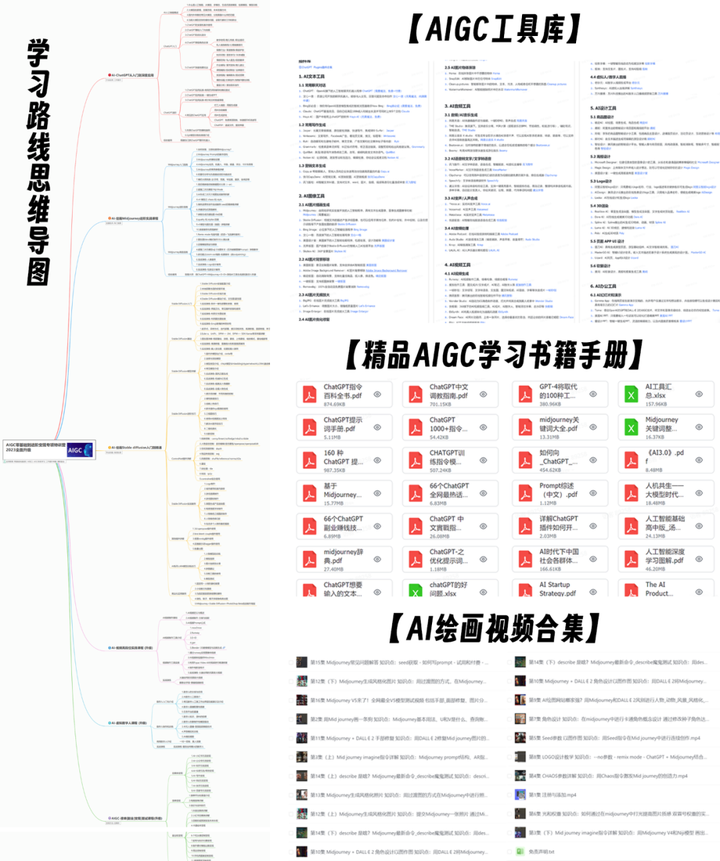
- 1国内目前免费的地图API介绍_免费地图api
- 2软件测试——黑盒测试基本方法_某软件的一个模块的需求规格说明书中描述: (1)年薪制员工:严重过失,扣年终风险金
- 3前沿科技应用:AIGC技术的广泛渗透_aigc在科研领域的应用
- 4MySql中执行计划如何来的——Optimizer Trace_mysql optimizer
- 5基于springboot的采购管理系统的设计与实现
- 6【Mac】Dynamic Wallpaper(Mac动态壁纸桌面) v18.1中文版安装教程
- 7Spark-SQL小结
- 8Pytorch-08 实战:手写数字识别
- 9记录某三年经验前端岗面试题(20-30K)_面试者一半会问三年的前端什么面试题
- 10[mmcv系列] pip安装mmcv记录_pip install mmcv
stable diffusion最全插件大全,新手必备指南_stable diffusion有哪些实用插件
赞
踩
Stable diffusion30个必备插件推荐,给我点个赞吧,兄弟们
1,ComfyUI,SD扩展里面直接搜索就行,
ComfyUI 是一个基于节点操作的UI界面,玩过建模的更容易学

安装后大概是这样的
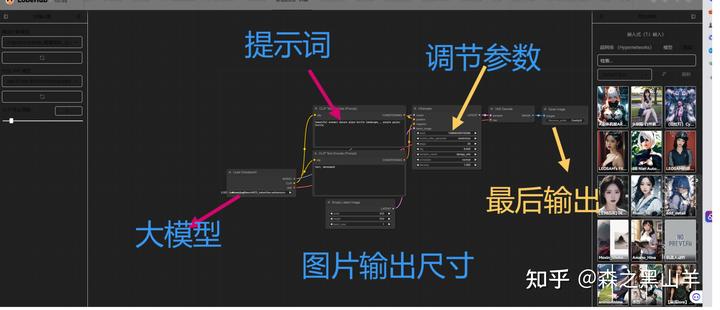
大概是这么个流程
评价:comfyui,更适合显卡配置低的,8G,6G显存具体可以自己尝试一下。内部生成流程做了优化,生成图片时的速度相较于webui又10%~25%的提升(根据不同显卡提升幅度不同),8G显存下直接生成2k图片是没什么问题的。当然图片越大,显卡越吃力。有钱的话,有专业需求的话,还是买个4090一步到位吧。
相比较与SD的话,comfyui可控性很强。
comfyui支持以节点化的方式自由串联各种编解码器实现更自由的生成控制,相比之下,我们常用的WebUI其实就是一个完全固定下来的比较具有普遍性的流程。虽然这需要很多额外的学习成本(了解各种节点的作用和组合逻辑),comfyui,更加适合,图像摄影,游戏、美术,行业。
