- 1winds操作系统下登录本地MySQL和远程MySQL_windows本地启动登录mysql
- 2机器人非线性控制方法——线性化与解耦
- 3云原生、数据和AI、混合云、软件开发,微软再次刷新业界地位!_微软云 云原生 拉美市场
- 4If you want an embedded database (H2, HSQL or Derby), please put it on the classpath.
- 5 关于 MacBook Pro 的入门
- 6HTML静态网页成品作业(HTML+CSS)——动漫大耳朵图图网页(4个页面)_大耳朵图图网页设计
- 7(131)Verilog[D触发器]_verilog d触发器
- 8win10怎么设置动态壁纸
- 9vue移动端实现图片预览_关于vue移动端下载图片
- 10基于PX4飞控的双机领航-跟踪的理论分析与实验验证_px4编队飞行
C-Pack论文解读
赞
踩
最近在工作有用到关于BGE(From C-Pack),下面的内容仅作笔记。
主要贡献
针对中文文本表征,做出了三大贡献,覆盖数据,模型,benchmark三大方面。
C-MTEB:中文文本表征benchmark,包含6个任务,35个数据集
C-MTP:大规模文本表征训练数据集
C-TEM:不同规模(small,base,large)的中文文本表征模型,超出SOTA 10%左右性能
技术细节
C-MTEB
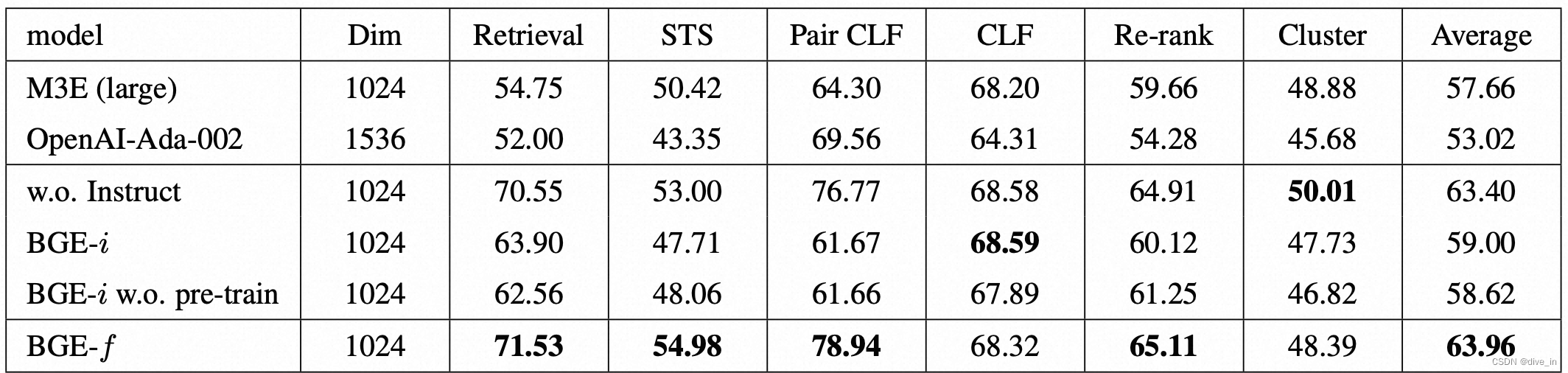
C-MTEB的35个数据集全部来源于public,覆盖文本召回(NDCG@10),排序(MAP),分类(average precision),相似度匹配(Spearman’s correlation),聚类(average precision),文本对分类(average precision)共六个方向,最终模型表现由6大任务指标取平均值得到。
C-MTP
C-MTP主要由unlabeled和labeled两部分组成,值得注意的是unlabeled的pair主要由(title,passage)组成,并且为了保证title和passage之间的相关性,采用了第三方模型text2VecChinese来对pair相关性进行打分,通过删除相关性低于0.43的方式删除部分噪声数据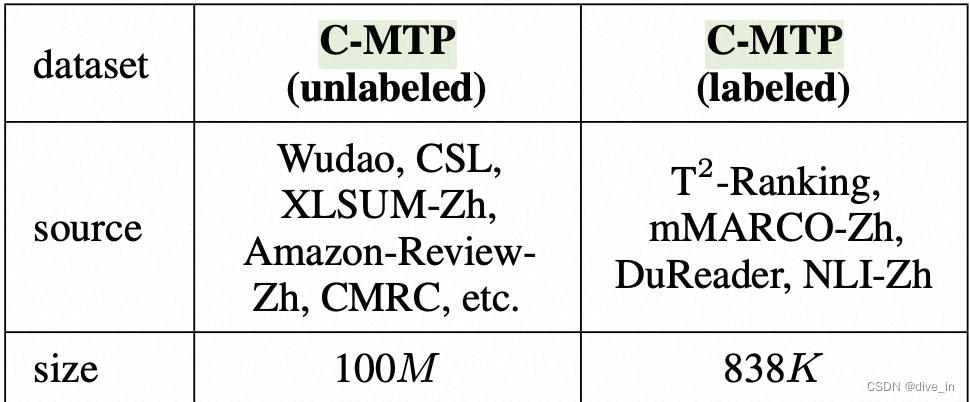
C-TEM
C-TEM是类bert架构,以最后一层隐藏层下[CLS] token的作为文本的embedding。
训练方式
训练过程主要分为三个阶段
- pretrain:该阶段使用wudao数据(完形填空),基于RetroMAE训练所得的encoder
RetroMAE:一种全尺寸编码器和单层解码器组合的面向检索的预训练语言模型,核心在使用encoder-decoder的结构,以及非对称掩码率(encoder的中等掩码率和decoder的高演码率)来增强encoder能力。
- General purpose fine-tuning:使用C-MTP(unlabeled)数据进行finetune,采用in-batch negotiate sample的方式训练,拉近正样本embedding距离,并且使负样本远离
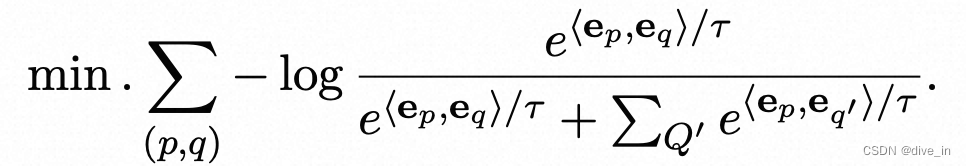
- Task-specific fine-tuning:使用C-MTP(labeled)数据进行finetune,区别与上面的general fine-tune,task-specific数据质量更高,为了统一文本表征,作者by task设计了对应的prompt与原始的query结合,并且为每一对pair样本引入了难负样本(从task原始语料中通过ANN-style[一种异步更新全局索引寻找难样本的方法]采样方式得到)
实验结论
中文表现不错,如果有中文文本任务需求的同学不妨一试
huggingface地址:https://huggingface.co/BAAI/bge-reranker-base
github地址:GitHub - FlagOpen/FlagEmbedding: Open-source Embedding Models and Ranking Models