
- 12021 年 Angular vs. React vs. Vue 前端框架对比_vue bom对比
- 2控制台打印心形_cmd打印爱心
- 32024年网络安全最全AWVS工具太顶了,漏洞扫描工具AWVS介绍及安装教程_qawvsq(1),2024年最新2024网络安全春招_awvs更新漏洞库
- 4swagger2 knife4j 集成配置_swagger2 配置 kneif4j
- 5Python字典(Dictionary)详细使用教程_python 用dictionary
- 6考研学习平台设计与实现(JSP+java+springmvc+mysql+MyBatis)_考研经验分享平台的设计与实现
- 7中小学居然也要开这门课程?普通人学Python有何用?_中小学为什么要学python
- 8【Transformer】一文搞懂Transformer | CV领域中Transformer应用_transformer在cv上的应用
- 9Kafka基础—3、Kafka 消费者API_kafka sarama创建消费组
- 10极光笔记丨Spark SQL 在极光的建设实践
LLMs之LLaMA:LLaMA的简介、安装和使用方法、案例应用之详细攻略_python chinesecalendar
赞
踩
LLMs之LLaMA:LLaMA的简介、安装和使用方法、案例应用之详细攻略
导读:2023年2月25日,Meta公开发布LLaMA,并提出了一系列开源的基础NLP模型——LLaMA模型,重点解决了目前许多模型依赖于专有数据集等资源的问题。
>> 背景痛点:许多现有的模型如GPT-3、PaLM等依赖于不可公开获取的专有数据集进行训练,不利于开源和研究。
>> 解决方案:本研究通过仅使用公开数据集,训练出不同规模的LLaMA模型,其中LLaMA-13B的性能超过了175B的参数的GPT-3,LLaMA-65B的性能接近70B的参数的Chinchilla模型。
>> 核心特点:LLaMA模型不同规模,最小7B参数可以在单个GPU上运行,最大65B参数性能指标与现有模型持平。
>> 优势:1提出了开放可复现的 baselline 模型 2训练覆盖公开资源,利于开源与研究 3不同规模满足不同应用场景需求 4性能指标与SOTA持平或优越
>> 结果总结:论文通过开放与复现性强的模型及训练方式,解决了依赖专有资源的问题,同时该系列模型性能也表现出色,为应用和未来模型提供了优质基线。
目录
LLMs之LLaMA:《LLaMA: Open and Efficient Foundation Language Models》翻译与解读
T1、基于原始LLaMA+国外微调或精调的版本:比如Alpaca、Vicuna
LLMs之Alpaca:《Alpaca: A Strong, Replicable Instruction-Following Model》翻译与解读
LLMs之Vicuna:《Vicuna: An Open-Source Chatbot Impressing GPT-4 with 90%* ChatGPT Quality》翻译与解读
T2、LLaMA的汉化版本——即Chinese-LLaMA-Alpaca+词表扩充的预训练2阶段+指令微调
LLMs:《Efficient And Effective Text Encoding For Chinese Llama And Alpaca—6月15日版本》翻译与解读
LLMs之LLaMA-2:LLaMA-2的简介(技术细节)、安装、使用方法(开源-免费用于研究和商业用途)之详细攻略
预训练数据。用于预训练的数据混合,对于每个子集,我们列出了采样比例、在1.4T标记上训练时在子集上执行的时代数量以及磁盘大小。在1T标记上进行的预训练运行具有相同的采样比例。