最好的方面是comfyui保存图像时,自动内嵌该图的所有工作流设置。那就意味着只要你下载足够多的参考图,模仿学习别人的工作流,会学的很快,简单易上手。有点像LR,和br
缺点,全英文界面,复杂的节点化流程,劝退非专业人士
2, roop换脸不太行,我就没发出来,专业的不适合普及,所以不发了
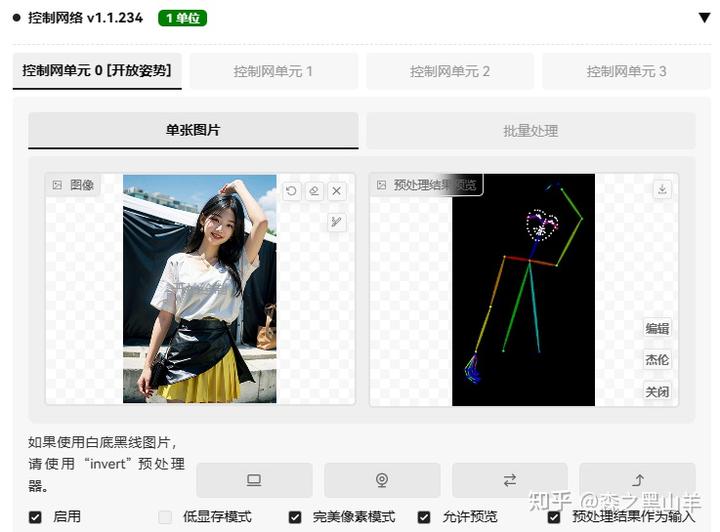
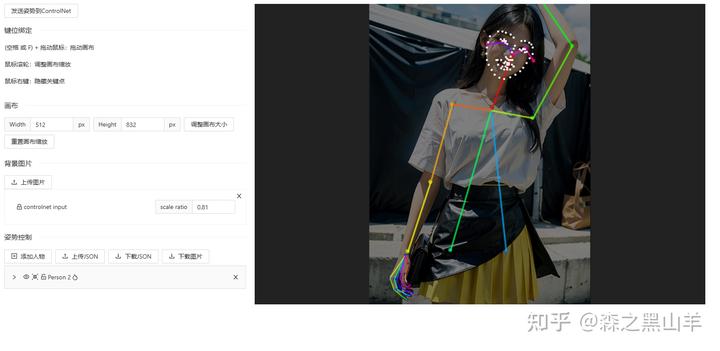
3,sd-webui-openpose-editor-main,可以对control里面进行编辑
4,大模型/Lora触发词插件lora-prompt-tool(Lora提示词助手)https://github.com/a2569875/lora-prompt-tool,可以直接安装。接下来,有触发词点一下就可以看到它的触发词了,没有的话,可以编辑一下。可以结合c站助手和喵手助理(这两个差不多),这个去复制对应的参数,和触发词当然不要指望用这个下东西,还是得去c站或者其他网站下载,再用idm跑满,下得飞快。

妙寿助理

c站
5,UI界面美化(建议12g显存以上)(kitchen)厨房主题,相比较与传统SD界面这个更美观,更直观,模型缩略图可以放大看。
可以选择主题,能上c站和github
6,完美手部修复插件Depth Library内含900个手部深度图,将文件复制到这个路径文件夹下“……\sd-webui-aki-v4\extensions”,直接覆盖。

7,提示词标签选择器Easy Prompt Selector网址安装”,然后输入以下地址,可以结合one button prompt 。 https://github.com/blue-pen5805/sdweb-easy-prompt-selector,可以直接安装。在写提示词的时候,我们遇到最多的情况可能就是脑子里面想不出来场景,可以逛逛“标签超市”——Danbooru 标签超市 (novelai.dev)。
8,抽卡神器,时间管理大师Agent Scheduler
适用于批量化操作,跑图,测试多CN融合
