
- 1Web Storm 的使用指南*(破解方法,快捷键,插件安装,常用插件,中文)_webstorm解码插件怎么用
- 2on windows in superset sql lab error "module object has no attribute sigalrm"
- 3windows 10安装MySQL-5.7版本全流程教程_win10安装mysql5.7
- 4相关与因果的相爱相杀——新书《为什么:因果关系的新科学》解读(上)_the book of why: the new science of cause and effe
- 5随机森林模型RandomForest scikit-learn参数说明_randomforestclassifier(n_estimators=n_estimators
- 620道常考Python面试题大总结_python基础面试
- 7【C++】使用 nlohmann 解析 json 文件
- 8福布斯富豪榜_福布斯富豪榜1982年排名
- 9零基础量化交易:Python入门_量化交易python培训
- 10Guacamole之本地安装Guacamole(二)
详解各种LLM系列|(2)LLaMA 2模型架构、 预训练、SFT、RLHF内容详解(PART-2)_llm sft prompt predict fft
赞
踩
引言
Llama 2是Meta在LLaMA基础上升级的一系列从 7B到 70B 参数的大语言模型。Llama2 在各个榜单上精度全面超过 LLaMA1,Llama 2 作为开源界表现最好的模型之一,目前被广泛使用。
对于Llama 2模型架构、 预训练、SFT的内容详解,请参考详解各种LLM系列|(2)LLaMA 2模型架构、 预训练、SFT内容详解 (PART-1)-CSDN博客
这一篇继续详细深入Llama 2的 RLHF内容,以及其实现的实验结果。
五、Reinforcement Learning with Human Feedback (RLHF)
RLHF是一种模型训练程序,应用于微调的语言模型,以进一步使模型行为与人类偏好和指令遵循保持一致。
(对于RL 不了解的小伙伴,可以参考这篇一文看懂什么是强化学习?(基本概念+应用场景+主流算法))
Llama 2的RLHF的主要过程为:人类偏好数据收集 -> 根据数据训练Reward Model -> 用RL的方式迭代式微调(使用PPO和Rejection Sampling)
