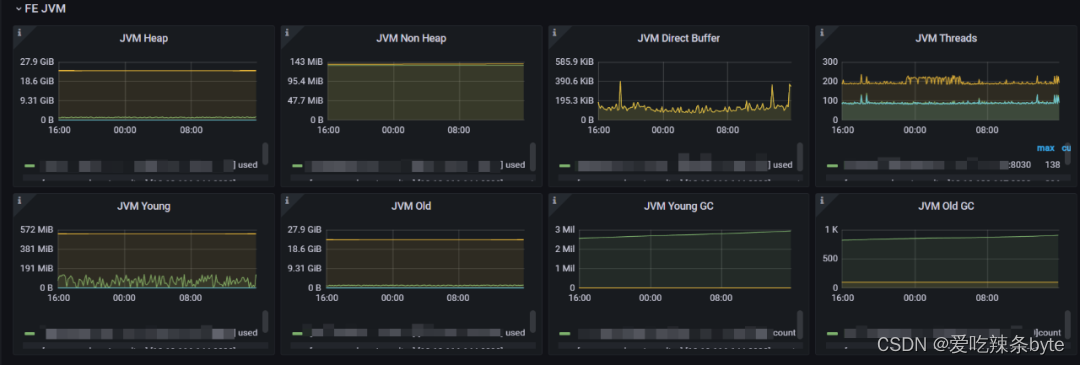
1、JVM Heap:FE 服务堆内存使用(2.0.2 版本 FE 内部有内存架构有问题,有统计不全的情况,该值不是极为准确,可以作为 FE 负载变化的参考)
2、JVM Non Heap:非堆内存的使用
3、JVM Direct Buffer:指定 FE 的 JVM 直接缓冲区使用情况。左 Y 轴显示已用/容量直接缓冲区大小。
4、JVM Threads:集群FE JVM线程数。用来参考FE的负载情况
5、JVM Young:指定 FE 的 JVM 年轻代使用情况。
6、JVM Old:指定 FE 的 JVM 老年代使用情况。
7、JVM Young GC:指定 FE 的 JVM 年轻 GC 统计信息(总数和平均时间)。
8、JVM Old GC:指定 FE 的 JVM 完整 GC 统计信息(总数和平均时间)。
2.2.7 BE
BE服务的基础,集群层面的指标:
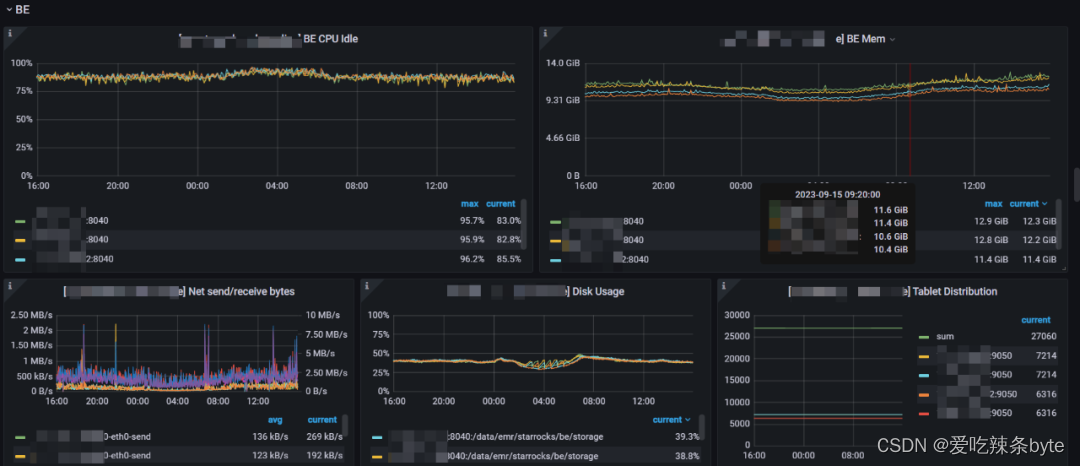
1、BE CPU Idle:BE 的 CPU 空闲状态。低表示 CPU 忙。说明CPU的利用率越高
2、BE Mem:这里是监控集群中每个BE的内存使用情况
3、Net send/receive bytes:每个BE节点的网络发送(左 Y)/接收(右 Y)字节速率,除了“IO”
4、Disk Usage:BE节点的storage的大小(注意这个只是/data/starrocks/storage目录的大小,实际机器上面可能会比这个大,有log或者系统使用的磁盘)
5、Tablet Distribution:每个 BE 节点上的 Tablet 分布情况,原则上分布式均衡的,如果差别特别大,就需要去分析原因。(该值不宜过大,太大会消耗FE,以及BE的内存,我们做过相关压测一个 Tablet 大概消耗FE 5KB的内存,并且改值随着整体 Tablet 总量增加而增加。默认一张表的全部Tablet 数= 分区数*分桶数 * 3副本)