安装方式就是在扩展面板中搜索“Agent Scheduler”,或者是点击“从网址安装”,然后输入以下地址https://github.com/ArtVentureX/sd-webui-agent-scheduler,可以直接安装。如果显存不足,只会停止这个任务,然后继续下一个
可以搞几十张,
9,(必备)cutoff,一个及其好用的插件,用于强化提示词生成的图片,
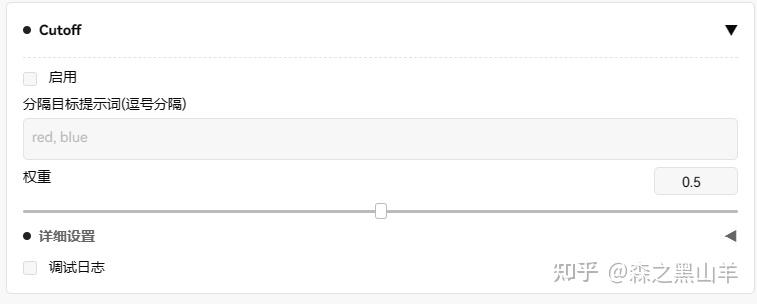
给的提示词是这个1 girl, blue eyes, white shirt, black dress,

相对而言,不那么随机
10,Photopea
安装方式就是在扩展面板中点击“从网址安装”,然后输入以下地址https://github.com/yankooliveira/sd-webui-photopea-embed.git,可以直接安装,直接装了个ps,magic replace”。这个功能就是“创成式填充”,没错,就是那个大名鼎鼎的“创成式填充”,我们在SD里面也能用啦。还可以结合SD涂鸦功能,做一些概念图

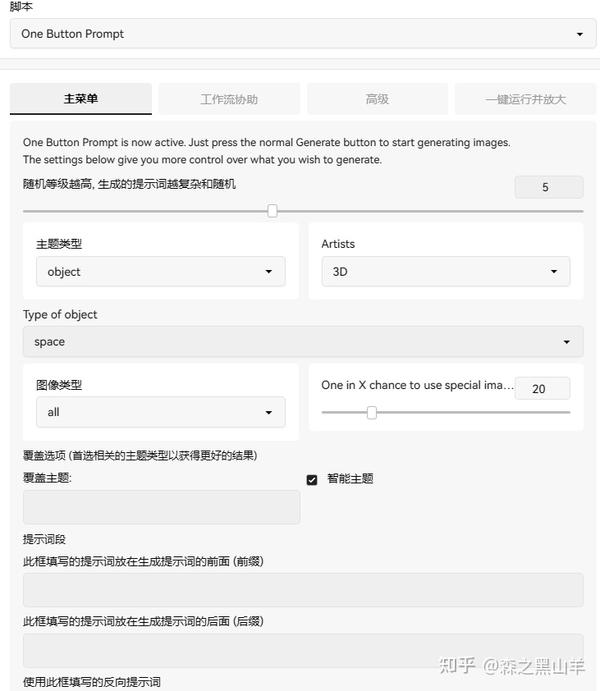
11,(必备)自动写提示词脚本One Button Prompt,没有想法可以用这个看看,可以给一些提示词参考
12,(必备)超清无损放大器StableSR,这个有点麻烦,我就没下,我一般用这两个,4x-UltraSharp,8x_NMKD-Superscale_150000_G
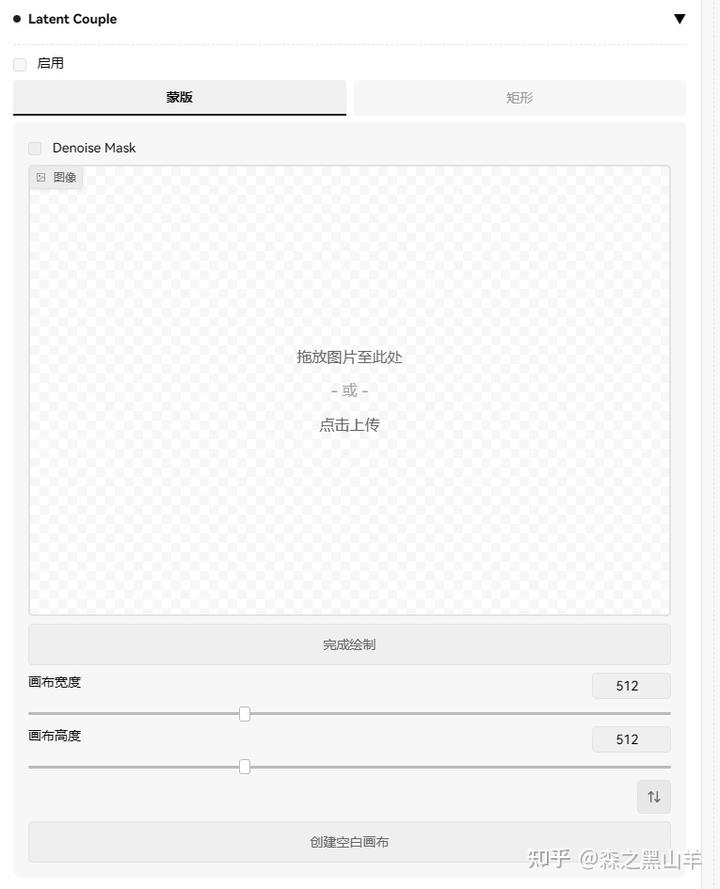
13,手涂蒙版定位插件Latent Couple,类似于SD涂鸦功能,可以控制一定的构图比例
14,(必备)脸部修复插件After Detailer,一个修复脸崩的插件,能在512X512像素做到很好的修复脸部,注意SD出图,一开始最好是先出小图,512X512像素的就可以,后面可以结合插件等一些手段放大。因为大模型训练的图都是这种小图,不像SDxl1.0它那个是1024的。

15,(必备)Aspect Ratio。可以锁定宽高比插件
