
热门标签
热门文章
- 1Android——APP启动流程&&Android开机流程_安卓app 启动 顺序
- 2微信小程序getUserProfile详解_wx.getuserprofile
- 3[UNet]通过一个小测试了解Command和ClientRpc的功能
- 4Git Manual / Git使用手册 / Git, GitLab, Git Bash, TortoiseGit (建议全文复制到Word文档中通过导航窗格查看)...
- 5王道考研购物网站(JSP+java+springmvc+mysql+MyBatis)
- 6WPF 登录窗口demo示例
- 7NumPy的实用函数整理之where_numpy where
- 8机器学习 决策树_头歌决策树案例
- 9Pandas透视表大揭秘:从基础到高级技巧的完整指南_pandas数据透视表函数
- 10五种常见的电子商务模式对比:B2B、B2C、C2B、C2C、O2O
当前位置: article > 正文
numpy使用_numpy 使用
作者:小蓝xlanll | 2024-05-25 01:47:31
赞
踩
numpy 使用
numpy全称是numerical python,是python中用于数值计算最重要的包。它可以用于进行快速的矩阵运算、线性代数、随机数生成和傅里叶变换。
它比python计算列表计算更快,占用内存更少。这是因为numpy是以数组为粒度进行计算的,而python要用for循环来计算。
numpy是scipy, pandas, scikit-learn, tensorflow等框架的底层语言。
我们先来看看numpy中的数据类型:
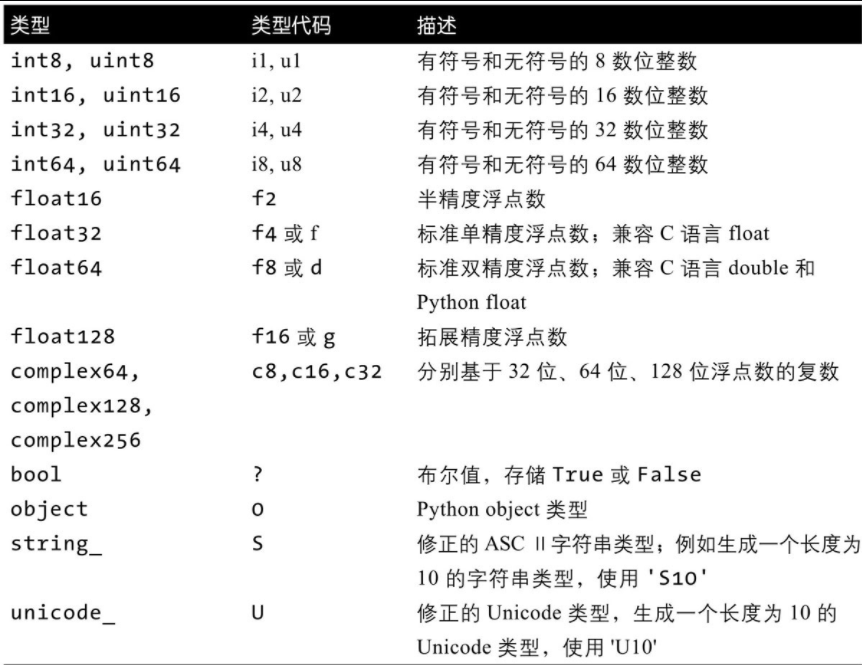
1. 基础
array本身的属性
arr.ndim # 维数
arr.shape # 维度,(行,列)
arr.size # 元素的个数
arr.dtype # 元素类型
- 1
- 2
- 3
- 4
创建数组
# 列表创建
arr = np.array([1,2,3],dtype=np.int8)
# 函数创建
arr = np.arange(start,stop,step,dtype)
arr = np.linspace(start,stop,steps)
arr = np.eye(size) # size可以是int或元组
arr = np.diag(arr) # 如果arr是一维的,那么将生成一个对角矩阵,如果arr是二维的,那么将取对角线上的元素组成一维数组
arr = np.diag([1,2,3],1) # 对角线往上挪了一格,相当于生成4*4的矩阵
np.zeros(size)
np.zeros_like(arr)
np.ones(size)
np.ones_line(arr)
np.empty(size)
np.empty_like(arr)
np.random.randn((2,3))
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
数组的索引、切片、赋值和复制
import numpy as np # 索引,切片 arr = np.arange(10) print(arr[5]) print(arr[5:8]) arr[5:8] = 12 print(arr) # 赋值 arr_slice = arr[5:8] print(arr_slice) arr_slice[1] = 12345 # arr_slice改变,arr也会改变,这并没有复制 print(arr) # 复制 arr = np.arange(10) print(arr) arr_slice = arr[5:8].copy() # 复制,arr_slice改变,arr不会改变 print(arr_slice) arr_slice[1] = 64 print(arr) # 二维数组的索引 arr = np.array([[1,2,3],[4,5,6],[7,8,9]]) # 两种方法 print(arr[0,2]) print(arr[0][2])

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
数组的转置和换轴
arr = np.arange(15).reshape((3,5))
print(arr)
print(arr.T) # 转置
# 换轴
arr = np.arange(16).reshape((2,2,4))
print(arr)
arr = arr.transpose((1,0,2))
print(arr)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
