
- 1stm32与51 Proteus仿真初体验之点灯大师
- 2xcode在应用市场不能直接更新时,可以用以下方法:_xcode15更新网站
- 3Python 将Influxdb时序数据写入mysql库时遇到的问题
- 4计算机应届生有没有必要参加IT培训?_应届生计算机培训有没有必要
- 5保姆级 -- Zookeeper超详解
- 6对泛型的认识_symbol: variable roundingmode where t is a type-va
- 7微星迫击炮b660m使用intel arc a750/770显卡功耗优化方法_native pcie enable
- 8Github 2024-02-08 开源项目日报 Top9_我的电视 github
- 9小程序backgroundAudioManager.pause()无法停止播放的原因_taro.stopbackgroundaudio不生效
- 10java+idea+mysql采用医疗AI自然语言处理技术的3D智能导诊导系统源码
Vitis HLS 学习笔记--优化指令-ARRAY_PARTITION
赞
踩
目录
1. ARRAY_PARTITION 概述
ARRAY_PARTITION 指令中非常重要,它用于优化数组的存储和访问。该指令可以将一个大数组分割成多个小数组,以提高并行处理能力和减少访问延迟。
其实这个过程类比到RTL种,就是手动分配如下数组:
reg [数据位宽-1:0] my_array [维度2:0][维度1:0];
HLS 提供了一个更高级的抽象层次,允许我们在不需要关心将 my_array 分解为多少个子数组以优化访问时序的情况下进行操作。它为数组分割的快速分析和实施提供了一种极为便捷的方法。
2. 语法解析
#pragma HLS array_partition variable=<name> type=<type> factor=<int> dim=<int>2.1 参数解释
2.1.1 variable
必要实参,用于指定要分区的阵列变量。
2.1.2 type
指定分区类型,可选。默认类型为 complete。支持以下类型:
- cyclic:循环分区会通过交织来自原始阵列的元素来创建更小的阵列。该阵列按循环进行分区,具体方式是在每个新阵列中放入一个元素,然后回到第一个阵列以重复该循环直至阵列完全完成分区为止。例如,如果使用 factor=3:
- 向第 1 个新阵列分配元素 0
- 向第 2 个新阵列分配元素 1
- 向第 3 个新阵列分配元素 2
- 向第 4 个新阵列分配元素 3
- block:块分区会从原始阵列的连续块创建更小阵列。这样可将阵列有效分区为 N 个相等的块,其中 N 为 factor= 实参定义的整数。
- complete:完全分区可将阵列分解为多个独立元素。对于一维阵列,这对应于将存储器解析为独立寄存器。这是默认 <type>。
2.1.3 factor
指定要创建的更小的阵列数量。
仅对于 block 和 cyclic 型分区生效!
2.1.4 dim
指定要分区的多维阵列的维度。针对含 <N> 维的阵列,指定范围介于 0 到 <N> 之间的整数:
- 如果使用 0 值,则使用指定的类型和因子选项对多维阵列的所有维度进行分区。
- 任意非零值均表示只对指定维度进行分区。例如,如果使用的值为 1,则仅对第 1 个维度进行分区。
2.2 典型示例
complete类型比较多见,故选择此类型进行分析。
- int l_A[2][5];
- #pragma HLS ARRAY_PARTITION variable=l_A type=complete dim=?
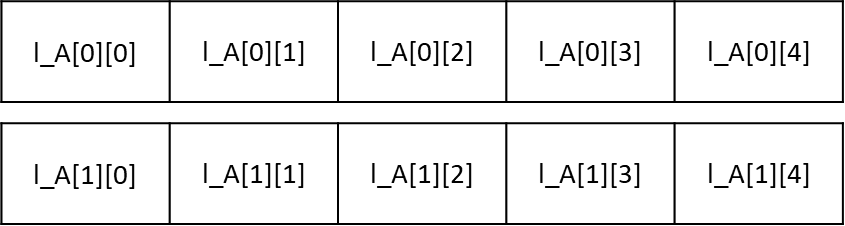
对于l_A[2][5],其元素分布如下:
| l_A[0][0] | l_A[0][1] | l_A[0][2] | l_A[0][3] | l_A[0][4] |
| l_A[1][0] | l_A[1][1] | l_A[1][2] | l_A[1][3] | l_A[1][4] |
2.2.1 dim=1
第 1 个维度进行分区,相当于将l_A[2][5]拆分成两个2元素数组。
它们分别存储在2个 ram_1p 的存储器中。
可以同时访问所有l_A[0][x]和l_A[1][x]。
该分区方法,每个时钟周期可以读取两个数据。
2.2.2 dim=2
第 1 个维度进行分区,相当于将l_A[2][5]拆分成两个5元素数组。

它们分别存储在5个 ram_1p 的存储器种。
可以同时访问所有l_A[x][0]、l_A[x][1]、l_A[x][2]、l_A[x][3]、l_A[x][4]。
该分区方法,每个时钟周期可以读取5个数据。
2.2.3 dim=0
当dim=0时,表示对整个数组进行完全分区,不考虑具体的维度。这意味着数组的每个元素都将被单独存储,完全独立地占用资源。对于l_A[2][5],这将导致所有10个元素都被独立存储,每个元素可以被单独访问,这最大化了并行访问能力,但也大量占用资源。
3. 实例演示
- #include <stdio.h>
- #include <string.h>
-
- #define MAX_SIZE 16
-
- const unsigned int c_dim = MAX_SIZE;
-
- extern "C" {
- void matmul(int* in1, int* in2, int* out_r, int size, int rep_count) {
- // Local buffers to hold input data
- int A[MAX_SIZE][MAX_SIZE];
- int B[MAX_SIZE][MAX_SIZE];
- int C[MAX_SIZE][MAX_SIZE];
- int temp_sum[MAX_SIZE];
-
- // Read data from global memory and write into local buffer for in1
- readA:
- for (int itr = 0, i = 0, j = 0; itr < size * size; itr++, j++) {
- #pragma HLS LOOP_TRIPCOUNT min = c_dim* c_dim max = c_dim * c_dim
- if (j == size) {
- j = 0;
- i++;
- }
- A[i][j] = in1[itr];
- }
-
- // Read data from global memory and write into local buffer for in2
- readB:
- for (int itr = 0, i = 0, j = 0; itr < size * size; itr++, j++) {
- #pragma HLS LOOP_TRIPCOUNT min = c_dim* c_dim max = c_dim * c_dim
- if (j == size) {
- j = 0;
- i++;
- }
- B[i][j] = in2[itr];
- }
-
- // Calculate matrix multiplication using local data buffer based on input size,
- // and write results into C
- count_loop:
- for (int i = 0; i < rep_count; i++) {
- nopart1:
- for (int row = 0; row < size; row++) {
- #pragma HLS LOOP_TRIPCOUNT min = c_dim max = c_dim
- nopart2:
- for (int col = 0; col < size; col++) {
- #pragma HLS LOOP_TRIPCOUNT min = c_dim max = c_dim
- nopart3:
- for (int j = 0; j < MAX_SIZE; j++) {
- #pragma HLS LOOP_TRIPCOUNT min = c_dim max = c_dim
- int result = (col == 0) ? 0 : temp_sum[j];
- result += A[row][col] * B[col][j];
- temp_sum[j] = result;
- if (col == size - 1) C[row][j] = result;
- }
- }
- }
- }
-
- // Write results from local buffer to global memory for out
- writeC:
- for (int itr = 0, i = 0, j = 0; itr < size * size; itr++, j++) {
- #pragma HLS LOOP_TRIPCOUNT min = c_dim* c_dim max = c_dim * c_dim
- if (j == size) {
- j = 0;
- i++;
- }
- out_r[itr] = C[i][j];
- }
- }
- }

添加这几行指令:
#pragma HLS ARRAY_PARTITION variable = B dim = 2 complete