安装方式就是在扩展面板中搜索Aspect Ratio,可以直接安装。或者是将下载好的插件,放在这个路径文件夹下“……\sd-webui-aki-v4\extensions”。

16,(必备)提示词服从度增强插件,dynamic-thresholding启用动态阈值 (CFG Scale 修复)也就是提示词引导系数,它关系到出图与我们文字的相关程度。太大也不好,图片会崩,所以这个要自己多尝试,和cutoff, dynamic prompt,这三个插件差不多
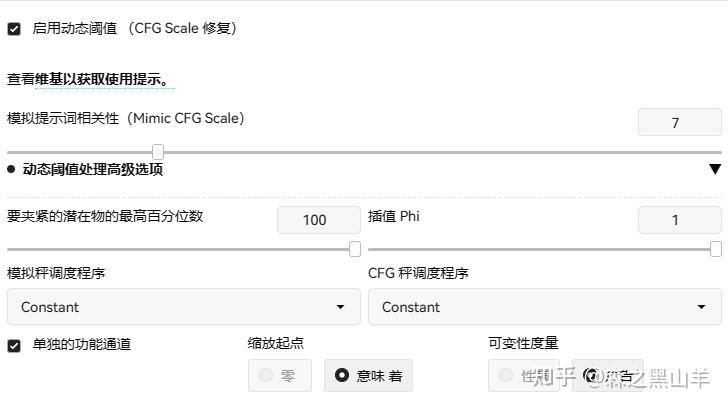
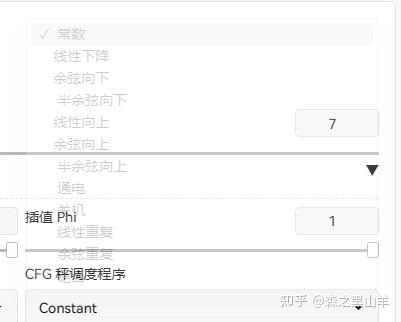
参数
17,dynamic prompt(动态提示词)为随机或组合式提示词的生成实现了一种表达性模板语言,并支持深层目录结构中的通配符
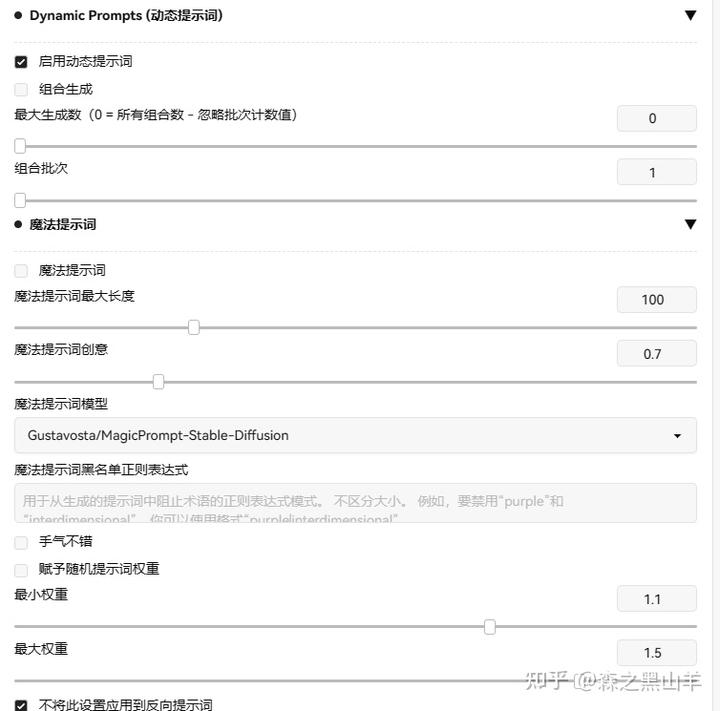
这个有点复杂
18,Deforum 动画插件,的官方移植,一个用于 2D 和 3D 动画的扩展脚本,支持关键帧序列、动态数学参数(甚至可用于提示词内)、动态蒙版、深度预测和变形
19,(必备)prompt-all-in-one。安装方式就是在扩展面板中搜索prompt-all-in-one,可以直接安装。或者是将下载好的插件,放在这个路径文件夹下“……\sd-webui-aki-v4\extensions”。可以研究一下怎么用,多去网上搜索看看
安装完成后,重启webUI,就可以看到提示词区域变成了这个样子。
20, sad tallker,生成带有面部图像和语音音频的说话头视频,还是比较假这个东西,想玩的可以去看看,但是和抖音小和尚效果差别不是很大
21,TemporalKit
后期处理,动画, 通过自动 1111 扩展将时间稳定性添加到稳定扩散渲染的多合一解决方案temporalkit+ebsynth+controlnet 可以达到流畅动画效果
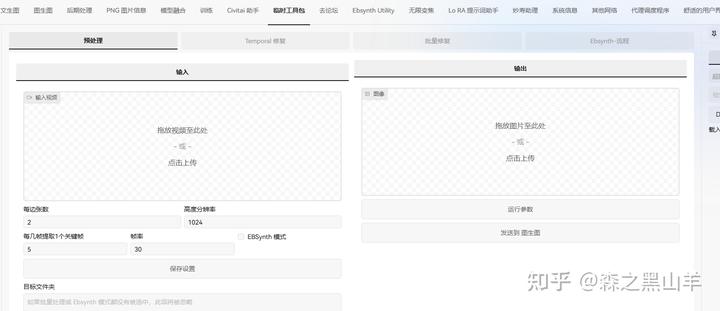
22,(必备)
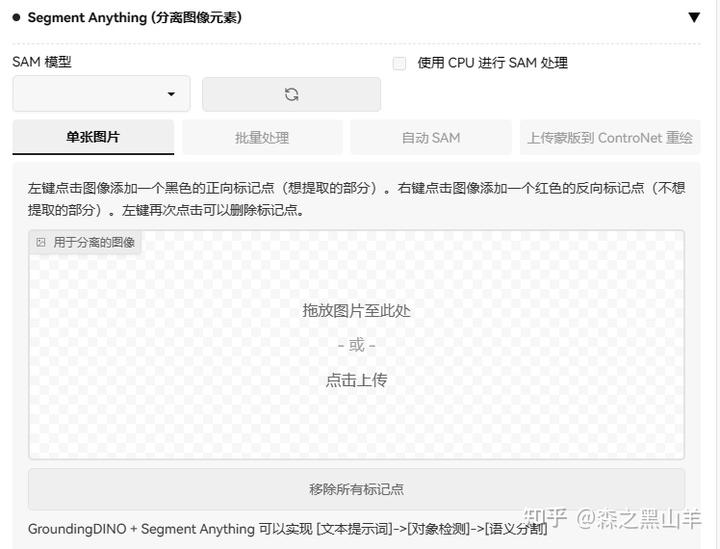
