
- 1kube-bench初体验
- 2python头歌-python第六章作业_头歌python第六章作业答案
- 3嵌入式开发-各种干货_dsk嵌入视频
- 4Python 中filter函数用法
- 5etcd 与 Zookeeper、Consul 等其它 kv 组件的对比
- 6Java面向对象:封装、继承、多态_java面向对象 - 封装、继承和多态头歌
- 7androidsdktools安装_Android-sdk 安装
- 8使用javaAPI对HDFS进行文件上传,下载,新建文件及文件夹删除,遍历所有文件_hadoop 遍历hdfs指定文件夹
- 9spark 类别特征_Spark 贝叶斯分类算法
- 10聚焦AI4S,产学研专家齐聚,探讨AI工具在多领域应用的现状与趋势
面试字节被挂了
赞
踩
分享一个面试字节的经历。
1、面试过程
一面:上来就直接"做个题吧",做完之后,对着简历上一个项目聊,一直聊到最后,还算比较正常。
二面:做自我介绍,花几分钟聊了一个项目,剩下20分钟全聊基础,CNN、pooling、1x1卷积,最后又做了一个题。
三面:做了个自我介绍,聊 GPU 与显存的内容,然后跟我讲业务,反问了我一句:"你们这个从0到1之后能从1到100吗?有可持续研究的价值吗?",问的是一脸懵。
最后在反问环节,我了解到他们部门竟然以NLP为主,但是面试问的全是 CV 方向的。
最后面试挂了,真的很奇葩。

这让我回想起几年前我面试某大厂的时候,被问到了很多深度学习相关的知识,那时的我懂的不多,可以说是被面试官360度无死角蹂躏。
那次面试,印象最深的就是被问到了和上面的小伙伴遇到的一样的问题:1X1卷积的作用。
今天就介绍一下:在卷积神经网络中,1x1的卷积都有什么作用?
2、在卷积神经网络中,1x1的卷积有什么作用呢?
大概有以下几个作用。
第一是可以实现输出feature map(特征图)的升维和降维
第二个是可以减少模型中的参数量,从而减少计算量,提升模型的推理性能
除此之外,就是使用1x1的卷积可以增加网络的深度,从而提升模型的非线性表达能力。
3、1x1的卷积是如何实现升维和降维的
这里说的1x1的卷积实现升维和降维的功能,指的是 feature map 通道维度的改变,也即特征维度的改变。
这是因为1x1的卷积,卷积核长宽尺寸都是 1,在计算的过程中,不存在长、宽方向像素之间的融合计算(乘累加计算),而仅仅存在通道之间的融合计算。
因此,在这种情况下,1x1的卷积所能改变的仅仅是通道数。
而从卷积算法上可以看出,卷积核的个数就是卷积输出的通道数。因此如果想让输出特征图的通道数增大,就要使用更多数量的卷积核来做卷积,从而实现特征维度的升或者降。
4、1x1的卷积是如何减少模型参数的
减少参数量可以这么理解:在输出相同特征图的前提下,将一个普通的卷积,替换成一个1x1的卷积加上另一个卷积,先进行降维,然后计算,如此一来整体的计算量要比普通卷积少。
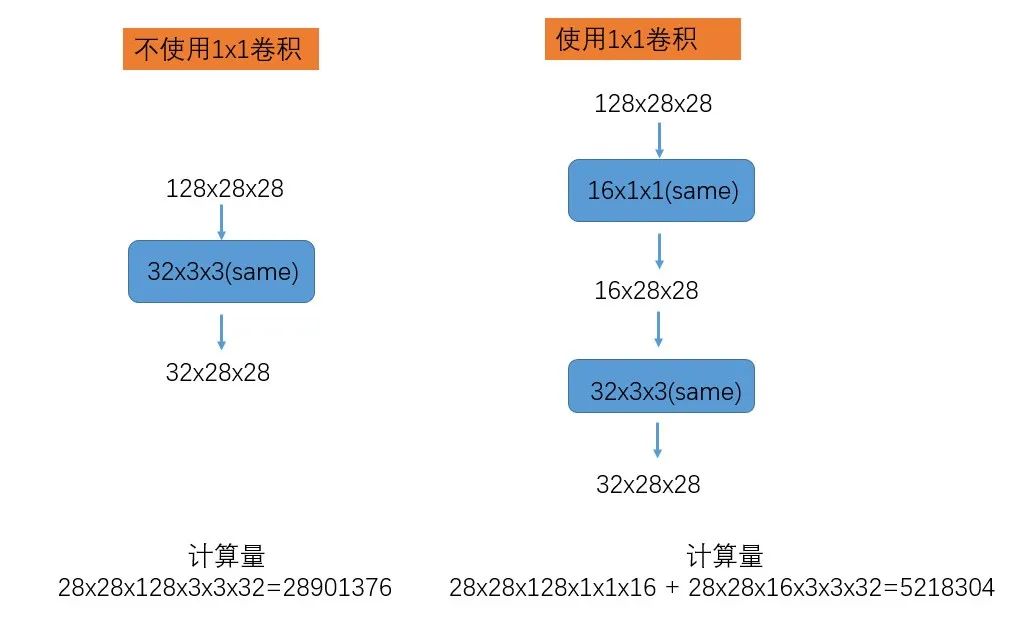
举个例子,如上图所示。
假设一个卷积的输入通道是128,输出通道是32,如果不使用1x1的卷积,那么整个卷积的乘累加计算量是:
28x28x128x3x3x32 = 28901376
而如果使用1x1的卷积先降维处理,然后在降维之后的特征图上进行一个卷积计算,那么整体的乘累加计算量为:
128x28x28x16 + 28x28x16x3x3x32 = 5218304
两者对比,后者比前者减少了80%的计算量。
5、如何理解1x1卷积可以提升模型的非线性表达能力
神经网络模拟的就是一个非线性系统,之所以在卷积层后面增加非线性层,比如Relu层,其实就是这个道理。
而1x1的卷积可以使得在完成相同卷积功能的前提下,网络的层数变得更深(如上面的例子,一个普通卷积变成了2层卷积)。
网络层数的加深,就会导致更多非线性层数的增加,从而使得整个神经网络模型的非线性表达能力更强。
6、1x1的卷积还有其他哪些优势吗
1x1的卷积还可以增加通道之间的融合程度。
由于1x1卷积不存在长宽方向的像素融合,所有的计算都是通道之间的交叉计算,因此,可以更好的完成通道间的融合,而通道代表的是特征,因此可以更好的实现特征融合。
这一点,和全连接类似(因为1x1的卷积就可以表示为全连接)。
总之,如果在面试过程中被问到关于1x1的卷积问题,把上面的几点回答出来,这个问题基本就可以了,不知道有没有小伙伴被问道过这个问题呢,欢迎大家在评论区交流学习一下~~