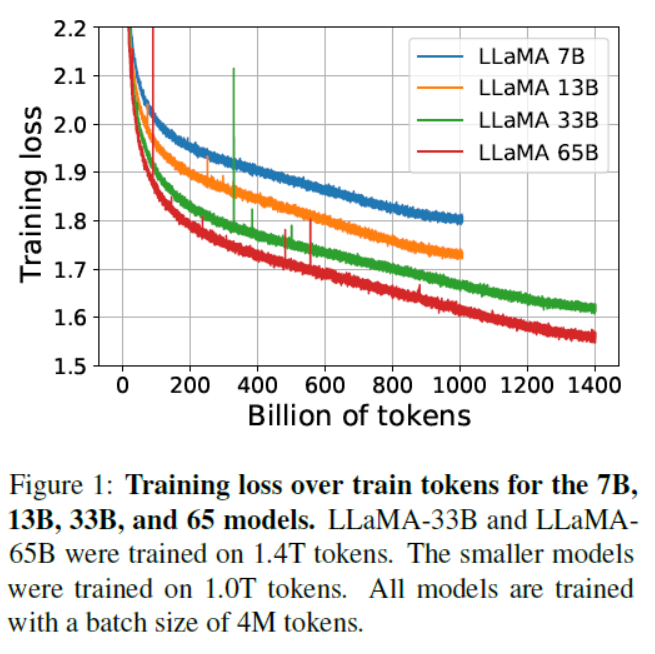
7B、13B、33B和65B模型在训练标记上的训练损失。LLaMA-33B和LLaMA-65B在1.4T标记上进行训练。较小的模型在1.0T标记上进行训练。所有模型的批次大小均为4M标记
LLMs:基于单个4GB GPU上(Windows系统)运行LLM上——pyllama模型(基于fjuncongmoo的GitHub)进行模型部署且实现模型推理全流程步骤的图文教程(非常详细)
LLMs:Chinese-LLaMA-Alpaca的简介(扩充中文词表+增量预训练+指令精调)、安装、案例实战应用之详细攻略
LLMs之llama.cpp:llama.cpp的简介、安装、使用方法之详细攻略
相关论文
LLMs之LLaMA:《LLaMA: Open and Efficient Foundation Language Models》翻译与解读
LLMs之LLaMA:《LLaMA: Open and Efficient Foundation Language Models》翻译与解读-CSDN博客
迭代版本
T1、基于原始LLaMA+国外微调或精调的版本:比如Alpaca、Vicuna
2023年3月14日——Alpaca(Stanford):使用小成本训练大模型(只需廉价600美元)、利用GPT3.5模型生成高质量的指令数据【175 个prompts+52K指令遵循样本数据】去SFT的LLaMA-7B、 基于LLaMA-7B+微调【HuggingFace框架训练】+Self-Instruct指令跟随语言模型、全分片数据并行+混合精度训练+8个A100-80G三个小时、后期的微调优化Alpace-LoRA
LLMs之Alpaca:《Alpaca: A Strong, Replicable Instruction-Following Model》翻译与解读
LLMs之Alpaca:《Alpaca: A Strong, Replicable Instruction-Following Model》翻译与解读_一个处女座的程序猿的博客-CSDN博客
2023年3月30日——Vicuna(Berkeley+CMU+Stanford):训练Vicuna13B仅300美元=8张A100耗费1天+PyTorch FSDP、ShareGPT收集7万段对话、基于Alpaca构建+内存优化(梯度检查点gradient checkpointing+闪光注意力flash attention,最大上下文长度扩展到2048)+多轮对话+管理Spot实例(降低成本)+GPT4模型评估
LLMs之Vicuna:《Vicuna: An Open-Source Chatbot Impressing GPT-4 with 90%* ChatGPT Quality》翻译与解读
LLMs:在Linux服务器系统上实Vicuna-7B本地化部署(基于facebookresearch的GitHub)进行模型权重合并(llama-7b模型与delta模型权重)、模型部署且实现模型推理全流程步骤的图文教程(非常详细)
LLMs:《如何使用Ray + DeepSpeed + HuggingFace简单、快速、经济有效地微调和服务LLM》解读_deepspeed ray-CSDN博客
T2、LLaMA的汉化版本——即Chinese-LLaMA-Alpaca+词表扩充的预训练2阶段+指令微调
LLMs:《Efficient And Effective Text Encoding For Chinese Llama And Alpaca—6月15日版本》翻译与解读