sd-webui-segment-anythinggithub.com/continue-revolution/sd-webui-segment-anything.git
分割任何内容以获得稳定的扩散 WebUI。通过单击或文本提示自动生成图像的高质量分割/遮罩。旨在将WebUI和ControlNet与Segment Anything和GroundingDINO连接起来,以增强稳定扩散/ ControlNet修复(单个图像和批处理),增强ControlNet语义分割,自动化图像垫并创建LoRA / LyCORIS训练集。
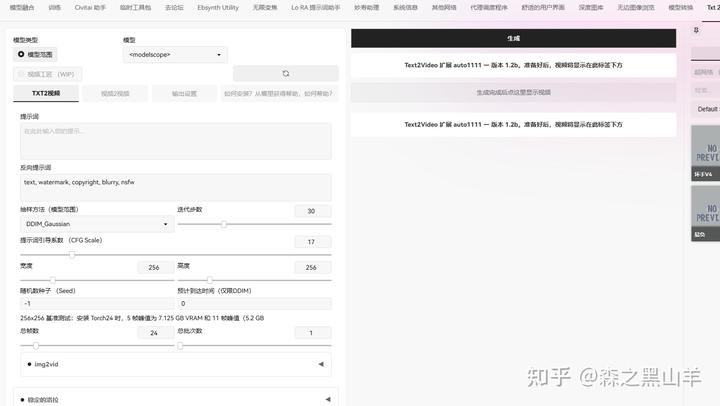
23,text2video
选项卡,动画,将一系列真正的text2video模型(如ModelScope和Videocrafter)引入WebUI。
24,(必备)
TiledDiffusion with Tiled VAEgithub.com/pkuliyi2015/multidiffusion-upscaler-for-automatic1111.git
无缝的大图像区域生成和升级,以及 vram 高效的平铺 vae 脚本
控制

25,显存预估,这个相对来说比较直观,可以看到自己生成图,所占的显存
选项卡,以递增的维度和批大小运行 txt2img、img2img、高分辨率修复,直到 OOM,并将数据输出到图形。
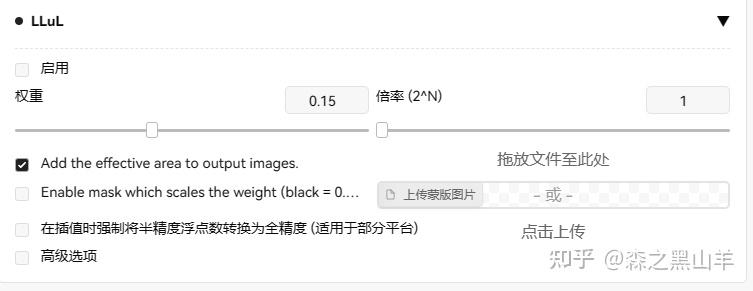
26(必备),LLuL,本地潜在升频器。通过蒙版的方式,定位区域以有选择地增强细节。
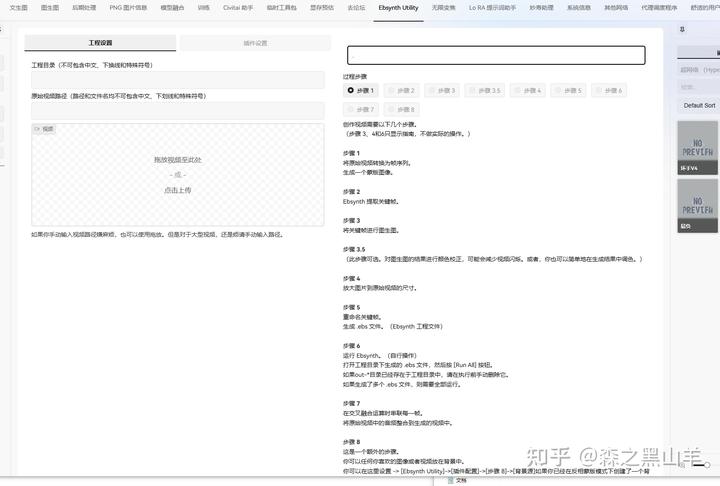
选项卡,动画,使用img2img和ebsynth创建视频的扩展。使用 ebsynth 输出编辑后的视频。与 ControlNet 扩展配合使用。
28,LoRA Block Weight (LoRA 区块权重配置),应用LoRA强度;一个块一个块在飞行中。包括预设、权重分析、随机化、XY 图
模型相关,涉及到lora分层训练

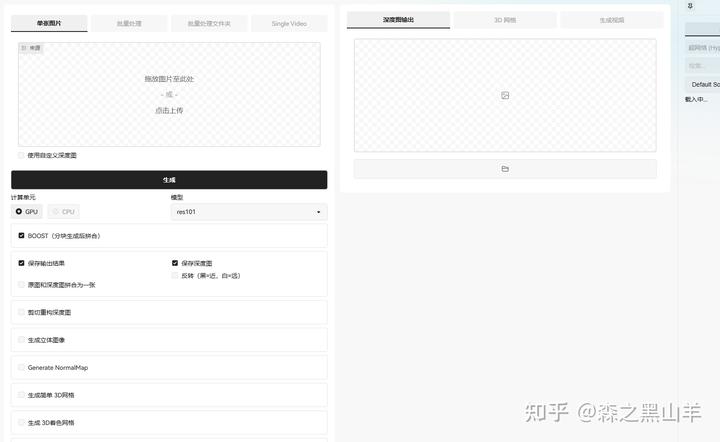