(笔者NOTE: 简而言之,RLHF 就是先通过获取人类偏好的数据来训练一个reward model,这个reward model学习了人类对于语言的偏好;然后这个model会用于对LLM输出打分,根据所获取的每一步的分数,训练LLM往最终产生的整体回复能获取最大分数的方向靠拢)
5.1 人类偏好数据
- 二元比较数据: 主要是因为它允许最大化收集到的提示的多样性
- 标注过程:要求注释者首先编写一个prompt,然后根据提供的标准在两个抽样的模型的回复(response)之间进行选择;
为了使多样性最大化,对给定prompt的两个response从两个不同的模型生成,并调整温度超参数;
除了给参与者一个强制性的选择,还要求标注者标注他们对所选择的回应与备选回应的偏好程度:他们的选择是明显更好、更好、稍微更好、或者几乎一样好/不确定 - 标注指标:关注帮助性 (helpfulness,即模型回复满足用户请求并提供请求信息的程度) 和安全性 (safety,即模型回复的安全性)
- 每周分批收集并迭代:在新的Llama 2-Chat调优迭代之前,使用最新的Llama 2-Chat迭代收集新的偏好数据,再用于后续迭代
(这一步骤有助于保持奖励模型分布,并为最新模型保持准确的奖励)
5.2 奖励模型 (Reward Model)
奖励模型将模型回复及其相应的提示(包括来自前一个回合的上下文)作为输入,并输出一个标量分数来指示模型生成的质量(例如,有用性和安全性)。利用这样的反馈分数作为奖励,我们可以在RLHF期间优化Llama 2-Chat,以更好地调整人类的偏好,提高帮助和安全性。
5.2.1 奖励模型初始化
- 两个Reward Model: 一些研究发现帮助性和安全性有时需要 trade-off,这可能会使单个奖励模型在这两者上同时表现良好具有挑战性。为了解决这个问题,研究团队训练了两个独立的奖励模型,一个针对有用性(称为Helpfulness RM)进行了优化,另一个用于安全(Safety RM)
- 从之前的Llama 2-chat检查点初始化:从预训练的Llama 2-chat检查点初始化的奖励模型,这确保两个模型都受益于预训练中获得的知识。简而言之,奖励模型“知道”Llama 2-chat知道什么。这可以防止两个模型会有信息不匹配的情况,这可能导致幻觉
