
- 1分表分库解决方案(mycat,tidb,shardingjdbc)_mycat 分库分表 只能单库多表 多库单表
- 2计算机专业论文结束语,毕业设计论文的结束语
- 3git+gerrit管理代码,常用git命令整理(持续更新)_gerrit上传代码
- 4RabbitMQ 鉴权、授权、权限访问
- 5长亭雷池WAF个人部署记录_waf windows
- 6通过openwrt查看连接设备的IP,MAC地址,设备名_openwrt查看网口的连接
- 7Anaconda 环境中安装OpenCV (cv2)_conda安装cv2,2024年最新想学IT的必看_conda install opencv
- 8在eclipse中用git导入工程问题:cannot open git-upload-pack_sts拉代码报错cannot open git-upload-pack
- 9Java项目实战笔记--基于SpringBoot3.0开发仿12306高并发售票系统--(二)项目实现-第一篇-后端项目框架搭建_12306项目 logaspect代码
- 10计算机写论文时,怎么引用文献? - 易智编译EaseEditing_计算机开题报告怎么引用文献
决策树Python头歌_决策树模型预测头歌
赞
踩
基于头歌,头歌真的是太多有趣的故事。
任务描述
本关任务:编写一个使用决策树算法进行信息增益计算及结点划分的程序。
决策树模型
决策树(Decision Tree)是在已知各种情况发生概率的基础上,通过构成决策树来求取净现值的期望值大于等于零的概率,评价项目风险,判断其可行性的决策分析方法,是直观运用概率分析的一种图解法。由于这种决策分支画成图形很像一棵树的枝干,故称决策树。在机器学习中,决策树是一个预测模型,他代表的是对象属性与对象值之间的一种映射关系。Entropy = 系统的凌乱程度,使用算法ID3, C4.5和C5.0生成树算法使用熵。这一度量是基于信息学理论中熵的概念。 决策树由结点和有向边组成。结点有两种类型:内部结点和叶结点,其中内部结点表示一个特征或属性,叶结点表示一个类。一般的,一棵决策树包含一个根结点、若干个内部结点和若干个叶结点。叶结点对应于决策结果,其他每个结点则对应于一个属性测试。每个结点包含的样本集合根据属性测试的结果被划分到子结点中,根结点包含样本全集,从根结点到每个叶结点的路径对应了一个判定测试序列。在下图中,圆和方框分别表示内部结点和叶结点。决策树学习的目的是为了产生一棵泛化能力强,即处理未见示例能力强的决策树。下图为决策树的示意图:
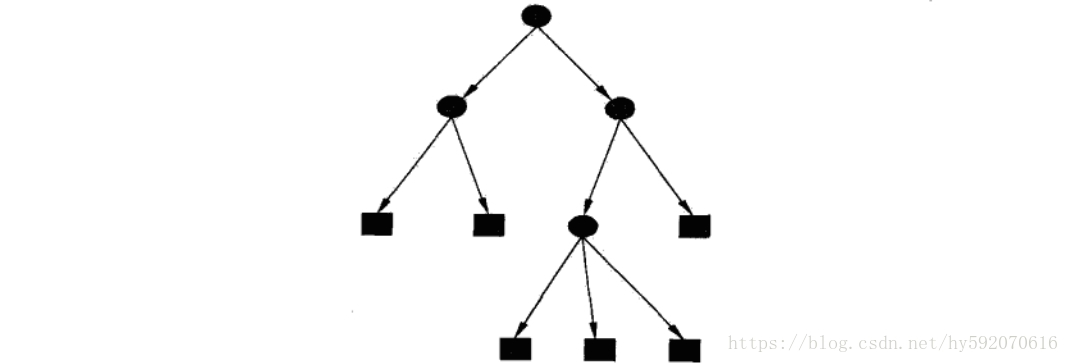
决策树根据任务的不同可以分为回归树和分类树,在本次课程中,我们主要实现分类树的构建。
决策树分类器
决策树算法分类和人类在进行决策时的处理机制类似,依据对一系列属性取值的判定得出最终决策。决策树是一棵树结构,其每个非叶子节点表示一个特征属性上的测试,每个分支表示这个特征属性在某个值域上的输出,而每个叶子节点对应于最终决策结果。使用决策树进行决策的过程就是从根节点开始,测试待分类项中相应的特征属性,并按照其值选择输出分支,直到到达叶子节点,将叶子节点对应的类别作为决策结果。
决策树学习的目的是产生一棵泛化性能强,即处理未见示例能力强的决策树。其基本流程遵循“分而治之”的策略,算法伪代码如下图所示:
- 输入:训练集D={(x_1,y_1),(x_2,y_2),⋯,(x_m,y_m)};
- 属性集A={a_1,a_2,⋯,a_d}.