LLMs之Chinese-LLaMA-Alpaca:基于中文汉化版LLaMA(Meta)/Alpaca(斯坦福)开源代码(详细解读多个py文件)基于Ng单机单卡实现定义数据集(生成指令数据)→数据预处理(token分词/合并权重)→增量预训练(本质是高效参数微调,LoRA的参数/LLaMA的参数)→指令微调LoRA权重(继续训练/全新训练)→模型推理(CLI、GUI【webui/LLaMACha/LangChain】)
https://yunyaniu.blog.csdn.net/article/details/131319010
LLMs之Chinese-LLaMA-Alpaca:源代码解读run_clm_pt_with_peft.py文件实现模型增量预训练(CLI准备【命令行解析/设置日志】→文件设置准备【递增训练/种子/配置字典/分词字典】→数据预处理【文本标记/文本序列长度/token化/分组/切分数据集】→模型训练与评估【判断执行模式/预训练文件/调整词嵌入的大小/LoRA模型/输出可被训练的参数/替换state_dict/初始化Trainer/训练【续载训练/保存结果/度量指标/保存状态】→保存【LoRA模型/预训练配置信息/tokenizer】→验证【计算困惑度/记录评估指标】
https://yunyaniu.blog.csdn.net/article/details/122274996
LLMs之Chinese-LLaMA-Alpaca:源代码解读inference_hf.py文件基于验证数据集(拼接输入数据和模板指令+去空格+分词)利用合并模型(LLaMA+LoRA)实现模型推理(交互方式【实时输出】/非交互方式【导出生成结果和模型配置文件到本地】)
LLMs之Chinese-LLaMA-Alpaca:基于单机CPU+Windows系统实现中文LLaMA算法进行模型部署(llama.cpp)+模型推理全流程步骤【安装环境+创建环境并安装依赖+原版LLaMA转HF格式+合并llama_hf和chinese-alpaca-lora-7b→下载llama.cpp进行模型的量化(CMake编译+生成量化版本模型)→部署f16/q4_0+测试效果】的图文教程(非常详细)
T3、LLaMA-2
LLMs之LLaMA-2:LLaMA-2的简介(技术细节)、安装、使用方法(开源-免费用于研究和商业用途)之详细攻略
LLMs之LLaMA-2:LLaMA-2的简介(技术细节)、安装、使用方法(开源-免费用于研究和商业用途)之详细攻略_llama2-CSDN博客
LLaMA的简介
2023年2月25日,Meta公开发布LLaMA(Large Language Model Meta AI),这是一款先进的基础性大型语言模型,旨在帮助研究人员推动人工智能的这一子领域的工作。像LLaMA这样的更小、更高性能的模型使研究社区中那些无法访问大量基础设施的人能够研究这些模型,进一步使这一重要而快速变化的领域的访问更加民主化。
官网:GitHub - meta-llama/llama: Inference code for Llama models
注意,官网的版本已经更新到了LLaMA 2版本
GitHub(加载LLaMA模型并进行推理):GitHub - facebookresearch/llama at llama_v1
GitHub(基于Python部署):GitHub - meta-llama/llama: Inference code for Llama models
GitHub(基于Python和C/C++部署):
部署文章
GitHub - ggerganov/llama.cpp: Port of Facebook's LLaMA model in C/C++
1、模型特点
预训练数据。用于预训练的数据混合,对于每个子集,我们列出了采样比例、在1.4T标记上训练时在子集上执行的时代数量以及磁盘大小。在1T标记上进行的预训练运行具有相同的采样比例。

模型大小、架构和优化超参数