- RM模型架构和超参数与预训练的Llama 2模型相同,除了用于下一个标记预测的分类头被用于输出标量奖励的回归头所取代。
5.2.2 奖励模型训练目标
- 研究团队将收集到的成对的人类偏好数据转换为二元排名标签格式(即选择和拒绝),并强制选择的响应具有比对应响应更高的分数。
- 训练 loss:促使 chosen 的样本得分比 reject 要高,所用的损失函数如下图所示:
(其中 x 是 prompt,yc 是标注员选择的模型回复,yr 是标注员拒绝的模型回复)

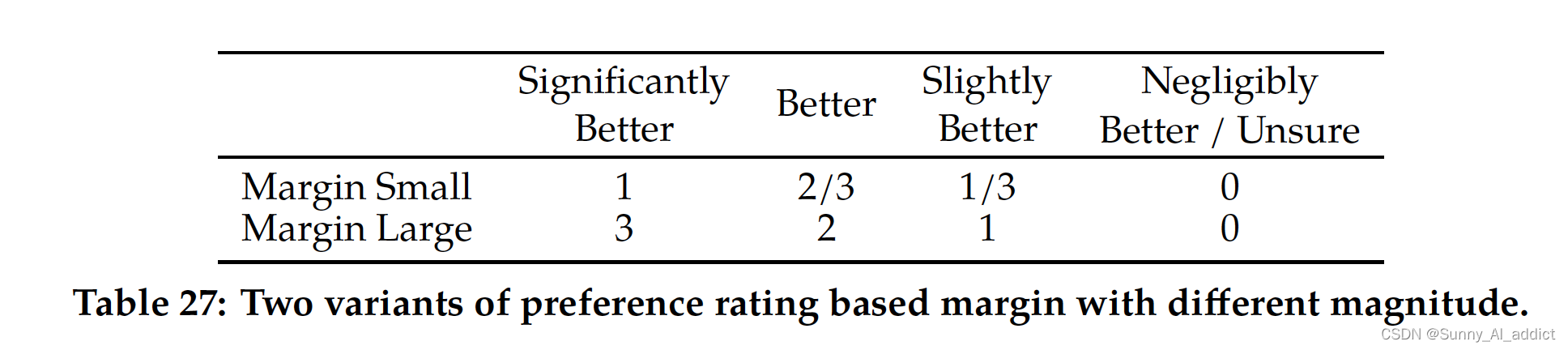
- 加入程度margin:为了利用上标注的两条数据的好坏确定程度(明显更好、更好、稍微更好、或者几乎一样好/不确定),增加了一个 margin 的 loss 项:
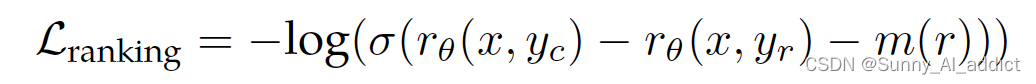
- 这个margin是一个离散函数,对具有不同响应对使用较大的 margin,对响应相似的对使用较小的 margin,具体值如下:
5.2.3 奖励模型训练数据(混合策略)
- 将标记数据与开源偏好数据集混合:研究团队并没有观察到来自开源偏好数据集的负迁移。因此,将这些开源偏好数据保留在最终的训练RM的数据中,因为它们可以为奖励模型提供更好的泛化,并防止奖励幻觉,即Llama 2-Chat利用奖励的一些弱点,从而夸大分数
- 混合策略:Helpfulness奖励模型最终是在所有Meta Helpfulness数据的基础上训练的,同时还结合了从Meta Safety和开源数据集中均匀采样的剩余数据;Safety奖励模型则是在所有Meta Safety和Anthropic Harmless数据上进行训练的,同时还混合了Meta Helpfulness和开源的Helpfulness数据,比例为90/10 (在10%Helpfulness数据的设置下,对于那些被所选和被拒绝的回答都是安全的的准确性尤为有益)
5.2.4 奖励模型训练
- 训练一个 epoch (训练长了会导致过拟合)
- 使用和基础模型相同的训练超参数
- 70B的模型使用5e-6的学习率,其他的使用1e-5学习率
- 余弦学习旅衰减,学习率降低到最大学习率的10%;使用总步数的3% 作为 warmup
- 每个 batch 有 512 pairs 数据
- 实现的效果:
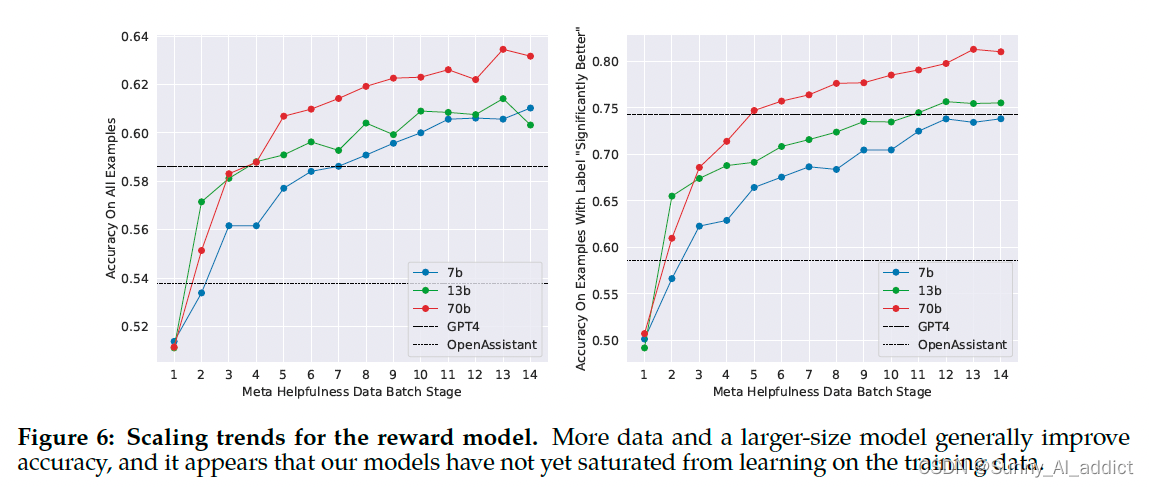
- 奖励模型的准确性是Llama 2-Chat最终性能的最重要代表之一。虽然综合评估生成模型的最佳实践是一个开放的研究问题,但奖励的排名任务没有任何歧义。因此,在其他条件相同的情况下,奖励模式的改进可以直接转化为Llama 2-Chat的改进。
5.3 RLHF迭代式微调
5.3.1 RLHF对应的基本概念
- Agent(智能体):强化学习的本体;在此情境下为经过SFT后的Llama2-Chat
- Environment (环境):智能体外的一切,由状态集合组成;在此情境下为与人对话着整个场景
- State(状态):某个时刻环境的状态;在此情境下为用户输入的prompt或者prompt加上输出的回复
(Note:对于answer的第二个词,可以把prompt+answer的第一个词当作新的state,而不只是把prompt当作state,状态转移蕴含在transformer内部) - Action(动作):智能体根据环境状态做出的动作;在此情境下为对应于prompt而输出的回复(answer)
- Reward(奖励):智能体在执行一个动作后,获得的反馈
- 整个流程:用户初始输入prompt是第一个state,只输入一次,然后模型输出一串action(回答的单词),得到一个reward,模型并没有在每个action之后得到新的state,二是在获取answer的第二个词后,把prompt+answer的第一个词当作新的state,而不只是把prompt当作state,状态转移蕴含在transformer内部
5.3.2 RLHF整体流程
当训练完奖励模型,能够获取对英语LLM的输出的奖励之后,为了模型不对某些提示的特定分布过拟合,研究团队使用了迭代式微调的策略,为 RLHF 模型训练了连续版本,这里称为 RLHF-V1, ..., RLHF-V5 等。
研究团队尝试了两种 RLHF 微调算法:
- Proximal Policy Optimization (PPO):PPO算法是一种强化学习中更新策略(Policy)的算法;相较于传统的Policy Gradient算法,Policy Gradient算法对步长十分敏感,但是又难以选择合适的步长,在训练过程中新旧策略的的变化差异如果过大则不利于学习;PPO提出了新的目标函数可以再在个训练步骤实现小批量的更新,解决了Policy Gradient算法中步长难以确定的问题。
