
- 1spark中使用flatmap报错:TypeError: ‘int‘ object is not subscriptable_int' object is not subscriptable
- 202、Java 数据结构:时间复杂度与空间复杂度
- 3读书笔记2区块链与大数据_区块链+大数据读书心得
- 4三大集合:List、Map、Set的区别与联系_listset和map的数据结构区别
- 5C++ 可变参数_c++可变参数
- 6Android项目集成高德地图定位功能_请检查配置文件是否配置服务,并且manifest中service标签是否配置在application
- 7遍历HashMap的五种方式_hashmap遍历
- 8小目标检测篇 | YOLOv8改进之增加小目标检测层(四头检测机制)_怎么把yolov8三头变成四头
- 9事件过滤器eventFliter_事件过滤器有什么用
- 10华为笔试0410第二题——字符串展开_给定一个字符串,字符串包含数字、大小写字母以及括号 (包括大括号、中括号和小括
Amazon Bedrock 多 IAM 用户的成本追踪和控制方案助力 AI Character 最佳实践
赞
踩

背景
Amazon Bedrock 是一项强大的服务,可以帮助客户基于先进的基础模型(FMs),轻松地构建和扩展基于生成式 AI 的应用程序。这些模型由领先的人工智能公司(如 AI21 Labs、Anthropic、Cohere、Meta、Stability AI 和亚马逊)提供,具有出色的性能表现。作为一项全面托管的服务,Amazon Bedrock 为客户提供了构建生成式 AI 应用程序所需的全套功能,从而简化了开发过程。同时,它也注重数据的隐私和安全性,确保客户的数据得到妥善保护。
挑战
企业用户在使用 Amazon Bedrock 构建生成式 AI 应用程序的时候,不仅关注应用程序本身是否能够解决业务痛点或者实现业务创新,同时还会关心业务流程是否存在风险、大语言模型应用是否得到有效的治理和性能成本是否可控等等。以下总结了构建生成式 AI 的应用程序的时候,经常碰到的监控和管理方面的痛点:
多账号管理:企业组织内通常有多个团队或者部门,使用不同的 IAM 账号来使用大语言模型(比如 Claude 3)。这个时候就需要运维或者治理团队来统一管控跨账号的可观测性。
成本控制:调用大语言模型通常需要消耗大量的计算资源,模型调用和 token 使用量直接影响成本支出。所以需要实时监控 token 的使用情况,控制成本在可接受范围内。
性能监控:需要实时监控模型的响应时间、吞吐量等性能指标,确保应用程序的高效运行,任何性能下降都可能影响最终用户体验。
内容审计:出于安全、隐私和合规性考虑,需要详细记录和审计所有模型请求及响应的内容,了解模型输入是否合规、输出是否存在风险。
警报和自动化:需要基于各种指标设置合理阈值,及时触发告警,并通过自动化流程快速应对,如自动扩缩容、IAM 账号暂停服务等。
