
- 1【原创】android——SQLite实现简单的注册登陆(已经美化)
- 2【SpringBoot】报错:Property ‘sqlSessionFactory‘ or ‘sqlSessionTemplate‘ are required_springboot升级3.2后 property 'sqlsessionfactory' or '
- 3源码助力,游戏陪玩陪练更轻松
- 4xp系统能不能安装mysql_XP系统不能安装SQL Server 2000?
- 5Makefile的基础知识,看这篇就够了!_makefile文件
- 6CogImageConvertTool工具 图像处理工具
- 7[转]OKhttp 302 死循环
- 8【Python入门】超详细Python+Pycharm安装保姆级教程,Python环境配置和使用指南,看完这一篇就够了_pycharm配置python运行环境
- 92024前端面试题汇总
- 10在Windows10系统下安装SQL Server2000_windwo10 安装sqlserver 2000
Transformer代码(Pytorch实现和详解)!!!_transformer代码pytorch
赞
踩
这个博主讲得很不错!:https://www.cnblogs.com/kongen/p/18088002
视频:Transformer的PyTorch实现_哔哩哔哩_bilibili
如果是刚接触Transformer,强烈建议去把上边两个看了!!!在此之前,希望你能仔细读2遍原文!!!

这里其实想讲一下为什么通过自注意力机制,就能够预测出来目标值了。一开始我也比较懵懵懂懂,毕竟刚接触, 只知道我的输入a = "我 有 一只 猫" 经过encoder 和 decoder 之后,就得到了b = "I have a cat ", 后来想了想,我觉得大致是这样的,Encoder里边的Multi-Head Attention,得到了编码器输入的注意力权重,也就是输入序列a中每个单词对其他单词的注意力权重;同理Decoder的第一个Multi-Head Attention 也是得到目标序列中,各个单词之间的注意力权重。Decoder中的第二个Multi-Head Attention是将Encoder 和 Decoder 两者结合起来计算注意力权重,这样就能得到源句子中单词,对应目标句子中的单词的权重,最后转换为概率,概率最大的目标单词就是我们的答案。如果扩展一下,分别构建源语言词汇表(src_vocab)和目标语言词汇表(tgt_vocab),我们经过多轮训练之后就能得到比较准确的映射,知道最大概率翻译成哪个target词汇。我建议,先大致看一下理论,然后在代码实现里边找细节!
好,正式开始我们的主题:transformer的pytorch代码实现,首先我会分每个部分分别讲解代码,每个部分都是我觉得比较关键的点,所以顾及不了所有点,如果有不理解的,可以在评论区向我提问,很乐意讨论,完整代码放到最后。另外,我建议你在实现代码的时候,可以单独创建一个test.py文件用来测试,将每一个部分的数据打印出来看看是什么样子,尤其是你存有疑惑的数据!
导库
- import math
- import torch
- import numpy as np
- import torch.nn as nn
- import torch.optim as optim
- import torch.utils.data as Data
数据预处理以及参数设置
为了方便理解,模型没有使用大数据集,用了两对“德译英”的例子,下面是代码中的操作讲解:
- 分别构建源语言(source)和目标语言(target)的词汇表(词汇表就是字典,形式:“word”:number),这里的词汇表是手动写的,正常大数据集需要代码。
- src_len就是源句子的长度是5,tgt_len就是目标句子的长度是6。
- 'P' 就是填充项,我们要统一句子长度,但并不是每一个句子都有那么长,所以不够的用'P'填充。
- make_data()的作用是将原来的单词转化为对应在词汇表中的数字,并生成enc_inputs,dec_inputs,dec_outputs这几个数据,务必要记住他们的形状。
- 自定义数据集MyDataSet类,方便管理数据集;创建DataLoader,用来生成mini-batch。
- # S: Symbol that shows starting of decoding input
- # E: Symbol that shows starting of decoding output
- # P: Symbol that will fill in blank sequence if current batch data size is short than time steps
- sentences = [
- #enc_input dec_input dec_output
- ['ich mochte ein bier P','S i want a beer .','i want a beer . E'],
- ['ich mochte ein cola P','S i want a coke .','i want a coke . E']
- ]
-
- #Padding Should be Zero
- src_vocab = {'P' : 0,'ich' : 1,'mochte':2,'ein':3,'bier':4,'cola':5}
- src_vocab_size = len(src_vocab)
-
- tgt_vocab = {'P' : 0,'i' : 1,'want':2,'a':3,'beer':4,'coke':5,'S':6,'E':7,'.':8}
- tgt_vocab_size = len(tgt_vocab)
- idx2word = {i:w for i,w in enumerate(tgt_vocab)}
-
- src_len = 5#enc_input max sequence length
- tgt_len = 6#dec_input(=dec_output) max sequence length
-
-
- def make_data(sentences):
- enc_inputs,dec_inputs,dec_outputs = [],[],[]
- for i in range(len(sentences)):
- enc_input = [[src_vocab[n] for n in sentences[i][0].split()]] # [[1, 2, 3, 4, 0], [1, 2, 3, 5, 0]]
- dec_input = [[tgt_vocab[n] for n in sentences[i][1].split()]] # [[6, 1, 2, 3, 4, 8], [6, 1, 2, 3, 5, 8]]
- dec_output = [[tgt_vocab[n] for n in sentences[i][2].split()]] ## [[1, 2, 3, 4, 8, 7], [1, 2, 3, 5, 8, 7]]
-
- enc_inputs.extend(enc_input)
- dec_inputs.extend(dec_input)
- dec_outputs.extend(dec_output)
-
- return torch.LongTensor(enc_inputs),torch.LongTensor(dec_inputs),torch.LongTensor(dec_outputs)
-
- enc_inputs, dec_inputs, dec_outputs = make_data(sentences)
-
- class MyDataSet(Data.Dataset):
- def __init__(self,enc_inputs,dec_inputs,dec_outputs):
- super(MyDataSet, self).__init__()
- self.enc_inputs = enc_inputs
- self.dec_inputs = dec_inputs
- self.dec_outputs = dec_outputs
-
- def __len__(self):
- return self.enc_inputs.shape[0]
-
- def __getitem__(self, idx):
- return self.enc_inputs[idx],self.dec_inputs[idx],self.dec_outputs[idx]
-
- mydataset = MyDataSet(enc_inputs,dec_inputs,dec_outputs)