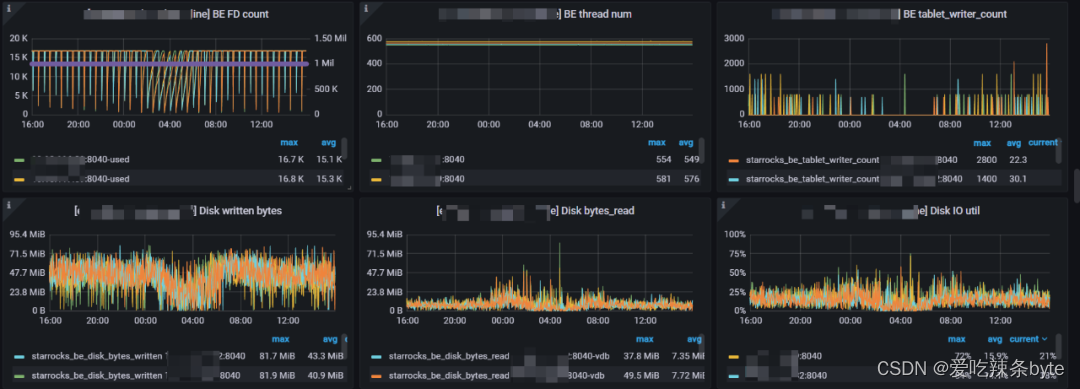
1、BE FD count:BE的文件描述符( File Descriptor)使用情况。左 Y 轴显示使用的 FD 数量。右侧 Y 轴显示软限制打开文件数。(可以理解为文件句柄)
2、BE thread num:BE的线程数(用来衡量be的并发情况,当前16core机器在400左右为正常值)
3、BE tablet_writer_count:be节点上面正在做写入的tablet 数量(用来衡量be写入负载)
4、Disk written bytes:be节点上磁盘的写速度。
5、Disk bytes_read:be节点上磁盘的读速度。
6、Disk IO util:每个 BE 节点上磁盘的 IO util 指标,数值越高表示IO越繁忙。

1、BE Compaction Base:BE的Base Compaction(基线合并)压缩速率。左Y轴显示be节点压缩速率,右Y轴显示的整个集群累计做base compaction的大小。
2、BE Compaction Cumulate:BE的Base Cumulate压缩速率。左Y轴显示be节点压缩速率,右Y轴显示的整个集群累计做Cumulate compaction的大小。
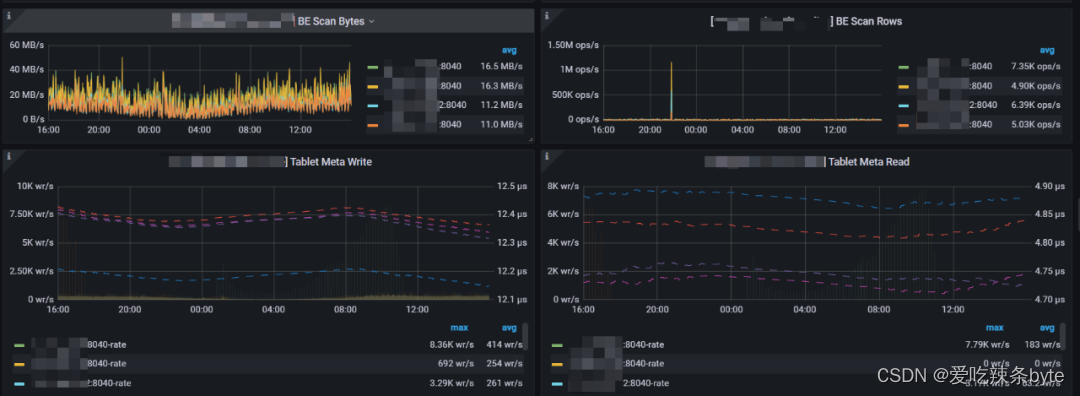
1、BE Scan Bytes:BE扫描效率,这表示处理查询时的读取率。(该值可以结合qps一起参考集群的查询压力)
2、BE Scan Rows:BE扫描行的效率,这表示处理查询时的读取率。
3、Tablet Meta Write:左Y 轴显示了tablet header 的写入速率。右侧 Y 轴显示每次写入操作的持续时间。
4、Tablet Meta Read:左Y 轴显示了tablet header 的读取速率。右侧 Y 轴显示每次读操作的持续时间。
2.2.8 BE tasks
BE服务任务级别的监控指标:
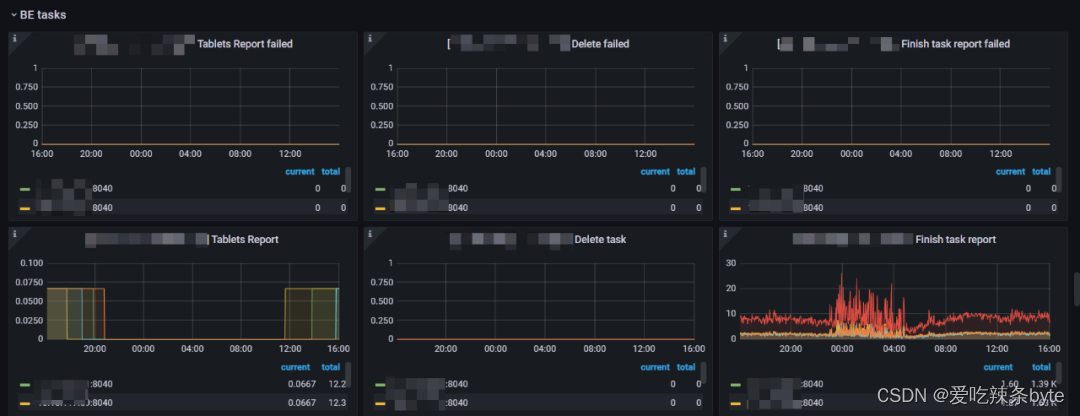