29,深度图后期编辑,深度图,立体图像,3D网格和视频生成器扩展
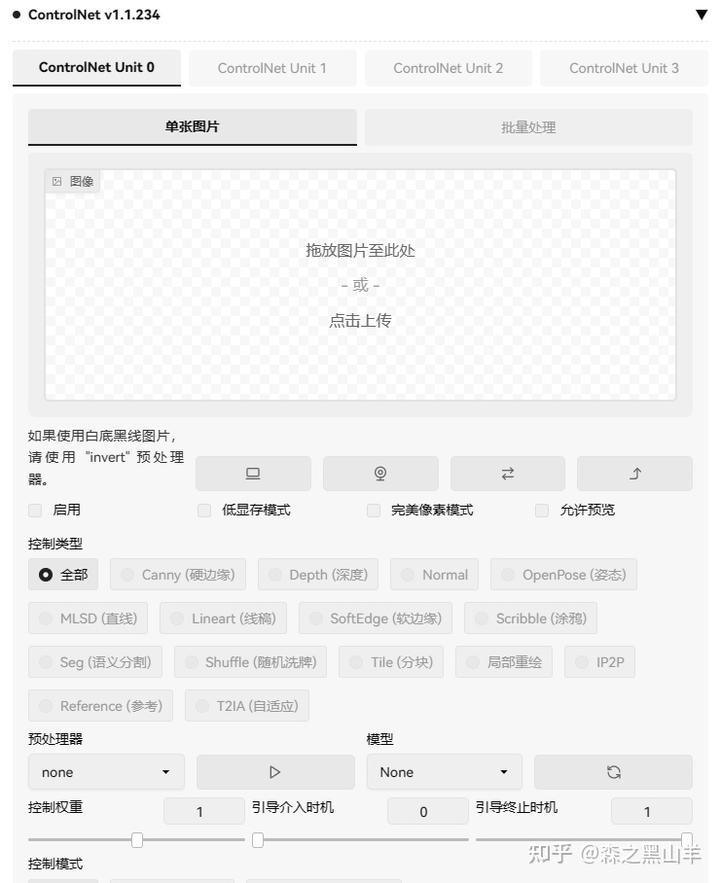
30,(必备)controlnet,这个后面出个教程,梳理一下这个是什么玩意,学过ps学这个一点都不难,只要涉及到图像领域就一定离不开蒙版,简单的雅痞
注意有的插件中文直接搜索不到,要翻译成英文,我把所有扩展基本上都看了一遍,采取星级较高的插件,和一些个人认为比较好用的插件,欢迎补充,觉得不错,点个赞吧,写这个好麻烦。详细的操作教程可以自己去找,我这里就不阐述了,已经写的够多了,再写下去没人看。
写这个的目的是,我之前也是小白,发现这个插件装不完,一天一个插件,学的真麻烦,所以就总结一下,新手先把这30个插件装完,把插件学会了,就已经是中级玩家了,再去搞lora和大模型,你就是SD高级玩家。多做出几个大模型和lora你就是大神了。如果自己有单反拍摄素材那就更好了
目前 ControlNet 已经更新到 1.1 版本,相较于 1.0 版本,ControlNet1.1 新增了更多的预处理器和模型,每种模型对应不同的采集方式,再对应不同的应用场景,每种应用场景又有不同的变现空间
我花了一周时间彻底把ControlNet1.1的14种模型研究了一遍,跑了一次全流程,终于将它完整下载好整理成网盘资源。
其总共11 个生产就绪模型、2 个实验模型和 1 个未完成模型,现在就分享给大家,点击下方卡片免费领取。
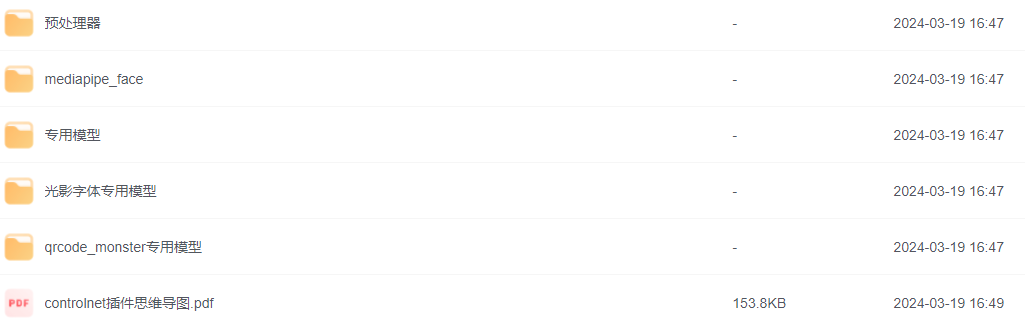
1. 线稿上色
方法:通过 ControlNet 边缘检测模型或线稿模型提取线稿(可提取参考图片线稿,或者手绘线稿),再根据提示词和风格模型对图像进行着色和风格化。
应用模型:Canny、SoftEdge、Lineart。
Canny 示例:(保留结构,再进行着色和风格化)
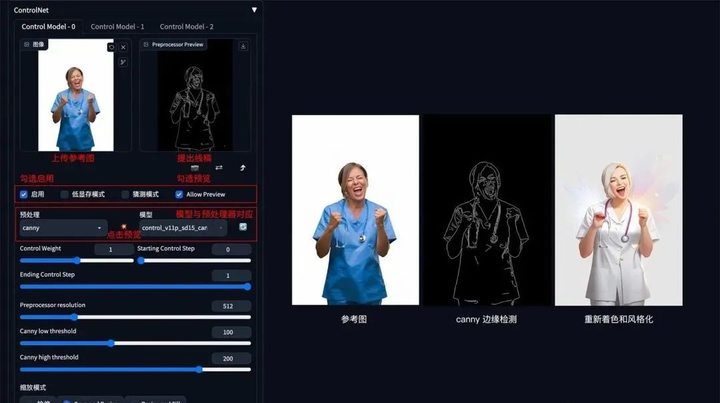
2. 涂鸦成图
方法:通过 ControlNet 的 Scribble 模型提取涂鸦图(可提取参考图涂鸦,或者手绘涂鸦图),再根据提示词和风格模型对图像进行着色和风格化。
应用模型:Scribble。
Scribble 比 Canny、SoftEdge 和 Lineart 的自由发挥度要更高,也可以用于对手绘稿进行着色和风格处理。Scribble 的预处理器有三种模式:Scribble_hed,Scribble_pidinet,Scribble_Xdog,对比如下,可以看到 Scribble_Xdog 的处理细节更为丰富:

Scribble 参考图提取示例(保留大致结构,再进行着色和风格化):
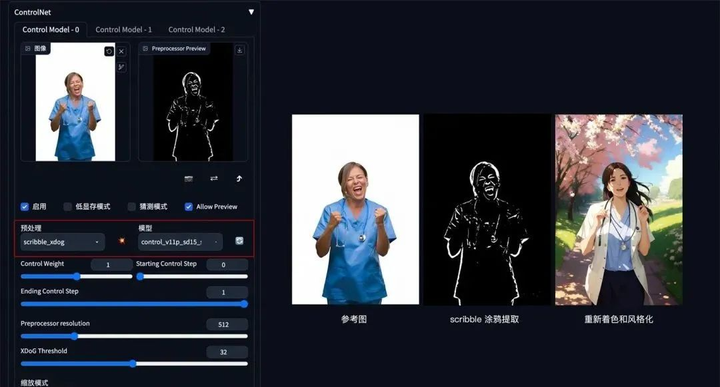
3. 建筑/室内设计
方法:通过 ControlNet 的 MLSD 模型提取建筑的线条结构和几何形状,构建出建筑线框(可提取参考图线条,或者手绘线条),再配合提示词和建筑/室内设计风格模型来生成图像。
应用模型:MLSD。
MLSD 示例:(毛坯变精装)
这份完整版的ControlNet 1.1模型我已经打包好,需要的点击下方插件,即可前往免费领取!
4. 颜色控制画面
方法:通过 ControlNet 的 Segmentation 语义分割模型,标注画面中的不同区块颜色和结构(不同颜色代表不同类型对象),从而控制画面的构图和内容。
应用模型:Seg。
Seg 示例:(提取参考图内容和结构,再进行着色和风格化)
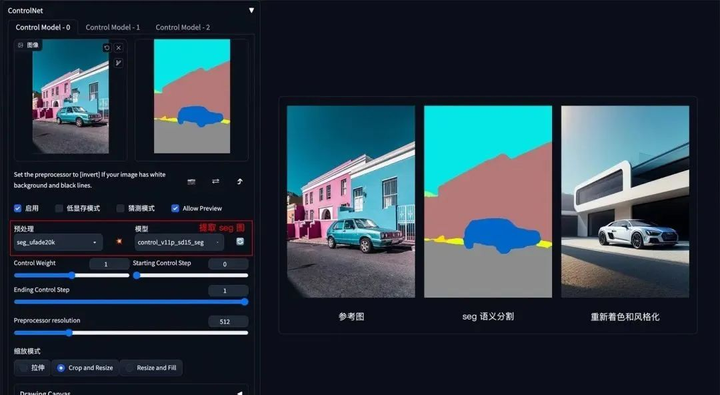
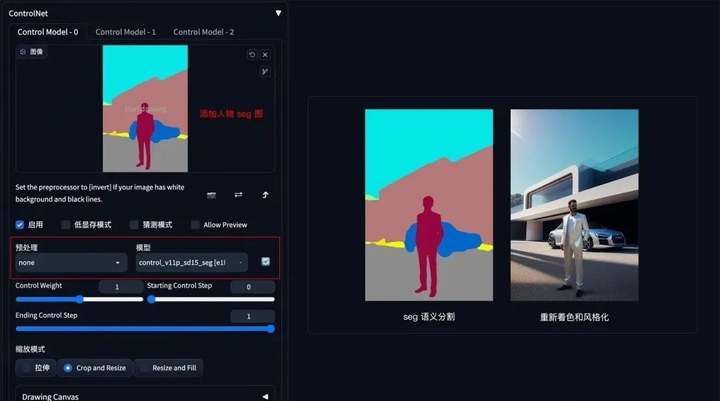
如果还想在车前面加一个人,只需在 Seg 预处理图上对应人物色值,添加人物色块再生成图像即可。
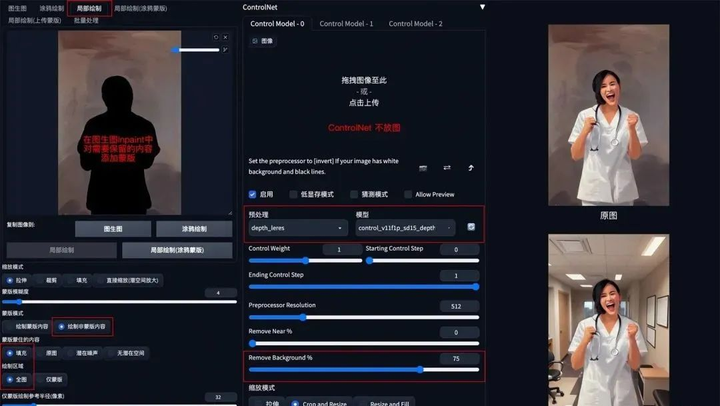
5. 背景替换
方法:在 img2img 图生图模式中,通过 ControlNet 的 Depth_leres 模型中的 remove background 功能移除背景,再通过提示词更换想要的背景。
应用模型:Depth,预处理器 Depth_leres。
要点:如果想要比较完美的替换背景,可以在图生图的 Inpaint 模式中,对需要保留的图片内容添加蒙版,remove background 值可以设置在 70-80%。
Depth_leres 示例:(将原图背景替换为办公室背景)
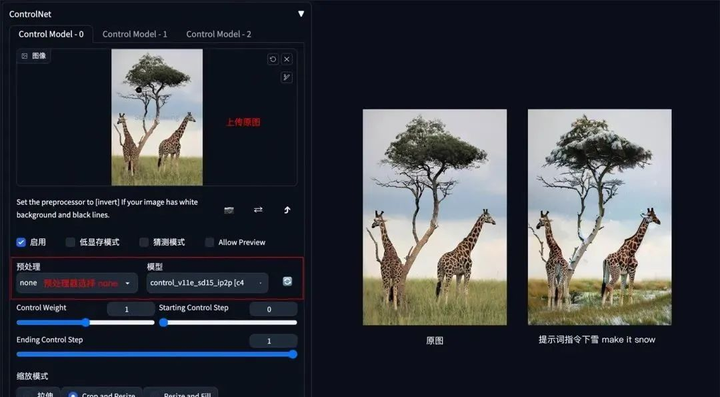
6. 图片指令
方法:通过 ControlNet 的 Pix2Pix 模型(ip2p),可以对图片进行指令式变换。
应用模型:ip2p,预处理器选择 none。
要点:采用指令式提示词(make Y into X),如下图示例中的 make it snow,让非洲草原下雪。
Pix2Pix 示例:(让非洲草原下雪)
7. 风格迁移
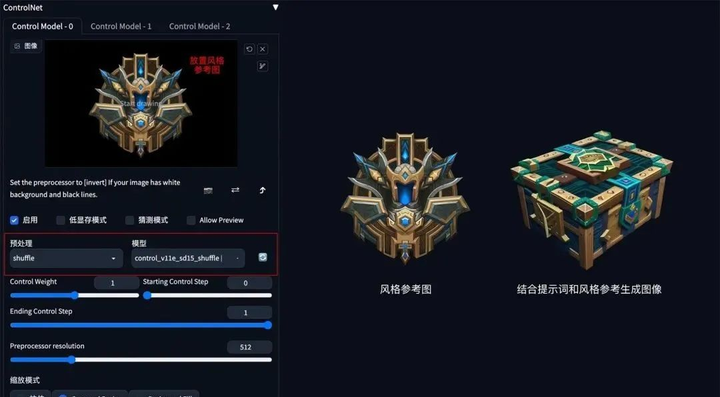
方法:通过 ControlNet 的 Shuffle 模型提取出参考图的风格,再配合提示词将风格迁移到生成图上。
应用模型:Shuffle。
Shuffle 示例:(根据魔兽道具风格,重新生成一个宝箱道具)
8. 色彩继承
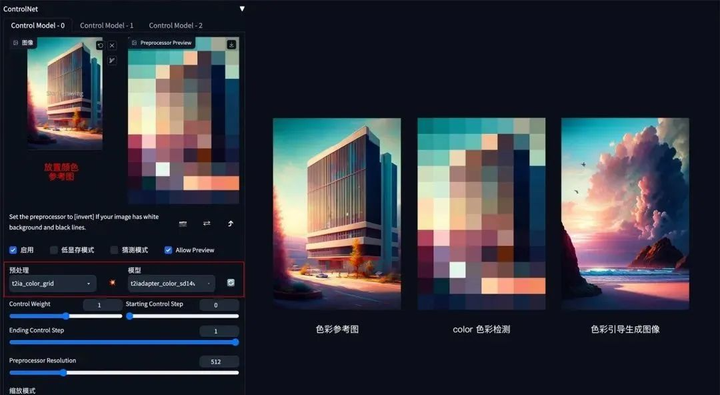
方法:通过 ControlNet 的 t2iaColor 模型提取出参考图的色彩分布情况,再配合提示词和风格模型将色彩应用到生成图上。
应用模型:Color。
Color 示例:(把参考图色彩分布应用到生成图上)
这份完整版的ControlNet 1.1模型我已经打包好,需要的点击下方插件,即可前往免费领取!
这里就简单说几种应用:
1. 人物和背景分别控制
2. 三维重建
3. 更精准的图片风格化
4. 更精准的图片局部重绘
以上就是本教程的全部内容了,重点介绍了controlnet模型功能实用,当然还有一些小众的模型在本次教程中没有出现,目前controlnet模型确实还挺多的,所以重点放在了官方发布的几个模型上。
同时大家可能都想学习AI绘画技术,也想通过这项技能真正赚到钱,但是不知道该如何开始学习,因为网上的资料太多太杂乱了,如果不能系统的学习就相当于是白学,因为自身做副业需要,我这边整理了全套的Stable Diffusion入门知识点资料,大家有需要可以直接点击下边卡片获取,希望能够真正帮助到大家。