通过集成云原生的 Amazon CloudWatch 监控服务,Amazon Bedrock 旨在帮助客户应对以上挑战,提供全面的监控、审计和成本控制能力,简化大语言模型应用的运维管理。CloudWatch 可以帮助客户跟踪应用程序的使用情况指标,并为审计目的构建自定义仪表盘(Dashboards)。通过监控这些指标,可以了解单个账户中单个基础模型或跨多个账户的所有基础模型的使用情况,包括模型调用次数和令牌计数等。此外,Amazon Bedrock 还为客户提供了模型调用日志记录功能。通过启用此功能,Amazon Bedrock 会收集账户中所有模型调用的元数据、请求和响应,方便客户进行审计和分析。不过,默认情况下此功能是关闭的,您需要手动启用它。
在本篇文章中,我们将深入探讨如何利用 Amazon CloudWatch 结合 Amazon Lambda 监控 Amazon Bedrock 的运行状况。CloudWatch 提供的指标和日志可用于触发警报,并在指标值超过预定义阈值时采取相应的操作,例如通过 Amazon Lambda 来触发预警,从而帮助您及时发现并处理潜在问题。本文设定了一个用户场景,就是企业级用户使用多个 IAM 用户来使用 Claude 3 on Amazon Bedrock,管理人员监控每个 IAM 用户的 InputToken 和 OutputToken 以及费用,当单个 IAM 用户的使用量超过阈值的时候发送邮件报警,同时也可以剥夺该 IAM 用户的 Bedrock 使用权限(Bedrock Permission),从而实现对单个 IAM 用户的精细成本管控,避免因为不当使用大语言模型而造成潜在的巨大成本损失。
除此之外,CloudWatch 还提供了诸多其他强大功能,例如跨账户可观测性、日志和指标关联、复合警报、日志分析和应用程序性能监控等,这些功能可以为您提供更全面的监控和故障排查能力。通过本文,我们希望能够帮助初学者更好地理解 Amazon Bedrock 和 CloudWatch 的集成方式,并学习如何利用它们来构建和监控生成式 AI 应用程序。
架构设计
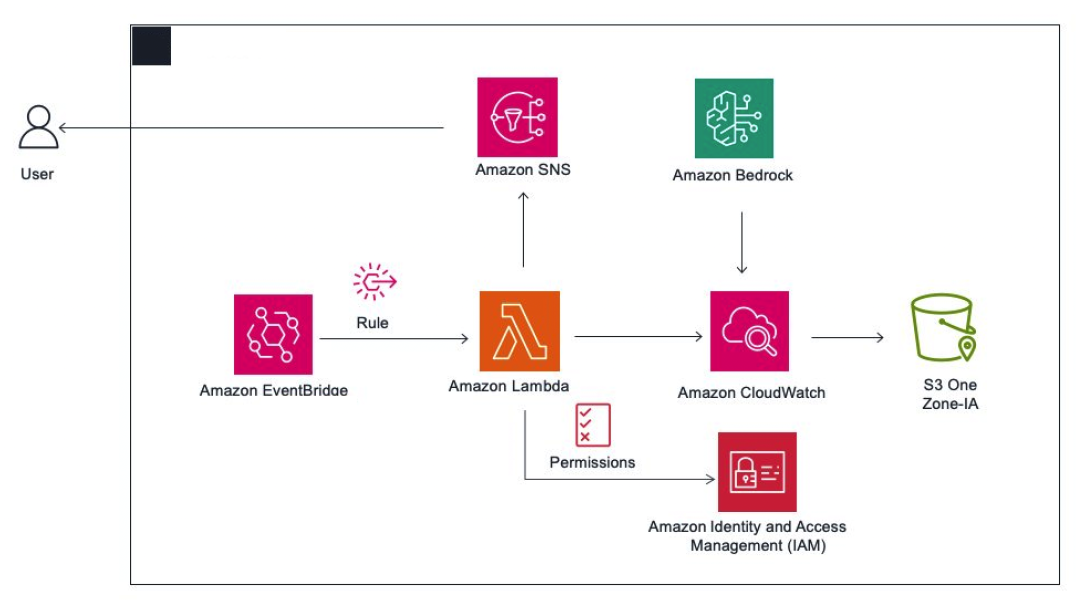
操作步骤
a)启用 Amazon Bedrock 的模型调用日志记录
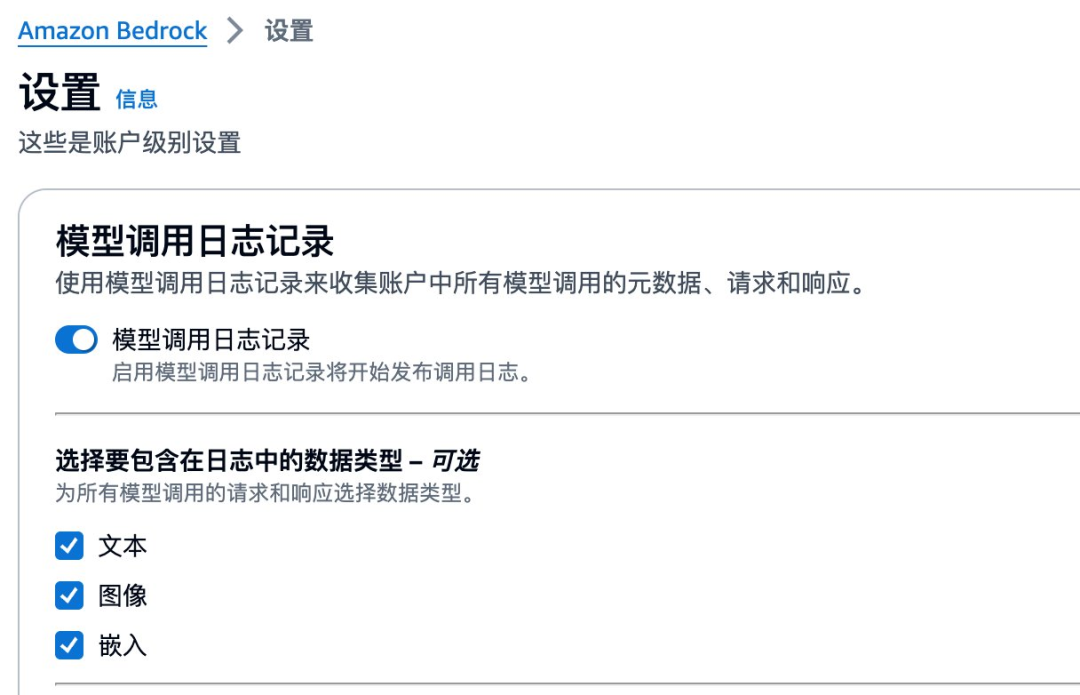
要配置日志记录,请在 Amazon Bedrock 控制台的左侧导航栏中导航到“设置”页面。然后切换“模型调用日志记录”按钮,系统会要求您填写几个字段后才能启用日志记录。
首先,选择要包含在日志中的数据类型。您可以选择文本、图像和嵌入。