- loader = Data.DataLoader(mydataset,2,shuffle = True)
-

模型参数
下面变量的含义依次是:
- d_model:词嵌入的维度(= 位置嵌入维度)
- d_ff:Feed Forward中两层linear中间的过渡维度(512 -> 2048 -> 512)
- d_k、d_v:分别是K 、V的维度,其中Q和K相等的就省略了
- n_layers:EncoderLayer的数量,也就是blocks的数量
- n_heads:Multi-Head Attention 的头数
- #Transformer Parameters
- d_model = 512 # Embedding Size (= Positional Size)
- d_ff =2048 # Feed Forward(512 -> 2048 ->512)
- d_k = d_v = 64 # (d_k=d_q),dimension of qkv
- n_layers = 6 # number of encoder-layer(=n blocks)
- n_heads = 8 # number of heads in Multi-Head Attention
Positional Encoding
位置编码模块的过程是这样的,在他之前对输入序列已经进行了词嵌入,所以该模块输入的是word_embedding,形状为:[batch_size, src_len, d_model],而位置编码是写死的,在模块初始化的时候生成,将pos_embedding + word_embedding,然后输出,输出的形状:[batch_size,src_len, d_model ],得到了经过word_embedding 和 pos_embedding 的输入表示。
- class PositionalEncoding(nn.Module):
- def __init__(self,d_model ,dropout = 0.1,max_len = 5000):
- self.dropout = nn.Dropout(p = dropout)
-
- pe = torch.zeros(max_len, d_model)
- position = torch.arange(0,max_len, dtype = torch.float).unsqueeze(1)
- div_term = torch.exp(torch.arange(0, d_model, 2).float()*(-math.log(10000.0) / d_model))
- pe[:, 0::2] = torch.sin(position * div_term)
- pe[:, 1::2] = torch.cos(position * div_term)
- pe = pe.unsqueeze(0).transpose(0,1)
- self.register_buffer('pe',pe)
-
- def forward(self,x):
- '''
- :param x: [seq_len, batch_size, d_model]
- :return:
- '''
- #pe[:x.size(0),:] -- [seq_len, 1, d_model]
- x = x + self.pe[:x.size(0),:]
- return self.dropout(x)
计算公式如下:

- div_term表示括号里的分母项,这里用exp对公式做了变形,(建议手推一下)求得了div_term。
- i = 0,1,2,...,d_model/2, 。pe[maxlen, d_model]的第2个dim中,每个奇数维度的值对应一个cos,每个偶数维度的值对应一个sin,这样正好d_model个维度。实际操作中就是在0~d_model之间, 取步长为2,取得[0,2,4,...... ,d_model-2],总共d_model/2个,分别做sin、cos,这样就是d_model个,分别放到pe的d_model个维度上。
这里想说一下,具体如何将词嵌入之后的输入x 加上位置编码pe的。
首先说一下pe,即position embedding。1)pe创建的时候, 形状: [maxlen, d_model], 表示的是对第0 - maxlen 位置的单词进行编码,每个单词维度是d_model,当然实际可能每个句子不到maxlen, 后边会截取不用担心。 2)我们对pe进行编码之后,在dim=1增加了一个维度,形状变成了: [max_len, 1, d_model], 。 3)pe[:x.size(0),:] 其实就是取了跟句子长度seq_len一样大小,pe的形状变为:[seqlen, 1, d_model] 。这里的输入x的形状为:[seq_len, batch_size, d_model] (传入参数的时候改变了形状,将dim0和dim1做了交换),如下图:
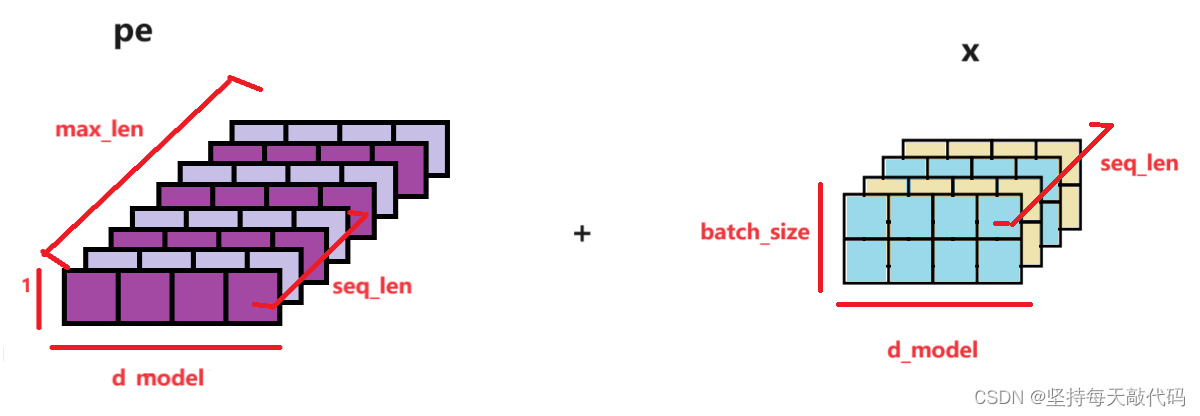
x + pe[:x.size(0),:] pe的第2维度的1会广播到batch_size大小。batch_size 就是几个句子,相当于对每个句子中的每个位置对应的单词都加上了位置编码。
[seq_len, batch_size, d_model] + [seqlen, 1, d_model] -》最后形状为:[seq_len, batch_size, d_model]。最后返回x,后边的代码会对x进行x.transpose(0,1),得到经过word_emb、pos_emb之后的编码输入:[batch_size, seq_len, d_model]
Pad Mask
这里的作用就是Mask Pad,即遮掩掉填充项,让其他单词对于填充项'P'的注意力权重几乎为0。
- def get_attn_pad_mask(seq_q, seq_k): # Mask Pad
- '''
- :param seq_q: [batch_size, seq_len]
- :param seq_k: [batch_size, seq_len]
- seq_len could be src_len or it could be tgt_len
- seq_len in seq_q and seq_len in seq_k maybe not equal
- '''
- batch_size, len_q = seq_q.size()
- batch_size, len_k = seq_k.size()
- #eq(zero) is Pad token
- pad_attn_mask = seq_k.data.eq(0).unsqueeze(1) #[batch_size,1, len_k] # True is masked
- return pad_attn_mask.expand(batch_size, len_q, len_k)#[batch_size, len_q, len_k]
Subsquence Mask

为了保证当前位置单词的翻译不考虑位置之后的信息,需要将当前位置的词汇,对它后边位置的注意力给mask掉。举个例子"我 爱 你"->"I love you" 。解码器是输入"我",预测出"I",然后输入"我 爱",预测出"I love",接着输入'''我 爱 你',预测出"I love you"。不同于RNN中的循环操作,self-attention,没有循环,都是并行计算注意力权重,但是mask掉当前词汇对其后的词汇的注意力,这样就能实现翻译当前位置的词汇时,不考虑后边的信息,如下图。
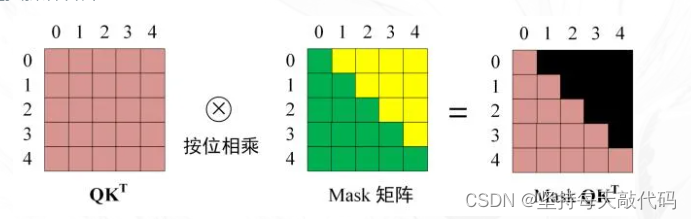
- def get_attn_subsequence_mask(seq):
- '''
- seq: [batch_size, tgt_len]
- '''
- attn_shape = [seq.size(0), seq.size(1), seq.size(1)]
- subsequence_mask = np.triu(np.ones(attn_shape), k=1) # Upper triangular matrix
- subsequence_mask = torch.from_numpy(subsequence_mask).byte()
- return subsequence_mask # [batch_size, tgt_len, tgt_len]
ScaledDotProductAttention