1、Tablets Report failed:BE Tablet 汇报给FE的失败率。(正常值是0,如果该值异常,考虑排查FE BE通信,或者FE BE负载是否有问题)
2、Delete failed:BE 做删除操作的失败率。(一般不会出现失败,如果删除失败检查一下磁盘是否正常)
3、Finish task report failed:BE向FE汇报的失败率。(正常值是0,如果该值异常,考虑排查FE BE通信,或者FE BE负载是否有问题)
4、Tablets Report:BE向FE做全量Tablet汇报的频率(正常的值是在0.67左右,如果该值减少,需要排查一下BE节点的负载情况)
5、Delete task:BE做删除操作的频率。(用来监控集群删除数据的频率,一般情况是0,如果该值比较大,需要排查集群是否在做 删表,删库操作)
6、Finish task report:BE节点运行Task的频率(可以用来衡量BE的繁忙程度和并发)
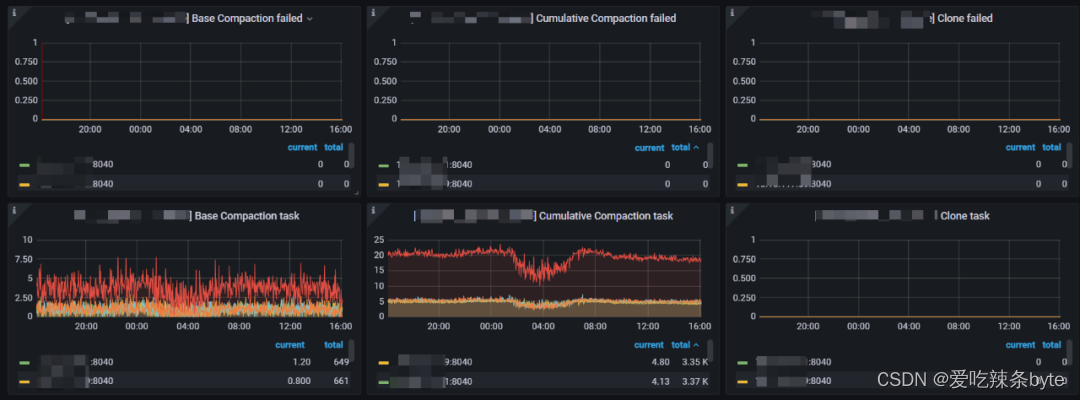
1、Base Compaction failed:Base compaction失败率(BE做大合并的失败率,正常是0,如果该值异常,需要检查Be compaction内存,以及BE的IO是否正常。)
2、Cumulative Compaction failed:Cumulative Compaction(BE做小合并的失败率,正常是0,如果该值异常,需要检查Be compaction内存,以及BE的IO是否正常。)
3、Clone failed:tablet clone的失败率(Tabelt 做副本修复或者均衡的时候会clone,该值异常检查一下BE的IO)
4、Base Compaction task:Be做base compaction的频率。(用来反应当前集群的compaction大压力,如果Tablet 不及时做compaction,会影响读写性能,可以调整base compaction的并发来调整)