接下来,选择您的日志记录目的地,您有三个选择。第一个选择是“仅 S3”,它将配置 Bedrock 只将日志发送到您选择的 S3 存储桶。第二个选择是“仅 CloudWatch 日志”,它将日志发送到 CloudWatch,当模型输入或输出数据大于 100kb 或为二进制格式时,可选择将其发送到 S3。最后一个选择是“S3 和 CloudWatch 日志”,日志将同时发送到 S3 和 CloudWatch,当模型输入或输出数据大于 100kb 或为二进制格式时,数据只会发送到 S3。无论您选择哪个选项,您都可以控制模型输入和输出,包括使用 KMS 进行加密和保留期限。在我的例子中,我选择了“仅 CloudWatch 日志”选项。在 CloudWatch 日志配置部分,指定日志组名称(在本例中,bedrock-log-test)。请注意,您需要先在 CloudWatch 中创建此日志组,具体操作可以参考这个链接:
https://docs.aws.amazon.com/zh_cn/AmazonCloudWatch/latest/logs/Working-with-log-groups-and-streams.html

然后,选择“创建并使用新角色”选项,并为您的角色提供一个名称。在本例中,我们选择了 Bedrock。
最后,前往 S3 并创建一个 S3 存储桶,为存储桶名称选择了此格式:bedrock-logging-[账户ID]-[区域]。现在回到 Bedrock 设置,在“用于大数据传输的 S3 存储桶”字段中选择您新创建的存储桶,然后单击“保存设置”以完成配置。请注意,[账户ID]和[区域]需要结合您的账号 ID 和使用区域进行替换。
s3://bedrock-logging-[AWSAccountID]-[region]b)通过 CloudWatch Insight 来实现数据洞察
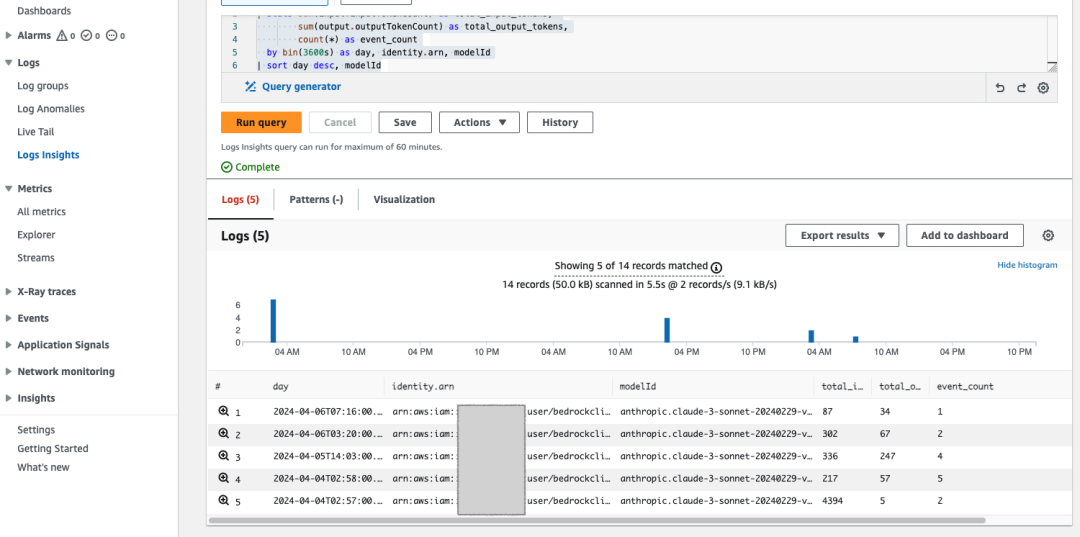
您可以在 CloudWatch Insight 中运行以下 query 获取对应的指标:
- fields input.inputTokenCount, output.outputTokenCount, @timestamp, errorCode, identity.arn, modelId, region
- | stats sum(input.inputTokenCount) as total_input_tokens,
- sum(output.outputTokenCount) as total_output_tokens,
- count(*) as event_count,
- count_distinct(errorCode) as distinct_error_codes
- by bin(3600s) as hour, identity.arn, modelId, region
- | sort day desc, modelId, region
在 CloudWatch Insight 页面可以看到如下内容,可以更加方便地根据不同的模型查看 Token 使用情况:
c) Lambda 函数做查询逻辑以及触发报警
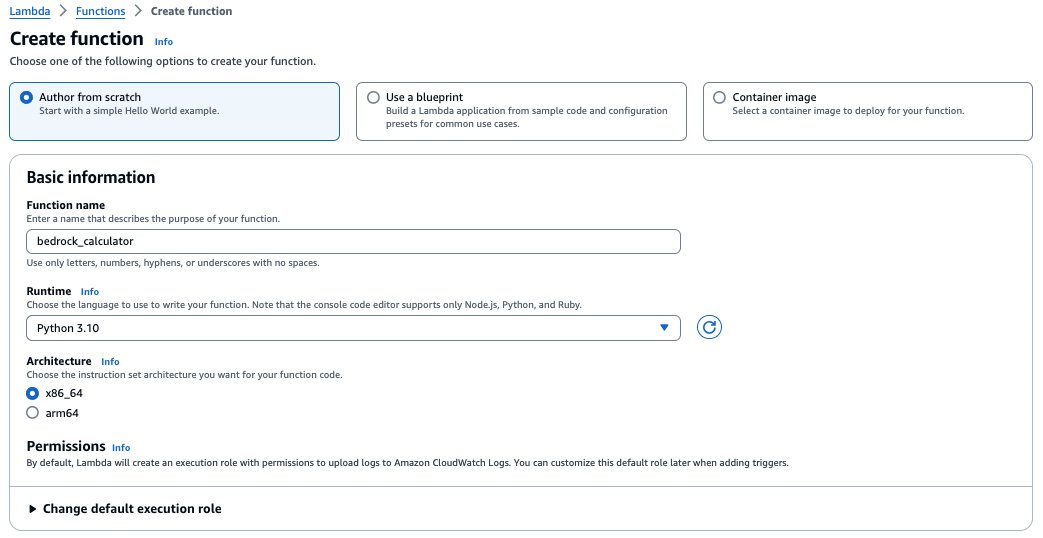