7B、13B、33B和65B模型在训练标记上的训练损失。LLaMA-33B和LLaMA-65B在1.4T标记上进行训练。较小的模型在1.0T标记上进行训练。所有模型的批次大小均为4M标记
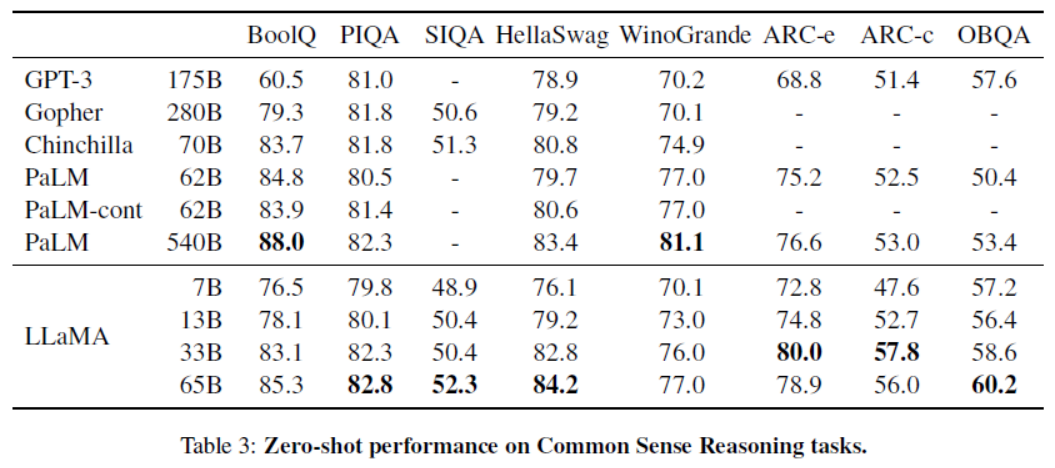
零样本模型性能,针对常识推理任务
在同一数据中心训练不同模型的碳足迹。我们遵循Wu等人(2022)的方法,在同一数据中心计算OPT、BLOOM和我们模型的碳排放量。对于A100-80GB的功耗,我们采用NVLink系统的热设计功耗,即400W。我们采用PUE值为1.1,碳强度因子设定为美国国家平均值,即每千瓦时0.385千克CO2

LLaMA的安装和使用方法
1、原始版本及其迭代版本直接训练与微调
LLMs:在单机CPU+Windows系统上对LLaMA模型(基于facebookresearch的GitHub)进行模型部署且实现模型推理全流程步骤【部署conda环境+安装依赖库+下载模型权重(国内外各种链接)→模型推理】的图文教程(非常详细)
LLMs之LLaMA-7B-QLoRA:基于Alpaca-Lora代码在CentOS和多卡(A800+并行技术)实现全流程完整复现LLaMA-7B—安装依赖、转换为HF模型文件、模型微调(QLoRA+单卡/多卡)、模型推理(对比终端命令/llama.cpp/Docker封装)图文教程之详细攻略
LLMs:基于单个4GB GPU上(Windows系统)运行LLM上——pyllama模型(基于fjuncongmoo的GitHub)进行模型部署且实现模型推理全流程步骤的图文教程(非常详细)
LLMs之Koala:《Koala: A Dialogue Model for Academic Research一款针对学术研究的对话模型》翻译与解读-CSDN博客
LLMs之LLaMA-7B-QLoRA:基于Alpaca-Lora代码在CentOS和多卡(A800+并行技术)实现全流程完整复现LLaMA-7B—安装依赖、转换为HF模型文件、模型微调(QLoRA+单卡/多卡)、模型推理(对比终端命令/llama.cpp/Docker封装)图文教程之详细攻略
2、汉化版本训练与微调:针对中文语料优化
LLMs:Chinese-LLaMA-Alpaca的简介(扩充中文词表+增量预训练+指令精调)、安装、案例实战应用之详细攻略
LLMs:Chinese-LLaMA-Alpaca的简介(扩充中文词表+增量预训练+指令精调)、安装、案例实战应用之详细攻略-CSDN博客
LLMs:基于单机CPU+Windows系统实现中文LLaMA算法(基于Chinese-LLaMA-Alpaca)进行模型部署(llama.cpp)+模型推理全流程步骤【安装环境+创建环境并安装依赖+原版LLaMA转HF格式+合并llama_hf和chinese-alpaca-lora-7b→下载llama.cpp进行模型的量化(CMake编译+生成量化版本模型)→部署f16/q4_0+测试效果】的图文教程(非常详细)
LLMs:基于Chinese-LLaMA-Alpaca开源代码在Ng单机单卡利用LLaMA(Meta)和Alpaca(斯坦福)实现定义数据集(生成指令数据)→数据预处理(token分词/合并权重)→增量预训练(LoRA的参数/LLaMA的参数)→指令微调LoRA权重(继续训练/全新训练)→模型推理(CLI、GUI【webui/LLaMACha/LangChain】)
https://yunyaniu.blog.csdn.net/article/details/131319010
3、基于第三方工具训练与微调
LLMs之llama.cpp:llama.cpp的简介、安装、使用方法之详细攻略
https://yunyaniu.blog.csdn.net/article/details/130397774
LLaMA的案例应用
持续更新中……