random

import numpy as np np.random.seed(666) # rand np.random.rand(5) np.random.rand(3,4) np.random.rand(2,3,4) # randn np.random.randn(5) np.random.randn(3,4) np.random.randn(2,3,4) # randint np.random.randint(3) np.random.randint(1,10) np.random.randint(10,30,size=(5,)) np.random.randint(10,30,size=(2,3,4)) # random np.random.random(5) np.random.random(size=(3,4)) np.random.random((2,3,4)) # choice() np.random.choice(5,3) # a是数字,则从range(5)中生成,size为3 np.random.choice(5,(2,3)) np.random.choice([2,3,6,7,9],3) # a是数组,从里面抽取出3个数字 np.random.choice([2,3,6,7,9],(2,3)) # shuffle(x) a = np.arange(10) result = np.random.shuffle(a) a = np.arange(20).reshape(4,5) np.random.shuffle(a) # 只在第一维度进行打散,列的顺序不会改变,在原始数组上操作,不返回值 # permutation(x) np.random.permutation(10) arr = np.arange(9).reshape((3,3)) result = np.random.permutation(arr) # 只在第一维度进行打散,列的顺序不会改变,不改变原来数组,返回一个新数组 # normal() np.random.normal(1,10,10) np.random.normal(1,10,(3,4)) # uniform() np.random.uniform(1,10,10) np.random.uniform(1,10,(3,4)) # 实例:对数组加入随机噪声 x = np.linspace(-10,10,100) y = np.sin(x) plt.plot(x,y) y1 = np.sin(x) + np.random.rand(len(x)) plt.plot(x,y) plt.show()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
数学统计函数
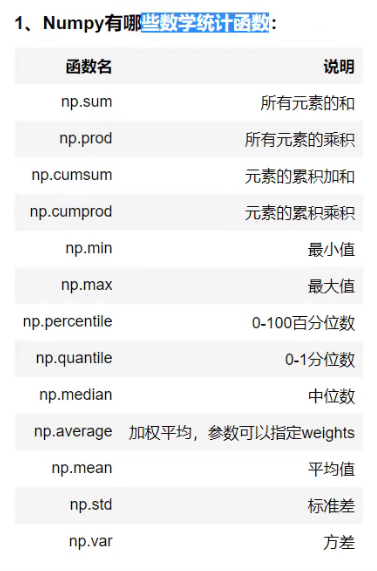
给数组增加维度
# 三种方法 # np.newaxis关键字 arr = np.arange(5) print(arr.shape) arr = arr[:,np.newaxis] print(arr) # np.expand_dims(arr,axis) arr = np.arange(5) print(arr) arr = np.expand_dims(arr,axis=0) print(arr.shape) # np.reshape(arr,newshape)) arr = np.arange(5) print(arr.shape) arr = np.reshape(arr,(1,-1)) print(arr.shape)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
数组合并
# np.concatenate(array_list,axis) 沿着指定axis进行数组的合并 a = np.arange(6).reshape(2,3) b = np.random.randint(10,20,size=(4,3)) result = np.concatenate([a,b],axis=0) print(result) # np.vsatck或np.row_stack(array_list) 垂直\按行进行数据合并 result = np.vstack([a,b]) print(result) result = np.row_stack([a,b]) print(result) # np.hstack或np.column_stack(array_list) 水平\按列进行数据合并 a = np.arange(12).reshape(3,4) b = np.random.randint(10,20,size=(3,2)) result = np.hstack([a,b]) print(result) result = np.column_stack([a,b]) print(result)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
数组分割