(关于PPO的具体内容,可参考李宏毅老师的视频(讲的超级清楚)(选修)To Learn More - Proximal Policy Optimization (PPO)_哔哩哔哩_bilibili)
- Rejection Sampling(拒绝采样):一种对于复杂问题的采样策略;在强化学习中,智能体(agent)需要从环境中获得高质量的训练数据。使用 Rejection Sampling,可以更有效地从环境中采样出对学习策略更有价值的情况,从而提高训练数据的质量。
(关于拒绝采样,可参考蒙特卡洛采样之拒绝采样(Reject Sampling) | TwistedW's Home)
- 研究团队在应用拒绝采样时,从模型中采样 K 个输出,并根据奖励模型计算出的奖励选择最佳候选(与 Constitutional AI: Harmlessness from AI Feedback 论文方法一致)。研究团队进一步使用选择的输出进行梯度更新。对于每个提示,获得最高奖励分数的样本被认为是新的黄金标准,随后在新的排序样本集上微调模型,强化奖励
- 两种RL算法的主要区别在于:
- 深度:PPO 中,在步骤 t 训练期间,样本是在上一步梯度更新后从 t-1 更新的模型策略的函数。在拒绝采样中,在应用类似SFT的微调之前,在给定之前模型的初始策略的情况下对所有输出进行采样以收集新数据集。然而,由于应用了迭代模型更新,两种 RL 算法之间的根本差异不太明显
- 广度:在拒绝采样中,该模型为给定提示探索K个样本,而PPO只进行了一个样本的探索
(使用拒绝采样可以更有效地从环境中采样出对学习策略更有价值的情况;用拒绝采样获取了高质量的数据后,PPO 可以用来优化策略。由于 PPO 通过限制策略更新幅度来减少训练过程中的性能波动,它可以更有效地利用这些高质量数据来进行稳定的策略学习。结合这两种方法还可以帮助在探索(尝试新的行为以获取更多信息)和利用(使用已知信息来获得最佳结果)之间找到更好的平衡。Rejection Sampling 可以用来探索更多样的情境,而 PPO 则可以确保这些探索得到有效利用。)
- 结合拒绝采样和PPO:在RLHF (V4)之前,只使用拒绝采样微调,之后,研究团队将两者结合起来,在再次采样之前在Rejection Sampling checkpoint上应用PPO。