5、Cumulative Compaction task:BE做cumulative compaction的频率。(用来反应当前集群的小compaction压力,如果Tablet 不及时做compaction,会影响读写性能,可以调整cumulative compaction的并发来调整)
6、Clone task:BE节点Tablet 做复制的频率(这个可以结合 scheduler tablet监控一起来判断集群的Tablet复制的情况)

1、Create tablet:新建Tablet 频率(一般新建表,新建分区,写数据会伴随着tablet数的增加,改值可以用来衡量集群的写入频率)
2、Single Tablet Report:tablet的汇报频率(左侧 Y 轴表示指定任务的失败率。通常,它应该是 0。右侧 Y 轴表示所有 Backends 中指定任务的总数。)
3、Create tablet failed:新建Tablet 失败率(一般新建表,新建分区,写数据会伴随着tablet数的增加,该值正常是0,如果该值异常要检查一下集群是否有建表,建分区失败的情况)
2.2.9 BE Mem
BE服务内存分配使用情况:
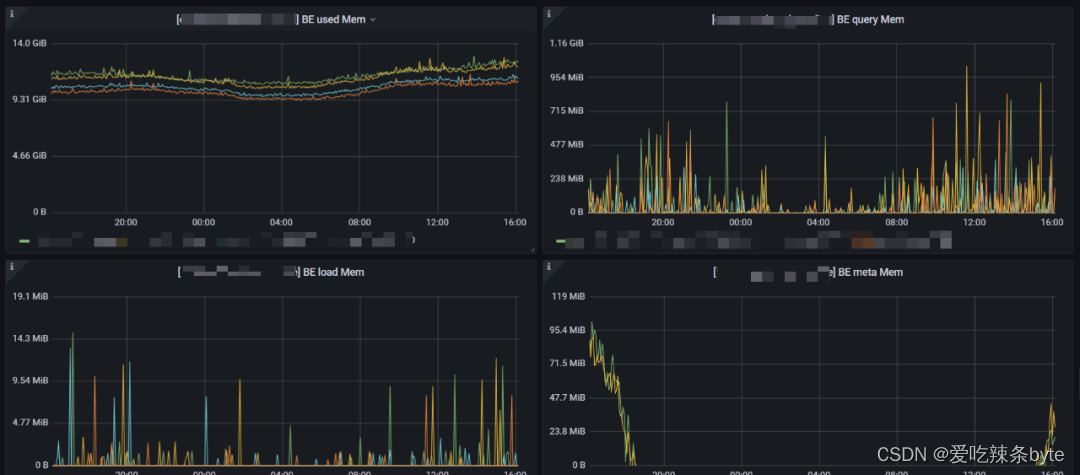
1、BE used Mem:BE服务使用的总内存(当前BE节点配置的内存基本都为机器内存的80%,如果使用内存超了需要,排查内存具体消耗在哪里,具体优化或者分析是否需要扩容)
2、BE query Mem:查询部分消耗的内存。(对于64G内存的机器,当前该值的限制是40G,该内存需要结合QPS,慢查询一起治理优化)
3、BE load Mem:导入任务消耗的内存。(对于64G内存的机器,当前该值的限制是13G,如果该值大,需要连接集群Show Load;查看当前的导入任务,建议超过10G大小的数据,不要再业务高峰期操作)
4、BE meta Mem:BE消耗元数据总内存。(在查询和导入的时候,BE会把相关的Tablet元数据加载到内存中,这部分内存目前没有命令可以主动释放,需要重启节点才能释放)