主要操作就是:Q 和 K^T 进行内积计算,sqrt(d_k)进行缩放得到scores,对注意力分数进行掩码操作,让不该关注的地方置成很大的负数,进行softmax操作转化为注意力权重attn, 将attn和V做矩阵乘法,得到自注意力的输出。注意代码操作的时候是把head作为一个维度加进去了,这样结果就是多个heads做self-attention的结果拼接得到的,也就是concat操作之后得到的结果。
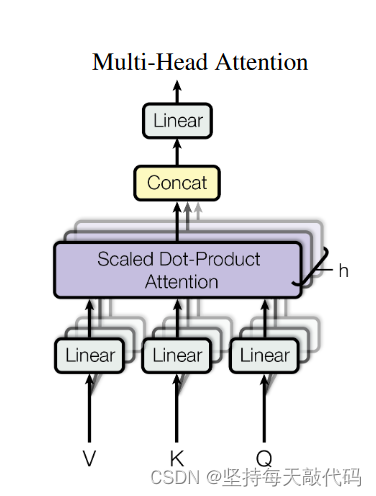
- class ScaledDotProductAttention(nn.Module):
- def __init__(self):
- super(ScaledDotProductAttention, self).__init__()
-
- def forward(self, Q, K, V, attn_mask):
- '''
- :param Q:[batch_size, n_heads, len_q, d_k]
- :param K:[batch_size, n_heads, len_k, d_k]
- :param V:[batch_size, n_heads, len_v(=len_k), d_v]
- :param attn_mask:[batch_size, n_heads, seq_len, seq_len]
- :return:
- '''
- scores = torch.matmul(Q,K.transpose(-1, -2)) / np.sqrt(d_k) # scores : [batch_size, n_heads, len_q, len_k]
- scores.masked_fill_(attn_mask, -1e9)# Fills elements of self tensor with value where mask is True.
-
- attn = nn.Softmax(dim = -1)(scores)
- context = torch.matmul(attn, V) ## [batch_size, n_heads, len_q, d_v]
- return context, attn
MultiHeadAttention
self.W_Q、self.W_K、self.W_V 是三个线性层变换,将我们的输入enc_inputs,映射成QKV,他这里映射的维度是d*n_heads,发现了没有?这是实际操作跟原理想的不太一样的,它是直接就把输入enc_inputs投影到n_heads=8个版本了。
QKV的形状经过一些列变换成了:[B,H,S,W], 如何理解呢?你可以先看后两个维度,S是序列长度,也就是单词个数,W是QKV的维度,把他看成一个小矩阵。然后再看H这个维度,就相当于有很多并排的小矩阵。B是句子个数,每个句子都有8个映射版本。
- class MultiHeadAttention(nn.Module):
- def __init__(self):
- super(MultiHeadAttention, self).__init__()
- self.W_Q = nn.Linear(d_model, d_k * n_heads, bias = False)#一次性做8个heads的qkv映射
- self.W_K = nn.Linear(d_model, d_k * n_heads, bias = False)
- self.W_V = nn.Linear(d_model, d_v * n_heads, bias = False)
- self.fc = nn.Linear(n_heads * d_v, d_model, bias = False)
-
- def forward(self,input_Q,input_K,input_V,attn_mask):
- '''
- :param input_Q: [batch_size, len_q, d_model]
- :param input_K: [batch_size, len_k, d_model]
- :param input_V: [batch_size, len_v, d_model]
- :param attn_mask: [batch_size, seq_len, seq_len]
- :return:
- '''
- residual, batch_size = input_Q, input_Q.size(0)
- #(B, S, D) -proj->(B, S, D_new) -split-> (B, S, H, W) -trans-> (B, H, S, W)
- Q = self.W_Q(input_Q).view(batch_size, -1, n_heads, d_k).transpose(1,2)
- K = self.W_K(input_K).view(batch_size, -1, n_heads, d_k).transpose(1,2)
- V = self.W_V(input_V).view(batch_size, -1, n_heads, d_v).transpose(1,2)
-
- attn_mask = attn_mask.unsqueeze(1).repeat(1, n_heads, 1, 1) # attn_mask : [batch_size, n_heads, seq_len, seq_len]
-
- #context: [batch_size, n_heads, len_q, d_v], attn: [batch_size, n_heads, len_q, len_k]
- context, attn = ScaledDotProductAttention()(Q, K, V, attn_mask)
- context = context.transpose(1,2).reshape(batch_size, -1, n_heads * d_v) # context:[batch_size,len_q, n_heads*d_v]
- output = self.fc(context) # output:[batch_size, len_q, d_model]
- return nn.LayerNorm(d_model).cuda()(output + context), attn
FeedForward Layer
两个线性层,中间用ReLu()函数激活,最后进行residual和LayerNorm操作,没什么好讲的。
- class PoswiseFeedForwardNet(nn.Module):
- def __init__(self):
- super(PoswiseFeedForwardNet, self).__init__()
- self.fc = nn.Sequential(nn.Linear(d_model, dff, bias = False),
- nn.ReLU(),
- nn.Linear(d_ff, d_model, bias = False))
-
- def forward(self, inputs):
- '''
- :param inputs: [batch_size, seq_len, d_model]
- :return:
- '''
- residual = inputs
- output = self.fc(inputs)
- return nn.LayerNorm(d_model).cuda()( output + residual)# [batch_size, seq_len, d_model]
Encoder Layer
包含两个sub-layers:Multi-Head Attention 和 FeedForward。
-
- class EncoderLayer(nn.Module):
- def __init__(self):
- super(EncoderLayer, self).__init__()
- self.enc_self_attn = MultiHeadAttention()
- self.pos_ffn = PoswiseFeedForwardNet()
-
- def forward(self,enc_inputs, enc_self_attn_mask):
- '''
- :param enc_inputs: [batch_size, src_len, d_model]
- :param enc_self_attn_mask:[batch_size, src_len, src_len]
- :return:
- '''
- #enc_outputs:[batch_size, src_len, d_model], attn: [batch_size, n_heads, src_len, src_len]
- enc_outputs, attn = self.enc_self_attn(enc_inputs, enc_inputs, enc_inputs, enc_self_attn_mask)
- enc_outputs = self.pos_ffn(enc_outputs)
- return enc_outputs, attn
DecoderLayer
- class DecoderLayer(nn.Module):
- def __init__(self):
- super(DecoderLayer, self).__init__()
- self.dec_self_attn = MultiHeadAttention()
- self.dec_enc_attn = MultiHeadAttention()
- self.pos_ffn = PoswiseFeedForwardNet()
-
- def forward(self, dec_inputs, enc_outputs, dec_self_attn_mask, dec_enc_attn_mask):
- '''
- dec_inputs: [batch_size, tgt_len, d_model]
- enc_outputs: [batch_size, src_len, d_model]
- dec_self_attn_mask: [batch_size, tgt_len, tgt_len]
- dec_enc_attn_mask: [batch_size, tgt_len, src_len]
- '''
- # dec_outputs: [batch_size, tgt_len, d_model], dec_self_attn: [batch_size, n_heads, tgt_len, tgt_len]
- dec_outputs, dec_self_attn = self.dec_self_attn(dec_inputs, dec_inputs, dec_inputs, dec_self_attn_mask)
- # dec_outputs: [batch_size, tgt_len, d_model], dec_enc_attn: [batch_size, h_heads, tgt_len, src_len]
- dec_outputs, dec_enc_attn = self.dec_enc_attn(dec_outputs, enc_outputs, enc_outputs, dec_enc_attn_mask)
- dec_outputs = self.pos_ffn(dec_outputs) # [batch_size, tgt_len, d_model]
- return dec_outputs, dec_self_attn, dec_enc_attn
Encoder
由两个嵌入层(src_emb、pos_emb)、n_layers个EncoderLayer组成。
- class Encoder(nn.Module):
- def __init__(self):
- super(Encoder, self).__init__()
- self.src_emb = nn.Embedding(src_vocab_size, d_model)
- self.pos_emb = PositionalEncoding(d_model)
- self.layers = nn.Modulelist([EncoderLayer() for _ in range(n_layers)])
-
- def forward(self,enc_inputs):
- '''
- :param enc_inputs: [batch_size,src_len]
- '''
- enc_outputs = self.src_emb(enc_inputs) #[batch_size, src_len, d_model]
- enc_outputs = self.src_emb(enc_outputs.transpose(0,1)).transpose(0,1) #[batch_size, src_len, d_model]
- enc_self_attn_mask = get_attn_pad_mask(enc_inputs,enc_inputs)
- enc_self_attns = []
- for layer in self.layers:
- # enc_outputs: [batch_size, src_len, d_model] , enc_self_attn: [batch_size, n_heads, src_len, ser_len]
- enc_outputs, enc_self_attn = layer(enc_outputs, enc_self_attn_mask)
- enc_self_attns.append(enc_self_attn)
- return enc_outputs, enc_self_attns
Decoder
- class Decoder(nn.Module):
- def __init__(self):
- super(Decoder, self).__init__()
- self.tgt_emb = nn.Embedding(tgt_vocab_size, d_model)
- self.pos_emb = PositionalEncoding(d_model)
- self.layers = nn.ModuleList([DecoderLayer() for _ in range(n_layers)])
-
- def forward(self, dec_inputs, enc_inputs, enc_outputs):
- '''
- dec_inputs: [batch_size, tgt_len]
- enc_intpus: [batch_size, src_len]
- enc_outputs: [batsh_size, src_len, d_model]
- '''
- dec_outputs = self.tgt_emb(dec_inputs) # [batch_size, tgt_len, d_model]
- dec_outputs = self.pos_emb(dec_outputs.transpose(0, 1)).transpose(0, 1).cuda() # [batch_size, tgt_len, d_model]
- dec_self_attn_pad_mask = get_attn_pad_mask(dec_inputs, dec_inputs).cuda() # [batch_size, tgt_len, tgt_len]
- dec_self_attn_subsequence_mask = get_attn_subsequence_mask(dec_inputs).cuda() # [batch_size, tgt_len, tgt_len]
- dec_self_attn_mask = torch.gt((dec_self_attn_pad_mask + dec_self_attn_subsequence_mask), 0).cuda() # [batch_size, tgt_len, tgt_len]
-
- dec_enc_attn_mask = get_attn_pad_mask(dec_inputs, enc_inputs) # [batc_size, tgt_len, src_len]
-
- dec_self_attns, dec_enc_attns = [], []
- for layer in self.layers:
- # dec_outputs: [batch_size, tgt_len, d_model], dec_self_attn: [batch_size, n_heads, tgt_len, tgt_len], dec_enc_attn: [batch_size, h_heads, tgt_len, src_len]
- dec_outputs, dec_self_attn, dec_enc_attn = layer(dec_outputs, enc_outputs, dec_self_attn_mask, dec_enc_attn_mask)
- dec_self_attns.append(dec_self_attn)
- dec_enc_attns.append(dec_enc_attn)
- return dec_outputs, dec_self_attns, dec_enc_attns
Transformer

由Encoder、Decoder,以及一个projection组成,其中Encoder部分由图中6个堆叠在一起的EncoderLayer组成(图中标错了),每个EncoderLayer的输入输出都是[batch_size, src_len, d_model],所以可以直接传到下一个EncoderLayer。Decoder输出后,进行projection操作,作用是降维,将d_model降到tgt_vocab_size大小,以便输出概率分布。
- class Transformer(nn.Module):
- def __init__(self):
- super(Transformer, self).__init__()
- self.encoder = Encoder().cuda()
- self.decoder = Decoder().cuda()
- self.projection = nn.torch.Linear(d_model, tgt_vocab_size, bias=False).cuda()
-
- def forward(self,enc_inputs,dec_inputs,dec_outputs):
- '''
- :param enc_inputs: [batch_size, src_len]
- :param dec_inputs: [batch_size, tgt_len]
- :return:
- '''
- # tensor to store decoder outputs
- # outputs = torch.zeros(batch_size, tgt_len, tgt_vocab_size).to(self.device)
-
- # enc_outputs: [batch_size, src_len, d_model], enc_self_attns: [n_layers, batch_size, n_heads, src_len, src_len]
- enc_outputs, enc_self_attns = self.encoder(enc_inputs)
- #dec_outputs: [batch_size,tgt_len, d_model],dec_self_attns: [n_layers, batch_size, n_heads, tgt_len, tgt_len],dec_enc_attn: [n_layers, batch_size, tgt_len, src_len]
- dec_outputs, dec_self_attns, dec_enc_attns = self.decoder(dec_inputs,enc_inputs, enc_outputs)
- dec_logits = self.projection(dec_outputs)
- return dec_logits.view(-1, dec_logits.size(-1)),enc_self_attns,dec_self_attns, dec_enc_attns
模型训练
- model = Transformer().cuda()
- criterion = nn.CrossEntropyLoss(ignore_index=0)
- optimizer = optim.SGD(model.parameters(), lr=1e-3, momentum=0.99)
-
- for epoch in range(1000):
- for enc_inputs, dec_inputs, dec_outputs in loader:
- '''
- enc_inputs: [batch_size, src_len]
- dec_inputs: [batch_size, tgt_len]
- dec_outputs: [batch_size, tgt_len]
- '''
- enc_inputs, dec_inputs, dec_outputs = enc_inputs.cuda(), dec_inputs.cuda(), dec_outputs.cuda()
- # outputs: [batch_size * tgt_len, tgt_vocab_size]
- outputs, enc_self_attns, dec_self_attns, dec_enc_attns = model(enc_inputs, dec_inputs)
- loss = criterion(outputs, dec_outputs.view(-1))
- print('Epoch:', '%04d' % (epoch + 1), 'loss =', '{:.6f}'.format(loss))
-
- optimizer.zero_grad()
- loss.backward()
- optimizer.step()
Greedy_decoder
暂时可以注释掉这部分代码,是以另一种方式进行训练,感兴趣的可以去了解一下。
- def greedy_decoder(model, enc_input, start_symbol):
- """
- For simplicity, a Greedy Decoder is Beam search when K=1. This is necessary for inference as we don't know the
- target sequence input. Therefore we try to generate the target input word by word, then feed it into the transformer.
- Starting Reference: http://nlp.seas.harvard.edu/2018/04/03/attention.html#greedy-decoding
- :param model: Transformer Model
- :param enc_input: The encoder input
- :param start_symbol: The start symbol. In this example it is 'S' which corresponds to index 4
- :return: The target input
- """
- enc_outputs, enc_self_attns = model.encoder(enc_input)
- dec_input = torch.zeros(1, 0).type_as(enc_input.data)
- terminal = False
- next_symbol = start_symbol
- while not terminal:
- dec_input = torch.cat([dec_input.detach(),torch.tensor([[next_symbol]],dtype=enc_input.dtype).cuda()],-1)
- dec_outputs, _, _ = model.decoder(dec_input, enc_input, enc_outputs)
- projected = model.projection(dec_outputs)
- prob = projected.squeeze(0).max(dim=-1, keepdim=False)[1]
- next_word = prob.data[-1]
- next_symbol = next_word
- if next_symbol == tgt_vocab["."]:
- terminal = True
- print(next_word)
- return dec_input
-
- # Test
- enc_inputs, _, _ = next(iter(loader))
- enc_inputs = enc_inputs.cuda()
- for i in range(len(enc_inputs)):
- greedy_dec_input = greedy_decoder(model, enc_inputs[i].view(1, -1), start_symbol=tgt_vocab["S"])
- predict, _, _, _ = model(enc_inputs[i].view(1, -1), greedy_dec_input)
- predict = predict.data.max(1, keepdim=True)[1]
- print(enc_inputs[i], '->', [idx2word[n.item()] for n in predict.squeeze()])
完整代码
- # -*- coding: utf-8 -*-
- """Transformer-Torch
- Automatically generated by Colaboratory.
- Original file is located at
- https://colab.research.google.com/drive/15yTJSjZpYuIWzL9hSbyThHLer4iaJjBD
- """
-
- '''
- code by Tae Hwan Jung(Jeff Jung) @graykode, Derek Miller @dmmiller612, modify by wmathor
- Reference : https://github.com/jadore801120/attention-is-all-you-need-pytorch
- https://github.com/JayParks/transformer
- '''
- import math
- import torch
- import numpy as np
- import torch.nn as nn
- import torch.optim as optim
- import torch.utils.data as Data
-
- # S: Symbol that shows starting of decoding input
- # E: Symbol that shows starting of decoding output
- # P: Symbol that will fill in blank sequence if current batch data size is short than time steps
- sentences = [
- # enc_input dec_input dec_output
- ['ich mochte ein bier P', 'S i want a beer .', 'i want a beer . E'],
- ['ich mochte ein cola P', 'S i want a coke .', 'i want a coke . E']
- ]
-
- # Padding Should be Zero
- src_vocab = {'P' : 0, 'ich' : 1, 'mochte' : 2, 'ein' : 3, 'bier' : 4, 'cola' : 5}
- src_vocab_size = len(src_vocab)
-
- tgt_vocab = {'P' : 0, 'i' : 1, 'want' : 2, 'a' : 3, 'beer' : 4, 'coke' : 5, 'S' : 6, 'E' : 7, '.' : 8}
- idx2word = {i: w for i, w in enumerate(tgt_vocab)}
- tgt_vocab_size = len(tgt_vocab)
-
- src_len = 5 # enc_input max sequence length
- tgt_len = 6 # dec_input(=dec_output) max sequence length
-
- # Transformer Parameters
- d_model = 512 # Embedding Size
- d_ff = 2048 # FeedForward dimension
- d_k = d_v = 64 # dimension of K(=Q), V
- n_layers = 6 # number of Encoder of Decoder Layer
- n_heads = 8 # number of heads in Multi-Head Attention
-
- def make_data(sentences):
- enc_inputs, dec_inputs, dec_outputs = [], [], []
- for i in range(len(sentences)):
- enc_input = [[src_vocab[n] for n in sentences[i][0].split()]] # [[1, 2, 3, 4, 0], [1, 2, 3, 5, 0]]
- dec_input = [[tgt_vocab[n] for n in sentences[i][1].split()]] # [[6, 1, 2, 3, 4, 8], [6, 1, 2, 3, 5, 8]]
- dec_output = [[tgt_vocab[n] for n in sentences[i][2].split()]] # [[1, 2, 3, 4, 8, 7], [1, 2, 3, 5, 8, 7]]
-
- enc_inputs.extend(enc_input)
- dec_inputs.extend(dec_input)
- dec_outputs.extend(dec_output)
-
- return torch.LongTensor(enc_inputs), torch.LongTensor(dec_inputs), torch.LongTensor(dec_outputs)
-
- enc_inputs, dec_inputs, dec_outputs = make_data(sentences)
-
- class MyDataSet(Data.Dataset):
- def __init__(self, enc_inputs, dec_inputs, dec_outputs):
- super(MyDataSet, self).__init__()
- self.enc_inputs = enc_inputs
- self.dec_inputs = dec_inputs
- self.dec_outputs = dec_outputs
-
- def __len__(self):
- return self.enc_inputs.shape[0]
-
- def __getitem__(self, idx):
- return self.enc_inputs[idx], self.dec_inputs[idx], self.dec_outputs[idx]
-
- loader = Data.DataLoader(MyDataSet(enc_inputs, dec_inputs, dec_outputs), 2, True)
-
- class PositionalEncoding(nn.Module):
- def __init__(self, d_model, dropout=0.1, max_len=5000):
- super(PositionalEncoding, self).__init__()
- self.dropout = nn.Dropout(p=dropout)
-
- pe = torch.zeros(max_len, d_model)
- position = torch.arange(0, max_len, dtype=torch.float).unsqueeze(1)
- div_term = torch.exp(torch.arange(0, d_model, 2).float() * (-math.log(10000.0) / d_model))
- pe[:, 0::2] = torch.sin(position * div_term)
- pe[:, 1::2] = torch.cos(position * div_term)
- pe = pe.unsqueeze(0).transpose(0, 1)
- self.register_buffer('pe', pe)
-
- def forward(self, x):
- '''
- x: [seq_len, batch_size, d_model]
- '''
- x = x + self.pe[:x.size(0), :]
- return self.dropout(x)
-
- def get_attn_pad_mask(seq_q, seq_k):
- '''
- seq_q: [batch_size, seq_len]
- seq_k: [batch_size, seq_len]
- seq_len could be src_len or it could be tgt_len
- seq_len in seq_q and seq_len in seq_k maybe not equal
- '''
- batch_size, len_q = seq_q.size()
- batch_size, len_k = seq_k.size()
- # eq(zero) is PAD token
- pad_attn_mask = seq_k.data.eq(0).unsqueeze(1) # [batch_size, 1, len_k], False is masked
- return pad_attn_mask.expand(batch_size, len_q, len_k) # [batch_size, len_q, len_k]
-
- def get_attn_subsequence_mask(seq):
- '''
- seq: [batch_size, tgt_len]
- '''
- attn_shape = [seq.size(0), seq.size(1), seq.size(1)]
- subsequence_mask = np.triu(np.ones(attn_shape), k=1) # Upper triangular matrix
- subsequence_mask = torch.from_numpy(subsequence_mask).byte()
- return subsequence_mask # [batch_size, tgt_len, tgt_len]
-
- class ScaledDotProductAttention(nn.Module):
- def __init__(self):
- super(ScaledDotProductAttention, self).__init__()
-
- def forward(self, Q, K, V, attn_mask):
- '''
- Q: [batch_size, n_heads, len_q, d_k]
- K: [batch_size, n_heads, len_k, d_k]
- V: [batch_size, n_heads, len_v(=len_k), d_v]
- attn_mask: [batch_size, n_heads, seq_len, seq_len]
- '''
- scores = torch.matmul(Q, K.transpose(-1, -2)) / np.sqrt(d_k) # scores : [batch_size, n_heads, len_q, len_k]
- scores.masked_fill_(attn_mask, -1e9) # Fills elements of self tensor with value where mask is True.
-
- attn = nn.Softmax(dim=-1)(scores)
- context = torch.matmul(attn, V) # [batch_size, n_heads, len_q, d_v]
- return context, attn
-
- class MultiHeadAttention(nn.Module):
- def __init__(self):
- super(MultiHeadAttention, self).__init__()
- self.W_Q = nn.Linear(d_model, d_k * n_heads, bias=False)
- self.W_K = nn.Linear(d_model, d_k * n_heads, bias=False)
- self.W_V = nn.Linear(d_model, d_v * n_heads, bias=False)
- self.fc = nn.Linear(n_heads * d_v, d_model, bias=False)
- def forward(self, input_Q, input_K, input_V, attn_mask):
- '''
- input_Q: [batch_size, len_q, d_model]
- input_K: [batch_size, len_k, d_model]
- input_V: [batch_size, len_v(=len_k), d_model]
- attn_mask: [batch_size, seq_len, seq_len]
- '''
- residual, batch_size = input_Q, input_Q.size(0)
- # (B, S, D) -proj-> (B, S, D_new) -split-> (B, S, H, W) -trans-> (B, H, S, W)
- Q = self.W_Q(input_Q).view(batch_size, -1, n_heads, d_k).transpose(1,2) # Q: [batch_size, n_heads, len_q, d_k]
- K = self.W_K(input_K).view(batch_size, -1, n_heads, d_k).transpose(1,2) # K: [batch_size, n_heads, len_k, d_k]
- V = self.W_V(input_V).view(batch_size, -1, n_heads, d_v).transpose(1,2) # V: [batch_size, n_heads, len_v(=len_k), d_v]
-
- attn_mask = attn_mask.unsqueeze(1).repeat(1, n_heads, 1, 1) # attn_mask : [batch_size, n_heads, seq_len, seq_len]
-
- # context: [batch_size, n_heads, len_q, d_v], attn: [batch_size, n_heads, len_q, len_k]
- context, attn = ScaledDotProductAttention()(Q, K, V, attn_mask)
- context = context.transpose(1, 2).reshape(batch_size, -1, n_heads * d_v) # context: [batch_size, len_q, n_heads * d_v]
- output = self.fc(context) # [batch_size, len_q, d_model]
- return nn.LayerNorm(d_model).cuda()(output + residual), attn
-
- class PoswiseFeedForwardNet(nn.Module):
- def __init__(self):
- super(PoswiseFeedForwardNet, self).__init__()
- self.fc = nn.Sequential(
- nn.Linear(d_model, d_ff, bias=False),
- nn.ReLU(),
- nn.Linear(d_ff, d_model, bias=False)
- )
- def forward(self, inputs):
- '''
- inputs: [batch_size, seq_len, d_model]
- '''
- residual = inputs
- output = self.fc(inputs)
- return nn.LayerNorm(d_model).cuda()(output + residual) # [batch_size, seq_len, d_model]
-
- class EncoderLayer(nn.Module):
- def __init__(self):
- super(EncoderLayer, self).__init__()
- self.enc_self_attn = MultiHeadAttention()
- self.pos_ffn = PoswiseFeedForwardNet()
-
- def forward(self, enc_inputs, enc_self_attn_mask):
- '''
- enc_inputs: [batch_size, src_len, d_model]
- enc_self_attn_mask: [batch_size, src_len, src_len]
- '''
- # enc_outputs: [batch_size, src_len, d_model], attn: [batch_size, n_heads, src_len, src_len]
- enc_outputs, attn = self.enc_self_attn(enc_inputs, enc_inputs, enc_inputs, enc_self_attn_mask) # enc_inputs to same Q,K,V
- enc_outputs = self.pos_ffn(enc_outputs) # enc_outputs: [batch_size, src_len, d_model]
- return enc_outputs, attn
-
- class DecoderLayer(nn.Module):
- def __init__(self):
- super(DecoderLayer, self).__init__()
- self.dec_self_attn = MultiHeadAttention()
- self.dec_enc_attn = MultiHeadAttention()
- self.pos_ffn = PoswiseFeedForwardNet()
-
- def forward(self, dec_inputs, enc_outputs, dec_self_attn_mask, dec_enc_attn_mask):
- '''
- dec_inputs: [batch_size, tgt_len, d_model]
- enc_outputs: [batch_size, src_len, d_model]
- dec_self_attn_mask: [batch_size, tgt_len, tgt_len]
- dec_enc_attn_mask: [batch_size, tgt_len, src_len]
- '''
- # dec_outputs: [batch_size, tgt_len, d_model], dec_self_attn: [batch_size, n_heads, tgt_len, tgt_len]
- dec_outputs, dec_self_attn = self.dec_self_attn(dec_inputs, dec_inputs, dec_inputs, dec_self_attn_mask)
- # dec_outputs: [batch_size, tgt_len, d_model], dec_enc_attn: [batch_size, h_heads, tgt_len, src_len]
- dec_outputs, dec_enc_attn = self.dec_enc_attn(dec_outputs, enc_outputs, enc_outputs, dec_enc_attn_mask)
- dec_outputs = self.pos_ffn(dec_outputs) # [batch_size, tgt_len, d_model]
- return dec_outputs, dec_self_attn, dec_enc_attn
-
- class Encoder(nn.Module):
- def __init__(self):
- super(Encoder, self).__init__()
- self.src_emb = nn.Embedding(src_vocab_size, d_model)
- self.pos_emb = PositionalEncoding(d_model)
- self.layers = nn.ModuleList([EncoderLayer() for _ in range(n_layers)])
-
- def forward(self, enc_inputs):
- '''
- enc_inputs: [batch_size, src_len]
- '''
- enc_outputs = self.src_emb(enc_inputs) # [batch_size, src_len, d_model]
- enc_outputs = self.pos_emb(enc_outputs.transpose(0, 1)).transpose(0, 1) # [batch_size, src_len, d_model]
- enc_self_attn_mask = get_attn_pad_mask(enc_inputs, enc_inputs) # [batch_size, src_len, src_len]
- enc_self_attns = []
- for layer in self.layers:
- # enc_outputs: [batch_size, src_len, d_model], enc_self_attn: [batch_size, n_heads, src_len, src_len]
- enc_outputs, enc_self_attn = layer(enc_outputs, enc_self_attn_mask)
- enc_self_attns.append(enc_self_attn)
- return enc_outputs, enc_self_attns
-
- class Decoder(nn.Module):
- def __init__(self):
- super(Decoder, self).__init__()
- self.tgt_emb = nn.Embedding(tgt_vocab_size, d_model)
- self.pos_emb = PositionalEncoding(d_model)
- self.layers = nn.ModuleList([DecoderLayer() for _ in range(n_layers)])
-
- def forward(self, dec_inputs, enc_inputs, enc_outputs):
- '''
- dec_inputs: [batch_size, tgt_len]
- enc_intpus: [batch_size, src_len]
- enc_outputs: [batsh_size, src_len, d_model]
- '''
- dec_outputs = self.tgt_emb(dec_inputs) # [batch_size, tgt_len, d_model]
- dec_outputs = self.pos_emb(dec_outputs.transpose(0, 1)).transpose(0, 1).cuda() # [batch_size, tgt_len, d_model]
- dec_self_attn_pad_mask = get_attn_pad_mask(dec_inputs, dec_inputs).cuda() # [batch_size, tgt_len, tgt_len]
- dec_self_attn_subsequence_mask = get_attn_subsequence_mask(dec_inputs).cuda() # [batch_size, tgt_len, tgt_len]
- dec_self_attn_mask = torch.gt((dec_self_attn_pad_mask + dec_self_attn_subsequence_mask), 0).cuda() # [batch_size, tgt_len, tgt_len]
-
- dec_enc_attn_mask = get_attn_pad_mask(dec_inputs, enc_inputs) # [batc_size, tgt_len, src_len]
-
- dec_self_attns, dec_enc_attns = [], []
- for layer in self.layers:
- # dec_outputs: [batch_size, tgt_len, d_model], dec_self_attn: [batch_size, n_heads, tgt_len, tgt_len], dec_enc_attn: [batch_size, h_heads, tgt_len, src_len]
- dec_outputs, dec_self_attn, dec_enc_attn = layer(dec_outputs, enc_outputs, dec_self_attn_mask, dec_enc_attn_mask)
- dec_self_attns.append(dec_self_attn)
- dec_enc_attns.append(dec_enc_attn)
- return dec_outputs, dec_self_attns, dec_enc_attns
-
- class Transformer(nn.Module):
- def __init__(self):
- super(Transformer, self).__init__()
- self.encoder = Encoder().cuda()
- self.decoder = Decoder().cuda()
- self.projection = nn.Linear(d_model, tgt_vocab_size, bias=False).cuda()
- def forward(self, enc_inputs, dec_inputs):
- '''
- enc_inputs: [batch_size, src_len]
- dec_inputs: [batch_size, tgt_len]
- '''
- # tensor to store decoder outputs
- # outputs = torch.zeros(batch_size, tgt_len, tgt_vocab_size).to(self.device)
-
- # enc_outputs: [batch_size, src_len, d_model], enc_self_attns: [n_layers, batch_size, n_heads, src_len, src_len]
- enc_outputs, enc_self_attns = self.encoder(enc_inputs)
- # dec_outpus: [batch_size, tgt_len, d_model], dec_self_attns: [n_layers, batch_size, n_heads, tgt_len, tgt_len], dec_enc_attn: [n_layers, batch_size, tgt_len, src_len]
- dec_outputs, dec_self_attns, dec_enc_attns = self.decoder(dec_inputs, enc_inputs, enc_outputs)
- dec_logits = self.projection(dec_outputs) # dec_logits: [batch_size, tgt_len, tgt_vocab_size]
- return dec_logits.view(-1, dec_logits.size(-1)), enc_self_attns, dec_self_attns, dec_enc_attns
-
- model = Transformer().cuda()
- criterion = nn.CrossEntropyLoss(ignore_index=0)
- optimizer = optim.SGD(model.parameters(), lr=1e-3, momentum=0.99)
-
- for epoch in range(1000):
- for enc_inputs, dec_inputs, dec_outputs in loader:
- '''
- enc_inputs: [batch_size, src_len]
- dec_inputs: [batch_size, tgt_len]
- dec_outputs: [batch_size, tgt_len]
- '''
- enc_inputs, dec_inputs, dec_outputs = enc_inputs.cuda(), dec_inputs.cuda(), dec_outputs.cuda()
- # outputs: [batch_size * tgt_len, tgt_vocab_size]
- outputs, enc_self_attns, dec_self_attns, dec_enc_attns = model(enc_inputs, dec_inputs)
- loss = criterion(outputs, dec_outputs.view(-1))
- print('Epoch:', '%04d' % (epoch + 1), 'loss =', '{:.6f}'.format(loss))
-
- optimizer.zero_grad()
- loss.backward()
- optimizer.step()
-
- def greedy_decoder(model, enc_input, start_symbol):
- """
- For simplicity, a Greedy Decoder is Beam search when K=1. This is necessary for inference as we don't know the
- target sequence input. Therefore we try to generate the target input word by word, then feed it into the transformer.
- Starting Reference: http://nlp.seas.harvard.edu/2018/04/03/attention.html#greedy-decoding
- :param model: Transformer Model
- :param enc_input: The encoder input
- :param start_symbol: The start symbol. In this example it is 'S' which corresponds to index 4
- :return: The target input
- """
- enc_outputs, enc_self_attns = model.encoder(enc_input)
- dec_input = torch.zeros(1, 0).type_as(enc_input.data)
- terminal = False
- next_symbol = start_symbol
- while not terminal:
- dec_input = torch.cat([dec_input.detach(),torch.tensor([[next_symbol]],dtype=enc_input.dtype).cuda()],-1)
- dec_outputs, _, _ = model.decoder(dec_input, enc_input, enc_outputs)
- projected = model.projection(dec_outputs)
- prob = projected.squeeze(0).max(dim=-1, keepdim=False)[1]
- next_word = prob.data[-1]
- next_symbol = next_word
- if next_symbol == tgt_vocab["."]:
- terminal = True
- print(next_word)
- return dec_input
-
- # Test
- enc_inputs, _, _ = next(iter(loader))
- enc_inputs = enc_inputs.cuda()
- for i in range(len(enc_inputs)):
- greedy_dec_input = greedy_decoder(model, enc_inputs[i].view(1, -1), start_symbol=tgt_vocab["S"])
- predict, _, _, _ = model(enc_inputs[i].view(1, -1), greedy_dec_input)
- predict = predict.data.max(1, keepdim=True)[1]
- print(enc_inputs[i], '->', [idx2word[n.item()] for n in predict.squeeze()])
-
总结
这个是第一版,有些代码如果不对,欢迎在评论指正,后续会慢慢改,我也是刚接触transformer,若有些地方理解不对还请指正。我相信如果你自己一行一行代码实操一下对你的理解有很大的帮助,谢谢别忘了点赞哦!