5.3.3 拒绝采样(Rejection Sampling)
- 用 70B Llama 2-Chat 执行拒绝采样:仅使用最大的 70B Llama 2-Chat 执行拒绝采样。所有较小的模型都根据来自较大模型的拒绝采样数据进行微调,从而将大模型能力提炼为较小的模型(相当于模型蒸馏)
- 使用所有RLHF迭代模型进行拒绝采样:在每个迭代阶段,研究团队从模型中为每个 prompt 采样 K 个答案。然后,使用当时实验可访问的最佳奖励模型对每个样本进行评分,并选择给定 prompt 的最佳答案。研究团将所有迭代中(RLHF-V1、RLHF-V2 、RLHF-V3)表现最好的样本都纳入训练数据。
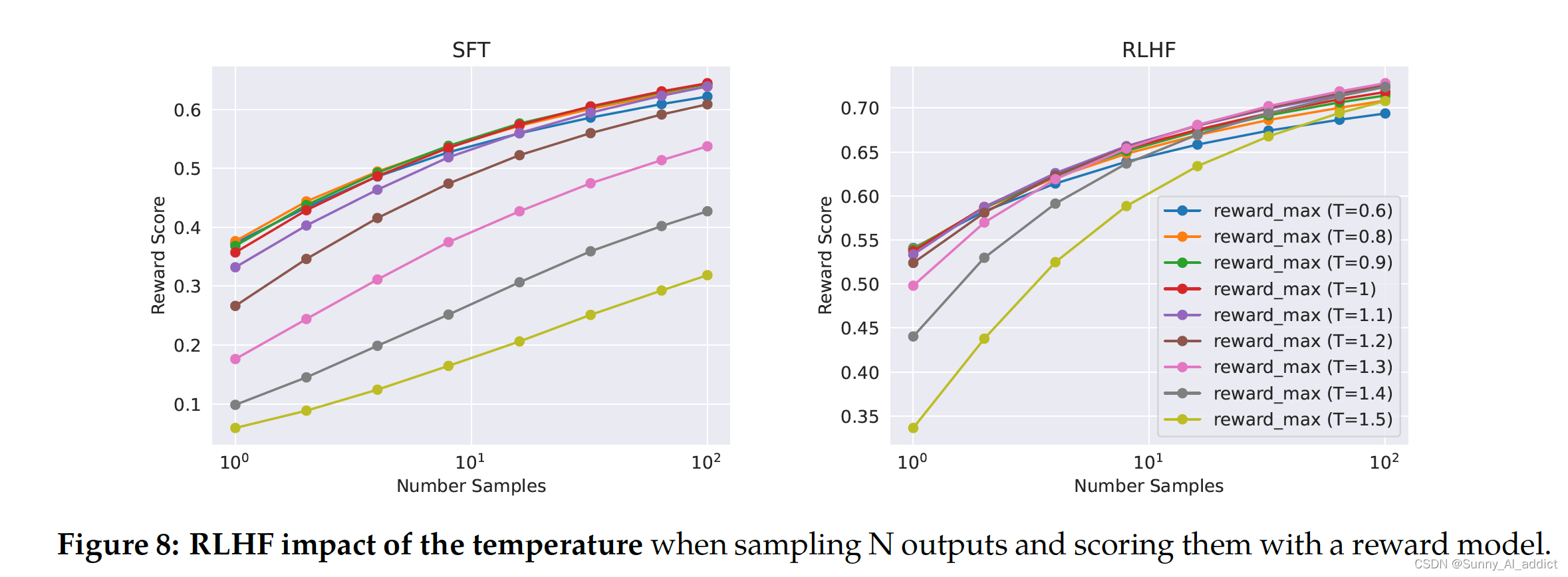
- 拒绝抽样的增益:如下图,最大曲线和中位数曲线之间的差异可以被解释为在最佳输出上进行微调的潜在收益。正如预期的那样,随着样本数量的增加,这种差异增大(即更多样本,更多机会生成良好的轨迹),而中位数保持不变。在样本中,探索和获得最大奖励之间存在直接联系。温度参数对于探索也起着重要作用,因为较高的温度能够使采样更多样化的输出。

- 经过拒绝采样训练后的最大奖励曲线:在下图中展示了 Llama 2-Chat-SFT(左图)和 Llama 2-Chat-RLHF(右图)的最大奖励曲线,这些曲线是在不同温度下进行 N 次样本采样(其中N ∈ [1, . . . , 100])得到的。可以观察到,在迭代模型更新的过程中,平均reward在增加;同时,最佳温度是不固定的,且RLHF对温度进行了直接影响。
5.3.4 PPO
PPO是一种off-policy的手段,使用奖励模型作为真实奖励函数(人类偏好)的估计,使用预训练的语言模型作为policy进行优化。
- 优化目标:优化目标就是提升 reward,同时与原始模型的输出加个 KL 散度约束(为了训练稳定性,并且缓解 reward hacking 情况)
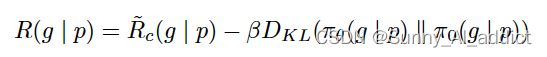
- 其中
是安全性奖励和帮助性奖励的分段组合。其计算公式如下:

- 将最终的线性分数进行白化,以增加稳定性并与上面的KL惩罚项(
)正确平衡:

5.3.5 训练细节
- AdamW:
= 0.9,
= 0.95