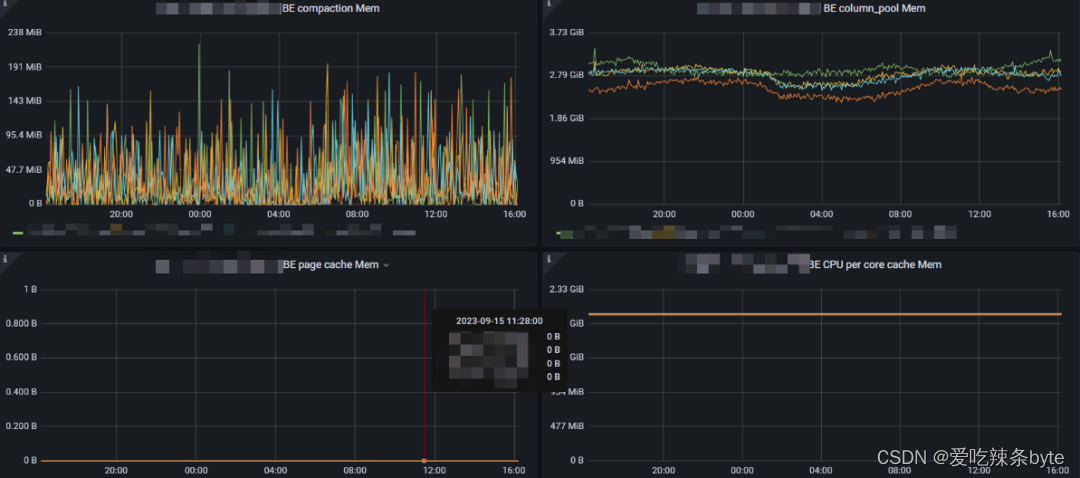
1、BE compaction Mem:BE服务做compaction合并使用的内存。(对于64G的机器,当前该值的限制是14G,建议超过10G大小的数据,不要再业务高峰期操作,否则做compaction会很消耗内存,影响集群的查询)
2、BE column_pool Mem:column pool 内存池,用于加速存储层数据读取的 Column Cache。(在做查询的时候,会把部分缓存保留在内存中,该内存没有命令主动释放,只能重启节点才能释放)
3、BE page cache Mem:BE 存储层 Page 缓存。(当前集群都没有开启Page cache)
4、BE CPU per core cache Mem:CPU per core 缓存,用于加速小块内存申请的 Cache。
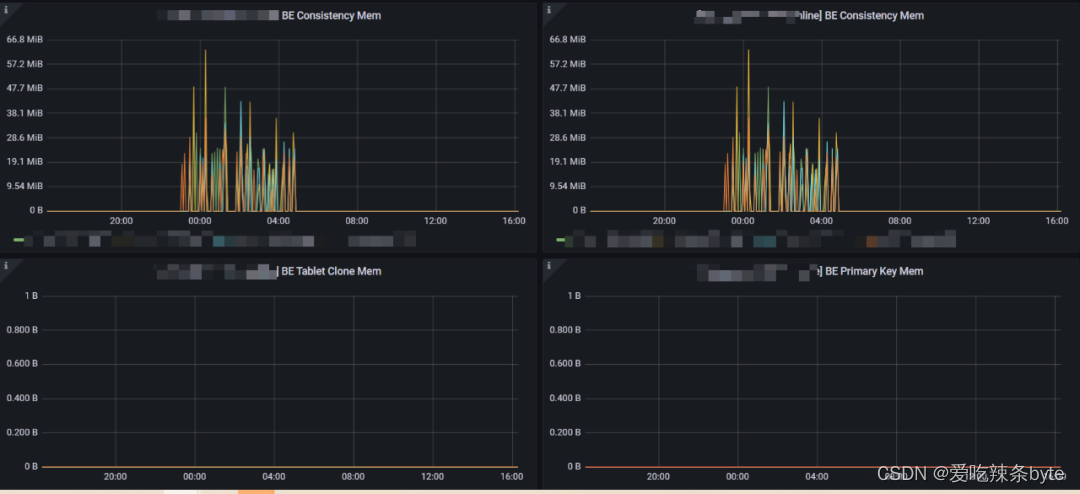
1、BE Consistency Mem:集群做Tablet 一致性校验的时候消耗的内存(集群会周期性的自动触发做一致性校验,有不一致的之后会伴随着Tablet 的复制,改情况为正常情况)
2、BE Primary Key Mem:主键索引消耗的内存。(对于64G的机器,该值的限制是26G,默认主键表在写入的时候,会把目标分区的主键索引都加载到内存中,如果该值过大,可以联系运维,访问BE 8040端口查看主键内存消耗的集群情况,找到对应的表做对应治理)
3、 BE Tablet Clone Mem:Tablet 复制时消耗的内存(如果该值过大,需要排查集群tablet的健康情况,一般会伴随大量的Tablet Scheduler)
三、总结
在 StarRocks 中,合理建表和集群监控是数据分析和查询引擎的关键环节。建表是构建数据基础的第一步,需要精心规划和管理,以确保数据的高效存储和查询。同时,监控则是保障系统稳定性和性能的守护者,通过实时的性能分析和故障检测,及时发现并解决潜在问题,确保系统持续运行。
参考文章:

