
热门标签
热门文章
- 1raspberry pi pico建立C++环境报错解决_pico-project-generator 启动不了
- 2idea,webstorm等系列通用激活
- 3ai智能外呼机器人如何进行外呼工作的
- 4LeetCode 114. 二叉树展开为链表_public static void flatten(treenode root){
- 5JDK 常用工具 —— jstat 详解_jstat -gcutil参数说明
- 6使用VSCode编辑器创建React.js项目_vscode react.js
- 7基于SpringBoot+Vue的毕业设计管理系统(源码+文档+部署+讲解)_基于springboot和vue的毕设
- 851单片机使用uart串口和助手简单调试
- 9电子计算机eniac的储存能力有限 只能,电子计算机ENIAC的存储能力有限,只能存储简单的控制程序代码。...
- 10uniapp-IOS自定义启动页面模版的修改
当前位置: article > 正文
推荐算法之召回模型:DSSM、YoutubeDNN_dssm的缺点
作者:小蓝xlanll | 2024-04-27 03:32:47
赞
踩
dssm的缺点
1. DSSM
1.1 DSSM模型原理
DSSM(Deep Structured Semantic Model),由微软研究院提出,利用深度神经网络将文本表示为低维度的向量,应用于文本相似度匹配场景下的一个算法。不仅局限于文本,在其他可以计算相似性计算的场景,例如推荐系统中。根据用户搜索行为中query(文本搜索)和doc(要匹配的文本)的日志数据,使用深度学习网络将query和doc映射到相同维度的语义空间中,即query侧特征的embedding和doc侧特征的embedding,从而得到语句的低维语义向量表达sentence embedding,用于预测两句话的语义相似度。
1.2 DSSM结构
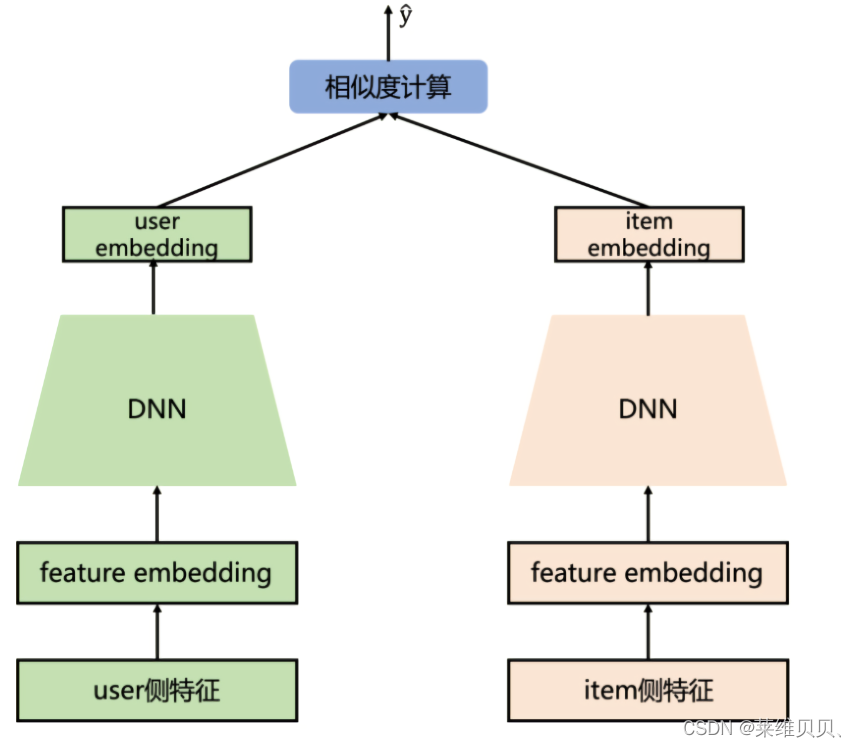
模型结构:user侧塔和item侧塔分别经过各自的DNN得到embedding,再计算两者之间的相似度
特点:
- user和item两侧最终得到的embedding维度需要保持一致
- 对物料库中所有item计算相似度时,使用负采样进行近似计算
- 在海量的候选数据进行召回的场景下,速度很快
**缺点:**双塔的结构无法考虑两侧特征之间的交互信息,在一定程度上牺牲掉模型的部分精准性。
1.3 正负样本构建
正样本:以内容推荐为例,选“用户点击”的item为正样本。最多考虑一下用户停留时长,将“用户误点击”排除在外
负样本:user与item不匹配的样本,为负样本。
- 全局随机采样: 从全局候选item里面随机抽取一定数量作为召回模型的负样本,但可能会导致长尾现象。
- 全局随机采样+热门打压:对一些热门item进行适当的采样,减少热门对搜索的影响,提高模型对相似item的区分能力。
- Hard Negative增强样本:选取一部分匹配度适中的item,增加模型在训练时的难度
- Batch内随机选择:利用其他样本的正样本在batch内随机采样作为自己的负样本
1.4 DSSM的代码
class DSSM(torch.nn.Module):
def __init__(self, user_features, item_features, user_params, item_params, temperature=1.0):
super().__init__()
self.user_features = user_features
self.item_features = item_features
self.temperature = temperature
self.user_dims = sum([fea.embed_dim for fea in user_features])
self.item_dims = sum([fea.embed_dim for fea in item_features])
self.embedding = EmbeddingLayer(user_features + item_features)
self.user_mlp = MLP(self.user_dims, output_layer=False, **user_params)
self.item_mlp = MLP(self.item_dims- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
推荐阅读
相关标签