选择创建函数,并填入自定义的函数名称,选择运行时为 Python 3.10,其他配置保持默认。权限中会创建一个具有基本 Lambda 权限的新角色,后续您需要在这个角色中配置额外的权限使得该 Lambda 有访问 CloudWatch 的权限。点击创建函数,设置函数名称为 bedrock_calculator。
从 github 下载代码:
git clone https://github.com/tsaol/aws-bedrock-calculator这段代码是一个 Amazon Lambda 函数,用于计算使用 Bedrock FM 模型的费用。代码由三个文件组成:pricing.py、sns_utils.py 和 Lambda 函数文件。
pricing.py
存储不同区域和模型的定价信息。
包含一个名为 ANTHROPIC_PRICING 的字典,该字典按 Region 和 Model 组织价格信息。每个模型都有输入和输出 Token 的价格。
- "us-east-1": {
- "claude-instant-v1": {
- "input": 0.00080,
- "output": 0.00240,
- },
- "claude-v2": {
- "input": 0.00080,
- "output": 0.00240,
- },
- "claude-v3-haiku": {"input": 0.00025, "output": 0.00125},
- "claude-v3-sonnet": {"input": 0.00300, "output": 0.01500},
- },
sns_utils.py
提供了一个函数 send_cost_alert,用于在费用超出阈值时发送 SNS 告警消息。定义了 send_cost_alert 函数,该函数接受总费用、阈值和 SNS 主题的 ARN 作为参数。在函数内部,它检查总费用是否超过阈值,如果超过,则构建一条警告消息并使用 sns.publish 方法将其发布到指定的 SNS 主题。
- def send_cost_alert(total_cost, threshold, topic_arn):
- if total_cost > threshold:
- message = f"警告:Bedrock模型的总使用费用已达到 ${total_cost:.2f},超出了 ${threshold:.2f} 的阈值。"
- sns.publish(
- TopicArn=topic_arn,
- Subject='模型费用超出阈值',
- Message=message
- )
Lambda 主函数文件
您可以直接使用以下语句查询每一条记录:
- query = '''
- fields requestId, input.inputTokenCount, output.outputTokenCount, region, timestamp, identity.arn, modelId
- | sort timestamp desc
- '''
如果您的请求量较大,建议您更改为以下 query 语句以做聚合处理,本文示例为从 CloudWatch Logs 中聚合过去 1 小时内的模型使用数据。
- query = '''
- fields input.inputTokenCount, output.outputTokenCount, @timestamp, identity.arn, modelId
- | stats sum(input.inputTokenCount) as total_input_tokens,
- sum(output.outputTokenCount) as total_output_tokens,
- count(*) as event_count
- by bin(3600s) as day, identity.arn, modelId
- | sort day desc, modelId
- '''
您需要将 logGroupName 更改为步骤 a)中配置的日志组名称:
- response = logs_client.start_query(
- logGroupName='bedrock-log-test',
- startTime=start_time,
- endTime=end_time,
- queryString=query
- )
您可以根据自己的需求指定需要监控的计费窗口:
- start_time = int(time.time()) - 259200 # 查询最近72小时的数据作为计费窗口
- end_time = int(time.time())
计算每个用户在每个模型上的费用:
- for record in response['results']:
- model_id = record[1]['value'] # 访问 'modelId' 字段
- region = 'us-east-1' # 替换为实际区域
- total_input_tokens = float(record[3]['value']) # 访问 'total_input_tokens' 字段
- total_output_tokens = float(record[4]['value']) # 访问 'total_output_tokens' 字段
-
- input_token_price = get_token_price(model_id, 'input', region)
- output_token_price = get_token_price(model_id, 'output', region)
- print('---record---')
-
-
- if input_token_price is not None and output_token_price is not None:
- input_token_cost = (total_input_tokens / 1000 * input_token_price)
- output_token_cost = (total_output_tokens / 1000 * output_token_price)
- total_cost = round(input_token_cost + output_token_cost, 2)
-
- record.append({'field': 'inputTokenCost', 'value': str(input_token_cost)})
- record.append({'field': 'outputTokenCost', 'value': str(output_token_cost)})
- record.append({'field': 'totalCost', 'value': str(total_cost)})
- print(record)
-
-
- else:
- record.append({'field': 'inputTokenCost', 'value': 'None'})
- record.append({'field': 'outputTokenCost', 'value': 'None'})
- record.append({'field': 'totalCost', 'value': 'None'})
- print(record)

如果需要,您可以创建 SNS 主题,并调用 sns_utils.py 中的 send_cost_alert 函数发送费用超出阈值的警告。
- ##发送告警邮件
- COST_THRESHOLD=0.15 #设置费用阈值
- total_cost = 0.0
-
-
- for result in response['results']:
- for item in result:
- if item['field'] == 'totalCost':
- total_cost += float(item['value']) #获取当前费用
- break
-
- SNS_TOPIC_ARN='arn:aws:sns:[region]:[account]:[TopicName]' #配置SNS主题ARN
- print("Total Cost:", total_cost)
- send_cost_alert(total_cost, COST_THRESHOLD, SNS_TOPIC_ARN)
返回处理后的结果。
d)给 Lambda 添加触发器
在函数配置成功后,您可以通过点击添加触发器,配置 EventBridge 用于控制事件触发的频率。
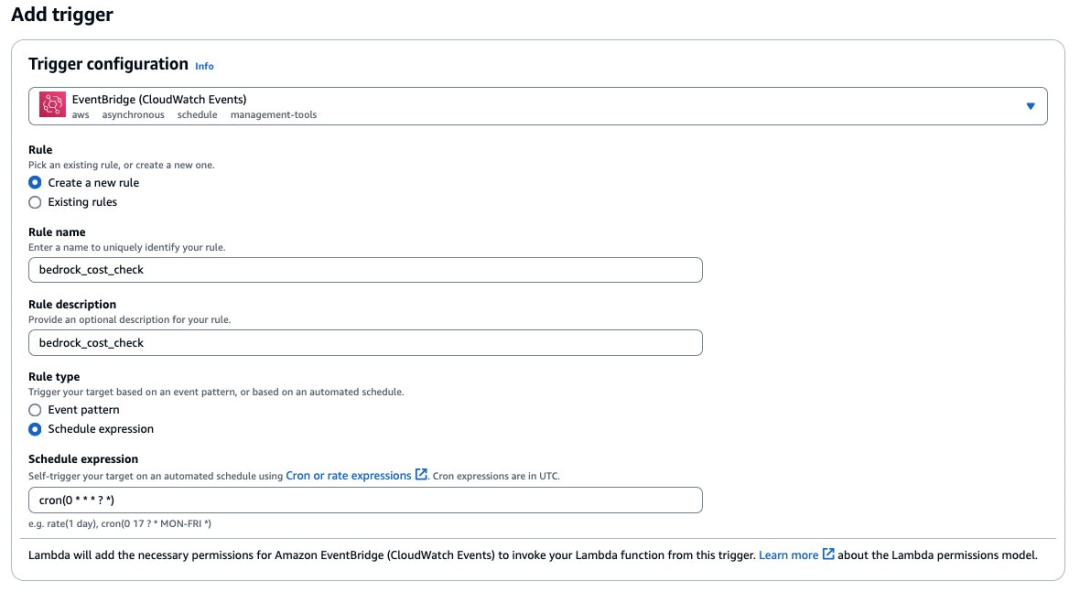
通过上图的配置您就可以添加 EventBridge 触发器,可以以小时维度或更细的维度触发 Lambda 函数。如果您去要在触发告警的同时控制权限限制,请按下面操作,如果不需要控制权限则不需要操作以下内容。