- 过程:函数TreeGenerate(D,A)
- 1: 生成节点node
- 2: if D中样本全属于同一类别C then
- 3: 将node标记为C类叶节点;return
- 4: end if
- 5: if A=∅ or D中样本在A上取值相同 then
- 6: 将node标记为叶节点,其类别标记为D中样本数最多的类;return
- 7: end if
- 8: 从A中选择最优 划分属性a_*;
- 9: for a_*的每一个取值a_*^v do
- 10: 为node生成一个分支;令D_v表示D中在a_*上取值为a_*^v的样本子集;
- 11: if D_v=∅ then
- 12: 将分支节点标记为叶节点,其类别标记为D中样本最多的类;return
- 13: else
- 14: 以TreeGenerate(D_v,A\{a_*})为分支节点
- 15: end if
- 16: end for
- 输出:以node为根节点的一棵决策树

编程要求
根据提示,在右侧编辑器补充代码,实现决策树信息熵构建,包括:
- 划分的函数
- 信息熵计算的函数
- 最优划分属性和最优值计算的函数
- 进行划分,并打印划分后的信息熵值
- import numpy as np
- from sklearn import datasets
-
- #######Begin#######
- # 划分函数
- def split(x,y,d,value):
-
- #######End#########
- index_a=(x[:,d]<=value)
- index_b=(x[:,d]>value)
- return x[index_a],x[index_b],y[index_a],y[index_b]
- #######Begin#######
- # 信息熵的计算
- from collections import Counter
- def entropy(y):
- counter=Counter(y)
- res=0.0
- for i in counter.values():
- p=i/len(y)
- res+=-p*np.log(p)
- return res
- #######End#########
-
- #######Begin#######
- # 计算最优划分属性和值的函数
- def try_spit(x,y):
- best_entropy=float("inf")
- best_d,best_v=-1,-1
- for d in range(x.shape[1]):
- sorted_index=np.argsort(x[:,d])
- for i in range(1,len(x)):
- if x[sorted_index[i-1],d] != x[sorted_index[i],d]:
- v=(x[sorted_index[i-1],d]+x[sorted_index[i],d])/2
- x_l,x_r,y_l,y_r=split(x,y,d,v)
- e=entropy(y_l)+entropy(y_r)
- if e<best_entropy:
- best_entropy,best_d,best_v=e,d,v
- return best_entropy,best_d,best_v
- #######End#########
-
-
- # 加载数据
- d=datasets.load_iris()
- x=d.data[:,2:]
- y=d.target
- # 计算出最优划分属性和最优值
- best_entropy=try_spit(x,y)[0]
- best_d=try_spit(x,y)[1]
- best_v=try_spit(x,y)[2]
- # 使用最优划分属性和值进行划分
- x_l,x_r,y_l,y_r=split(x,y,best_d,best_v)
- # 打印结果
- print("叶子结点的熵值:")
- print(entropy(y_l))
- print("分支结点的熵值:")
- print(entropy(y_r))
-
-
这个耗时很久,大多是信息熵entropy(y)函数的内部编写出现了问题。
第一次:
- #定义二分类问题的信息熵计算函数np.sum(-p*np.log(p))
- def entropy(p):
- return -p*np.log(p)-(1-p)*np.log(1-p)
Error:
RuntimeWarning: divide by zero encountered in log
return -p*np.log(p)-(1-p)*np.log(1-p)
这里log标错是因为p应该不为0和1
RuntimeWarning: invalid value encountered in multiply
return -p*np.log(p)-(1-p)*np.log(1-p)
这里multiply标错是p等于1时乘法无效
RuntimeWarning: invalid value encountered in log
return -p*np.log(p)-(1-p)*np.log(1-p)
这里log标错同上。
第二次:
课本例题:
第三次:
第四次:找找Counter函数的功能。