- Weight decay=0.1,Gradient clipping=1.0
- Constant learning rate=10−6
- Batch Size:512
- PPO clip threshold=0.2, mini batch size=64, take one gradient step per mini-batch
- KL 惩罚系数:7B and 13B 采用 0.01,34B 和 70B 采用 0.005
六、多轮一致性的系统消息
6.1 模型忘记初始指令
在对话设置中,有些指令应该适用于所有对话回合,例如要简洁回复,或者“扮演”某个公众人物。当向 Llama 2-Chat 提供这样的指令时,后续的回复应始终遵守这些限制。
然而,最初的 RLHF 模型在对话进行几个回合后往往会忘记初始指令,如下图(左图)所示。为了解决这些问题,研究团队提出了 Ghost Attention(GAtt)方法。GAtt 使得对话在多个回合内能够保持控制,如下图(右图)所示:
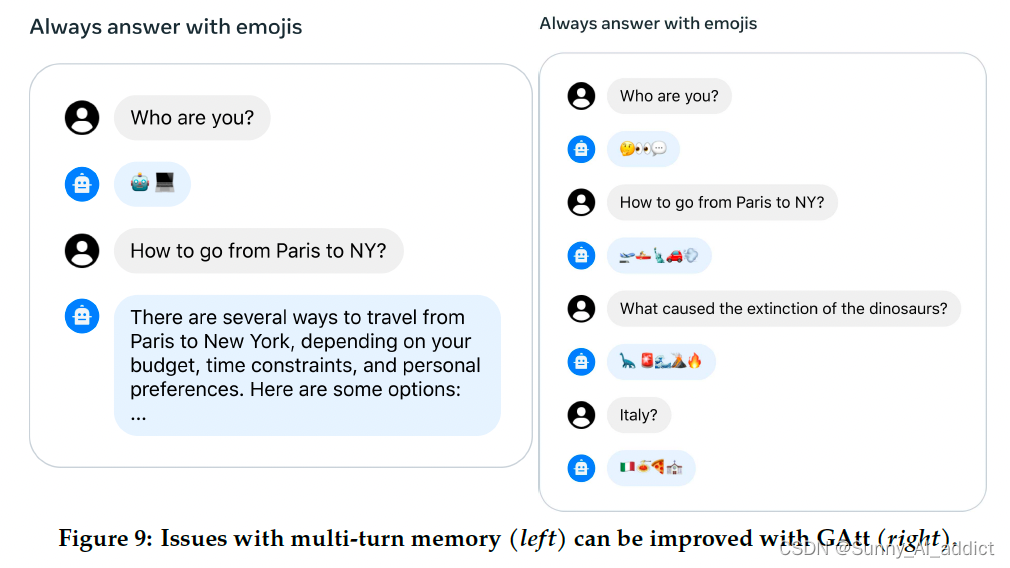
6.2 Ghost Attention (GAtt)
这是一个受 Context Distillation 启发的非常简单的方法,通过对微调数据进行干预来帮助注意力在多阶段的过程中聚焦。GAtt 使得对话在多个回合内能够保持控制。
具体流程:
- 假设可以访问两个人之间的多轮对话数据集(例如,用户和助手之间的对话),其中包含一系列消息 [u1, a1, ..., un, an],其中 un 和 an 分别对应第 n 轮对话的用户和助手消息。然后,研究团队定义一个指令(inst),在整个对话过程中应该被遵守。例如,指令可以是"扮演"某个角色。然后,将这个指令合成地连接到对话中所有的用户消息上。
- 接下来,可以使用最新的RLHF模型从这个合成数据中进行采样。现在有了一个上下文对话和用于微调模型的样本,这个过程类似于拒绝抽样。然而,研究团队并不是在所有上下文对话回合中都加入指令,而是只在第一个回合中加入,这样会导致一个训练时的问题,即系统消息(即最后一轮之前的所有中间助手消息)与原来的样本不匹配。为了解决这个问题,以免影响训练,研究团队简单地将之前回合中的所有标记的损失设置为0,包括助手消息。