e)创建 Lambda 函数对 IAM 用户的权限进行限制
在项目中有 iam_utils.py 用于根据传入的 IAM 用户的 arn,并移除对应的权限,下面代码假定用户的 Bedrock 权限策略名为“BedrockAccess”。
- import json
- import boto3
-
-
- def remove_bedrock_policies(identity):
- iam = boto3.client('iam')
-
-
- if identity:
- try:
- user_name = identity.split("/")[1]
-
- response = iam.list_attached_user_policies(UserName=user_name)
- attached_policies = response.get('AttachedPolicies', [])
-
-
- for policy in attached_policies:
- policy_name = policy['PolicyName']
- if "BedrockAccess" in policy_name.lower():
- try:
- iam.detach_user_policy(UserName=user_name, PolicyArn=policy['PolicyArn'])
- print(f"Removed policy '{policy_name}' from user '{identity}'")
- except Exception as e:
- print(f"Error removing policy '{policy_name}': {e}")
- except Exception as e:
- print(f"Error listing attached user policies for '{identity}': {e}")
如果需要根据 token 数量或者金额判断是否需要控制权限需要将以下代码添加到 lambda_function.py 中:
- token_threshold = 1000000 # 设置 token 数量阈值
- price_threshold = 100 # 设置价格阈值
- total_tokens = total_input_tokens + total_output_tokens
-
-
- if total_cost > price_threshold or total_tokens > token_threshold:
- remove_bedrock_policies(identity)
如果需要对 IAM 策略进行移除,在 Lambda 配置中需要给 lambda_function 添加权限,选择 IAMFullAccess。如果您希望更细粒度的控制该 Lambda 函数对于 IAM 的权限,您可以创建自定义的权限并绑定在该角色中。在本例中,简单允许该 Lambda 所有的 IAM 操作。