#pragma HLS ARRAY_PARTITION variable = C dim = 2 complete
#pragma HLS ARRAY_PARTITION variable = temp_sum dim = 1 complete
运行 Vitis HLS 编译器,我们得到如下结果:
- ================================================================
- == Bind Storage Report
- ================================================================
- +--------------------+------+------+--------+----------+---------+------+---------+
- | Name | BRAM | URAM | Pragma | Variable | Storage | Impl | Latency |
- +--------------------+------+------+--------+----------+---------+------+---------+
- | + matmul_partition | 1 | 0 | | | | | |
- | A_U | 2 | - | | A | ram_1p | auto | 1 |
- | B_U | - | - | | B | ram_1p | auto | 1 |
- | B_1_U | - | - | | B_1 | ram_1p | auto | 1 |
- | B_2_U | - | - | | B_2 | ram_1p | auto | 1 |
- | B_3_U | - | - | | B_3 | ram_1p | auto | 1 |
- | B_4_U | - | - | | B_4 | ram_1p | auto | 1 |
- | B_5_U | - | - | | B_5 | ram_1p | auto | 1 |
- | B_6_U | - | - | | B_6 | ram_1p | auto | 1 |
- | B_7_U | - | - | | B_7 | ram_1p | auto | 1 |
- | B_8_U | - | - | | B_8 | ram_1p | auto | 1 |
- | B_9_U | - | - | | B_9 | ram_1p | auto | 1 |
- | B_10_U | - | - | | B_10 | ram_1p | auto | 1 |
- | B_11_U | - | - | | B_11 | ram_1p | auto | 1 |
- | B_12_U | - | - | | B_12 | ram_1p | auto | 1 |
- | B_13_U | - | - | | B_13 | ram_1p | auto | 1 |
- | B_14_U | - | - | | B_14 | ram_1p | auto | 1 |
- | B_15_U | - | - | | B_15 | ram_1p | auto | 1 |
- | C_U | - | - | | C | ram_1p | auto | 1 |
- | C_1_U | - | - | | C_1 | ram_1p | auto | 1 |
- | C_2_U | - | - | | C_2 | ram_1p | auto | 1 |
- | C_3_U | - | - | | C_3 | ram_1p | auto | 1 |
- | C_4_U | - | - | | C_4 | ram_1p | auto | 1 |
- | C_5_U | - | - | | C_5 | ram_1p | auto | 1 |
- | C_6_U | - | - | | C_6 | ram_1p | auto | 1 |
- | C_7_U | - | - | | C_7 | ram_1p | auto | 1 |
- | C_8_U | - | - | | C_8 | ram_1p | auto | 1 |
- | C_9_U | - | - | | C_9 | ram_1p | auto | 1 |
- | C_10_U | - | - | | C_10 | ram_1p | auto | 1 |
- | C_11_U | - | - | | C_11 | ram_1p | auto | 1 |
- | C_12_U | - | - | | C_12 | ram_1p | auto | 1 |
- | C_13_U | - | - | | C_13 | ram_1p | auto | 1 |
- | C_14_U | - | - | | C_14 | ram_1p | auto | 1 |
- | C_15_U | - | - | | C_15 | ram_1p | auto | 1 |
- +--------------------+------+------+--------+----------+---------+------+---------+
数组A未指定特定分区,因此将整体存储于单个ram_1p存储器中。而数组B与数组C经过特定设置,按照dim=2的维度被分割为16个区块(即16个ramp_1p存储器),这意味着数组B和数组C能够并行读取16个数据项。此举显著提升了程序处理的吞吐率。
4. 总结
ARRAY_PARTITION指令是高层次综合中一个强大的工具,它可以帮助设计者在保证性能的同时,更有效地利用硬件资源。合理的数组分区可以在不牺牲性能的前提下,优化硬件资源的使用,尤其是在资源受限的设计中。