- 对于训练指令,研究团队创建了一些合成的限制供采样,例如兴趣爱好("您喜欢(),例如网球"),语言("说(),例如法语"),或者公众人物("扮演(),例如拿破仑")。为了获得兴趣爱好和公众人物的列表,研究团队让Llama 2-Chat来生成,避免了指令与模型知识不匹配的问题(例如,让模型扮演它在训练中没有遇到过的角色)。为了使指令更加复杂和多样化,研究团队通过随机组合上述限制来构造最终的指令。在构造用于训练数据的最终系统消息时,研究团队还会将一半的原始指令修改为更简洁的形式,例如"Always act as Napoleon from now"会变为"Figure: Napoleon"。这些步骤生成了一个 SFT 数据集,用于微调Llama 2-Chat。
GAtt 评测:为了说明 GAtt 如何帮助在微调期间重塑注意力,在下图中展示了模型的最大注意力激活(与没有GAtt的模型(左)相比,配备GAtt的模型(右)在更大的对话部分中保持了与系统消息相关的大量注意力):

七、实验结果
7.1 基于模型的评估结果
- 为了测评不同的SFT和RLHF版本在安全性和有用性两个方面的进展情况,进行了内部的安全性和有用性奖励模型进行度量。在这组评估中,在RLHF-V3版本之后在两个方面都优于ChatGPT(一种基线模型),即无害性(harmlessness)和有用性(helpfulness)均高于50%。
- 为了公平比较,额外使用GPT-4进行最终结果的计算,以评估哪个生成模型更受青睐。为避免任何偏见,ChatGPT和Llama 2-Chat输出在GPT-4提示中的顺序会被随机交换。如预期,Llama 2-Chat相对于ChatGPT的胜率变得不太显著,不过最新的Llama 2-Chat仍超过60%的胜率。
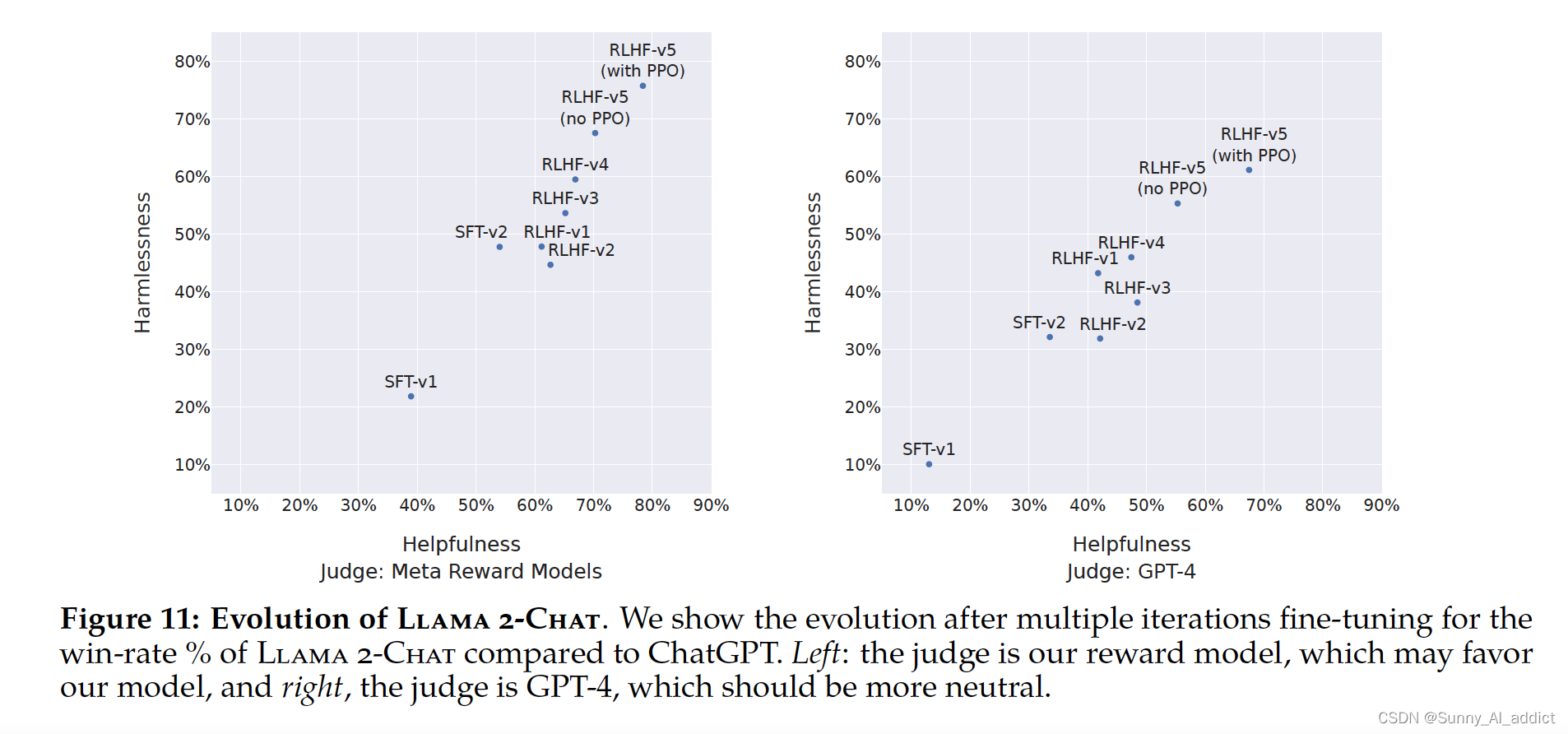
7.2 基于人工的评测结果
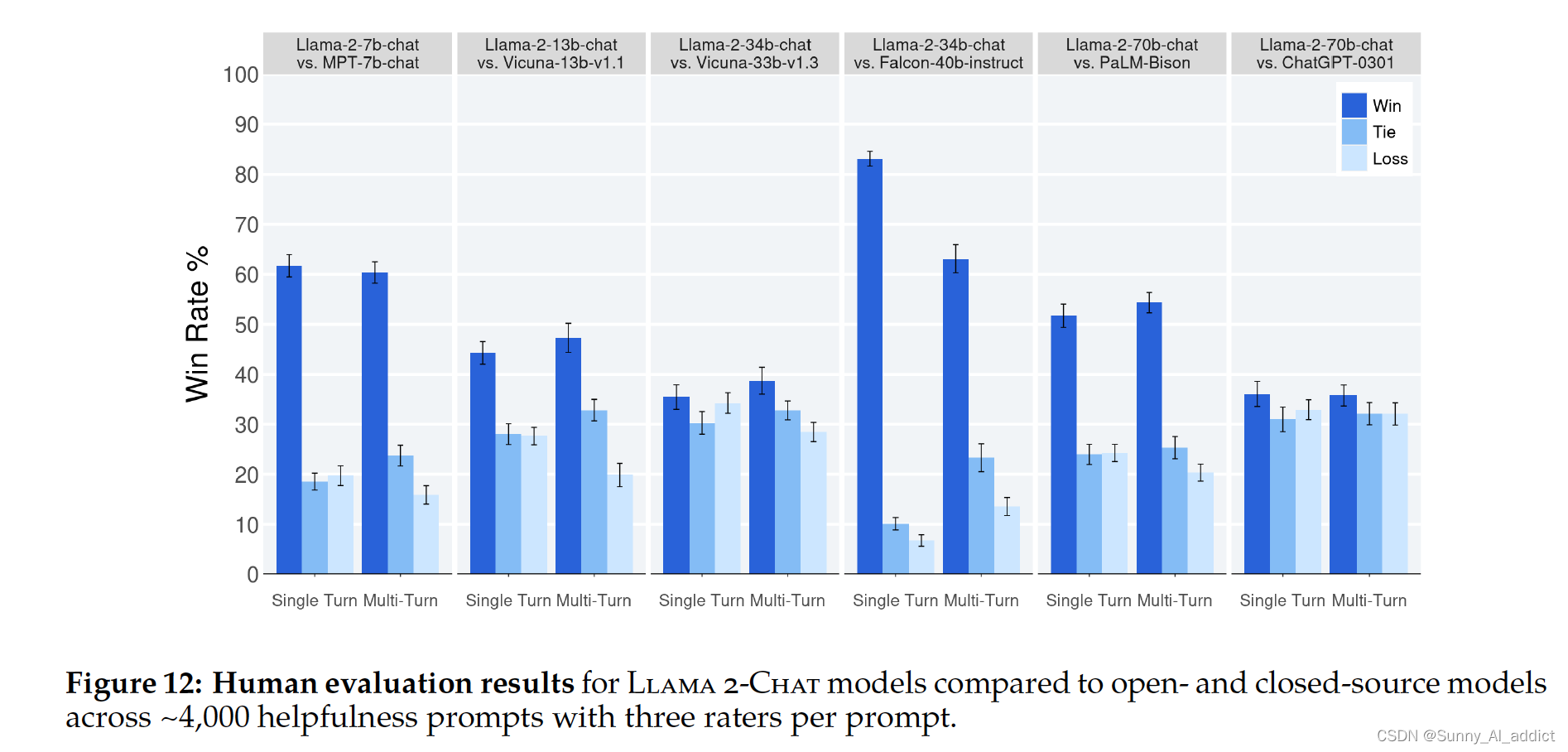
笔者NOTE:由于篇幅原因,本篇详细地介绍了RLHF的内容,简短地带过了Llama RLHF实现的结果。Llama原文中对大模型研发的每个环境都讲解地非常详细,对于其他内容(模型、数据的安全性,GQA的优势、训练数据的分析以及其他开放问题的探讨),有兴趣的小伙伴可以去看下原文,或者参考Llama2 详解:开源世界最优秀的大语言模型 - 知乎
我们下期见~
Copyright © 2003-2013 www.wpsshop.cn 版权所有,并保留所有权利。