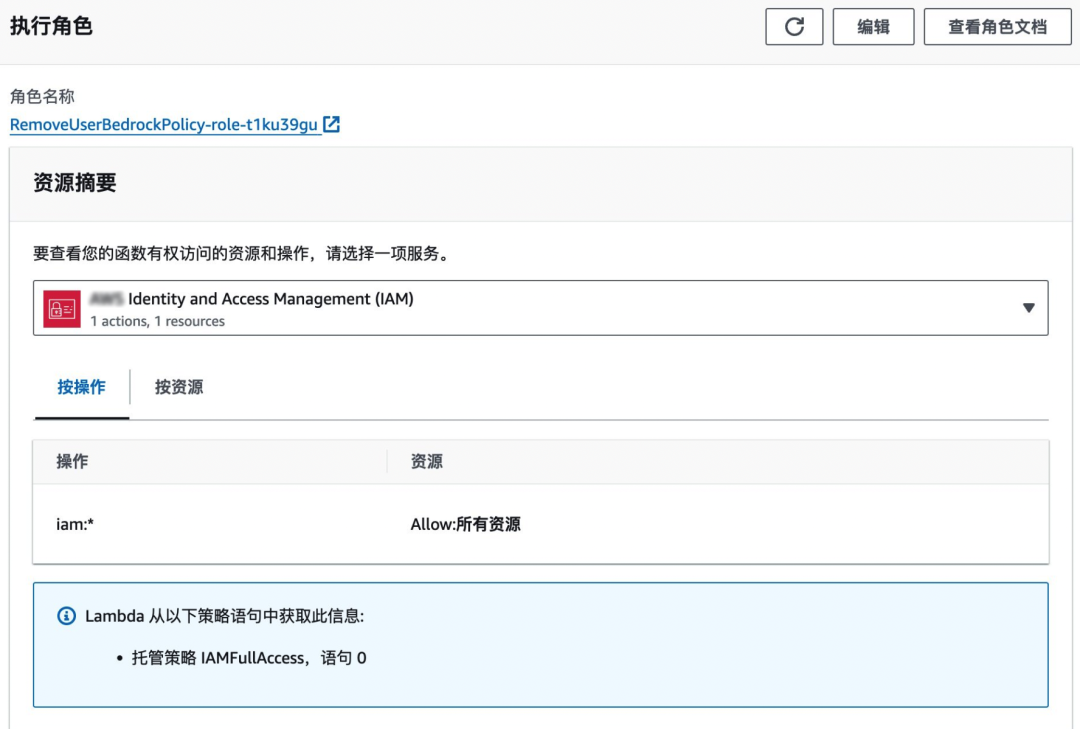
至此,您已经成功用一个函数来删除超出 Token/费用使用限制数量的 IAM 用户 Bedrock 权限了。
结论
在这篇文章中,我们展示了如何使用 Amazon CloudWatch 监控 Amazon Bedrock 并深入了解基础模型和生成式 AI 应用程序的 InputToken 和 OutputToken 的情况,并针对 IAM 用户和不同的模型进行用户级别的精细监控。Amazon Bedrock 是一项完全托管的服务,可以使用领先 AI 提供商的基础模型轻松开发和扩展生成式 AI 应用程序。它与 Amazon CloudWatch 和 Amazon Lambda 集成,通过指标和日志提供近乎实时的监控、审计和使用情况分析功能。Amazon Bedrock 简化了大规模生成式 AI 应用程序的构建,同时通过与 Amazon CloudWatch 的集成提供透明度和控制力。
参考链接
https://aws.amazon.com/cn/blogs/mt/monitoring-generative-ai-applications-using-amazon-bedrock-and-amazon-cloudwatch-integration/
https://docs.aws.amazon.com/zh_cn/AmazonCloudWatch/latest/logs/Working-with-log-groups-and-streams.html
https://docs.aws.amazon.com/zh_cn/AmazonCloudWatch/latest/monitoring/Create-alarm-on-metric-math-expression.html
本篇作者

朱文军
亚马逊云科技解决方案架构师。负责基于亚马逊云科技的云计算方案架构的设计和技术咨询,同时致力于亚马逊云科技在各行业中的应用与推广,在 IoT 领域有丰富经验。目前致力于生成式 AI 加速企业效率与创新,提供企业落地生成式 AI 或者关键业务需求实现的解决方案,并在落地过程中提供技术方案指导。

曹镏
亚马逊云科技解决方案架构师,专注于为企业级客户提供信息化以及生成式 AI 方案的咨询与设计,在 AI/ML 领域具有解决实际问题能力以及落地大模型训练项目的经验。

刘振华
亚马逊云科技高级解决方案架构师。在加入亚马逊云科技之前,曾在埃森哲和华为等知名企业担任核心技术岗位,主导过多个大型软件系统的设计、开发和项目管理,拥有丰富的实战经验。凭借对 SaaS 领域的深入理解和实践经验,向客户提供高质量的技术咨询和赋能服务。近期开始专注于研究生成式 AI 技术如何助力中国企业客户实现创新发展,为企业量身定制 AI 解决方案,提升其核心竞争力。

听说,点完下面4个按钮
就不会碰到bug了!