import numpy as np
arr = np.arange(12).reshape(3,4)
print(arr)
print(np.split(arr,2,axis=1))
print(np.split(arr,3,axis=0))
# print(np.split(arr,3,axis=1)) # 报错,np.split只能进行等分
print(np.array_split(arr,3,axis=1)) # 可以进行不等分
print(np.vsplit(arr,3)) # 横向分割,也就是按行分割
print(np.hsplit(arr,2)) # 纵向分割,也就是按列分割
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
数组的通函数
# * 按元素相乘 a = np.array([[1,1],[0,1]]) b = np.array([[2,0],[3,4]]) result = a*b print(result) # dot 矩阵乘积 result = a.dot(b) print(result) # np.exp(arr) # np.sqrt(arr) # np.add(arr1,arr2) # np.all(a,axis) 检查指定axis上是否全为True # np.any(a,axis) 检查指定axis上是否存在True # np.argmax(a,axis) 返回指定axis上的最大元素的索引 # np.argmin(a,axis) 返回指定axis上的最小元素的索引 # np.argsort(a,axis) 返回指定axis上的从小到大排列的索引 x = np.array([3,1,2]) result = np.argsort(x) print(result) # array([1,2,0]) # np.sort(a,axis) 返回指定维度上的按照从小到大排列的数组 # np.ceil(a) # np.floor(a) # np.clip(a,a_min,a_max) a = np.arange(10) print(a) result = np.clip(a,1,8) print(a) # np.cross(a,b) 返回两个矩阵的向量积 # np.minimum(x1, x2[, out]) 返回两个数组的较小值组成的数组 # np.maximum(x1, x2[, out]) 返回两个数组的较大值组成的数组 # np.flipud(a) 对矩阵进行上下翻转 # np.argwhere(a) 返回符合条件的数组的索引 >>> x = np.arange(6).reshape(2,3) >>> x array([[0, 1, 2], [3, 4, 5]]) >>> np.argwhere(x>1) array([[0, 2], [1, 0], [1, 1], [1, 2]])
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
文件读写
# np.fromfile(file, dtype=float, count=-1, sep='', offset=0) 从文本或二进制文件中的数据构造一个数组。使用tofile方法写入的数据可以使用此函数读取。
# file:打开文件对象或文件名。file 或 str 或 Path。
# dtype:返回数组的数据类型。
# count:要读取的字符或字节数。-1表示所有字符或字节(即完整文件)。
# sep:如果文件是文本文件,则字符之间的分隔符。
# offset:与文件当前位置的偏移量(以字节为单位)。默认值为0。仅允许用于二进制文件。
- 1
- 2
- 3
- 4
- 5
- 6
内存管理
# np.ascontiguousarray(a, dtype=None):将一个内存不连续存储的数组转换为内存连续存储的数组,使得运行速度更快。
- 1
逻辑运算
# np.logical_and(x1, x2):返回X1和X2与逻辑后的布尔值。
# np.logical_or(x1, x2):返回X1和X2或逻辑后的布尔值。
# np.logical_not(x):返回X非逻辑后的布尔值。
# np.logical_xor(x1,x2):返回X1和X2异或逻辑后的布尔值。
- 1
- 2
- 3
- 4
声明:本文内容由网友自发贡献,转载请注明出处:【wpsshop博客】
推荐阅读
相关标签

